
My team and I were recently tasked with refactoring older data marts, particularly those that were created with SQL Server 2008 in mind. As we all know, SQL Server has undergone significant changes since the release of SQL Server 2008. One of those changes relates to the introduction of columnstore as an alternative to the traditional B-tree index (rowstore). Whilst most of the existing documentation relating to columnstore seem to focus on the benefit of columnstore against data warehouse workloads, in this article I argue that the usage of columnstore index should not be limited to facts and dimensions instead let’s introduce it in our data warehouse staging environments too.
Data Warehouse Staging Environment
The staging environment is an important aspect of the data warehouse that is usually located between the source system and a data mart. It is used to temporarily store data extracted from source systems and is also used to conduct data transformations prior to populating a data mart.

Figure 1
For demo purposes, the source data used in this article comes from a CustomerOrders sample database that I received after attending Uwe Ricken’s Johannesburg SQL Saturday Precon event. Figure 2 highlights the properties of the CustomerOrders table that will be used as source data – which is basically a heap table with 2 million rows.

Figure 2: Source table properties
A preview of CustomerOrders table is shown in Figure 3.

Figure 3
In order to demonstrate the benefits of columnstore in staging environment, we have to compare it against its rowstore counterpart, thus, our sample source data will be extracted into two staging databases; one that uses rowstore (SQLShack_RB) and the other using columnstore (SQLShack_CB). By default, the sizes of data and log files for the two databases are similar, as shown in Figure 4.
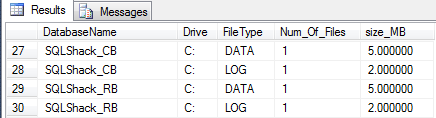
Figure 4
The two databases each have a table that will be used to store the source data. As shown in Figure 5, the table in the SQLShack_RB has a primary key (clustered index) whereas SQLShack_CB has a clustered columnstore index.

Figure 5
Data Warehouse Staging SSIS Packages
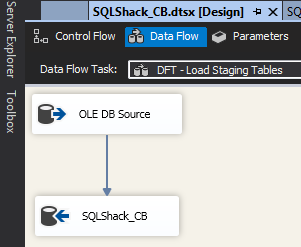
The source data will be extracted using SQL Server Integration Services (SSIS) package. Figure 6 shows a basic setup of the package that will be used – which simply uses a data flow task with an OLE DB source and destination components.
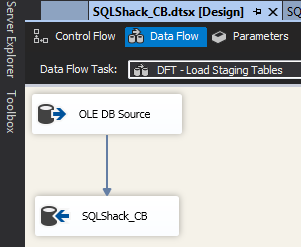
Figure 6
Data Warehouse Staging: Rowstore vs Columnstore
-
Data Extraction and Load
One of the differences that you will notice between rowstore and columnstore is in the total amount of time each packages would have taken to run. As shown in Figure 7, writing source data into the table with columnstore index took almost double the amount of time it took to load the rowstore staging table.

Figure 7: SSIS package execution results
Furthermore, as the data was being written into the two tables, I ran a SQL Server trace and the results of that trace are shown in Table 1. Table 1 basically provides a breakdown of what was happening in the backend as the two SSIS packages were executing. Evidently, writing data into the columnstore table generated more wait types, used more CPU and memory than writing to a rowstore staging table.
Database Wait types CPU reads writes Physical reads Used memory SQLShack_RB WRITELOG 84 36,709 235 0 627 SQLShack_CB WRITELOG , PREEMPTIVE_OS_WRITEFILEGATHER, PREEMPTIVE_OS_FLUSHFILEBUFFERS 14,179 3,424,278 17,103 40 28,654 Table 1
However, just because the columnstore SSIS package took longer to run is not necessary a bad thing. For instance, let’s try to simulate storing the first 3 rows shown Figure 3; the rowstore will write such data one page at a time and at the end the data will be stored as shown in Table 2. Columnstore, however, works differently as for every source column it allocate segments that are then used to store values of a given row into their respective segments as shown Figure 8.
Page 1 Id Customer_Id OrderNumber InvoiceNumber 1 74500 98043-GJND 2044-50211 2 25155 49524-BSHG 2046-98664 3 60970 98628-NUVG 2049-16668 Table 2: Typical rowstore data storage
The benefit of the columnstore approach is that data is organised according to data types thereby making it easier to compress.
Figure 8: Typical columnstore data storage
Now that we have an understanding of what happens when data is being written and stored into a columnstore, it is not surprising that the table using a columnstore index used half the disk space compared to its rowstore counterpart as shown in Figure 9.
Figure 9
-
Reading data out of the Staging tables
In addition to the reduced storage space, another benefit of columnstore index relates to the improved speed of reading data. For instance, let’s say the CustomerOrders data staged in the two staging databases is used to populate a fictitious FactOrders table. As part of loading FactOrders table, we need to look-up a list of invoice numbers that have so far been issued to a given customer. A T-SQL query that can be used obtain such a list against the rowstore staging table is shown in Script 1.
12345SELECT [InvoiceNumber]FROM [SQLShack_RB].[dbo].[STG_CustomerOrders_RB]WHERE Customer_id=29248Script 1
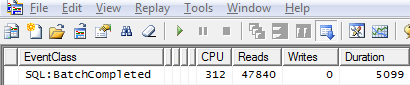
The results of tracing the execution of Script 1 are shown in Figure 10. You will notice that the Reads value of 47840 is almost similar to the used_pages value (47497) shown in Figure 9. This means that the entire rowstore staging table was scanned as part of returning the result set. Depending on the size of the table you are querying, conducting a full table scan is not ideal as it can consume lots of resources.
Figure 10
However, if customise the script shown in Script 1 so that it can be run against the columnstore staging table, we get the results shown in Figure 11. You can easily see that reading data out of the columnstore table took significantly lesser time, lesser CPU and read fewer pages compared to the output shown Figure 10.
Figure 11
Finally, just beware that an ideal scenario for querying columnstore tables is when you have filters in your query that results into retrieving values off a single column (i.e. Invoice Number). Conversely, the more columns you specify in your SELECT clause, the more pages would have to be read which means the longer the query will run. Thus, remember that columnstore is not a silver bullet to whatever issues you are having in your data warehouse environment; if you plan to replace rowstore staging tables with columnstore, you have to change the way you are reading data from staging tables.




Conclusion
In this article we have demonstrated that the data warehouse environment can benefit from columnstore indexing as it has several advantages over rowstore. Although it takes longer to write data into a staging environment, columnstore indexing uses less disk space and compresses database files in a manner that makes it convenient to later retrieve data out of that staging table.

Sifiso's LinkedIn profile
View all posts by Sifiso W. Ndlovu