
In this article, we will give a brief introduction of Hadoop and how it is integrated with SQL Server. Then, we will illustrate how to connect to the Hadoop cluster on-premises using the SSIS Hadoop connection manager and the related tasks.
Introduction
As defined in their official website, the Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. This framework is composed of five main components:
- The Hadoop Distributed File System (HDFS): A file system used to store files in a distributed manner
- The Map-Reduce programming model: It allows processing massive data sets with a parallel and distributed algorithms on a cluster
- Hadoop YARN: It is responsible for managing cluster computing resources
- Hadoop Common: A set of shared libraries between all Hadoop components
- Hadoop Ozone: An object-store
Currently, Hadoop is the most known framework for building data lakes and data hubs.
Since Hadoop is open-source, many software packages are developed to be installed on the top of it, such as Apache Hive and Apache Pig.
Apache Hive is a data warehousing software that allows defining external table on the top of HDFS files and directories to query them using a SQL-like language called HiveQL.
Since writing Map Reduce scripts using Java is a bit complicated, Apache Pig was developed to execute Map Reduce jobs using a language called Pig Latin, which is more straightforward.
A few years ago, and due to the data explosion, relational database management systems started to adopt Big Data technologies in order to survive. The main goal was to create a bridge between the relational world and the new data technologies.
Regarding Microsoft SQL Server, since 2016, they added a bunch of features that make this management system adaptable by large enterprises:
- Polybase: A technology that enables SQL Server to query external sources such as Hadoop and MongoDB
- JSON support
-
Hadoop (on-premise) support in Integration Services:
- SSIS Hadoop connection manager
- Hadoop File System Task
- Hadoop Hive Task
- Hadoop Pig Task
- HDFS File Source
- HDFS File Destination
Note that, the Hadoop cluster hosted on the cloud (Azure) was supported since SQL Server 2012; HDInsight and other Microsoft Azure feature components were added to SSIS.
In this article, we will illustrate the SSIS Hadoop connection manager and the Hadoop File System Task hoping that the other tasks and components be explained in the future.
To run this experiment, we installed Hadoop 3.2.1 single node on a machine where SQL Server 2017 and Integration Services are also installed.
If you are looking to install Hadoop on Windows, I published a step-by-step guide to install Hadoop 3.2.1 single node on Windows 10 operating system on the “Towards Data Science” website.
SSIS Hadoop Connection Manager
To add an SSIS Hadoop connection manager, you should first right-click within the connection managers tab and click on “New Connection…”.
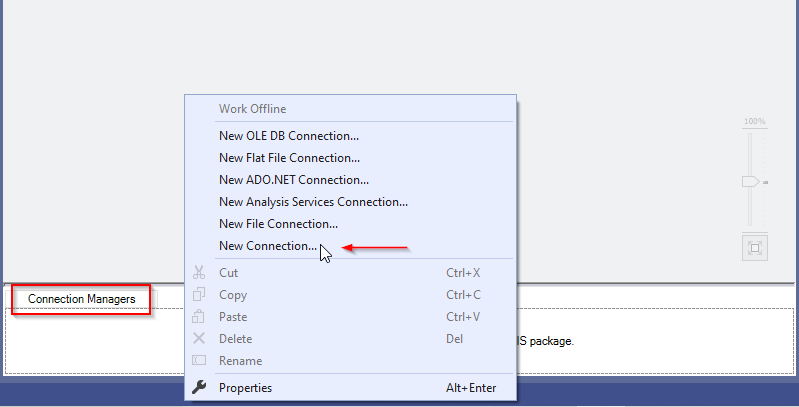
Figure 1 – Adding a new connection manager
Next, you should select Hadoop from the connection managers list:
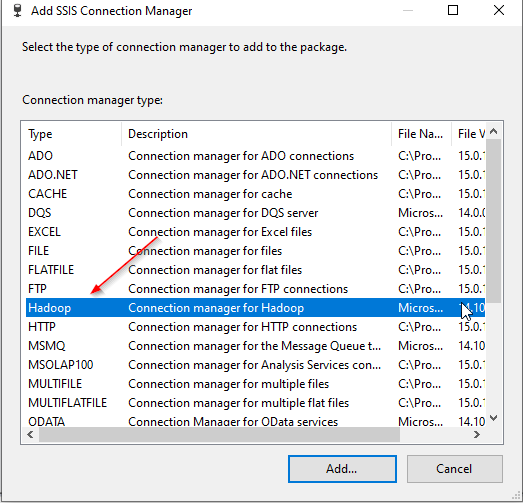
Figure 2 – Selecting SSIS Hadoop connection manager
As shown in the figure below, the SSIS Hadoop connection manager editor contains two tab pages:
- WebHCat: This page is used to configure a connection that invokes a Hive or Pig job on Hadoop
- WebHDFS: This page is used to copy data from or to HDFS
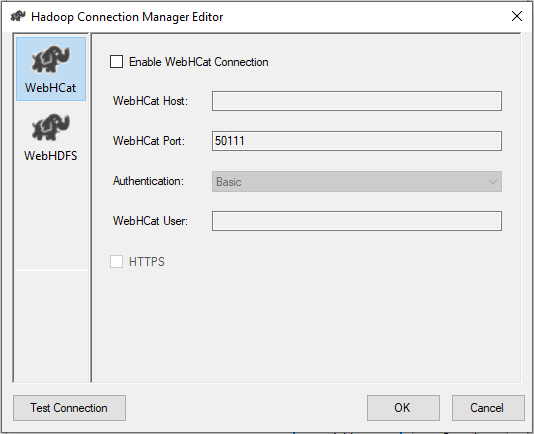
Figure 3 – SSIS Hadoop Connection manager editor
In this article, we will use this connection manager to copy data to HDFS. Then, we will only use a WebHDFS connection. Note that the Hadoop cluster web interface can be accessed on the following URL: http://localhost:9870/
To configure the WebHDFS connection, we need to specify the following parameters:
- Enable WebHDFS Connection: We must check this option when you will use this connection manager for HDFS related tasks, as mention above
- WebHDFS Server: We should specify the server that hosts the Hadoop HDFS web service
- WebHDFS Port: We should specify the port used by the Hadoop HDFS web service
- Authentication: We should specify the method for accessing the Hadoop web service. There are two methods available:
- Kerberos
- Basic
- WebHDFS User: We should specify the user name used to establish the connection
- Password (only available for Kerberos authentication)
- Domain (only available for Kerberos authentication)
- HTTPS: This option must be selected if we need to establish a secure connection with the WebHDFS server
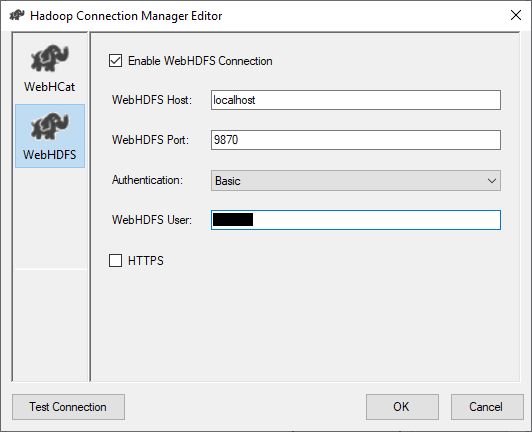
Figure 4 – Configuring WebHDFS connection
After finishing the configuration, we click on the “Test Connection” button to check if the connection is configured correctly.
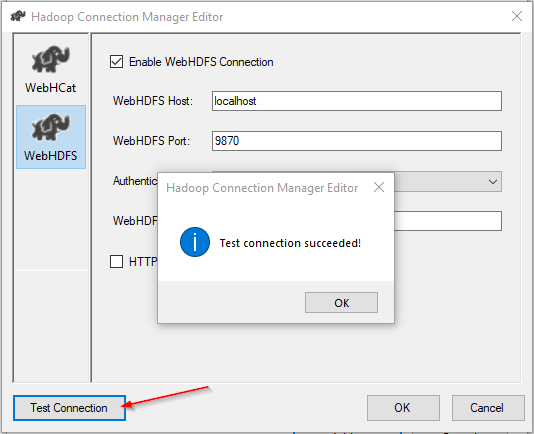
Figure 5 – Testing connection
Since we have configured a WebHDFS connection, we will test it using the SSIS Hadoop File System Task.
- Note: Configuring WebHCat connection is very similar, we will explain in a separate article where we will be talking about Executing Hive and Pig Tasks in SSIS
SSIS Hadoop File System Task
![]()
Figure 6 – Hadoop File System Task
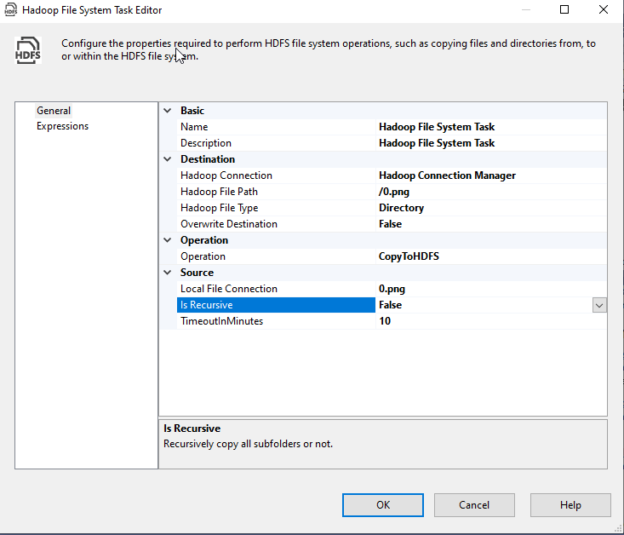
IF we open the SSIS Hadoop file system task editor, we can see that the properties are classified into four categories:
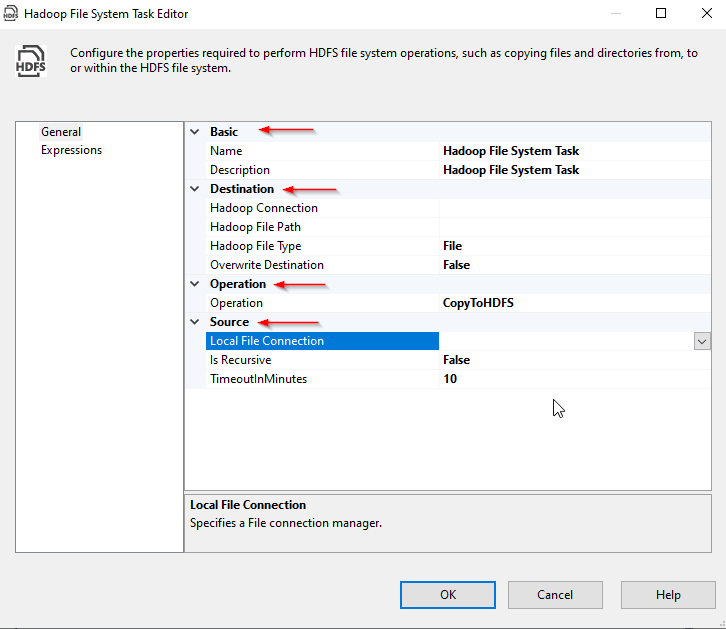
Figure 7 – Hadoop File System Task editor
- Basic: Contains the task name and description properties
- Source: The source (file/directory) configuration
- Destination: The destination (file/directory) configuration
-
Operation: The SSIS Hadoop File system task is used to perform one of the following operations:
- Copy data from HDFS to the local file system (CopyFromHDFS)
- Copy data from the local file system to HDFS (CopyToHDFS)
- Copy data within HDFS (CopyWithinHDFS)
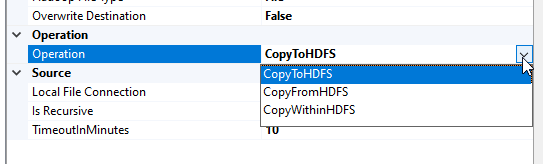
Figure 8 – Supported operations
The third operation (CopyWithinHDFS) only requires a Hadoop connection while the other requires an additional local file connection.
- Note:The source and destination properties are dependants on the operation type
We will not explain each property since they are all mentioned in the official documentation. Instead, we will run an example of CopyToHDFS operation.
Copy data to HDFS
In this section, we will copy a file into the Hadoop cluster. First, we need to add a File Connection Manager and configure it to read from an existing file, as shown in the screenshots below:
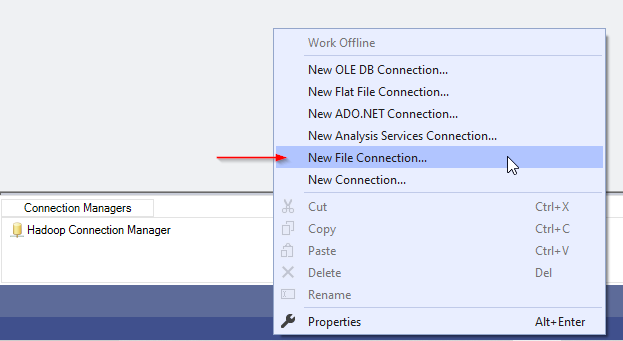
Figure 9 – Adding a File Connection Manager
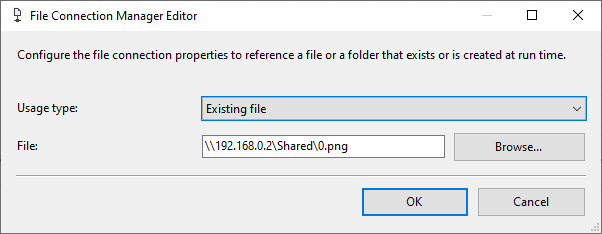
Figure 10 – Configuring File Connection to an existing file
Then we configured the Hadoop file system task as the following:
- Operation: CopyToHDFS
-
Destination:
- Hadoop Connection: We selected the Hadoop connection manager
- Hadoop File Path: /0.png (the file path should start with a slash “/”)
- Hadoop File Type: File
- Overwrite Destination: False
-
Source:
- Local File Connection: We selected the File connection manager
- Is Recursive: False (This should be set to true when the source is a folder and we need to copy all subfolders)
- TimeoutInMinutes: 10
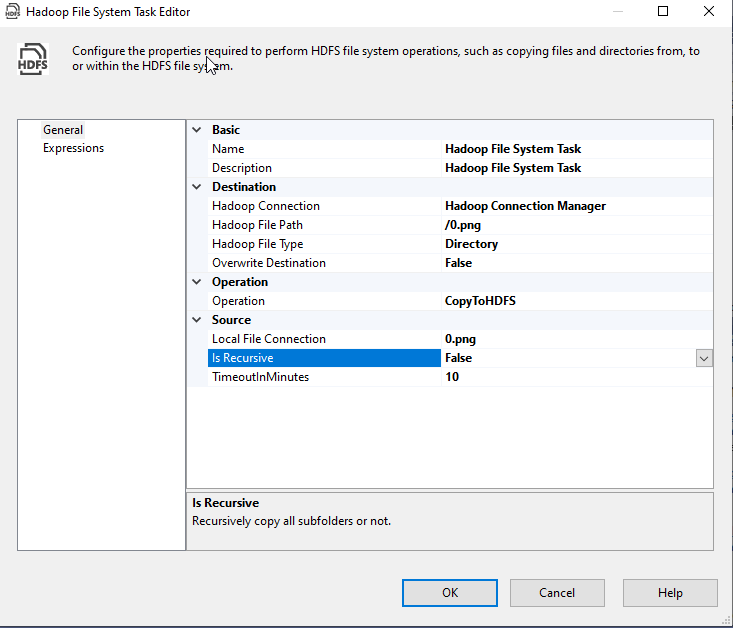
Figure 11 – Configuring CopyToHDFS operation
After executing the package, we will go to the Hadoop web interface to check if the file is transferred successfully.
As mentioned in the previous section, the web interface can be accessed from the following URL: http://localhost:9870/ (as configured in the Hadoop installation article).
In the web interface, in the top bar, Go to Utilities > Browse the File System.
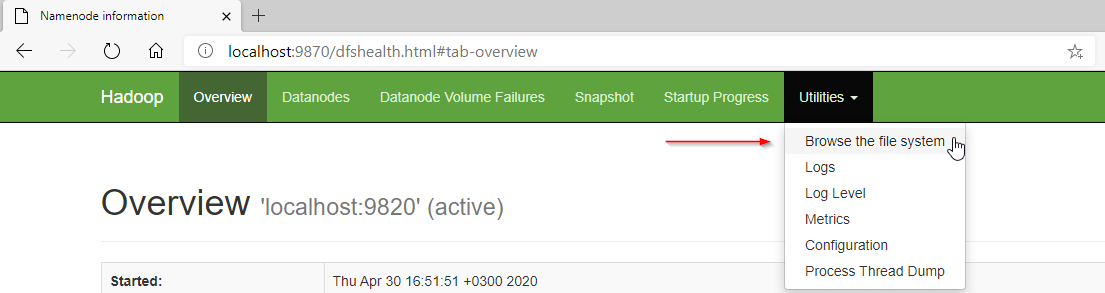
Figure 12 – Browsing the Hadoop file system from the web interface
Then we can see that 0.png is stored within HDFS main directory.
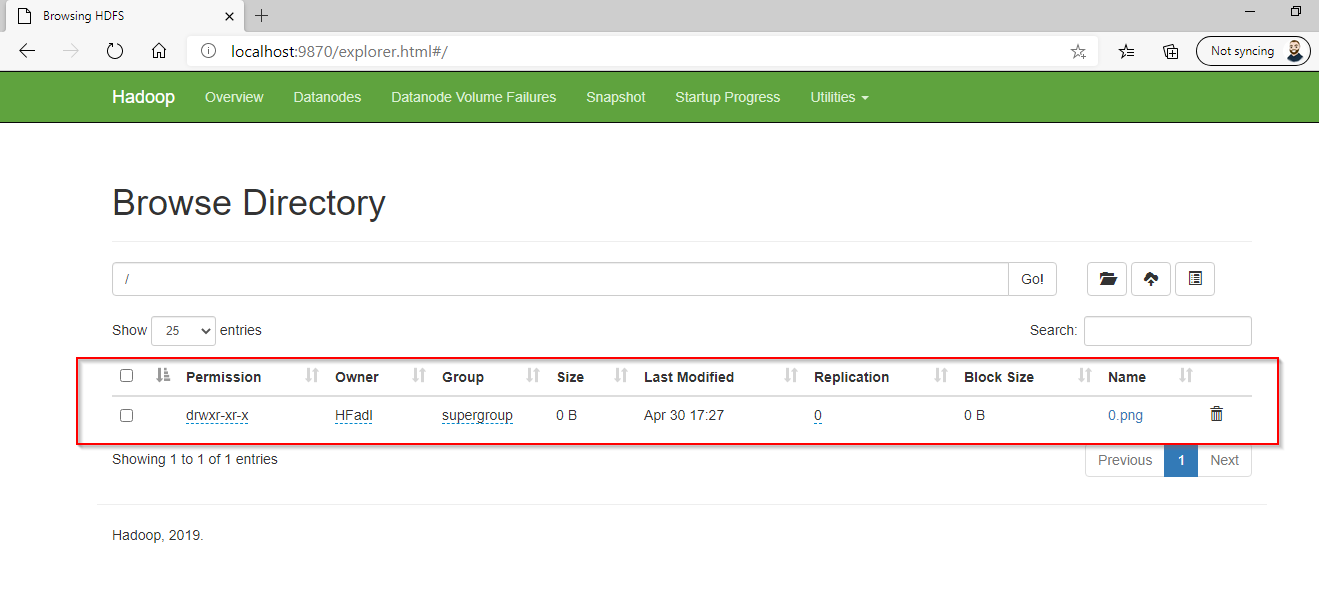
Figure 13 – File is located within HDFS main directory
Conclusion
In this article, we gave a brief overview of Hadoop and why relational data management systems adopted it. Then, we illustrated what the tasks and components added to SQL Server Integration Services (SSIS) are. We explained in detail how to use the SSIS Hadoop connection manager and Hadoop file system task. Finally, we ran an example of copying data from a local system file into the Hadoop cluster and how to browse the Hadoop file system from the web interface. We didn’t add examples of copying data within HDFS or into a local file since it is very similar.
Table of contents
| SSIS Hadoop Connection Manager and related tasks |
| Importing and Exporting data using SSIS Hadoop components |
| Connecting to Apache Hive and Apache Pig using SSIS Hadoop components |

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023