
In this article, in the series, we’ll discuss understanding and preparing data by using SQL unpivot.
As I announced in my previous article, Data science in SQL Server: pivoting and transposing data, this one is talking about the opposite process to pivoting, the unpivoting process. With unpivoting, you rotate the data to get rows from specific number of columns, with the original column names stored as a value in the rows of a new, unpivoted column. Unpivoting might be even more frequent operation in data science data preparation than pivoting because quite a lot of data exist in spreadsheets and other table formats that are not suitable for an immediate use.
Instead of any further explanation of unpivoting, I will show you the process through examples.
T-SQL Unpivot Operator and Other Possibilities
As always, I need some data to work on. The following query creates a table with pivoted data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
USE AdventureWorksDW2017; GO -- Data preparation - pivoting WITH PCTE AS ( SELECT g.EnglishCountryRegionName AS Country, d.CalendarYear AS CYear, SUM(s.SalesAmount) AS Sales FROM dbo.FactInternetSales s INNER JOIN dbo.DimDate d ON d.DateKey = s.OrderDateKey INNER JOIN dbo.DimCustomer c ON c.CustomerKey = s.CustomerKey INNER JOIN dbo.DimGeography g ON g.GeographyKey = c.GeographyKey WHERE g.EnglishCountryRegionName IN (N'Australia', N'Canada') GROUP BY g.EnglishCountryRegionName, g.StateProvinceName, d.CalendarYear ) SELECT Country, [2010], [2011], [2012], [2013], [2014] INTO dbo.SalesPivoted FROM PCTE PIVOT (SUM(Sales) FOR CYear IN ([2010], [2011], [2012], [2013], [2014])) AS P; GO |
The following query checks the content of the table I just created.
|
1 2 |
SELECT Country, [2010], [2011], [2012], [2013], [2014] FROM dbo.SalesPivoted; |
Here is the result, the pivoted table:

In a data science projects, you might have a task to forecast the sales over countries and years. You need to create time series, with years as time points. Since you have data for five years in five columns, you need to create five rows for each year. You will get five rows per country, with a new column that denotes the year, with the original column names [2010] to [2014] as the values of this new column. You will get another new column with sales data. The values of this column will be the respective values of the cells in the intersection of each country with each year. For example, the for the row with country Australia and year 2010, the sales value will be 20,909.78. My first query uses the T-SQL UNPIVOT operator.
|
1 2 3 4 5 |
SELECT Country, CYear, Sales FROM dbo.SalesPivoted UNPIVOT(Sales FOR CYear IN ([2010], [2011], [2012], [2013], [2014])) AS U ORDER BY Country, CYear; |
Here is the unpivoted result. You can see that I used the name CYear for the year column (denoting calendar year) and Sales for the value column:

Similarly like the PIVOT operator, the UNPIVOT operator is also not a part of the ANSI SQL standard. In order to have your data science project code prepared for multiple database management systems, you might want to use the standard ANSI SQL expressions only. For each original row, for each country, you have to create five rows, one for each year. You can do it with a cross join of the original table with the tabular expression in the FROM clause that returns the five rows. Then you use the CASE expression to extract the correct value for each year. Finally, you need to eliminate rows with unknown sales. This last task is just to have completely the same logic as the PIVOT operator, which eliminates rows with NULLs in the value column. In your data science project, you might keep NULLs, and replace them with some default value, in order to have all time points present. Note that in the demo dataset I am using, there are no NULLs, so the result of the following query would be the same even without the WHERE clause.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT Country, CYear, Sales FROM (SELECT Country, CYear, CASE CYear WHEN 2010 THEN [2010] WHEN 2011 THEN [2011] WHEN 2012 THEN [2012] WHEN 2013 THEN [2013] WHEN 2014 THEN [2014] END AS Sales FROM dbo.SalesPivoted CROSS JOIN ( SELECT 2010 AS CYear UNION ALL SELECT 2011 UNION ALL SELECT 2012 UNION ALL SELECT 2013 UNION ALL SELECT 2014) AS CY) AS D WHERE Sales IS NOT NULL ORDER BY Country, CYear; |
In T-SQL, you could also use the CROSS APPLY operator to apply a tabular expression for each row from the original table. You can also create the five rows, one for each year, with the VALUES clause, which is a shorthand for multiple SELECT … UNION clauses. Like the following example shows, the query becomes shorter.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT Country, CYear, Sales FROM dbo.SalesPivoted CROSS APPLY ( VALUES (2010, [2010]), (2011, [2011]), (2012, [2012]), (2013, [2013]), (2014, [2014]) ) AS U( CYear, Sales ) WHERE Sales IS NOT NULL ORDER BY Country, CYear; |
However, the APPLY operator is also a T-SQL extension of the ANSI standard. You might still prefer to use the standard SQL in your projects.
In all of the queries so far, I had to write manually the list of the values for the CYear column. Therefore, you can unpivot only a fixed number of original columns. The question is, of course, can you create this list dynamically, as I have shown in my previous article for the PIVOT operator. And the answer is yes. All you need to know is that in SQL Server, you can find all column names of all tables in sys.columns catalog view. Then you can use the STRING_AGG() function to get a delimited list of the column names.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @stmtvar AS NVARCHAR(4000); SET @stmtvar = N' SELECT Country, CYear, Sales FROM dbo.SalesPivoted UNPIVOT(Sales FOR CYear IN (' + (SELECT STRING_AGG(QUOTENAME([name]), N', ') WITHIN GROUP (ORDER BY [name]) FROM ( SELECT [name] FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.SalesPivoted', N'U') AND name LIKE N'2%' ) AS Y) + N')) AS U ORDER BY Country, CYear;'; EXEC sys.sp_executesql @stmt = @stmtvar; GO |
It is time to switch to the languages that are more oriented towards data science.
Unpivoting in R
Let me read the pivoted data from SQL Server in R.
|
1 2 3 4 5 6 7 8 |
library(RODBC) con <- odbcConnect("AWDW", uid = "RUser", pwd = "Pa$$w0rd") SGY <- as.data.frame(sqlQuery(con, "SELECT Country, [2010], [2011], [2012], [2013], [2014] FROM dbo.SalesPivoted;"), stringsAsFactors = TRUE) close(con) View(SGY) |
You can use the stack() function from the basic installation to unpivot the data. The following code stacks vertically the data from the SGY data frame without the first column.
|
1 |
stack(SGY[-1]) |
Here is the result:
| values | ind | |
| 1 | 20909.78 | 2010 |
| 2 | 3578.27 | 2010 |
| 3 | 2563732.25 | 2011 |
| 4 | 571571.80 | 2011 |
| 5 | 2128407.46 | 2012 |
| 6 | 307604.52 | 2012 |
| 7 | 4339443.38 | 2013 |
| 8 | 1085632.65 | 2013 |
| 9 | 8507.72 | 2014 |
| 10 | 9457.62 | 2014 |
You can see that I lost the country values. I can add them back with the following code.
|
1 |
cbind(rbind(SGY[1], SGY[1], SGY[1], SGY[1], SGY[1]), stack(SGY[-1])) |
In the previous code, I used the rbind() function to multiply the first two rows of the original data frame with the first column only, with the country only. Now I have ten rows, which I can bind as a new column with the cbind() function to the result of the stack() function. Here is the result:
This was not a very useful code. Besides adding the countries manually, I also did not change the default column names for the two new columns, the values and the column.
To make the complete unpivoting dynamically, I can use the melt() function from the reshape package. Here is an example.
|
1 2 3 |
library(reshape) SU <- melt(SGY, id = c("Country")) SU |
The following result shows that I still have default names for them to new columns. The melt() function assigns the names variable and value. In addition, I didn’t care about the order of the rows.
| Country | variable | value | |
| 1 | Australia | 2010 | 20909.78 |
| 2 | Canada | 2010 | 3578.27 |
| 3 | Australia | 2011 | 2563732.25 |
| 4 | Canada | 2011 | 571571.80 |
| 5 | Australia | 2012 | 2128407.46 |
| 6 | Canada | 2012 | 307604.52 |
| 7 | Australia | 2013 | 4339443.38 |
| 8 | Canada | 2013 | 1085632.65 |
| 9 | Australia | 2014 | 8507.72 |
| 10 | Canada | 2014 | 9457.62 |
I will take care of the column names and the row order with the rename() and arrange() functions from the dplyr package.
|
1 2 3 4 5 |
library(dplyr) SUO <- rename(SU, CYear = variable, Sales = value) %>% arrange(Country, CYear) SUO |
Now I got the result I wanted.
| Country | CYear | Sales | |
| 1 | Australia | 2010 | 20909.78 |
| 2 | Australia | 2011 | 2563732.25 |
| 3 | Australia | 2012 | 2128407.46 |
| 4 | Australia | 2013 | 4339443.38 |
| 5 | Australia | 2014 | 8507.72 |
| 6 | Canada | 2010 | 3578.27 |
| 7 | Canada | 2011 | 571571.80 |
| 8 | Canada | 2012 | 307604.52 |
| 9 | Canada | 2013 | 1085632.65 |
| 10 | Canada | 2014 | 9457.62 |
I will show one more option in R – the gather() function from the tidyr package. I can define the new column names when calling this function directly. Then I can use the arrange() function again to sort the data, like the following code shows. The result is the same as above.
|
1 2 3 |
library(tidyr) gather(SGY, key = CYear, value = Sales, - Country) %>% arrange(Country, CYear) |
Time to show another graph. This time, I am using the plot_ly() function from the plotly library. With this library, you can make interactive graphs online. Therefore, the next graph opens in a Web browser.
|
1 2 3 4 5 6 |
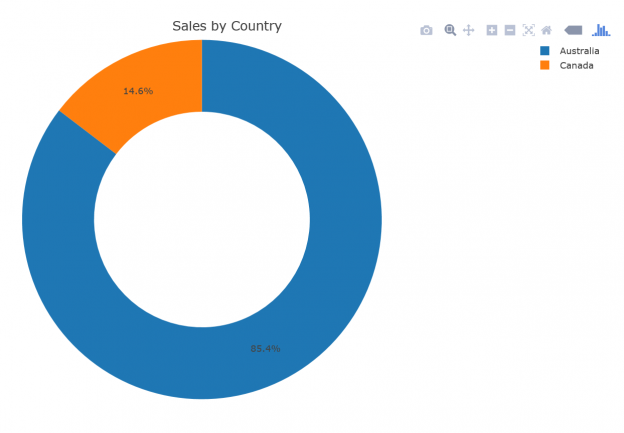
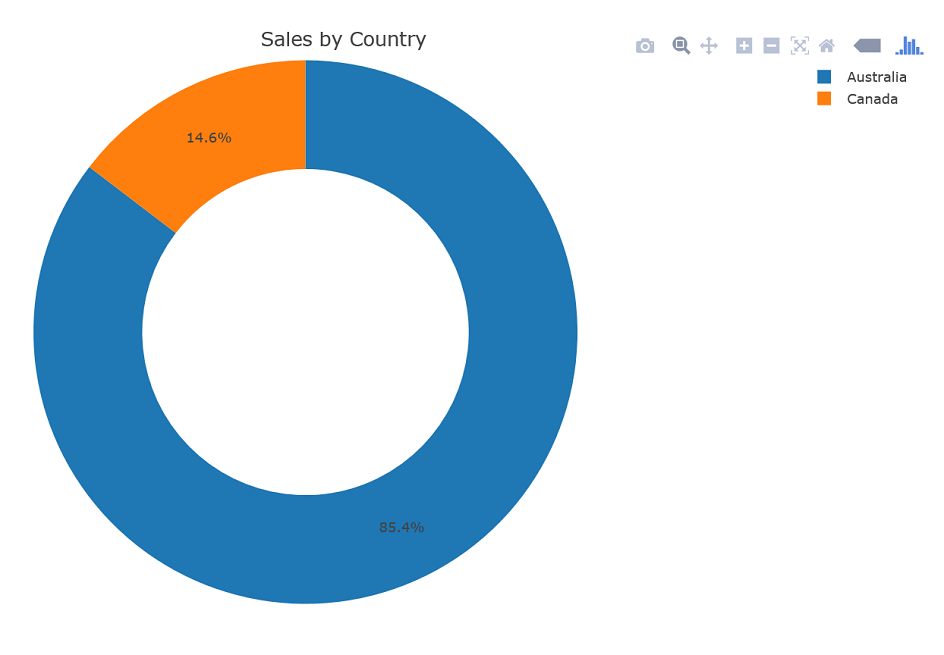
library(plotly) plot_ly(data = SUO, labels = ~SUO$Country, values = ~SUO$Sales) %>% add_pie(hole = 0.6) %>% layout(title = "Sales by Country", showlegend = T, xaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE), yaxis = list(showgrid = FALSE, zeroline = FALSE, showticklabels = FALSE)) |
Here is the plotly graph, showing the sales oved countries in a donut chart:
In the next section, I will show how to do the unpivoting in Python.
Python Pandas Unpivoting
Let me again start with imports and with reading the data from SQL Server.
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np import pandas as pd import pyodbc import matplotlib.pyplot as plt # Connecting and reading the data con = pyodbc.connect('DSN=AWDW;UID=RUser;PWD=Pa$$w0rd') query = """ SELECT Country, [2010], [2011], [2012], [2013], [2014] FROM dbo.SalesPivoted;""" SGY = pd.read_sql(query, con) SGY.head() |
I will find all methods I need for unpivoting in the pandas library. The first method I am showing is the unstack() method.
|
1 |
SGY.unstack() |
Here is the result:
| Country | 0 | Australia |
| 1 | Canada | |
| 2010 | 0 | 20909.8 |
| 1 | 3578.27 | |
| 2011 | 0 | 2.56373e+06 |
| 1 | 571572 | |
| 2012 | 0 | 2.12841e+06 |
| 1 | 307605 | |
| 2013 | 0 | 4.33944e+06 |
| 1 | 1.08563e+06 | |
| 2014 | 0 | 8507.72 |
| 1 | 9457.62 |
I got a two-level index or a multi-index. I can use the rest_index() method to get flattened index structure with both levels shown explicitly, like the following code shows.
|
1 |
SGY.unstack().reset_index(name = 'Sales') |
Here is the result:
| Level 0 | Level 1 | Sales | |
| 0 | Country | 0 | Australia |
| 1 | Country | 1 | Canada |
| 2 | 2010 | 0 | 20909.8 |
| 3 | 2010 | 1 | 3578.27 |
| 4 | 2011 | 0 | 2.56373e+06 |
| 5 | 2011 | 1 | 571572 |
| 6 | 2012 | 0 | 2.12841e+06 |
| 7 | 2012 | 1 | 307605 |
| 8 | 2013 | 0 | 4.33944e+06 |
| 9 | 2013 | 1 | 1.08563e+06 |
| 10 | 2014 | 0 | 8507.72 |
| 11 | 2014 | 1 | 9457.62 |
Still, the result is not very useful. The melt() function returns a more standard data frame result.
|
1 |
pd.melt(SGY, id_vars = ['Country']) |
You can see the output of the melt() function bellow:
| Country | variable | value | |
| 0 | Australia | 2010 | 2.090978e+04 |
| 1 | Canada | 2010 | 3.578270e+03 |
| 2 | Australia | 2011 | 2.563732e+06 |
| 3 | Canada | 2011 | 5.715718e+05 |
| 4 | Australia | 2012 | 2.128407e+06 |
| 5 | Canada | 2012 | 3.076045e+05 |
| 6 | Australia | 2013 | 4.339443e+06 |
| 7 | Canada | 2013 | 1.085633e+06 |
| 8 | Australia | 2014 | 8.507720e+03 |
| 9 | Canada | 2014 | 9.457620e+03 |
Finally, let me also rename the columns and sort the data.
|
1 2 3 4 |
SUO = pd.melt(SGY, id_vars = ['Country'], var_name = 'CYear', value_name = 'Sales').sort_values(by = ['Country', 'CYear']) SUO |
The next result is again in the form I wanted to achieve.
| Country | CYear | Sales | |
| 1 | Australia | 2010 | 2.090978e+04 |
| 2 | Australia | 2011 | 2.563732e+06 |
| 3 | Australia | 2012 | 2.128407e+06 |
| 4 | Australia | 2013 | 4.339443e+06 |
| 5 | Australia | 2014 | 8.507720e+03 |
| 6 | Canada | 2010 | 3.578270e+03 |
| 7 | Canada | 2011 | 5.715718e+05 |
| 8 | Canada | 2012 | 3.076045e+05 |
| 9 | Canada | 2013 | 1.085633e+06 |
| 10 | Canada | 2014 | 9.457620e+03 |
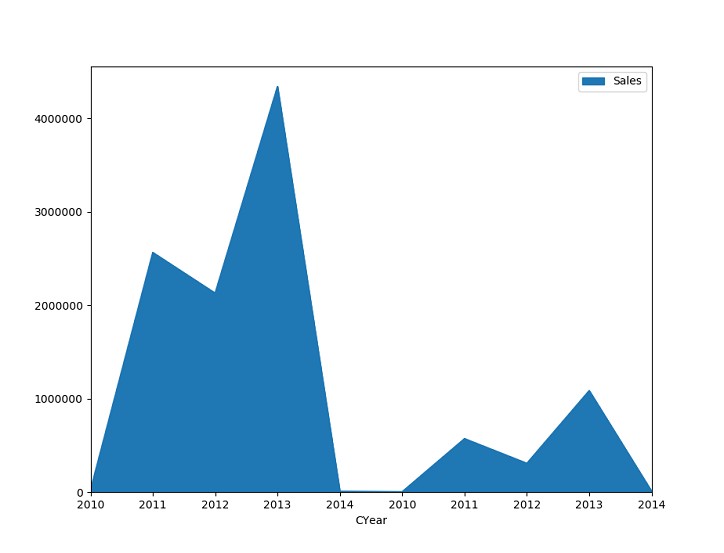
And for the last thing, let me show the sales over years for both countries together in a pandas area chart.
|
1 2 |
SUO.plot(kind = 'area', y = 'Sales', x = 'CYear') plt.show() |
The following figure shows the graph:
Conclusion
I am done with pivoting and unpivoting. However, I am not done with the data preparation yet. So far, I always had a dataset with known values only. What happens if there are NULLs in the data? Stay tuned for the forthcoming articles.
Table of contents
Downloads

View all posts by Dejan Sarka
- Data Science in SQL Server: Unpivoting Data - October 29, 2018
- Data science in SQL Server: Data analysis and transformation – Using SQL pivot and transpose - October 11, 2018
- Data science in SQL Server: Data analysis and transformation – grouping and aggregating data II - September 28, 2018