
In this article, I am going to discuss the various ways in which we can use Pandas in python to export data to a database table or a file. In my previous article Getting started with Pandas in Python, I have explained in detail how to get started with analyzing data in python. Pandas is one of the most popular libraries used for the purpose of data analysis. It is very easy and intuitive to use. Personally, I love using the library due to the ease of use and the great documentation that is available online.
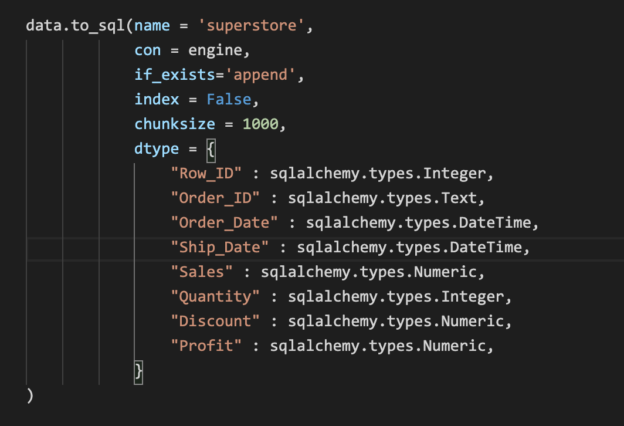
You can install it on your machine by running the command below. It is covered under the BSD license, so you can use it for free. The only dependency is that you must have a version of python running on your machine prior to installing the library.
pip install pandas
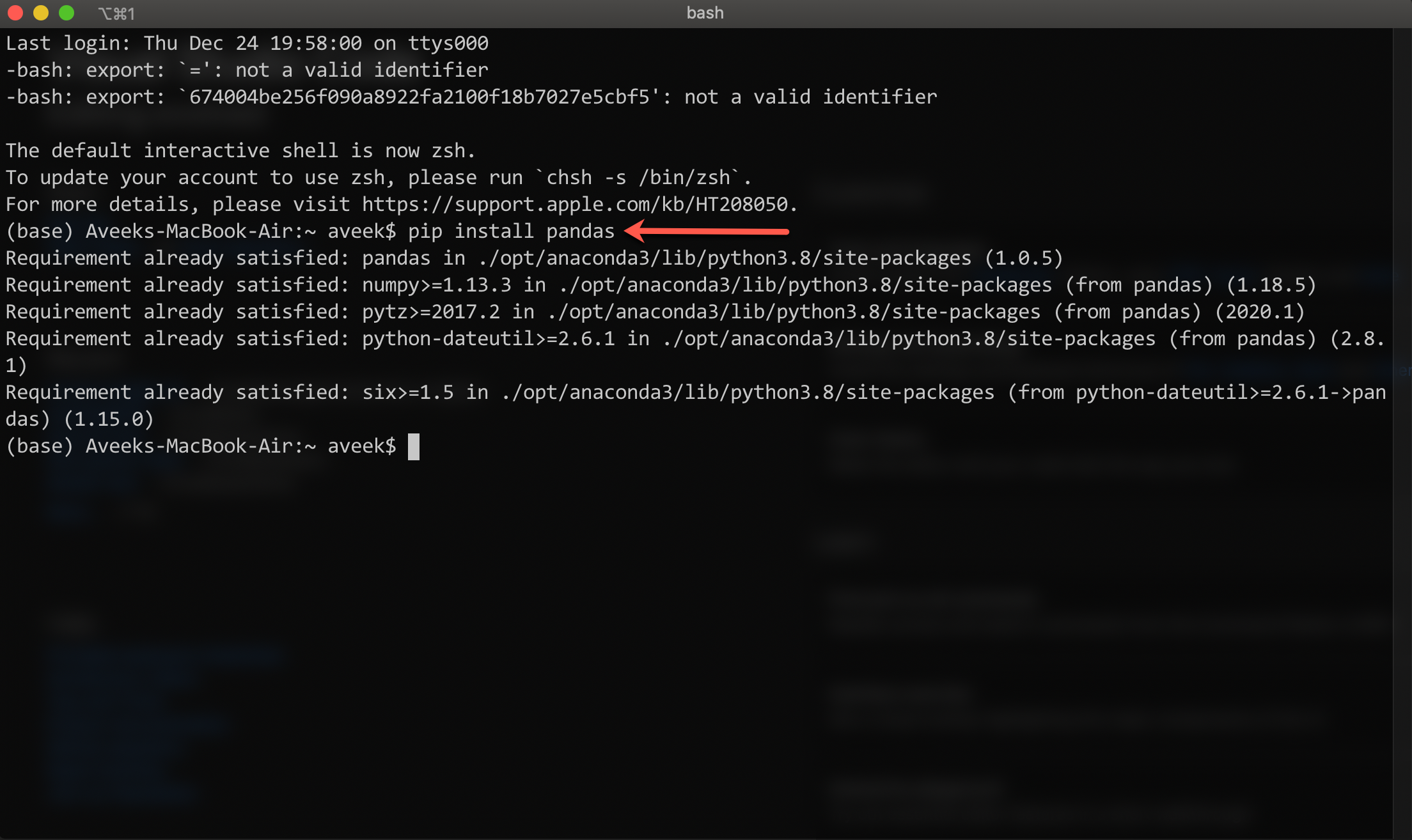
Figure 1 – Installing the library
Once you have installed the library, you can check the version that has been installed by running the command below.
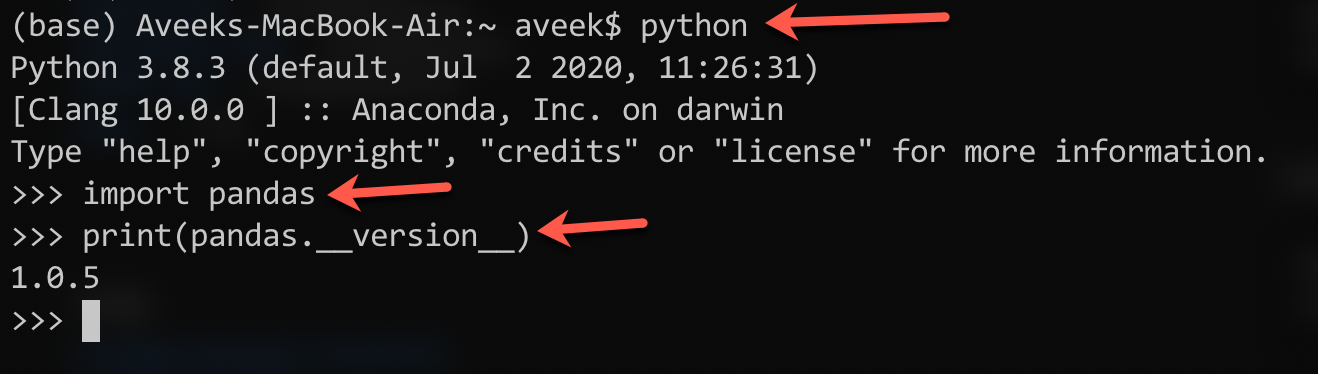
Figure 2 – Checking the version of the library
Exporting data from Python using Pandas
While working on any application, it is often a requirement that you would need to export your data from the python application to a data store such as a database or a flat-file. This data can then be read by other services in downstream. In one of my previous articles Exploring databases in Python using Pandas, I have explained about reading data from database and files using pandas and this article can be considered as a continuation of the previous one. I am assuming that you have already started exploring databases and now created a data frame within your application.
When we talk about exporting data from python, especially pandas, it heavily relies on another library called sqlalchemy. Sqlalchemy has been around for quite a long time now and is considered one of the most reliable enterprise-wide ORM for pythonic applications. Using this library, you can implement a lot of database-related activities just by writing a few lines of code. Sqlalchemy supports a wide range of databases like SQLServer, Oracle, MySQL, PostgreSQL etc. To learn more about Sqlalchemy and not it works, you can read the official documentation from here. In this article, we will also leverage this library as we are working with pandas and it requires the sqlalchemy library to interact with the databases.
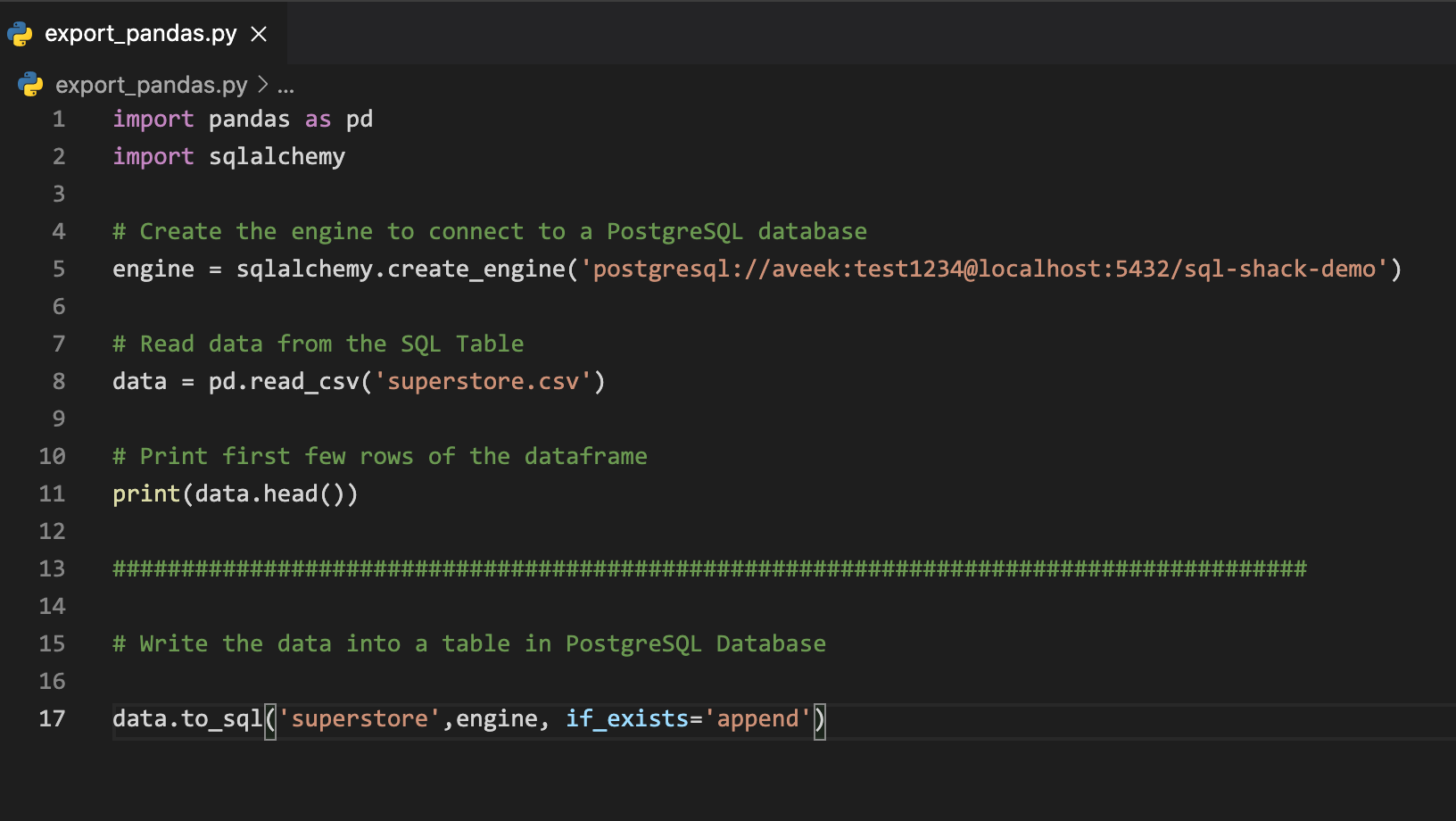
Figure 3 – Importing and exporting data from pandas dataframe
Once you execute the above script, the data will be read from the CSV file mention in the program and stored in a data frame. Then it is exported to a table in the PostgreSQL table and it can be verified by browsing the database using PGAdmin – a web-based GUI tool to manage PostgreSQL database servers.
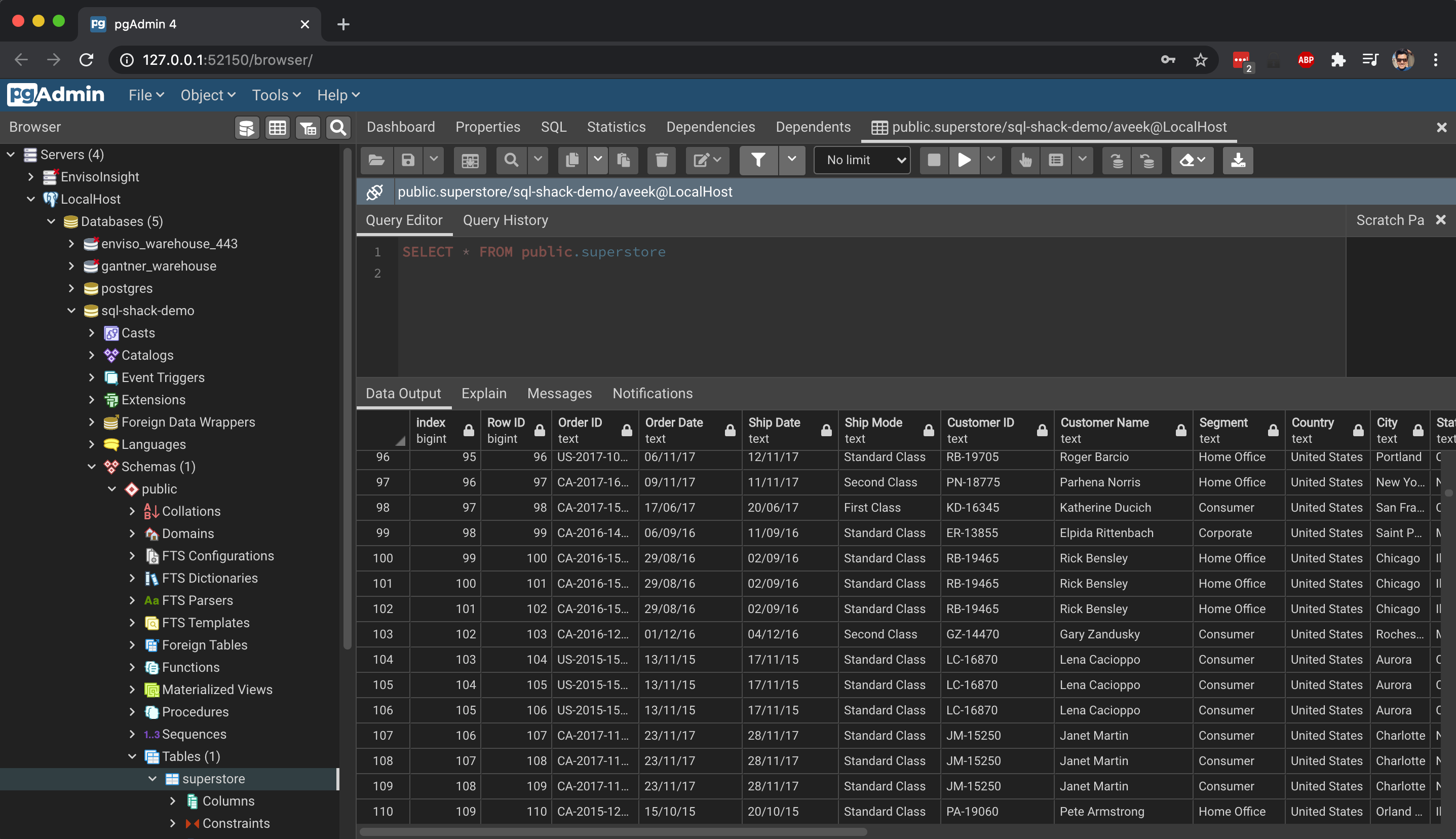
Figure 4 – Data inserted into the table
As you can see in the figure above, the data is now available in the PostgreSQL database. This was done using the to_sql() method of the dataframe class in Pandas. Let us learn more about this method and the parameters in detail.
Understanding the to_sql() method and parameters
Now that we have some idea on how to export data into database tables using the to_sql() method, let us learn what are the different parameters that can be provided to this method and what those parameters actually mean. If you see the sample code above, you might notice that I have used only three parameters, of which two are mandatory.
- name : This is a required parameter. It defines the name of the table to which the data from the dataframe is supposed to be written. By default, it will create a new table, however, this behavior can be changed by specifying the if_exists parameter which we will see in a while
- con : This is also another required parameter. It is a sqlalchemy.engine connection object which defines the connection to the database server. If this parameter is not defined correctly, in that case, there would be no connection made to the database and hence no data would be written to the database table
- if_exists : This is an optional parameter that tells the system what to do in case the table name specified in the first parameter already exists. By default, the value is set to be “fail”, which means you will get an error if the table is already present in the database. Other values accepted by this parameter are “replace” and “append”, which drops and recreates the table and the latter adds records in the same table respectively
- index : This is a Boolean optional parameter that is set to True by default. When data is loaded into a dataframe, an index is assigned to each of the records. So, when the data is exported to a database table or a flat file, this parameter is used to define if the index value is also exported along with the data. If the value for this parameter is set to False, then the index column is not exported
- index_label : This is also an optional parameter using which you can set the name of the index column if it is being exported. By default, the name of the index column is “index” itself
- chunksize : This is an optional integer parameter. It takes integer values and defines how many records are to be written to the database in a batch. By default, all the values in the dataframe are exported at once. This is a useful feature if your dataframe is very large, usually more than a million, and you do not want to place a heavy load on your system by inserting all the records at once. In such a case, you can define the parameter as “10000”, which will ensure that data is written to the database tables in batches of 10000 each
- dtype : This is an optional parameter which takes a dictionary or a scalar value as a parameter. In case you want greater control over your column names and data types and want to set those explicitly, you are recommended to use this parameter. If you define the values as a dictionary, then the keys in the dictionary will be the column names and the values will be the datatypes. The datatypes for the columns that you will define in this parameter are imported through sqlalchemy.types module. Please see the sample in the next section for a better understanding
- method : This is an optional parameter that takes in the following values
- None : This is the default value set that uses the standard SQL insert statement to insert records one row at a time
- multi : This parameter is used to pass multiple values to the insert clause
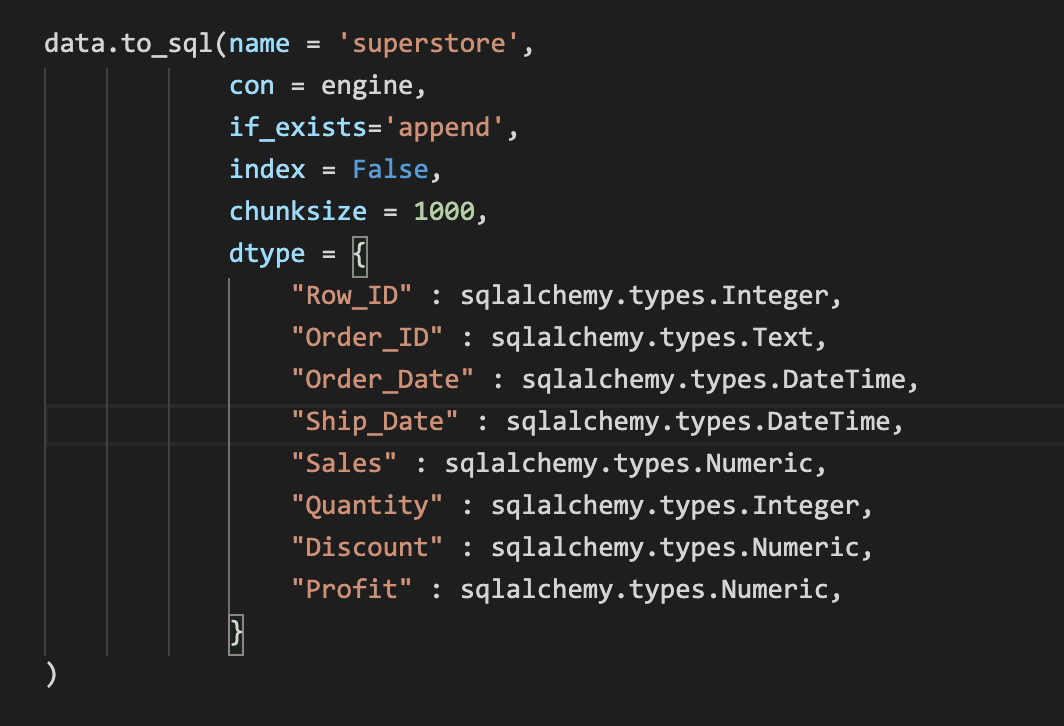
Figure 5 – Specifying parameters while exporting data to an SQL table
You can view the raw code here: https://gist.github.com/aveek22/32b5487838605700fe37afdb48f9b575
Conclusion
In this article, we have understood how to deal with databases and files in Python using Pandas as a library. This is one of the most important and popular packages being used by developers and data scientists. It is free to use and download and can be integrated with a lot of other tools. You can also use other libraries in python to make graphs about your data but that is beyond the scope of this article. The library has rich reading APIs which allows you to read data from various services, transform and clean the data as required and then write the data finally into a database table or a file of your choice.
Table of contents

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021