
In this article, we will learn how to interpret an execution plan of a SQL Server insert statement.
Introduction
When we execute an insert statement, the database engine performs tons of work in the background. Query execution operations, an internal data page, memory, and logging activities are performed by the SQL Server database engine. Consequently, performing an insert statement is a very complicated operation, and also its query plans are very different than the select statements. SQL Server query optimizer generates an execution plan for every query which is also true for insert statements. Understanding an SQL Server insert statement execution plan will help us to understand what the SQL Server is dealing with in the background during the execution of an insert statement.
First Look: Execution Plan of the SQL Server Insert statement
As we just mentioned above, execution plans are very helpful to understand what is going on behind the scenes during the execution of a query. Now, we will take a glance at the straightforward insert statement query plan. At first, we create a Product table through the following query.
|
1 2 3 4 5 |
CREATE TABLE Customer ( CustomerId INT PRIMARY KEY IDENTITY(1, 1), CustomerName VARCHAR(100)); |
In order to enable the actual execution plan of the query, we click the Include Actual Execution Plan button on the SQL Server Management Studio (SSMS) tab.

Now, we execute the following query and its actual execution plan will be shown in the Execution plan tab.
|
1 |
INSERT INTO Customer (CustomerName) VALUES ('Customer 1') |
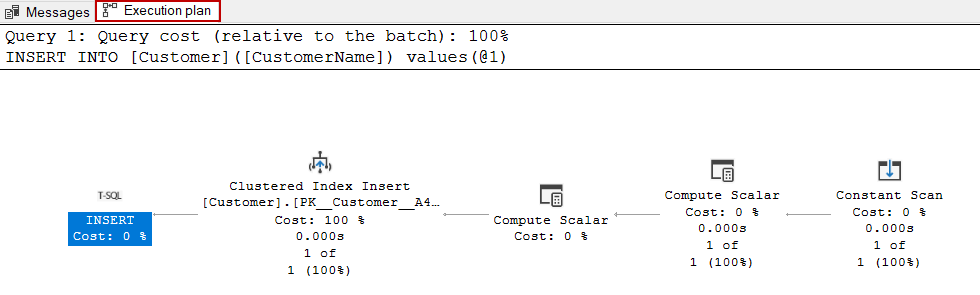
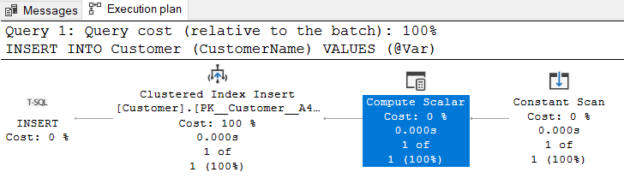
As we can see, the query optimizer generates a very simple execution plan for the insert statement. As a practice, the graphical execution plans can begin to read top to bottom and right to left. However, if we take a glance into the INSERT operator, it gives some general information about the SQL Server insert statement. For example, MemoryGrantInfo attribute gives information on how much memory is used by the query and OptimizerHardwareDependentProperties shows the hardware and configuration settings when generating the execution plan.
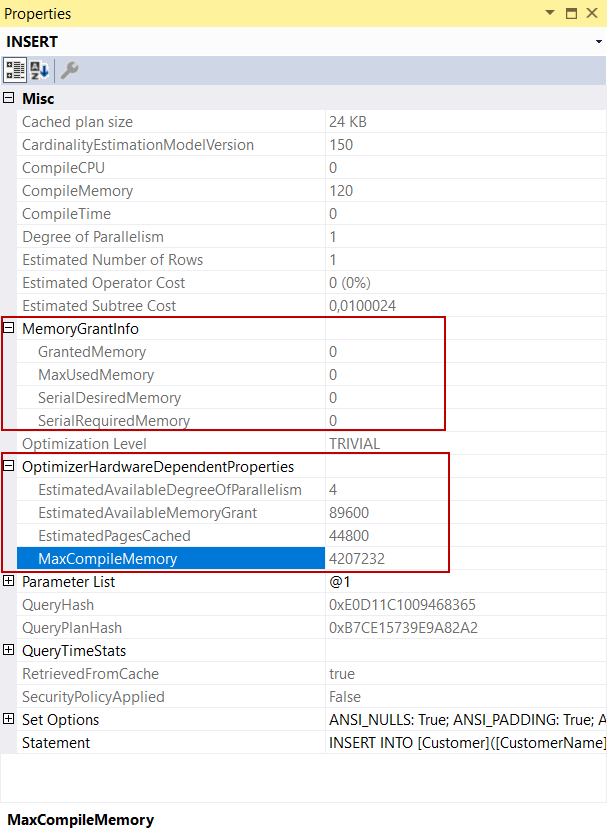
The Estimated Subtree Cost is calculated by the query optimizer and shows the cost of the query. This value directly affects which execution plan will be used for the execution of the query. Our sample SQL Server insert statement is very simple so its calculated cost is very low. Under this circumstance, the query optimizer decided on a TRIVIAL query plan. The query optimizer uses trivial execution plans when a query is pretty simple so that it skips several optimization phases and avoids consuming more time during the generation of a query plan.
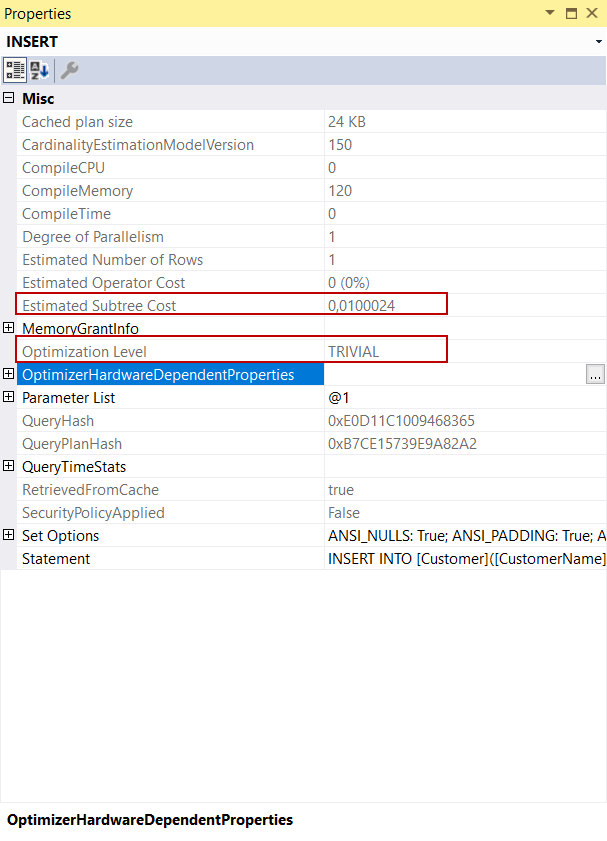
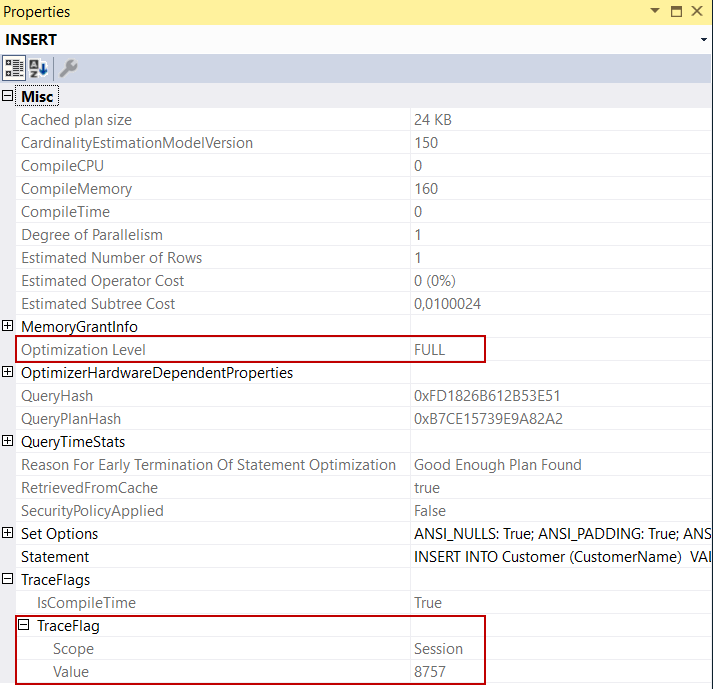
- Tip: The trace flag 8757 forces the query optimizer to perform all query optimization phases. When you analyze the following query execution plan the Optimization Level attribute shows as FULL. It means that all query optimization phases are performed
|
1 2 3 |
INSERT INTO Customer (CustomerName) VALUES ('Customer 1') OPTION ( QUERYTRACEON 8757 ); |
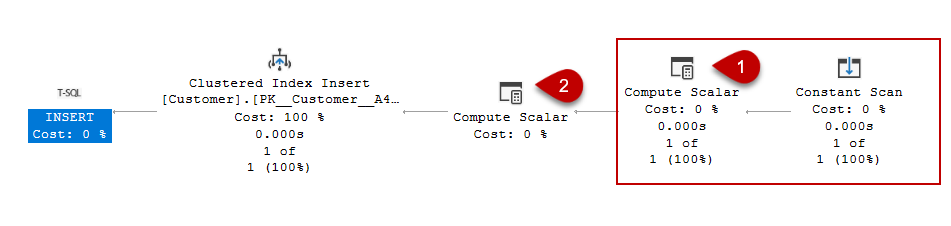
Now let’s try to understand all operator’s tasks on the execution plan beginning from the right to left.
Constant Scan Operator
Constant Scan Operator is a very interesting operator because its Output List attribute is empty so we can think it returns nothing to the next operator. However, this case is not completely true because it generates at least one row and passes it into the next operator. This type of row will never be used in the queries, it can only exist in intermediate phases in an execution plan because it has zero columns. When we look at the Actual Number of Rows attribute of the constant scan operator, we can notice this single row.
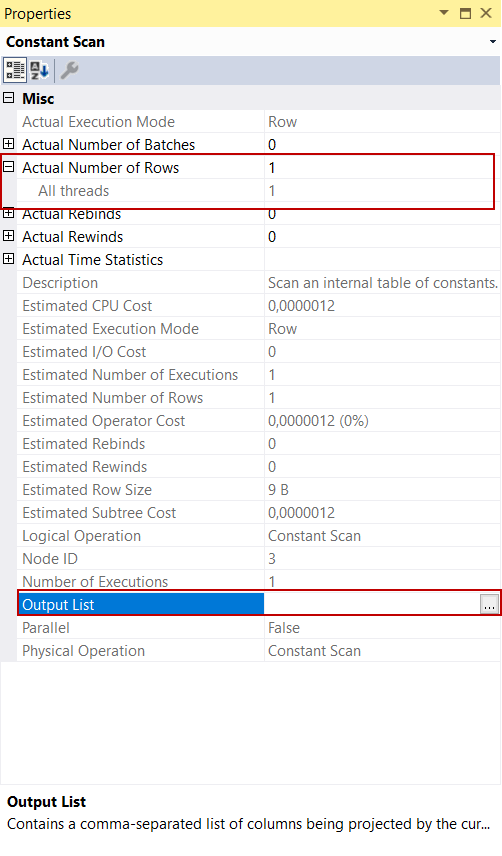
Sometimes the constant scan operator is confused with the table scan operator but a constant scan has minimal impact on the performance of the queries. In spite of that, the table scan operator reads all data from a table, and sometimes it dramatically decreases the performance of the queries.
Compute Scalar Operator
Compute scalar operator calculates a new value using a scalar computation function. As the next step, the calculated values are sent to the next operator with an extra output column(s). Compute scalar operator needs an input row to perform its calculation therefore we see the constant scan operator and compute scalar operator computation in the insert query execution plan. The constant scan operator generates an empty row, then the compute scalar performs the calculation, and adds a new column to store the calculated values.
Now let’s see what the compute scalar operator with number one calculates: We expand the Defined Values attribute to see its sub-attributes of it. The FunctionName sub-attribute identifies the name of the function and ScalarOperator shows parameters of the function.
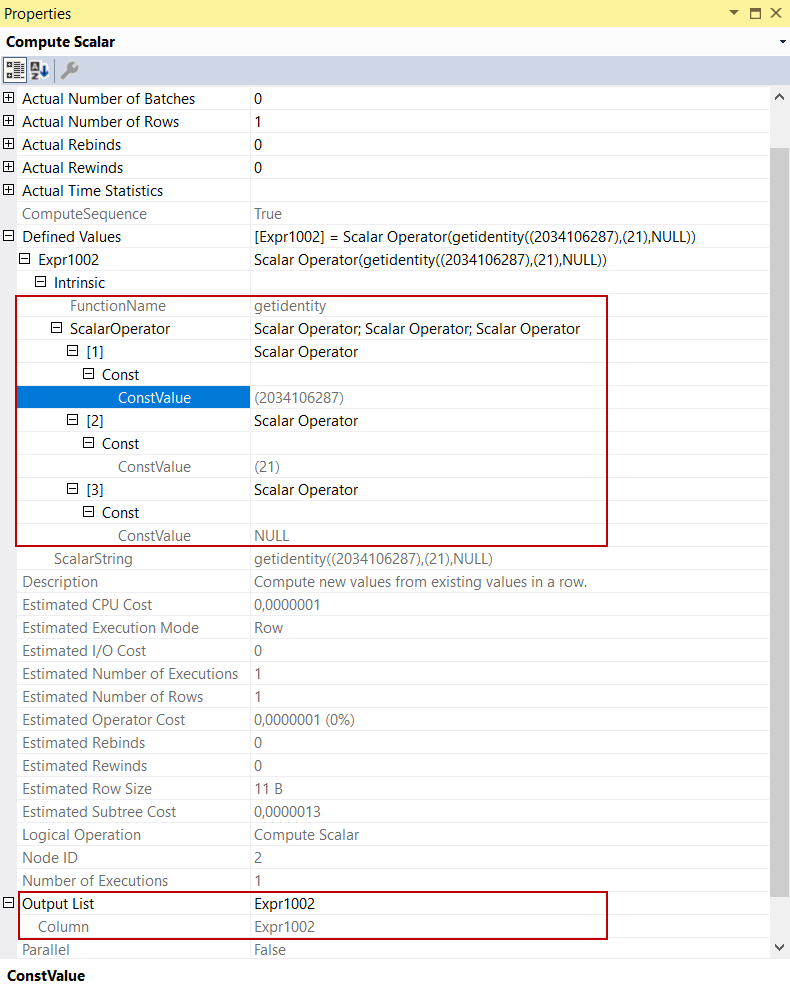
As we can see, the function name is getidentity and it takes 3 different parameters. In the definition of the table, we had declared an identity property for the CustomerId column, for this reason, the getidentity function calculates the next identity value for this column and passes this value to the second compute scalar operator. The first parameter of the getidentity function is the object id of the table. When we inquire about this object id on the sys.objects table, it will return the name of the table and the other ones are also required to find the last identity value.
|
1 |
SELECT * FROM sys.objects where object_id=2034106287 |
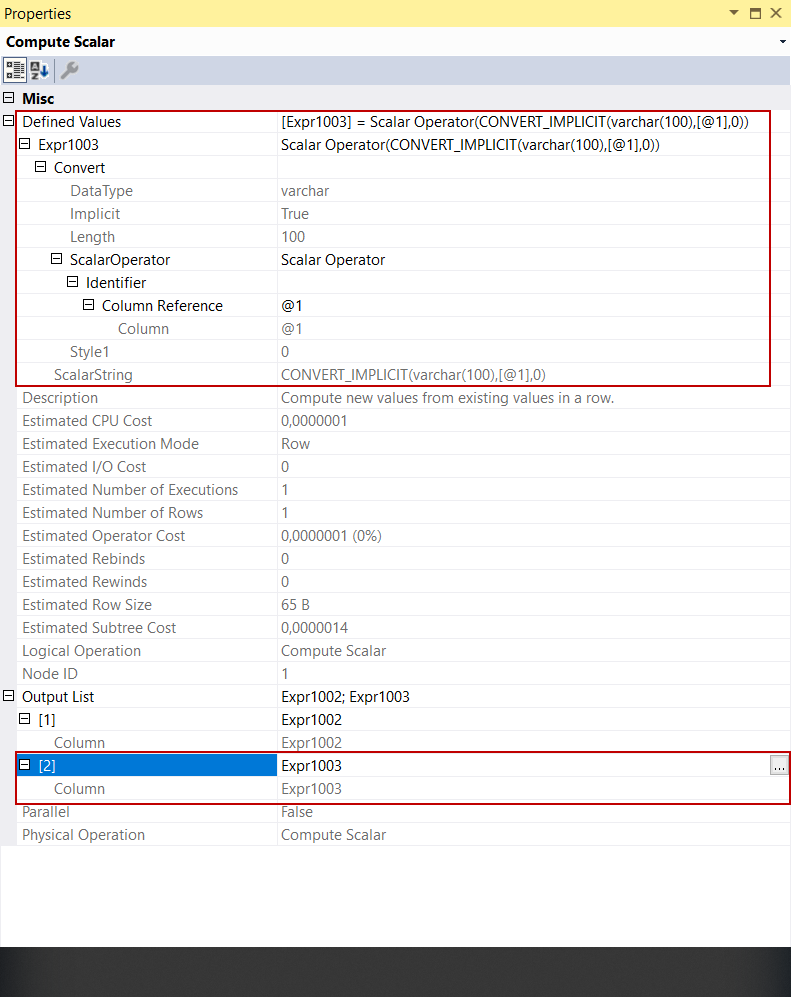
The Output List attribute shows the Expr1002 column and this column has been added by compute scalar operator.
For some cases, SQL Server needs data conversion and it makes this conversion automatically without seen by the users. This data conversion is called an implicit conversion. The second compute scalar operator task is to implicitly convert the insert value into the CustomerName column type. This column type is varchar so the “Customer 1” expression is converted into this type. This converted value is inserted into a new column named Expr1003.
- Tip: To avoid this type of implicit conversion, we can explicitly convert the values into the column type. For the following query, we can not see any implicit conversion
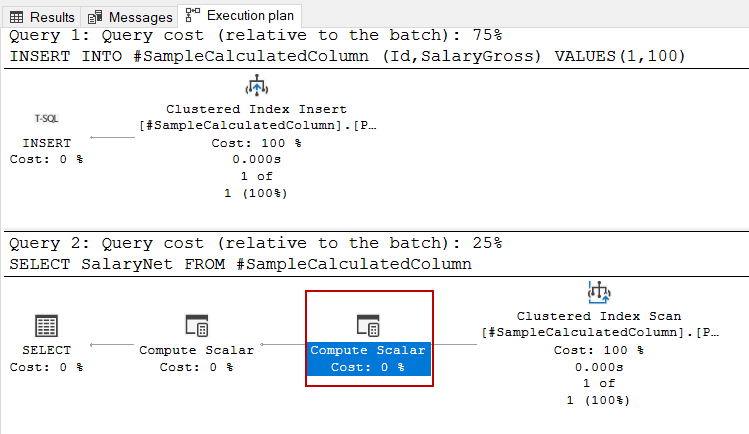
- Tip: Computed columns are the virtual columns and their values are calculated and displayed from other values in the table. When we declare non-persisted computed columns in a table and retrieve data from the computed columns, we can see the compute scalar operators in query plans. For example, when we examine the query plan below, we can notice the compute scalar operators
- The constant scan operator creates an empty row and passes it to the next operator
- The compute scalar operator calculates the last identity value and adds a new column to its output
- The compute scalar operator performs an implicit conversion and converts the hardcoded value to column data type
- The Clustered index Insert operator inserts a new row into the clustered index
- Final operator
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023
|
1 2 3 4 |
DECLARE @Var VARCHAR(100) SET @Var='Customer 1' INSERT INTO Customer (CustomerName) VALUES (@Var) |
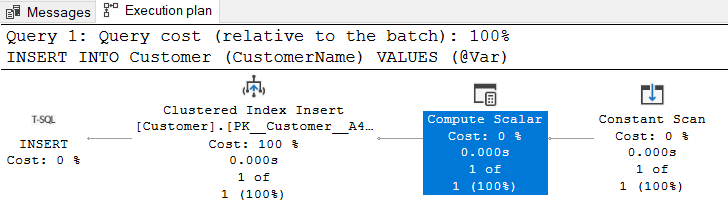
The query optimizer does not require and second compute scalar operator because it knows the inserted valued data type in the runtime.
|
1 2 3 4 5 6 7 |
CREATE TABLE #SampleCalculatedColumn (Id INT PRIMARY KEY, SalaryGross Float, SalaryNet AS (SalaryGross*0.72) ) INSERT INTO #SampleCalculatedColumn (Id,SalaryGross) VALUES(1,100) SELECT SalaryNet FROM #SampleCalculatedColumn |
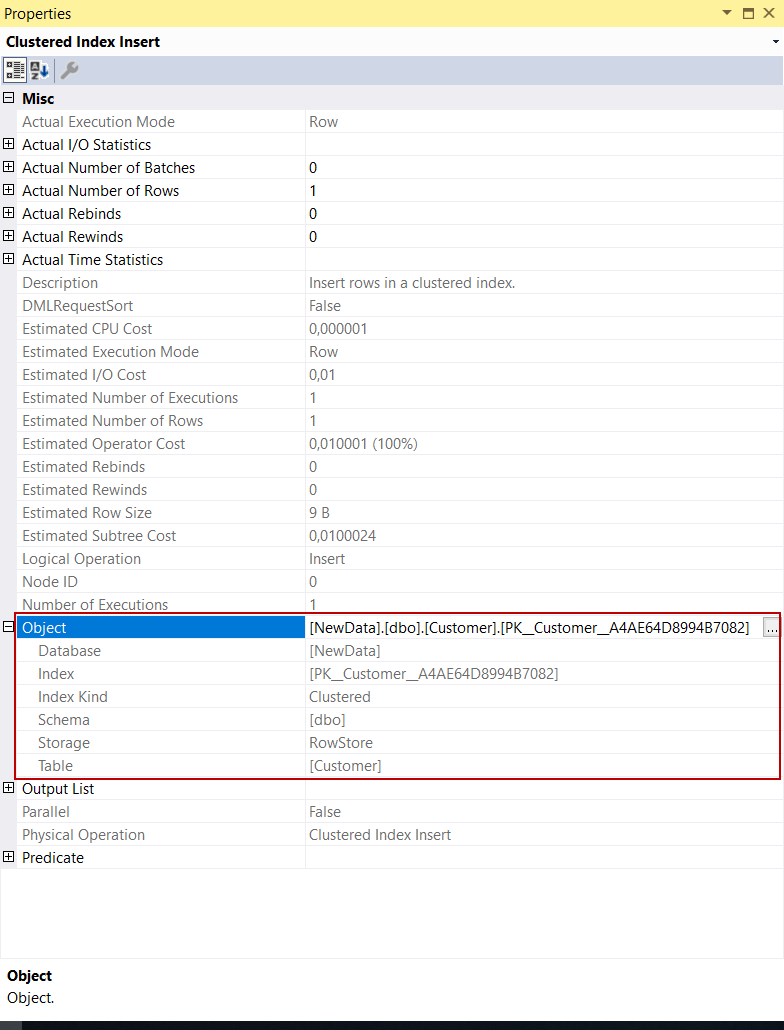
Clustered Index Insert Operator
The task of the clustered index insert operator is to insert rows into a clustered index. The index name shows in the Object attribute.
Join Up the Dots
After learning the task of each operator separately, join the parts together and interpret the execution plan.
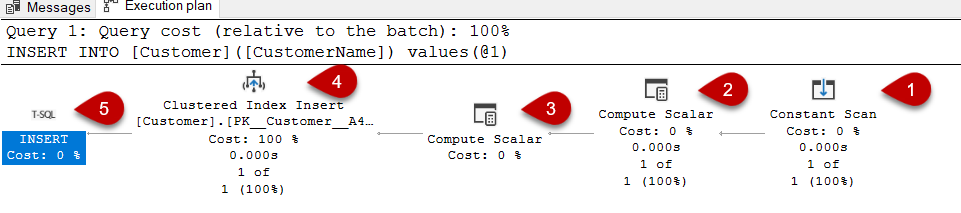
Along with these operations, SQL Server has automatically started a transaction write the data into the log buffer. If the SQL Server insert statement is completed successfully it writes data into the log files and then data files.
Conclusion
In this article, we have analyzed an SQL Server insert statement execution plan with all aspects. As we learned, a database engine performs tons of operations when we execute an insert statement.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec