
This is the fourth article in a series of learning the CREATE VIEW SQL statement. So far, we have done a great deal of creating and altering views using T-SQL. In this last part, I want to take a big look at how to work with indexed views.
As always, to follow along with the series, it’s highly recommended to read the previous parts first and then this one. This is primarily because we created our own sample database and objects in it from scratch that we’ll be using in this part too, but also because it will be much easier to see the big picture.
Here are the previous three pieces of the CREATE VIEW SQL series:
- Creating views in SQL Server
- Modifying views in SQL Server
- Inserting data through views in SQL Server
So, head over and read those before continuing with this one.
Introduction
The first thing that we’ll do is create an indexed view. We will, of course, use the CREATE VIEW SQL statement for this as we did many times through the series. But the general idea, as the title says, is to see how to work with indexed views, see what the requirements are for adding an index to a view, and how to do it programmatically. Furthermore, to explain the pros of indexed views, we’ll be looking at executions plans in SQL Server. They are a great tool for DBAs and developers when it comes to finding and fixing a bottleneck in the slow running query.
CREATE VIEW SQL statement
Without further ado, let’s create a view using the CREATE VIEW SQL statement from below and see what it does:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
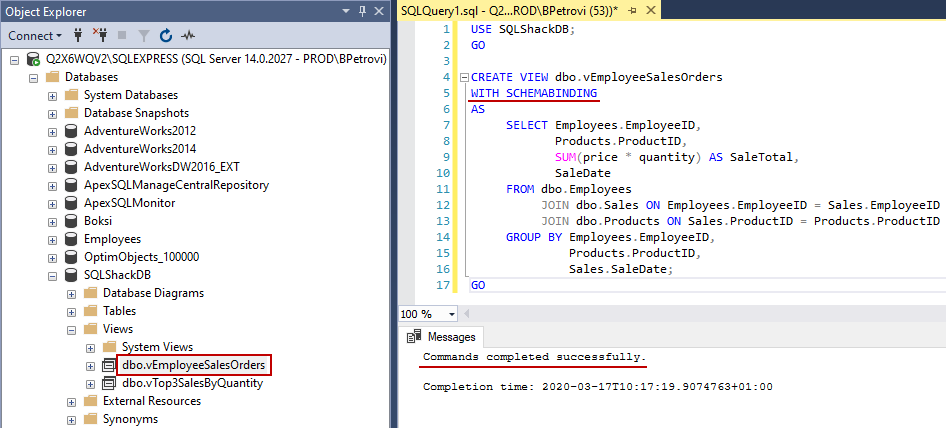
USE SQLShackDB; GO CREATE VIEW dbo.vEmployeeSalesOrders WITH SCHEMABINDING AS SELECT Employees.EmployeeID, Products.ProductID, SUM(price * quantity) AS SaleTotal, SaleDate FROM dbo.Employees JOIN dbo.Sales ON Employees.EmployeeID = Sales.EmployeeID JOIN dbo.Products ON Sales.ProductID = Products.ProductID GROUP BY Employees.EmployeeID, Products.ProductID, Sales.SaleDate; GO |
Notice that this view has a WITH SCHEMABINDING option on it. The reason why it has this option turned on is because when creating indexes on views, they actually physically get stored in the database. In other words, anything that this view relies on, as far as the tables are concerned, the structure cannot change from what we’re referencing.
Therefore, it must be bound to the underlying tables so that we can’t modify them in a way that would affect the view definition. If we try to change them in any way, SQL Server will throw an error saying that this view depends on something. So, look at it as a hard requirement for creating an index on a view.
Once the command is executed successfully, you should see the vEmployeeSalesOrders view under Views folder in Object Explorer as shown below:
The definition of the view is a bit more complex query. We got an aggregate in the SELECT statement followed by the GROUP BY clause. Remember, when we have an aggregate in the query, it adds the numbers together, so we need to have the GROUP BY clause.
Basically, when there’s a GROUP BY in a query, we need to group by everything that is in the select list except the aggregate.
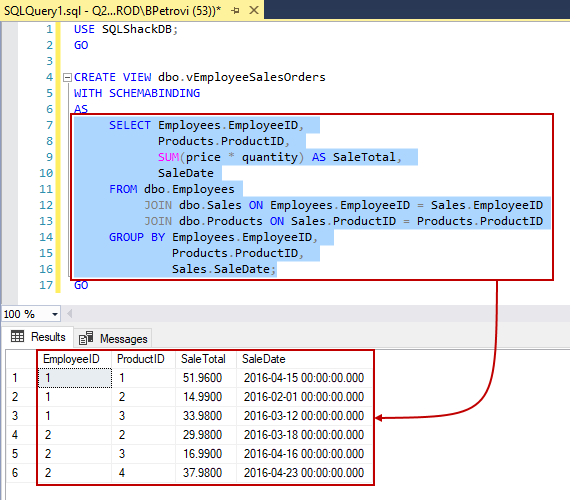
Now, I’ve already created the view, but remember that it’s always a good idea to test out the definition of the view by running only the SELECT part of the CREATE VIEW SQL statement to see what it returns:
Moving on, here’s how you can check whether the Schema bound option is enabled or disabled. Head over to Object Explorer, expand Views, right-click on the view, and select Properties:
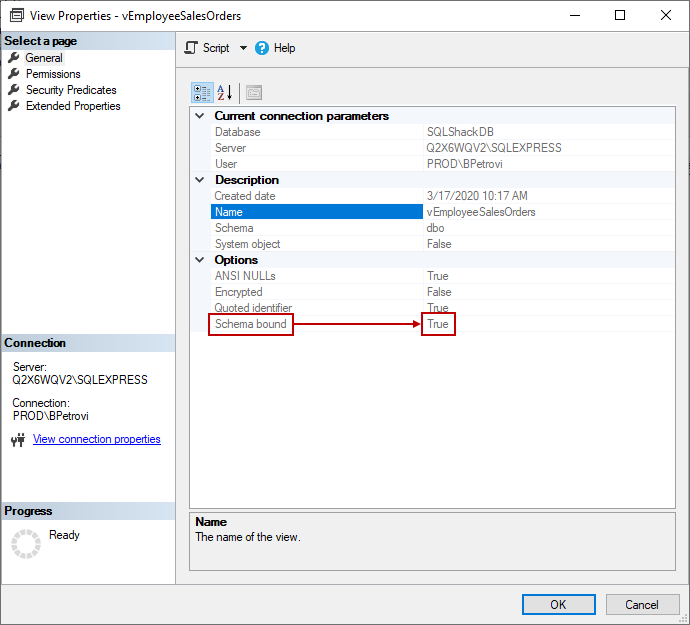
Among all other information in the View Properties window, you’ll see if the Schema bound option is set to True or False under the General page.
Creating indexed views
Let’s move on and create an index on our view. Consider the script from below for creating a clustered index on the vEmployeeSalesOrders view:
|
1 2 3 4 5 6 |
USE SQLShackDB; GO CREATE UNIQUE CLUSTERED INDEX CAK_vEmployeesSalesOrders ON dbo.vEmployeeSalesOrders(EmployeeID, ProductID, SaleDate); GO |
If we hit the Execute button in SSMS, SQL Server will throw an error saying that index cannot be created:
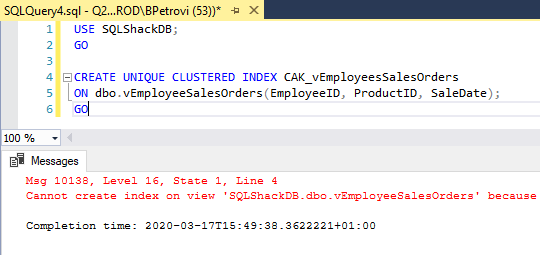
Here’s the full error message that cannot be seen in the shot above:
Cannot create index on view ‘SQLShackDB.dbo.vEmployeeSalesOrders’ because its select list does not include a proper use of COUNT_BIG. Consider adding COUNT_BIG(*) to select list.
We need COUNT_BIG in this case given the fact that we’re using GROUP BY in our view.
In general, if we are using aggregates like COUNT, SUM, AVG, etc. in the index’s select list, we also have to include COUNT_BIG in order to create an index on it.
That’s exactly what we’re going to do. Modify the existing view with the ALTER VIEW command by changing its definition created previously using the CREATE VIEW SQL statement and add COUNT_BIG to the select list using the script from below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE SQLShackDB; GO ALTER VIEW dbo.vEmployeeSalesOrders WITH SCHEMABINDING AS SELECT Employees.EmployeeID, Products.ProductID, SUM(price * quantity) AS SaleTotal, SaleDate, COUNT_BIG(*) AS RecordCount FROM dbo.Employees JOIN dbo.Sales ON Employees.EmployeeID = Sales.EmployeeID JOIN dbo.Products ON Sales.ProductID = Products.ProductID GROUP BY Employees.EmployeeID, Products.ProductID, Sales.SaleDate; GO |
If you’re wondering why this is happening in this case, the answer is because SQL Server needs a way of tracking the number of the record that we’re turning for the index and this is also one of a whole bunch of limitations with creating indexed views.
So far, everything looks good. We successfully changed the definition of our view:

Now, we can get back to creating an index on the view by executing the previously used script one more time. This time, the operation will complete smoothly. If we go to Object Explorer and expand the Indexes folder of our view, we’ll see the newly created index:
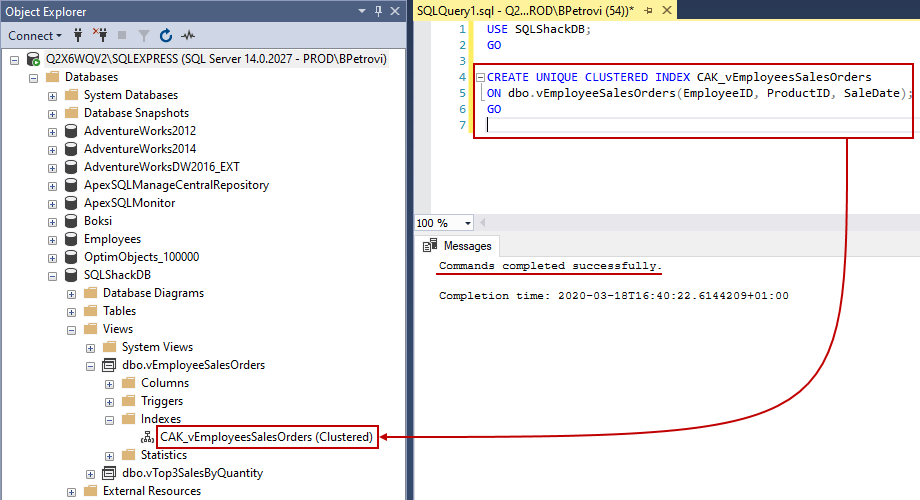
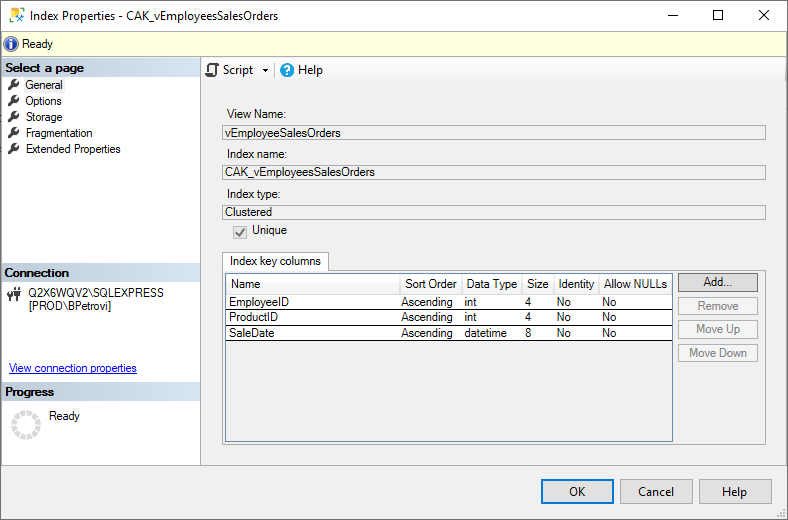
From here, if we right-click on the index and select Properties, under the General page, you can see view name, index name, type, key columns, etc.:
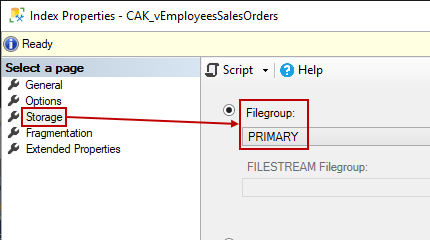
If we switch over to Storage, you’ll see that it has a Filegroup because it is physically stored in a database:
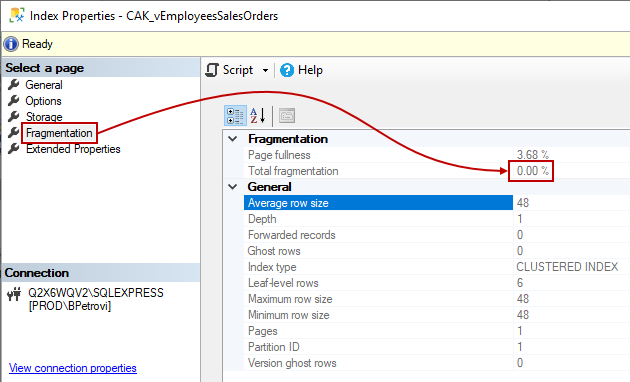
Furthermore, if we switch over to Fragmentation, it should say that Total fragmentation is zero percent because we only have a few records in our tables:
Looking for a detailed but fun and easy to read primer on maintaining and monitoring SQL indexes? Check out SQL index maintenance.
Deleting indexes
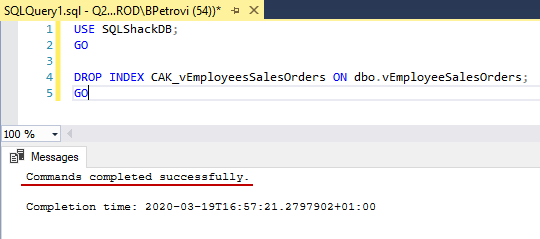
Before we go any further, let’s see how we can delete an index. The easiest way is to right-click on the index in Object Explorer and use the Delete option. But in case you need to drop multiple indexes at once, the DROP INDEX statement comes in handy. That’s what we’re going to do, because, after all, this is a T-SQL series about learning the CREATE VIEW SQL statement.
Use the script from below to drop the CAK_vEmployeesSalesOrders index:
|
1 2 3 4 5 |
USE SQLShackDB; GO DROP INDEX CAK_vEmployeesSalesOrders ON dbo.vEmployeeSalesOrders; GO |
When you need to drop multiple indexes, just specify all names separated by a comma.
Generating random data
Now, that we got rid of the index, let’s generate some random data in our table so that we can look at the execution plan and see how SQL Server fetches data under the hood. Analyzing the execution plan will show the difference in how the performance is affected by running the query with and without an index on the view.
Use the script from below to insert 50000 random records into the Sales table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE SQLShackDB; GO --Create 50000 random sales records DECLARE @counter INT; SET @counter = 1; WHILE @counter <= 50000 BEGIN INSERT INTO Sales SELECT NEWID(), (ABS(CHECKSUM(NEWID())) % 4) + 1, (ABS(CHECKSUM(NEWID())) % 2) + 1, (ABS(CHECKSUM(NEWID())) % 9) + 1, DATEADD(day, ABS(CHECKSUM(NEWID()) % 3650), '2020-04-01'); SET @counter+=1; END; |
I’m not going to walk you through the script in details, but it’s basically a loop that will execute 50000 times and insert random data into the Sales table. Once the loop is terminated, SQL Server will return 50000 messages saying “1 row affected”:
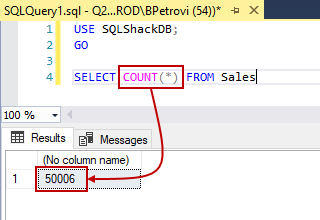
Just to check if the records were inserted successfully, execute the following SELECT statement that will count all records from the Sales table:
|
1 2 3 4 |
USE SQLShackDB; GO SELECT COUNT(*) FROM Sales |
The number returned shows that there’re 50006 rows in the Sales table. This is the number of records that we just generated + 6 that we initially had:
Analyzing execution plans
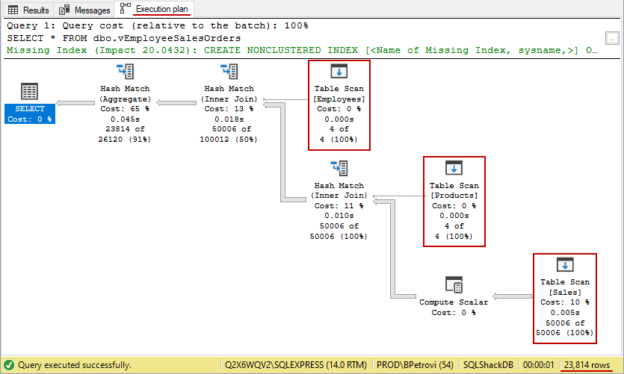
Now that we have some data in our table, we can really demonstrate the use of an index on the view. Let’s query the vEmployeeSalesOrders view and see how SQL Server retrieves the data. Before executing the SELECT statement from below, make sure to include the Actual Execution Plan as shown below:
|
1 2 3 4 |
USE SQLShackDB; GO SELECT * FROM dbo.vEmployeeSalesOrders; |
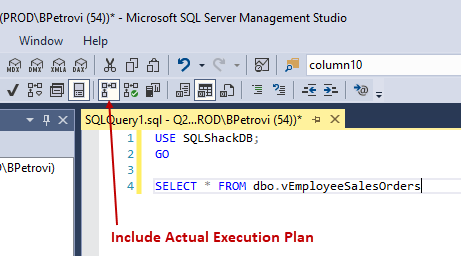
This script returned 23814 rows, but what’s more important, it generated the execution plan of the query. Remember that we previously dropped the index on our view. So, right now there’s no index on our view. Therefore, SQL Server will do a few table scans as shown below:
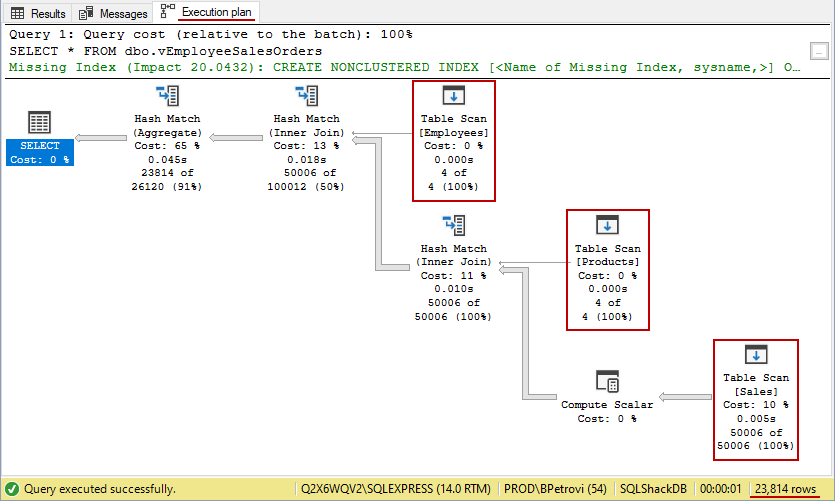
This is pretty much the worst thing in the database world, especially on tables with a large amount of data. It’s okay to have table scans with a small amount of data e.g. the case with our Employees and Products tables, but it’s bad for the Sales table because it has 50K+ records.
The easiest way to get rid of the table scans is to create an index on it because it dramatically speeds things up. So, what we’ll do to fix this problem is re-execute the script for creating the unique clustered index on the vEmployeeSalesOrders view.
Now, if we just re-run the SELECT statement, there will be no differences even though we just created the index. Why is that? Because I’m using the SQL Server Express edition for the purpose of this series, and only in Enterprise and Developer editions of SQL Server will the Query Optimizer actually take the index into consideration.
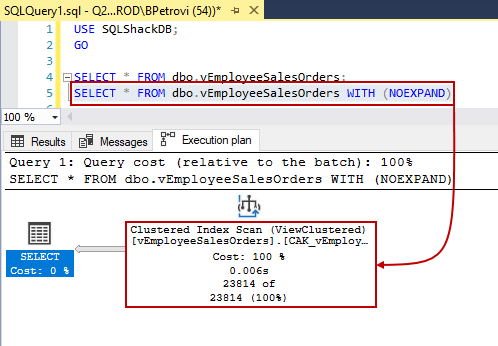
No worries because we can actually force SQL Server to use an index when generating execution plans. This is done by using the NOEXPAND option. NOEXPAND applies only to indexed views:
|
1 |
SELECT * FROM dbo.vEmployeeSalesOrders WITH (NOEXPAND) |
Just like that, we forced SQL Server to use the clustered index which basically means do not use the underlying tables when fetching data. As can be seen below, we’ve made some progress by eliminating a number of operations:
In fact, we can executeboth SELECT statements simultaneously and compare the results by looking at the execution plans:
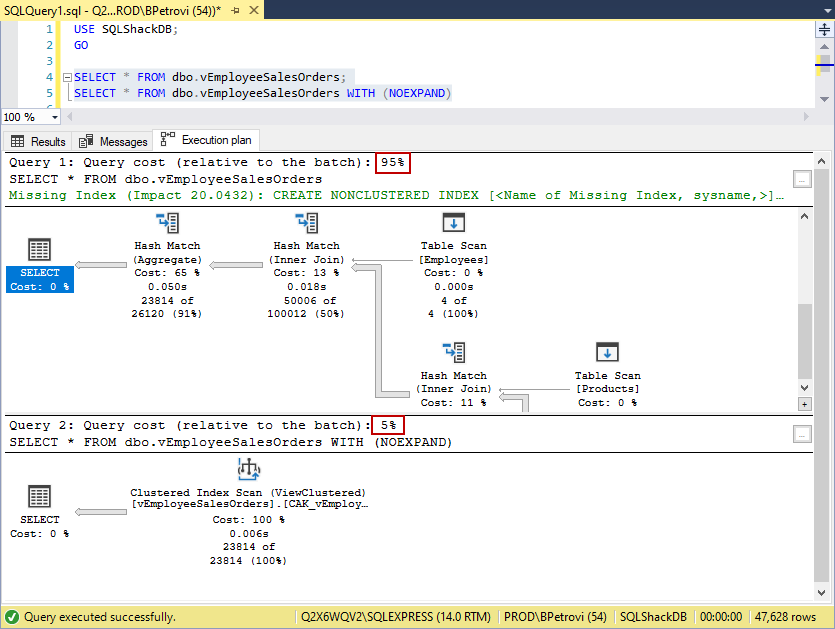
Would you look at that? If we compare the query cost of the first SELECT statement (w/o index 95%) to the second SELECT statement (w/ index 5%), I’d say that’s a huge performance gain using a single index.
Conclusion
Indexes are great because they speed up the performance and with an index on a view it should really speed up the performance because the index is stored in the database. Indexing both views and tables is one of the most efficient ways to improve the performance of queries and applications using them.
I’d like to wrap things up and finish this series of learning the CREATE VIEW SQL statement with this article. We’ve pretty much covered everything about creating and altering views with T-SQL. We started off with the CREATE VIEW SQL statement, created a few views, altered them, deleted, and much more.
I hope this series of learning the CREATE VIEW SQL statement has been informative for you and I thank you for reading it.
Table of contents
| CREATE VIEW SQL: Creating views in SQL Server |
| CREATE VIEW SQL: Modifying views in SQL Server |
| CREATE VIEW SQL: Inserting data through views in SQL Server |
| CREATE VIEW SQL: Working with indexed views in SQL Server |

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
See more about Bojan at LinkedIn
View all posts by Bojan Petrovic
- Visual Studio Code for MySQL and MariaDB development - August 13, 2020
- SQL UPDATE syntax explained - July 10, 2020
- CREATE VIEW SQL: Working with indexed views in SQL Server - March 24, 2020