
In this article, I am going to cover in detail working with databases in Python using Pandas and SQLAlchemy. This is a part of the series Learn Pandas in Python where I talk about the various techniques to work with the Pandas module in Python.
In my previous article in the series, I have explained how to create an engine using the SQLAlchemy module and how to connect to databases in Python while using the Pandas module. You can use any database to connect to starting from MySQL, SQL Server, PostgreSQL, SQLite, etc. However, for the sake of the tutorials, I will proceed by using PostgreSQL. Further, I have also explained in detail how to create a Pandas dataframe in Python and insert data from the dataframe into a table in a PostgreSQL database. This involved the use of the “to_sql()” method of the dataframe object to interact with the database. We have also learned about the various arguments that can be accepted by this method and what those arguments are meant for.
Create Pandas dataframe from SQL tables
As explained in the previous article, we have created a table from the Pandas dataframe and inserted records into it using the same. We will be using the same table now to read data from and create a dataframe from it. Loading data from a SQL table is fairly easy. You can use the following command to load data from a SQL table into a Pandas dataframe.
|
1 2 3 4 5 6 7 8 |
import pandas import sqlalchemy # Create the engine to connect to the PostgreSQL database engine = sqlalchemy.create_engine('postgresql://postgres:test1234@localhost:5432/sql-shack-demo') # Read data from SQL table sql_data = pandas.read_sql_table('superstore',engine) |
This is the easiest way to create a dataframe from a SQL table. In this, we have just provided the two mandatory arguments which tell the Pandas to connect to the specific table with the connection engine. If you want to learn more about how we created the engine, I suggest you have a quick look into my previous article on the same topic. There, I have explained in detail how to create the SQLAlchemy engine to connect to the database.
Further, we can just print the top 5 lines from the dataset that we imported by using the “head()” method of the pandas dataframe.
|
1 |
sql_data.head() |
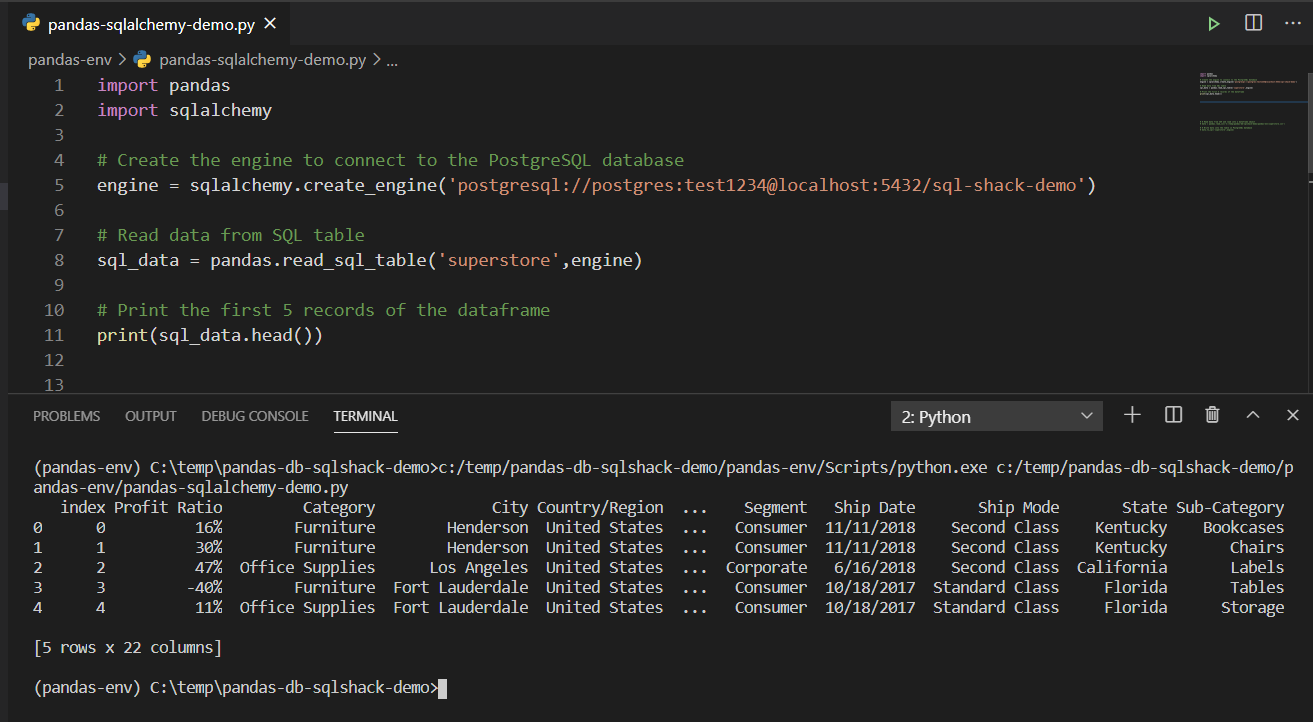
Figure 1 – Reading top 5 records from databases in Python
As you can see in the figure above when we use the “head()” method, it displays the top five records of the dataset that we created by importing data from the database. You can also print a list of all the columns that exist in the dataframe by using the “info()” method of the Pandas dataframe. You can print a list of the columns by using the command below.
|
1 |
sql_data.info() |
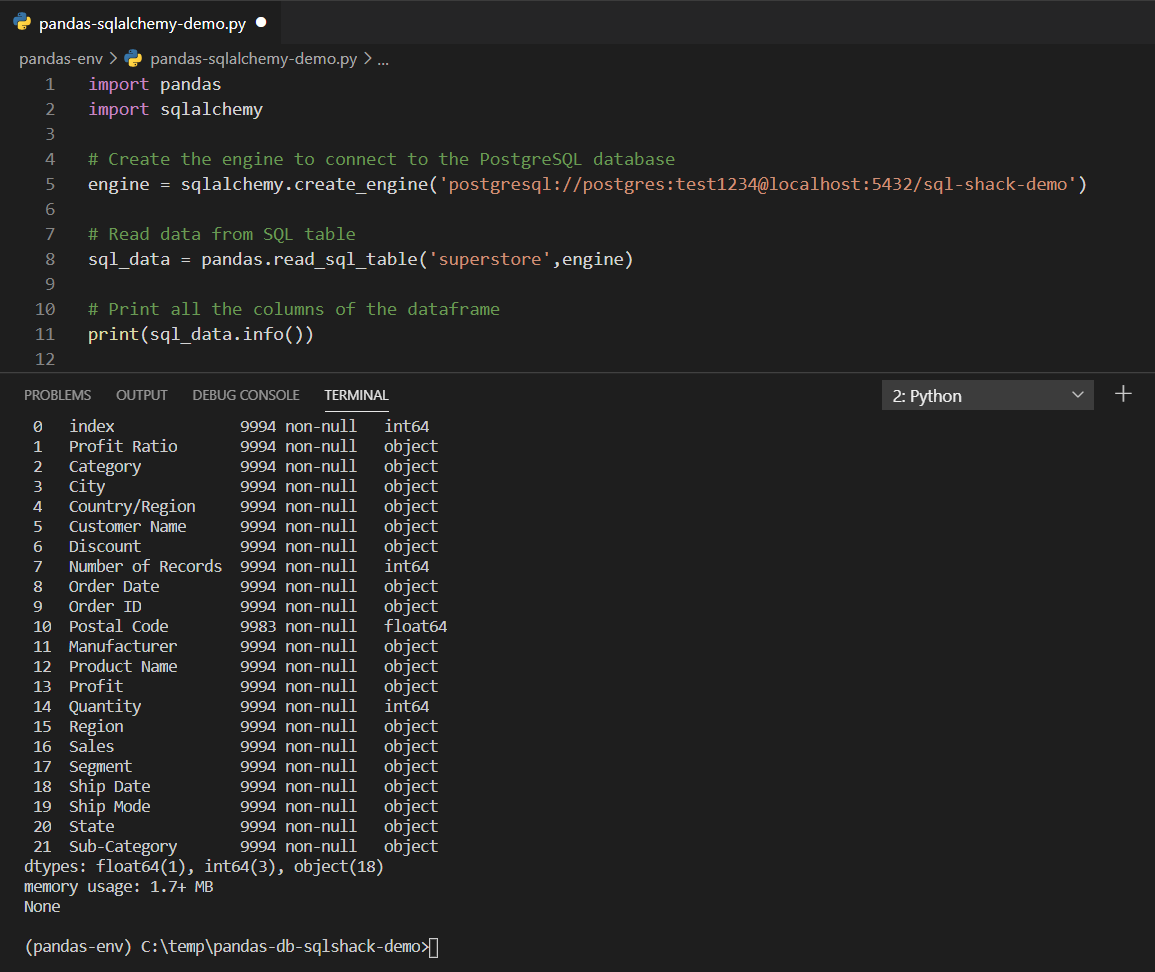
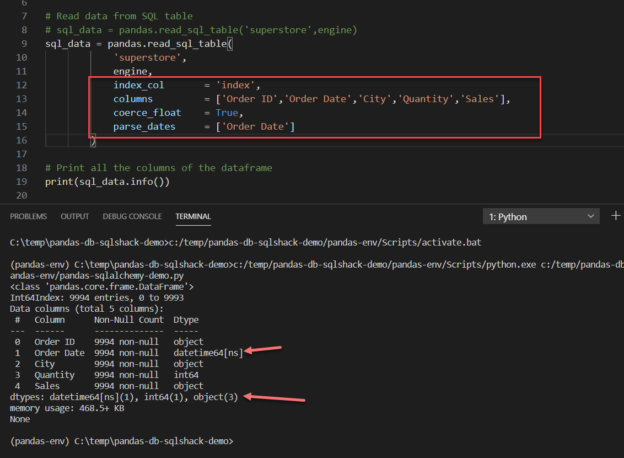
Figure 2 – Reading data from databases in Python
As you can see in the image above, the list of all the columns available in the dataset is listed along with the datatypes. All the strings are represented as “object” datatype in the console whereas the integer and decimal fields are represented as “int64” and “float64” respectively.
Moving forward, let us try to understand what are the other parameters that can be provided while calling the “read_sql_table()” method from the Pandas dataframe.
- table_name – As already mentioned earlier, this is a required parameter that will tell the python interpreter which table to read the data from the database
- con – This is also a required argument, which takes in the value of the engine that is used to connect to the database
- schema – If the table from which you want to read data is in a different schema other than the default, then you need to provide the name of the schema for this parameter. If the name of the schema is not provided, then it will search for the table in the default schema, which might not be correct or will throw an exception as the table will not be present in the default schema
- index_col – This helps us to create an index column in the Pandas dataframe while reading data from a SQL table. This index will be created during the Python execution and is irrespective of the index column in the SQL table. You can mention the name of a single column as a string or pass a list of the strings if you want your index to be created from multiple columns
- coerce_float – This is a Boolean field that is set to TRUE by default. This helps the Pandas dataframe to automatically convert numerical fields from the database to floating-point numbers
- columns – This argument allows us to pass a list of column names that we want to read the data from. By default, if you do not provide this parameter, then the “read_sql_table()” method will attempt to read all the columns from the table. This basically, generates a “SELECT * FROM table_name;” query. However, when you provide a list of columns to this parameter, the query generated to read the table will be something like – “SELECT col1, col2 FROM table_name;“. This is a better approach to fetching data from SQL tables as you might not want to load all the columns into the dataframe on which there will not be any analysis performed
- parse_dates – This argument accepts a list of columns that we want to be converted as dates while reading data from the SQL table
Let us now modify our previous script and pass all the parameters that we just discussed.
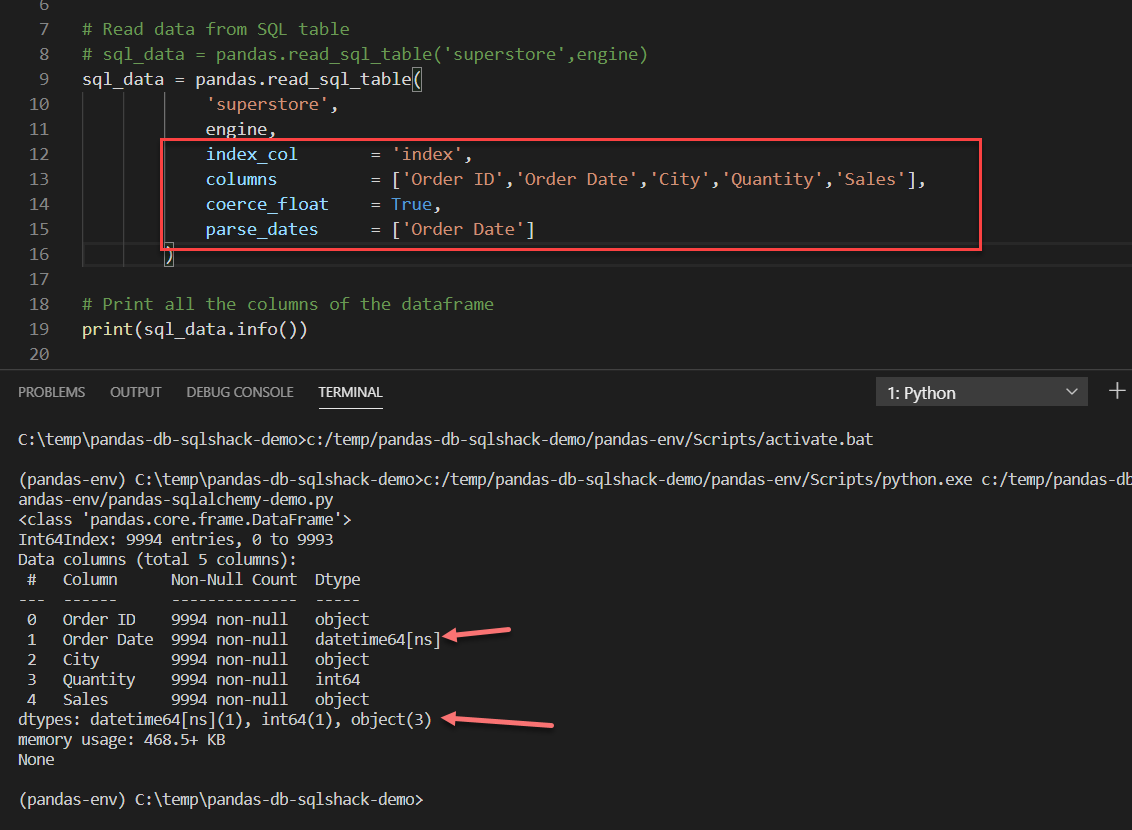
Figure 3 – Adding optional arguments for demonstration
As you can see in the figure above, we have added the optional parameters to select a few columns and also provided the date column that should be parsed as a date. If you look at the console below the datatypes are now clearly displayed for the dates as opposed to the one in Figure – 2.
Running SQL queries to read data from databases in Python
In addition to what we have already seen so far, there is also an option to write simple SQL queries and execute those against a table in the SQL database. This can be done with the help of the “read_sql()” method that is available in the Pandas dataframe object. This method is useful when you want to have more control over the data that you want to bring into the Python environment. You can also join multiple tables in the SQL statement and filter the query buy adding where clause on it. The final result will thus be executed on the table and data will be fetched into the Python environment.
Let us now see this in action.
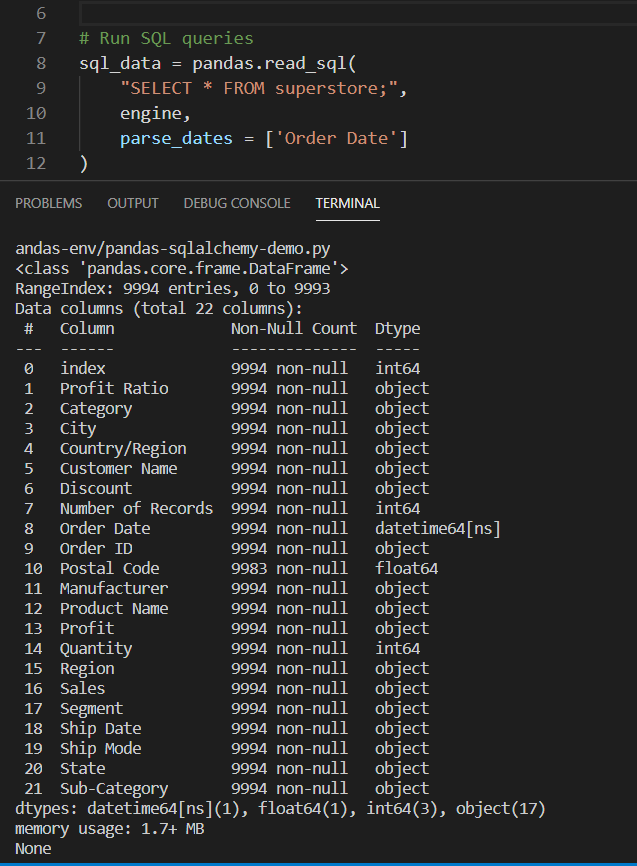
Figure 4 – Running queries to read data from SQL table
As you can see in the figure above, I have used the method “read_sql()” available in the Pandas object to read data from the SQL table by running a simple SQL script. You can also design your scripts by writing complex queries such as join conditions between multiple tables or running sub queries etc.
Conclusion
In this article, we have seen how to work with databases in Python using the Pandas and SQLAlchemy module. The Pandas is a popular data analysis module that helps users to deal with structured data with simple commands. Using the Pandas dataframe, you can load data from CSV files or any database into the Python code and then perform operations on it. Finally, once your analysis is completed, you can also write the data back to the table in the database or generate a flat file to store the data. The connection to the databases is made with the help of the SQLAlchemy plugin which helps us to connect to databases in Python while working with the Pandas module.
Table of contents

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021