
En los artículos previos de estas series (véase abajo para el índice entero de los artículos), fuimos a través de la estructura entera de las tablas e índices de SQL Server, listamos un numero de líneas guía que ayuda a diseñar un índice apropiado, discutimos las operaciones que pueden ser realizadas en los índices SQL Server, y finalmente mostramos como diseñar y crear índices Agrupados SQL Server para hacer más rápidas las operaciones de recuperación de información. En este artículo, veremos como diseñar índices No agrupados efectivos que van a mejorar el rendimiento de las consultas más frecuentes y más usadas que no son cubiertas con un índice Agrupado y, al hacerlo, mejorar el rendimiento del sistema en general.
Resumen de las estructuras de índices No agrupados
Un índice no agrupado es construido usando la misma página de 8K con estructura B-Árbol que es usada para construir los índices Agrupados, excepto que la información y los índices No agrupados están hechos de páginas índice en vez de páginas de información. Las páginas de índice de los índices No agrupados contienen valores de índices No agrupados clave con punteros para la localización de almacenaje de estas filas en las tablas montón subyacentes del índice Agrupado.
Si un índice No Agrupado es construido sobre una tabla montón o vista (lee más sobre vistas con índice SQL Server que no tienen índices Agrupados) los nodos de nivel hoja de ese índice contiene valores de índice clave y punteros de Filas ID (RID) a las localizaciones de las filas en la tabla montón. El RID consiste en el identificador de archivo, el número de página de la información, y el número de filas en esa página de información. Por otro lado, si un índice No agrupado es creado sobre una tabla Agrupada, los nodos de nivel hoja de ese índice contienen valores de índices No agrupados clave y claves agrupadas para la tabla base, que son las localizaciones de las filas en las páginas de información de índices Agrupados. Si un índice No agrupado es construido sobre un índice Agrupado no único, los nodos del nivel hoja de los índices No agrupados retendrán valores adicionales unificadores de las filas de información, que es añadida por el Motor SQL Server para asegurar la singularidad del índice Agrupado.
Cuando envías una consulta que busca filas especificas basados en valores de índices No agrupados clave, el Optimizador de Consultas SQL Server buscara ese valor clave en las páginas de índice No agrupados y usara el valor de localizador de fila para localizar la fila requerida en la tabla subyacente, luego recuperara los registros requeridos directamente de la localización de almacenaje de la información, haciendo más rápido el proceso de recuperación de la información, ya que el índice No agrupado contiene una descripción completa para la localización exacta de la información en la tabla subyacente, basado en los valores de índice clave.
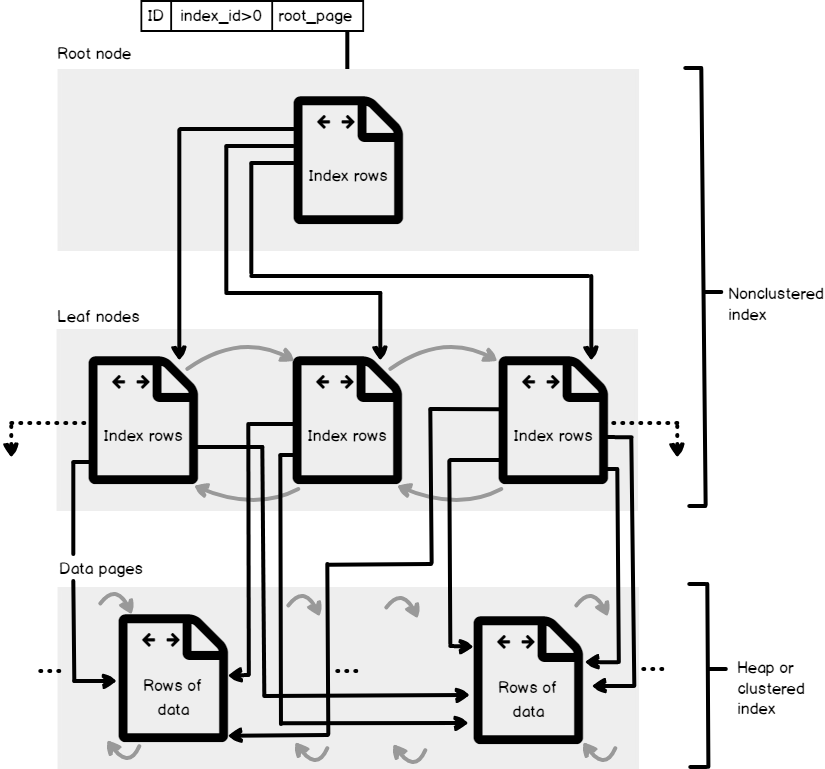
La figura de abajo, de Microsoft Books Online, muestra la estructura de un índice No agrupado que está construido sobre una tabla Agrupada o montón como se describió previamente. SQL Server nos permite crear índices múltiples No agrupados, con un total de hasta 999 índices No agrupados, en cada tabla, con los valores ID de índice asignados para cada índice empezando desde 2 por cada partición usada por el índice, como puedes encontrar en la tabla sys.partitions. Dependiendo en el tipo de información de las columnas participando en el índice No agrupado clave, un índice No agrupado SQL Server tendrá una o más unidades de asignación que son usadas para almacenar y administrar la información del índice. Mínimamente, cada índice No agrupado tendrá la unidad de asignación IN_ROW_DATA para almacenar la información del índice. Otros tipos especiales de unidades de asignación pueden ser también usadas para almacenar los objetos de información grande (LOB) y la unidad de asignación ROW_OVERFLOW_DATA que es usada para almacenar las columnas con una extensión variable que excede el tamaño límite de 8,060 bytes por fila.
Consideraciones del diseño de índices No agrupados
El objetivo principal de crear un índice No agrupado es el de mejorar el rendimiento de consultas al hacer más rápido el proceso de recuperación de la información. A pesar de que el SQL Server nos permite crear índices No agrupados múltiples, hasta 999 No agrupados en cada tabla que pueden cubrir nuestras consultas, cualquier índice añadido a la tabla va a impactar negativamente al rendimiento de modificación de información en esa tabla. Esto es debido al hecho de que, cuando modificas una columna clave in la tabla subyacente, los índices No agrupados deberían ser ajustados apropiadamente también.
Cuando diseñas un índice No agrupado, deberías considerar el tipo de carga de trabajo realizado en tu base de datos o tabla al comprometer entre los beneficios tomados de crear un nuevo índice y la modificación de información futura que será causada por la creación de este índice. Es recomendado crear un mínimo de índices estrechos, con un mínimo número de columnas participando en el índice clave, en la tabla pesadamente actualizada. Una tabla que tiene un gran número de filas con modificaciones de información bajas puede beneficiar bastante de más índices No agrupados con índices clave compuestos, que contienen más de una columna en el índice clave, que cubre todas las columnas en la consulta para mejorar el rendimiento de recuperación de información.
Cuando el índice contiene todas las columnas requeridas por la consulta, el Optimizador de Consulta SQL Server recuperará todos los valores de la columna del índice mismo, sin la necesidad de realizar operaciones de verificación para recuperar el resto de las columnas en la tabla subyacente o el índice Agrupado, reduciendo las operaciones costosas de disco I/O. Además, si el índice No agrupado es construido sobre una tabla Agrupada, las columnas que participan en el índice Agrupado serán añadidas automáticamente al final de cada índice No agrupado en esa tabla Agrupada, sin la necesidad de incluir estas columnas al índice No agrupado clave o las columnas no clave, para cubrir las consultas.
Mejor que crear un índice No agrupado con una clave ancha, columnas largas que son usadas para cubrir las búsqueda pueden ser incluidas en el índice No agrupado como columnas no clave, con un límite de hasta 1023 columnas no clave, usando la cláusula INCLUDE de la declaración CREATE INDEX T-SQL, que es introducida en la versión SQL Server 2005, con un mínimo de una columna clave. La opción INCLUDE extiende la funcionalidad del índice No agrupado, al permitirnos recuperar más consultas al añadir columnas como columnas no clave para ser almacenadas y clasificadas solo en el nivel hoja del índice, sin considerar que los valores de columna en los niveles raíz e intermedio del índice No agrupado. En este caso el Optimizador de Consultas SQL Server localizara todas las columnas requeridas de la tabla, sin la necesidad de verificaciones extra. Usando las columnas incluidas nos puede ayudar a evadir exceder el tamaño limite No agrupado de 900 bytes y 16 columnas en el índice clave, como el Motor de base de datos SQL Server no considerara las columnas en el índice No agrupado no clave cuando calcula el tamaño y numero de columnas de la clave del índice. Además, el SQL Server nos permite incluir las columnas con tipos de información que no están permitidas en el índice clave, como VARCHAR(MAX), NVARCHAR(MAX), text, ntext e image, como columnas no clave de índice No agrupado. Para más información sobre incluir columnas al índice clave No agrupado, revisa Índices no agrupados SQL Server con columnas incluidas.
Con todas estas posibilidades provistas por el SQL Server, es muy recomendable evadir añadir muchas claves o columnas no clave a los índices No agrupados que no son requeridos por las consultas. Esto es debido al gran espacio del disco que es requerido para almacenar ese índice y el gran número de páginas requeridas para almacenar la información del índice, porque añadiendo muchas columnas al índice resultara con menor número de filas que pueden entrar en cada página de información, incrementando el costo I/O y reduciendo la eficiencia caché. Puedes también imaginar el costo de la modificación de la información resultado de tan grandes índices.
Las columnas candidatas para los índices No agrupados clave son aquellas que están frecuentemente involucradas en la cláusula GROUP BY o en la condición JOIN o WHERE, que va a cubrir las consultas enviadas y retornar valores exactos correspondientes, en vez de retornar un conjunto largo de información. Las columnas semi-únicas que tienen un gran número de valores distintos son buenas candidatas también para columnas de índice No agrupados clave. Para la columna que tiene poco número de valores distintos, como la columna Gender, puedes tomar beneficio de crear un índice filtrado, como vamos a ver en el próximo artículo.
Implementación de índices No agrupados
En este punto, ya somos familiares con la estructura de índice No agrupado y la línea guía que deberían ser seguidas cuando se diseña un índice No agrupado. Ahora vamos a aprender cómo implementar un índice No agrupado.
Cuando creas una restricción UNIQUE, un índice No agrupado único será creado automáticamente para aplicar esa restricción. Índices No agrupados pueden ser creados independientemente de las restricciones usando la ventana de dialogo New Index de SQL Server Management Studio o usando el comando CREATE INDEX T-SQL. Para poder crear un índice No agrupado, debes ser un miembro de la función de servidor fijo sysadmin o de las funciones de base de datos fijos db_ddladmin y db_owner.
Déjanos crear una nueva tabla montón para ser usada en nuestro demo, usando la declaración CREATE TABLE T-SQL de abajo:
|
1 2 3 4 5 6 7 8 9 10 |
USE SQLShackDemo GO CREATE TABLE NonClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, StudentName NVARCHAR(50) NULL, STDBirthDate DATETIME NULL, STDPhone VARCHAR(20) NULL, STDAddress NVARCHAR(MAX) NULL ) |
Los índices No agrupados pueden ser creados usando SSMS al expandir el folder de las Tablas bajo tu base de datos. Para lograr esto, expande la tabla sobre la cual planeas crear el índice No agrupado, luego apretar clic derecho en el nodo de Índices bajo tu tabla y escoge crear el tipo de Índice No agrupado de la opción Nuevo Índice, como se muestra abajo:
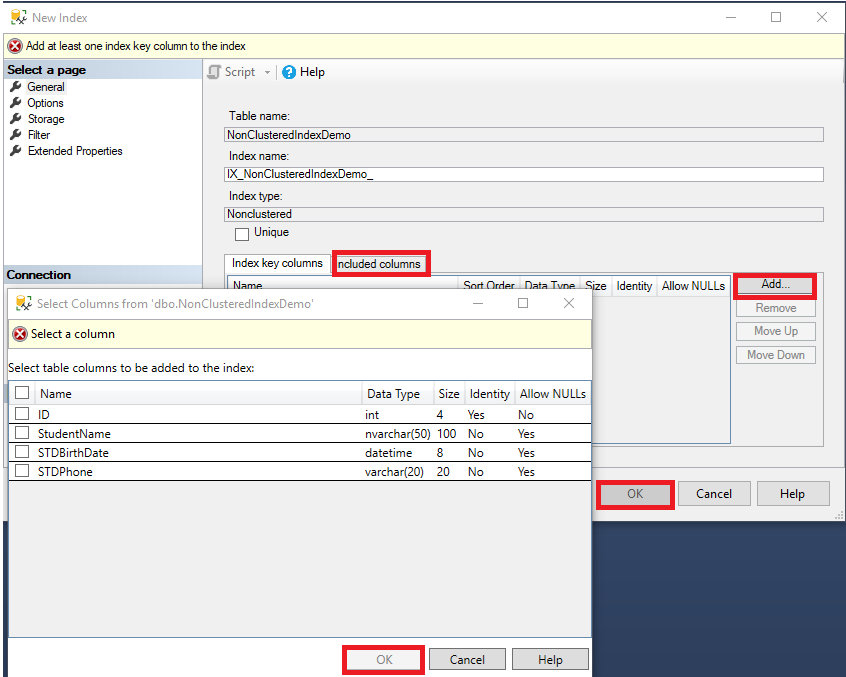
En la ventana abierta de New Index, verás que el nombre de la tabla en el cual el índice será creado y el tipo de índice de cluster no agrupado se llena automáticamente sin ninguna opción para cambiarlo. Lo que se require de tu lado es proveer un nombre para el índice siguiendo las convenciones específicas de nombre, si los valores clave de índice serán únicos o no, si la columna o lista de columnas que participaran in la clave de indice y finalmente la lista de columnas que serán incluidas al índice no agrupado como columnas no clave al hacer click en el botón Add como se muestra a continuación.
La pestaña Opciones de la ventana de dialogo Nuevo Índice te permite también configurar las diferentes opciones de creación de índice que controlan el rendimiento de la creación de índices, la cual es descrita profundamente en el artículo previo, como se muestra abajo:
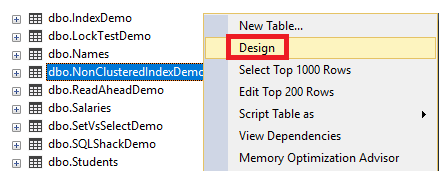
Otra forma de crear índices No agrupados usando SSMS es usar la Tabla Designer. Abre la tabla donde el índice será creado y luego apretar clic derecho en esa tabla y escoge la opción Design como se muestra abajo:
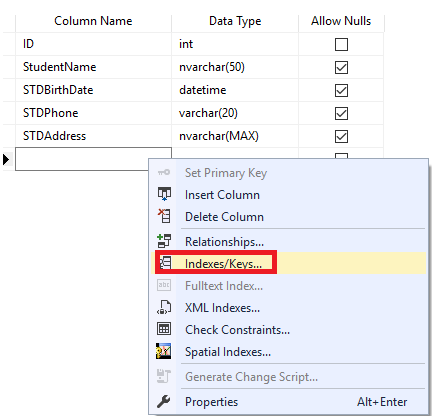
De la ventana abierta Tabla Designer, apretar clic derecho en cualquier parte y escoge la opción Índices/Claves para abrir la ventana de dialogo creación de índice, como se muestra abajo:
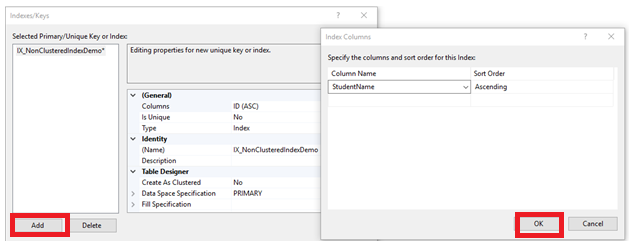
En la ventana abierta, apretar clic en el botón Añadir para añadir un nuevo índice No agrupado. Configura la opción Crear Como Agrupado como “No”, provee un nombre para el índice, si los valores clave de los índices No agrupados serán únicos o no, la columna o columnas que van a participar en el índice clave, con el orden requerido, como se muestra claramente abajo:
De la misma ventana, expande las Especificaciones de relleno para especificar las columnas no-clave que serán incluidas en los índices No agrupados y las opciones diferentes de creación de índice, como se muestra abajo:
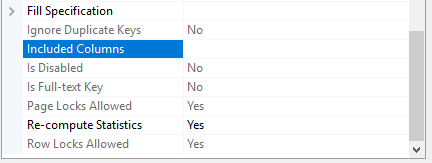
Un índice No agrupado puede también ser creado usando el comando CREATE NONCLUSTERED INDEX, al proveer el nombre del índice, el nombre de la tabla en la cual el índice será creado, la singularidad del índice clave y la columna o lista de columnas que van a participar en el índice clave y las columnas no-clave, opcionalmente, en la cláusula INCLUDE, como se muestra en el comando abajo:
|
1 2 3 |
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexDemo_StudentName ON NonClusteredIndexDemo (StudentName) WITH (ONLINE = ON , FILLFACTOR=90) |
Por defecto la declaración CREATE INDEX T-SQL creará un índice No agrupado si el tipo del índice no es especificado. Considera configurar las opciones de creación específicas de índice en la declaración previa CREATE INDEX que afecta el rendimiento del proceso de creación del índice. La opción ONLINE permite a los usuarios concurrentes acceder a la tabla subyacente o la información de índices Agrupados durante el proceso de creación de índices No agrupados, donde la opción FILLFACTOR es usada para configurar el porcentaje de espacio libre que será dejado en los nodos de nivel hoja de los índices No agrupados durante la creación del índice, para minimizar la división de la página y problemas de fragmentación de rendimiento.
Comparación de rendimiento
Antes de empezar con los ejemplos de comparación de rendimiento, vamos a llenar la tabla previamente creada con 200 mil filas, usando ApexSQL Generate, como se muestra abajo:
Índice No agrupado en table montón
La tabla montón NonClusteredIndexDemo esta lista ahora, llenada con 200 mil filas y no tiene índice creado en esta tabla, asumiendo que la declaración CREATE INDEX previa no es ejecutada, como se muestra abajo:
Si tratamos de ejecutar la sentencia SELECT a continuación, despues de habilitar las estadìsticas de IO y TIME y el plan actual de ejecución en una consulta como se muestra a continuación.
|
1 2 3 4 5 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Las estadísticas TIME y IO muestran que 2109 operaciones lógicas leídas, 47 ms del tiempo de CPU consumidos en 204 ms de tiempo para recuperar la información requerida como se muestra en la captura de pantalla de abajo:

Verificando el plan de ejecución general después de ejecutar la consulta, un Escaneo Completo será realizado en la tabla montón para recuperar la información requerida, como se muestra abajo:

Si creamos un índice No Agrupado sobre la tabla montón en las columnas StudentName y STDAddress usadas en la cláusula WHERE, usando la declaración CREATE INDEX T-SQL de abajo:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
La declaración CREATE INDEX fallará, mientras la columna STDAddress, con información tipo NVARCHAR(MAX), no puede ser añadida al índice No agrupado como columna clave, como se muestra en el mensaje de error de abajo:

Si tratamos otra vez de crear un índice No Agrupado en la tabla montón solamente en el StudentName, usando la declaración CREATE INDEX T-SQL de abajo:
|
1 2 3 |
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexDemo_StudentName ON NonClusteredIndexDemo (StudentName) WITH (ONLINE = ON , FILLFACTOR=90) |
Y ejecutar la misma declaración SELECT, que busca basada en las columnas StudentName y STDAdderss:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Verificando las estadísticas TIME e IO, verás que 2109 operaciones lógicas leídas son realizadas, 47 ms del tiempo CPU son consumidos en 110 ms de tiempo para recuperar la información requerida, lo cual es de algún modo similar a los valores generados después de recuperar la información sin un índice, pero un poco más rápido como se muestra en la captura de pantalla de abajo:

El plan de ejecución generado después de ejecutar la consulta mostrará que un escaneo entero de la tabla será también realizado en esa tabla sin considerar los índices No agrupados creados, con un mensaje indicando que hay un índice faltante que puede mejorar el rendimiento de la consulta en aproximadamente 72 %. El script para crear ese índice puede ser mostrado haciendo clic derecho en el plan de ejecución y escoger la opción Missing Index Details, como se muestra abajo:
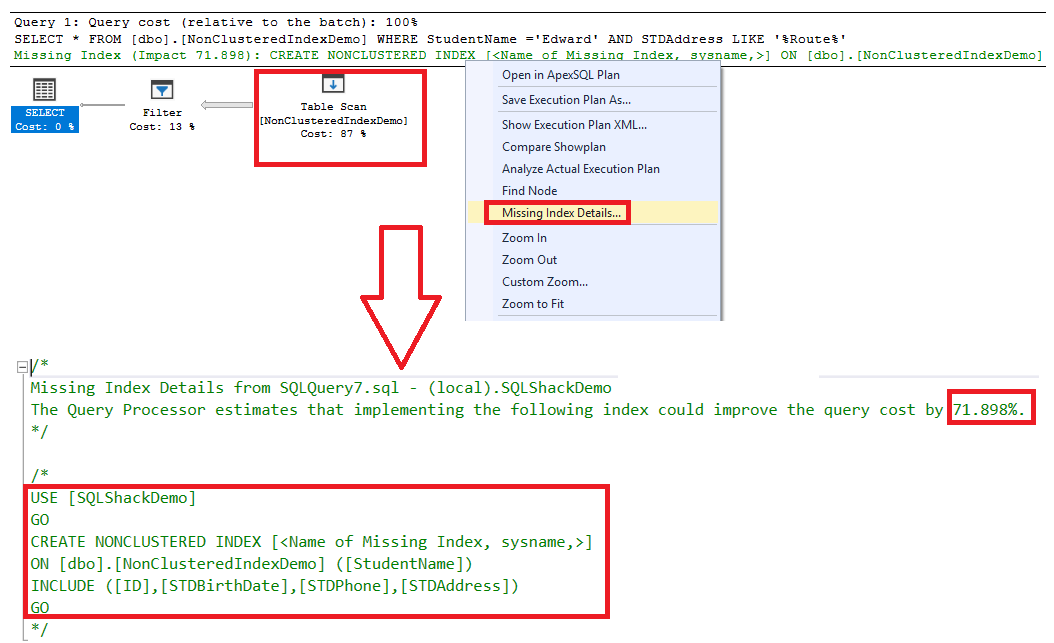
El mensaje de índice perdido previo incluye todas las columnas requeridas para la consulta en la columna de índice no-clave sugerida. Déjanos mover gradualmente en el proceso de creación, al incluir solo las columnas de ID y STDAddress en las columnas índices no-clave, usando la declaración CREATE INDEX T-SQL de abajo:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
Luego ejecuta la misma declaración SELECT de abajo:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Verás de las estadísticas TIME e IO que, solo 37 operaciones lógicas leídas son realizadas, 15 ms del tiempo de CPU es consumido en 76 ms de tiempo para recuperar la información requerida, lo cual es claramente mejor que el anterior resultado generado por escanear enteramente la tabla subyacente, como se muestra en la captura de pantalla de abajo:

El plan de ejecución, generado después de ejecutar la consulta, también muestra que la operación de Búsqueda de índice es realizada para recuperar la información directamente del índice No agrupado, sin la necesidad de escanear la tabla subyacente. El único problema que puede ser derivado del plan es que la operación pesada y costosa del Buscador RID es realizada para recuperar el resto de las columnas que no están disponibles en el índice de la tabla montón basado en el ID de cada fila, consumiendo la mayor parte del peso planeado como se muestra abajo:
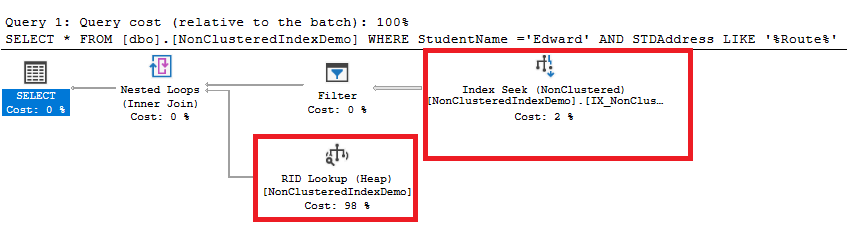
Si creamos un índice cubierta que es sugerido por el SQL Server e incluimos todas las columnas de consulta, usamos el INDEX CREATE con la opción DROP_EXISTING para dejar el antiguo:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
Y ejecutamos la misma declaración SELECT:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Las estadísticas TIME e IO mostrarán que solo 20 operaciones lógicas leídas son realizadas, 0 ms del tiempo de CPU es consumido en 65 ms de tiempo para recuperar la información requerida, lo cual es claramente mejor que usar un índice No agrupado que no cubre todas las columnas requeridas, como se muestra en la captura de pantalla de abajo:

Y el plan de ejecución generado después de ejecutar la consulta muestra que las operaciones de Buscador de Índice serán realizadas para recuperar la información de los índices No agrupados directamente, sin la necesidad de visitar la tabla de montón subyacente como se muestra abajo:

Índices No agrupados sobre tabla agrupada
En el escenario previo, discutimos sobre construir un índice No agrupado sobre una tabla montón. Ahora veremos como la consulta va a comportarse cuando se crea un índice No agrupado sobre una tabla Agrupada. Déjanos primero quitar el índice No agrupado existente antes de crear el índice Agrupado, para evitar la reconstrucción de índices No agrupados durante el proceso de creación del índice Agrupado.
|
1 |
DROP INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] |
Ahora la tabla no tiene índice. Vamos a crear un nuevo índice Agrupado en la columna ID para convertir esa tabla a una tabla Agrupada que es ordenada basada en la columna ID, usando la declaración CREATE INDEX de abajo:
|
1 2 |
CREATE UNIQUE CLUSTERED INDEX IX_NonClusteredIndexDemo_ID ON NonClusteredIndexDemo(ID) WITH (ONLINE=ON, FILLFACTOR=90) |
Si ejecutamos la misma declaración SELECT que busca basada en los valores de las columnas StudentName y STDAddress:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Verás de las estadísticas Time e IO que, la consulta correrá más rápido que leerlas de la tabla montón, ya que las páginas de información están unidas y ordenadas ahora. Donde 2330 operaciones lógicas leídas son realizadas, 47 ms del tiempo de CPU son consumidos en 106ms de tiempo para recuperar la información requerida como se muestra abajo:

La ejecución del plan generado después de ejecutar la consulta, muestra que el SQL Server escanea los Índices Agrupados, lo cual es una copia ordenada de la tabla, para recuperar la información. Puedes ver que el SQL Server escanea el total de los registros de la tabla, 200 mil filas, para obtener la información requerida, pero más rápido que el escaneo de la tabla ya que es ordenada como se muestra abajo:
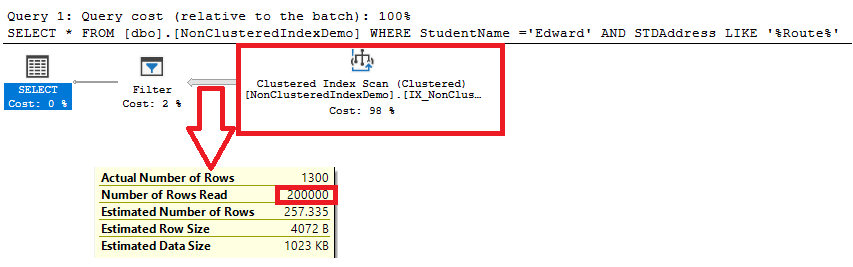
Si creamos un índice No agrupado en la columna StudentName que cubre parcialmente las columnas ID y STDAddress de la consulta, usando la declaración CREATE INDEX T-SQL de abajo:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDAddress]) WITH (ONLINE=ON, FILLFACTOR=90) GO |
Luego ejecuta la declaración previa SELECT de abajo:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Las estadísticas Time e IO mostrarán que solo 84 operaciones lógicas leídas son realizadas, 15 ms del tiempo de CPU es consumido en 68 ms de tiempo para recuperar la información requerida, lo cual es claramente más rápido que usar el índice Agrupado solamente, como se muestra abajo:

El plan de ejecución generado también muestra que la operación de Búsqueda de Índice será realizada para recuperar la información directamente del índice, sin la necesidad de escanear el índice Agrupado. Como el índice No agrupado no está cubriendo completamente la consulta, la Búsqueda Clave de operaciones pesadas y costosas es realizada para recuperar el resto de las columnas que no están disponibles en el índice del índice Agrupado, basado en la clave Agrupada de cada fila, consumiendo la mayor parte del peso planeado, como se muestra abajo:
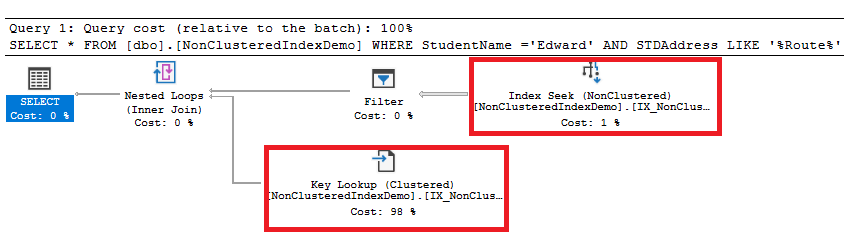
Creando un índice No agrupado que cubre todas las columnas de consulta, usando la opción CREATE INDEX … WITH DROP_EXISTING para dejar el antiguo:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
Luego ejecuta la declaración previa SELECT:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Puedes ver de las estadísticas TIME e IO que solo 18 operaciones lógicas leídas son realizadas, 0 ms del tiempo de CPU es consumido en 59 ms de tiempo para recuperar la información requerida, que es obviamente más rápido que usar un índice No agrupado que no cubre todas las columnas requeridas, como se muestra en la captura de pantalla de abajo:

Del plan de ejecución generado, puedes ver que la operación de Búsqueda de Índice será realizada para recuperar toda la información de los índices No agrupados creados, sin visitar el índice Agrupado como se muestra abajo:

Costos de modificación de Información
Los índices No agrupados son muy útiles para hacer más rápido el proceso de recuperación de información, como vimos de los ejemplos previos. Por el otro lado, cada índice creado añadirá costo extra a las operaciones de modificación. Déjanos verificar el costo de índice en las operaciones de modificación de información. Asume que dejamos nuestra tabla de prueba y creamos una copia montón vacía de esa tabla, usando el script de abajo:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE SQLShackDemo GO DROP TABLE NonClusteredIndexDemo GO CREATE TABLE NonClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, StudentName NVARCHAR(50) NULL, STDBirthDate DATETIME NULL, STDPhone VARCHAR(20) NULL, STDAddress NVARCHAR(MAX) NULL ) |
Después llenaremos la tabla montón con 200 mil filas, usando ApexSQL Generate. Verás que tomará 4.53 segundos en llenar la tabla, como se muestra abajo:
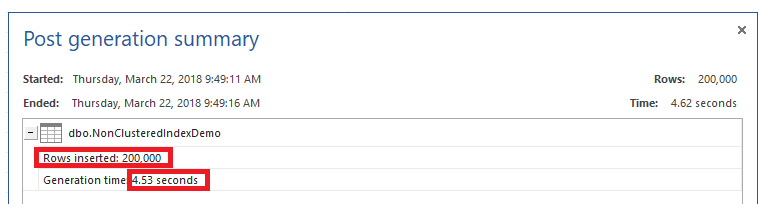
Si truncas la tabla y creas un índice No Agrupado nuevo en esa tabla, usando el script T-SQL de abajo:
|
1 2 3 4 5 6 7 |
TRUNCATE TABLE [NonClusteredIndexDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
Y tratas ahora de llenar la tabla con 200 mil filas de Nuevo, usando ApexSQL Generate. Verás que tomará 5,01 segundos para llenar la tabla, con cerca de 0,48 segundos de costo debido a escribir a ambos, la tabla subyacente y el índice No agrupado, como se muestra abajo:
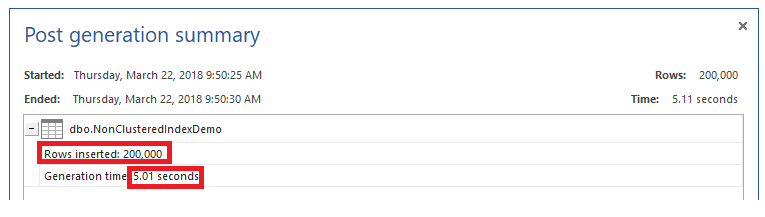
Puedes imaginar el costo de modificación de información extra que será causado por añadir otros índices a la tabla. Déjanos tomar otro ejemplo. Dejaremos el índice No agrupado previamente creado y trataremos de actualizar las direcciones de estudiantes específicos, usando el script T-SQL de abajo:
|
1 2 3 4 5 |
DROP INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] UPDATE [dbo].[NonClusteredIndexDemo] SET STDAddress='335 Delaware Avenue' WHERE STDAddress LIKE '%Delaware%' |
Verás de las estadísticas IO y Time mostrar que el Motor SQL Server realizará 2117 lecturas lógicas, consumir 375 ms del tiempo de CPU con 374 ms, para actualizar la tabla que no tiene índice, como se muestra abajo:

Si creamos la cubierta de índice No agrupado otra vez usando la declaración CREATE INDEX T-SQL de abajo:
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
Luego ejecutar una declaración nueva de UPDATE:
|
1 2 |
UPDATE [dbo].[NonClusteredIndexDemo] SET STDAddress='336 Delaware Avenue' WHERE STDAddress LIKE '%Delaware%' |
Las estadísticas IO y Time mostrarán que, el Motor SQL Server realizara 7876 lecturas lógicas en la tabla principal y las páginas índice No agrupadas “Worktable”, consumiendo 391 ms del tiempo de CPU con 398 ms para actualizar la tabla que no tiene índice, con todos los contadores, más largo que actualizar la tabla que no tiene índice, como se muestra abajo:

Las estadísticas previas muestran el costo causado por realizar operaciones INSERT y UPDATE a la vez. Puedes imaginar el costo causado en una tabla con requerimientos pesados de INSERT, UPDATE y DELATE, con números múltiples de índices No agrupados. Pero otra vez, necesitas comprometer entre las operaciones de recuperación de información y la modificación de información que son realizadas en tu tabla, antes de planear crear un nuevo índice en esa tabla.
En este artículo, tratamos de cubrir todos los aspectos del concepto de índice No agrupado, teóricamente y prácticamente. En el siguiente artículo, iremos a través los otros tipos de índices SQL Server. ¡Sigue sintonizado!
Tabla de contenido
Ver más
Para arreglar la fragmentación de índices de SQL, considera ApexSQL Defrag – Un análisis de monitoreo de Índices de SQL Server, mantenimiento, y herramienta de desfragmentación.


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Restricciones en SQL Server: SQL NOT NULL, UNIQUE y SQL PRIMARY KEY - December 16, 2019
- Operaciones de copia de seguridad, truncamiento y reducción de registros de transacciones de SQL Server - November 4, 2019
- Qué elegir al asignar valores a las variables de SQL Server: sentencias SET vs SELECT T-SQL - November 4, 2019