

A naming convention is a set of unwritten rules you should use if you want to increase the readability of the whole data model. Today, I’ll try to explain how you should formulate your naming convention and, maybe even more important, why should you do it and what is the overall benefit from using it.
Data Model & the brief introduction
We’ll use the same data model we’re using in this series.

This time we won’t talk about the data itself, but rather about the database objects and the way they were named.
I’ve already stated it in the intro, but more generally, a naming convention is a set of rules you decide to go with before you start modeling your database. You’ll apply these rules while naming anything inside the database – tables, columns, primary and foreign keys, stored procedures, functions, views, etc. Of course, you could decide to only set naming convention rules for tables and column names. That part is completely up to you.
Also, using the naming convention is not the rule, but it’s desired. While most rules are pretty logical, you could go with some you’ve invited (e.g., you could call a primary key attribute “id”, or “ID”), and that is completely up to you. In this article, I’ll try to use these rules you’ll meet in most cases.
Why should you use the naming convention?
Maybe the most important reason to use it is to simplify life to yourself. Databases rarely have a small number of tables. Usually, you’ll have hundreds of tables, and if you don’t want to have a complete mess, you should follow some organizational rules. One of these rules would be to apply a naming convention. It will increase the overall model readability, and you’ll spend less time finding what you need. Also, it will be much easier to query the INFORMATION_SCHEMA database in search of specific patterns – e.g., checking if all tables have the primary key attribute named “id”; do we have a stored procedure that performs an insert for each table, etc.
If that wasn’t enough, there is also one good reason. The database shall live for a long time. Changes at the database level are usually avoided and done only when necessary. The main reason is that if you change the name of the database object that could affect many places in your code. On the other hand, the code can change during time. Maybe you’ll even change the language used to write the code. Therefore, you can expect that the database will stay, more or less, very similar to its’ initial production version. If you apply best practices from the start and continue using them when you add new objects, you’ll keep your database structure well organized and easily readable.
One more reason to use it is that you probably won’t be the only one working with the database. If it’s readable, anybody who jumps into the project should be aware of what is where and how the data is related. That shall be especially the case if you’re using the most common naming convention rules. In case you have something specific for your database, you can list all such exceptions in one short document.
How to name tables?
Hint: Use lower letters when naming database objects. For separating words in the database object name, use underscore
When naming tables, you have two options – to use the singular for the table name or to use a plural. My suggestion would be to always go with names in the singular.
If you’re naming entities that represent real-world facts, you should use nouns. These are tables like employee, customer, city, and country. If possible, use a single word that exactly describes what is in the table. On the example of our 4 tables, it’s more than clear what data can be found in these tables.
Hint: Use singular for table names (user, role), and not plural (users, roles). The plural could lead to some weird table names later (instead of user_has_role, you would have users_have_roles, etc.)
If there is a need to use more than 1 word to describe what is in the table – do it so. In our database, one such example would be the call_outcome table. We can’t use only “call”, because we already have the table call in the database. On the other hand, using the word outcome wouldn’t clearly describe what is in the table, so using the call_outcome as the table name seems like a good choice.
For relations between two tables, it’s good to use these two tables’ names and maybe add a verb between these names to describe what that action is.
Imagine that we have tables user and role. We want to add a many-to-many relation telling us that a user had a certain role. We could use names user_has_role, or if we want to be shorter – user_role.
We could always make exceptions if they are logical. If we have tables product and invoice, and we want to specify which products were on which invoice, we could name that table invoice_product or invoice_contains_product. Still, using the name invoice_item is much closer to the real world. Still, that decision is completely up to you.
How to name columns?
I would separate the naming convention for columns in a few categories:
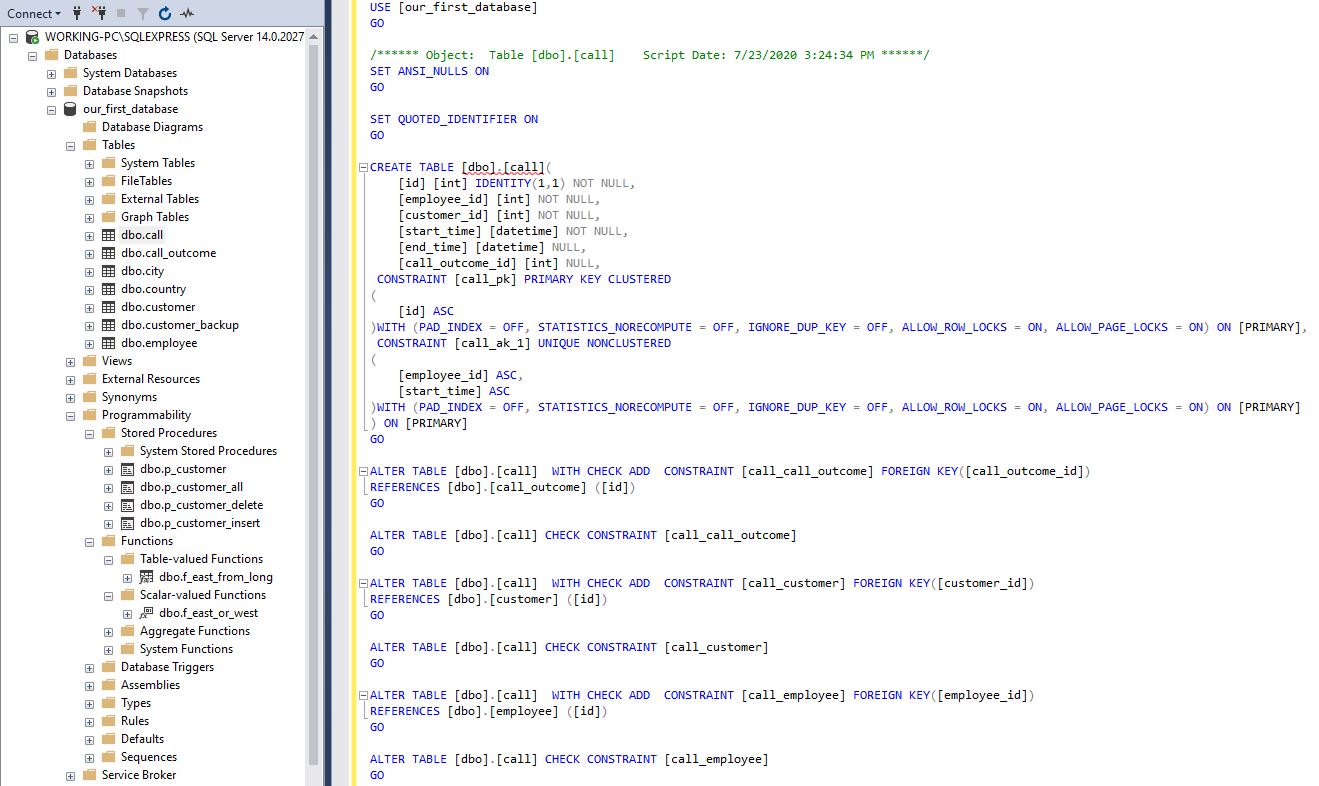
- A primary key column. You should usually have only 1 column serving as a primary key. It would be the best to simply name this column “id”. You should also name your PK constraint in a meaningful way. E.g., in our database, the PK of the call table is named call_pk
1CONSTRAINT [call_pk] PRIMARY KEY CLUSTERED

- Foreign key columns. Since they store values from the range of primary key of the referenced table, you should use that table name and “id”, e.g. customer_id or id_customer, employee_id or employee_id. This will tell us that this is a foreign key column and also point to the referenced table. In our database, we go with the first option – e.g., customer_id
- Data columns. These are attributes that store real-world data. The same rules could be applied as the ones used when naming tables. You should use the least possible words to describe what is stored in that column, e.g., country_name, country_code, customer_name. If you expect that 2 tables will have the column with the same name, you could add something to keep the name unique. In our model in the customer table, I’ve used the customer_name as a column name. I’ve also done the same in the table city with the column city_name. Generally, you can expect that using the word name alone won’t be enough to keep that column name unique
Hint: It’s not a problem if two columns, in different tables in the database, have the same name. Still, having unique names for each column is OK because we reduce the chance to later mix these two columns while writing queries
- Dates. For dates, it’s good to describe what the date represents. Names like start_date and end_date are pretty descriptive. If you want, you can describe them even more precise, using names like call_start_date and call_end_date
- Flags. We could have flags marking if some action took place or not. We could use names like is_active, is_deleted
Naming Conventions for Foreign Keys, Procedures, Functions, and Views
I won’t go into details here, but rather give a brief explanation of the naming convention I use when I do name these objects.
Foreign keys. You should name them in such a manner that they uniquely and clearly describe what they are – which tables they relate. In our database, the foreign key that relates tables call and call_outcome is called call_call_outcome.
|
1 2 |
ALTER TABLE [dbo].[call] WITH CHECK ADD CONSTRAINT [call_call_outcome] FOREIGN KEY([call_outcome_id]) REFERENCES [dbo].[call_outcome] ([id]) |
Stored procedures. Stored procedures usually run a set of actions and return a dataset. My rule is to have two approaches to their naming.
- If the store procedure is using only one table, I’ll name it p_<table_name>_<action_name>. E.g., p_customer_insert inserts a new row in the table customer; p_customer_delete deletes a row, p_customer_all returns all customers from the table, while p_customer returns only 1 customer
- If the procedure uses more than 1 table, I would use a descriptive name for the procedure. E.g., if we want all customers with 5 or more calls, I would call this procedure similar to this – p_customer_with_5_or_more_calls
Functions. Functions usually perform simple calculations and return values. Therefore, the best way to name them would be to describe what the function does. I also love to put f_ at the start of the name. In our database, one example is – f_east_from_long.
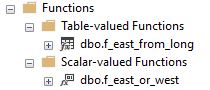
Views. Most of the rules that are applied to naming stored procedures should be applied to views. I usually don’t use views, but when I do, I place v_ at the start of their name.
Conclusion
The naming convention is not a must, but (very) nice to have. Applying the rules you’ve set for the database design will help not only you but also others who will work with the database. Therefore, I would suggest that you use it and keep the database as organized as it could be.
Table of contents

His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020