
In the first part we started discussion about choosing the right table structure and described the heaps — in my opinion a mostly overused option. Now let’s see better alternatives.
Four different table structures — continued discussion
For years Microsoft has been trying to convince us that Enterprise edition is worth the additional money. For SQL Server 2014 this is even more true than it was previously. So, if you are lucky Enterprise Edition owner, you can adapt your database model to leverage unique features of this edition. It will make the design simpler and result in a better performance.
In order to improve structure of tables, SQL Server 2014 Enterprise Edition offers two interesting options: memory-optimized tables and clustered columnstore indexes.
Memory-Optimized Tables
Because the entire memory-optimized table resides in memory (the copy of it is stored on disk for durability only) and this kind of table has lock-free structures, it fits nicely into any logging scenarios. In other words, if you have a table used primary for logging, memory-optimized one should be your first choice.
Before a memory-optimized table can be created, a dedicated filegroup with a file (actually this file is a folder — Hekaton, the in-memory OLTP engine uses storage built on top on filetable feature) have to be added to a database (the script that creates this database can be found in the first article):
|
1 2 3 4 5 6 7 8 9 10 11 |
USE master; GO ALTER DATABASE Indices ADD FILEGROUP InMemoryOLTP CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Indices ADD FILE (name = 'InMemoryOLTP', filename = 'e:\SQL\InMemoryOLTP') TO FILEGROUP InMemoryOLTP GO |
Secondly, there are many limitations for the memory-optimized tables. Fortunately, they count for little in our scenario — logging tables usually don’t have foreign keys, check constraints or defined triggers. Still, there is one important exception — the memory-optimized tables don’t support distributed transactions. What is more, this kind of table cannot be altered in any way, drop and re-create excepted, and 1252 character set must be used for varchar or char columns (and come to that, if you want to put an index on varchar column, you will need a BIN collation. So, our table definition can look like this below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE dbo.InMemory( Id INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 100000), fixedColumns CHAR(200) COLLATE Latin1_General_100_CI_AS CONSTRAINT Col2InMemDefault DEFAULT 'This column mimics all fixed-legth columns', varColumns VARCHAR(200) COLLATE Latin1_General_100_CI_AS CONSTRAINT Col3InMemDefault DEFAULT 'This column mimics all var-legth columns', ) WITH (MEMORY_OPTIMIZED=ON); |
If we insert once again the same 100000 rows into the memory-optimized table, in spite of using 50 of concurrent sessions (the same methodology was used to load data into the heap) the average time will drop from 18 seconds to 10.
However, this improvement has its price — we have to have enough memory to store all of these rows in it:
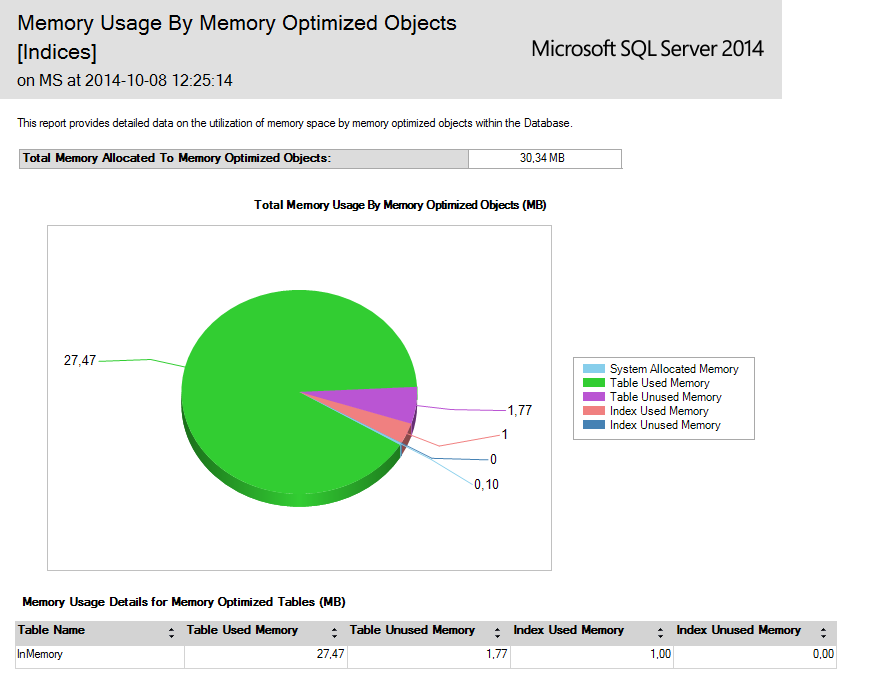
Now let’s do our UPDATE test. Again, we will update some rows with the aid of SQLQueryStress using five concurrent sessions and two queries — first one is the UPDATE statement and the second one is a simple parameter substitution:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
UPDATE dbo.InMemory SET varColumns = REPLICATE('a',200) WHERE id % @var = 0; SELECT 9 AS nr UNION SELECT 13 UNION SELECT 17 UNION SELECT 25 UNION SELECT 29; |
For the heap, SQL Server updated about 800 rows per second. The memory-optimized table, with more than 50 000 updates per second, it’s completely different story. Now, I would like to draw your attention to the fact that the rows are not stored in pages any more so there are no side effects like forwarding pointers in heaps.
With DELETEs, the space which was used by deleted rows will be reclaim by background process (by the way, this process is integrated with index scans, so this space can be recover even quicker). Therefore, also in this aspect memory optimized tables are better than heaps.
In summary, memory-optimized tables are great for logging, if only we have enough free memory to store the whole table in it.
Columnstore indexes
The second scenario in which heaps are traditionally being used is staging. The classic example is like this: to speedup data loading and avoid fragmentation, new data is loaded into an empty heap, and later this heap is switched into destination table as its last non-empty partition. This procedure is well-defined and worldwide proofed.
However, if your server is not CPU constrained (most of them are not) but the I/O is its bottleneck (as it is in most cases) maybe you should revalue this strategy. The main idea is that compression (or uncompression) data on the fly, is more efficient than copy it in uncompressed state and apply compression afterwards.
The new approach, dedicated to SQL Server 2014 Enterprise Edition, can be implemented with clustered columnstore indexes — first, they are finally read-write, second, they can be partitioned.
To demonstrate this concept, we will need a partition function and a partition scheme:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE PARTITION FUNCTION PF_CS (int) AS RANGE RIGHT FOR VALUES ( 1,100000,200000); GO CREATE PARTITION SCHEME PS_CS AS PARTITION PF_CS ALL TO ([PRIMARY]); GO |
To keep this example as simply as possible the partitioning function was defined for identity column. And the third table definition was slightly adjusted, just to simplify inserting rows into the third partition:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE dbo.CS( id INT IDENTITY(100000,1), fixedColumns CHAR(200) CONSTRAINT Col2CSDefault DEFAULT 'This column mimics all fixed-legth columns', varColumns VARCHAR(200) CONSTRAINT Col3CSDefault DEFAULT 'This column mimics all length-legth columns') ON PS_CS (id); GO |
Finally, let’s convert this table into columnstore index by executing following statement:
|
1 2 3 4 5 6 |
CREATE CLUSTERED COLUMNSTORE INDEX IX_CS ON dbo.CS; GO |
This allows us to insert the same rows using exactly the same INSERT INTO … DEFAULT VALUES statement as for inserting rows into the heap and into the memory-optimized table. This time execution of 2000 inserts with 50 concurrent sessions took 11 seconds, so slightly longer than for the memory-optimized table but still about 40% faster than for the heap.
And without any additional work, such as adding constraints or switching partitions, we have already achieved our goal — the new data was loaded into the right partition:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT $partition.PF_CS(id) AS 'Partition Number' ,min(id) AS 'Min Value' ,max(id) AS 'Max Value' ,count(*) AS 'Rows In Partition' FROM dbo.CS GROUP BY $partition.PF_CS(id); ____________________________________________________________________________ Partition Number Min Value Max Value Rows In Partition 3 100000 199999 100000 |
One more time, the UPDATE’s performance was measured with execution of the same statement in 5 concurrent sessions. This time SQL Server updates about 7 thousand rows per second — more or less 8 times faster than for the heap but 7 to 10 times slower than for the memory-optimized table.
But what about reclaiming unused space? In SQL Server 2014 columnstore indexes use two different storages — columnar data is still read-only, so all changes are located into row-based delta storage. Both storages are automatically used by SQL Server to satisfy queries, so you will always have the actual data, but space used by deleted rows will not be reclaim automatically:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
EXEC sp_spaceused 'CS' DELETE dbo.CS WHERE id % 31 = 0; EXEC sp_spaceused 'CS' GO ____________________________________________________________________ name rows reserved data index_size unused CS 100000 1240 KB 1208 KB 24 KB 8 KB CS 96774 1240 KB 1208 KB 24 KB 8 KB |
To get back this space the columnstore index has to be rebuilt. Unfortunately, this operation cannot be done online:
|
1 2 3 4 5 6 7 8 9 10 |
ALTER INDEX IX_CS ON [dbo].[CS] REBUILD WITH (ONLINE=ON); ____________________________________________________________________________ ALTER INDEX REBUILD statement failed because the ONLINE option is not allowed when rebuilding a columnstore index. Rebuild the columnstore index without specifying the ONLINE option. |
Due to the fact that this table was partitioned, all you need is to rebuilt only one partition, so the downtime can be minimized:
|
1 2 3 4 5 6 7 8 9 10 |
ALTER INDEX IX_CS ON [dbo].[CS] REBUILD PARTITION = 3; EXEC sp_spaceused 'CS' ________________________________________________________ name rows reserved data index_size unused CS 96774 448 KB 344 KB 0 KB 104 KB |
To sum up — clustered columnstore indexes can not only greatly simplify data load but also speed up this process.
What is coming next?
All the next parts of this series will be dedicated to b-tree, clustered and nonclustered, indexes. In the upcoming article we will finish our debate about choosing the right table structure. And if you find that the clustered index is the best option, then I will strongly recommend to evaluate with me all the plus points of nonclustered indexes.

A consultant, lecturer, authorized Microsoft trainer with 15 years’ experience, and a database systems architect. He prepared Microsoft partners for the upgrade to SQL Server 2008 and 2012 versions within the Train to Trainers program.
A speaker at numerous conferences, including Microsoft Technology Summit, SQL Saturday, Microsoft Security Summit, Heroes Happen {Here}, as well as at user groups meetings. The author of many books and articles devoted to SQL Server.
View all posts by Marcin Szeliga
- Index Strategies – Part 2 – Memory Optimized Tables and Columnstore Indexes - October 30, 2014
- Index Strategies – Part 1 – Choosing the right table structure - October 6, 2014