
In SQL Server, it`s not always required to fully understand the internal structure, especially for performance and optimization, if the database design is good, because SQL Server is a very powerful Relational Database and, as such, it has many inbuilt optimization processes which assure a response to the users as fast as possible. But it is always beneficial for the SQL Server developers and administrators to understand the internal structure of the SQL Server so that they can understand and fix the problems that slowed the response of the Database.
The following article is the third edition in the Nested Loop Join series (Introduction to a Nested Loop Join in SQL Server, Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates) in which we will try to understand the Batch Sort, Explicit Sort and some interesting facts about Nested Loop Join.
Before we start, it is important to understand two data access methods from the permanent storage system.
In a nutshell, when the requested data is not in the cache, it has to bring the data from permanent storage and put it in the buffer cache. The two ways of accessing the data from permanent storage system are Sequential and Random access. For conventional rotating magnetic disks, accessing is much faster in a sequential manner than the random access, because disk hardware works in that particular manner. For reading the random IOs, disk head has to move back and forth, due to which the random-access method delivers a lower rate of throughput.
Usually, sequential access is not a problem unless the table is highly fragmented because when the table is fragmented, the data is not organized in contiguous clusters on the disk.
In the latest permanent storage systems which are more expensive, faster and more advanced, the latency between sequential and random-access methods has been reduced, but sequential reads are still preferred.
It is needed to understand this concept because inner side of Nested Loop Join fetches the data from the disk in a random manner.
Batch Sort and Implicit Sort
Nested Loop Joins generates random IOs to the inner side. To minimize the random IO impact the Query Optimizer uses some techniques, one of them is sorting the outer input. This technique is only applicable when the joining column(s) of the inner side table is already sorted (indexed). If it is sorted then the Query Optimizer might choose to sort the outer joining column(s).
To sort the Outer input, it either chooses Explicit Sort or Batch Sort. Explicit Sort is a part of the optimization process which is appropriate for a large set of data, but for a medium set of data it can be very expensive and blocking as well and may cost some additional IOs. For a medium set of rows, a post optimization process is used which is called Batch Sort.
Batch Sort is not visible as an iterator in the execution plan, but can be seen in the properties window of the Nested Loop Join as an Optimized TRUE keyword, as this is the part of the post optimization process even Optimized keyword does not guarantee that Batch Sort applied to the outer rows.
To see this phenomenon in action we are changing the Somedata column of DBO.T1 table to char(8000) with some random number on the search column and indexing the search column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ALTER TABLE T1 ALTER COLUMN somedata Char(8000) GO ;With RevOrder As ( Select searchcol , ROW_number() Over(Order by primarykey DESC ) RK from t1 ) UPDATE RevOrder SET searchcol = RK CREATE INDEX BatchSort ON T1 (searchcol) GO |
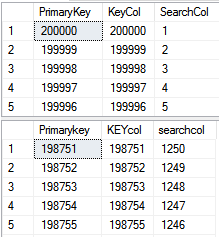
Now the searchcol column is updated with some random data, so we can clearly see the difference for both output result set. Run the query and have a look at the below result, for better visible differences in the result set, prepare the cache by running the below query twice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT PrimaryKey , KeyCol, SearchCol FROM T1 WHERE SearchCol < 1250 Option (Recompile , Loop Join) GO SELECT Primarykey ,KEYcol, searchcol FROM T1 WHERE SearchCol < 1251 Option (Recompile , Loop Join) GO |
Before we explain the above result set, I would like to draw your attention on the two indexes on the DBO.T1 table.
The first index is a unique clustered Index on the primarykey column that technically means it is logically sorted on a primarykey column and rest columns are on its leaf level. In the above script, I have created another Index on searchcol column (Batch Sort) which is logically sorted on the searchcol and as usual, it has a primary key column on the leaf level.
So, for the above-expressed query, it would be better to return the result by seeking the batch index and then get all the remaining rows from the clustered index. Now look at both result sets and you can see that the result order is quite different. Why is the result order different?
It is possible that both queries choose a different execution plan. Now see the below actual execution plan.
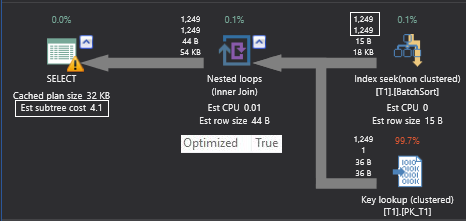
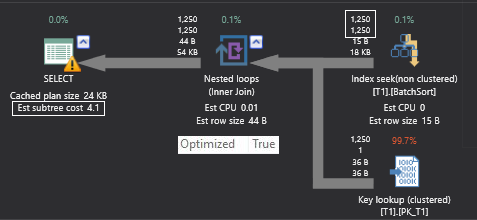
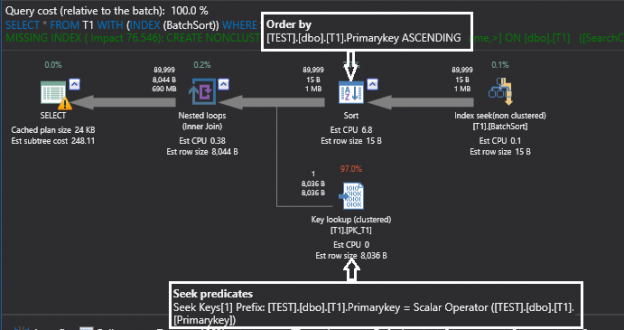
Of course, row count and cost of the iterators can vary slightly because the estimated number of rows are different for both queries. Apart from that, there is an Optimized keyword in the property window of Nested Loop Join iterator and this indicates that the outer row can enable a batch sort to minimize the impact of random access to the inner table.
Optimize keyword indicates that outer side data could be sorted, but there is no guarantee as seen in the above example. You can see that both the query plans have the optimized keyword true, but sort order is entirely different. The first result set is sorted on the searchcol column and the second result is sorted on the primary key column which means that batch sort has applied on the second execution plan, but not on the first plan.
Batch sort is a lightweight process and this is quite good for the medium set of rows, but if the Query Optimizer determines that it might get a large set of rows, then it chooses a full sort on the inner side of a nested loop join. To see this in action we will change the literal value below:
|
1 2 3 4 5 6 7 |
SELECT * FROM T1 WITH (INDEX (BatchSort)) WHERE SearchCol < 90000 OPTION (RECOMPILE) GO |
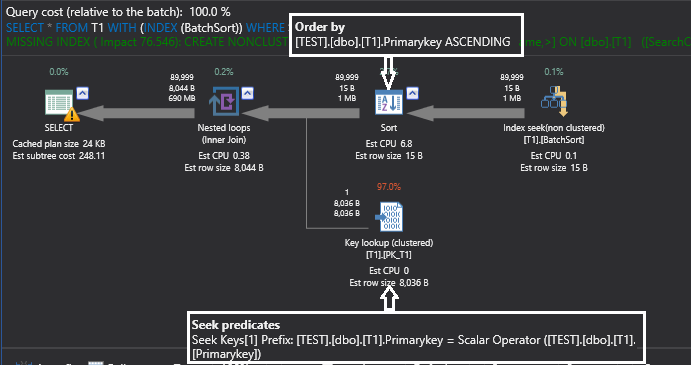
Looking at the above execution plan, there is a sort iterator which is sorting the outer input on the primary key column (the implicit sort might not be seen in your testing machine because it depends on the estimated number of rows on the outer input and the configured memory to SQL Server, we will see this in the next subsection).
Now the outer set or rows are sorted and inner set of rows are already sorted on the primary key column, so the Nested Loop Join can minimize the impact of random access to the inner input.
Both techniques given above are quite good, but their usefulness depends on the hardware you are using. To measure the performance difference you could run the test below.
Performance Impact of Batch Sort and Implicit Sort
Please note that in the below script that there is DBCC DropCleanBuffers which removes all clean buffers from the buffer pool so it is not recommended at all on the production server.
To perform the tests, we are using the documented Trace Flag 2340 to disable the batch sort. Script and Results are below.
Batch Sort Test Script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
CHECKPOINT; DBCC DROPCLEANBUFFERS; DECLARE @a varchar(max) SET STATISTICS TIME ON; SELECT @a = Primarykey, @a = Keycol, @a = SearchCol, @a = somedata FROM T1 WITH (INDEX (BatchSort)) WHERE SearchCol < 30000 OPTION (RECOMPILE) SET STATISTICS TIME OFF; PRINT 'With Batch Sort' CHECKPOINT; DBCC DROPCLEANBUFFERS; SET STATISTICS TIME ON; SELECT @a = Primarykey, @a = Keycol, @a = SearchCol, @a = somedata FROM T1 WITH (INDEX (BatchSort)) WHERE SearchCol < 30000 OPTION (RECOMPILE ,QUERYTRACEON 2340) SET STATISTICS TIME OFF; PRINT 'Without Batch Sort' |

The first query in the above script, with batch sort enabled, took 2.2 seconds and the second query without batch sort took 4.3 seconds on my system.
Now test with the full inner sort:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CHECKPOINT; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; Declare @Primarykey int Declare @Keycol varchar (50) Declare @SearchCol int Declare @SomeData char(8000) DECLARE @Lit int SET @Lit = 150000 SET STATISTICS TIME ON; SELECT @Primarykey = Primarykey, @Keycol = Keycol, @SearchCol = SearchCol, @SomeData = somedata FROM T1 WITH (INDEX (BatchSort)) WHERE SearchCol < 150000 OPTION (RECOMPILE) SET STATISTICS TIME OFF; PRINT 'With Explict Sort' CHECKPOINT; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET STATISTICS TIME ON; SELECT @Primarykey = Primarykey, @Keycol = Keycol, @SearchCol = SearchCol, @SomeData = somedata FROM T1 WITH (INDEX (BatchSort)) WHERE SearchCol < @Lit OPTION (RECOMPILE, QUERYTRACEON 2340,OPTIMIZE FOR (@Lit = 30000)) SET STATISTICS TIME OFF; PRINT 'Without Explict and Batch Sort' |

Looking at the above script, the first query is using the full inner sort while the second is neither using full sort nor the batch sort. To confirm this, you can view the estimated/actual execution plan.
An Estimated execution plan was used on my system for the above test.
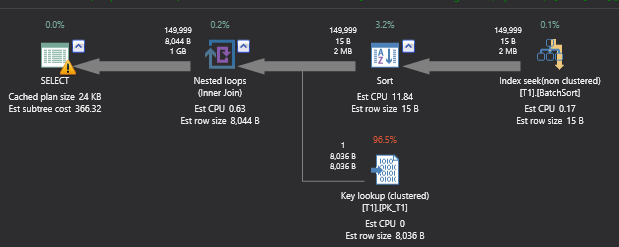
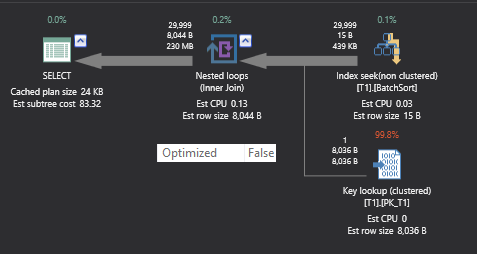
On my system first query with batch sort took 16.8 seconds and second query without full or batch sort took 25.7 seconds to complete the execution.
However, those were just basic tests and the performance difference varies a lot with the different hardware setup, data load and the current IO pressure.
Even these results can differ on some latest hardware setups (SSD, SSD NVMe etc.) because they perform random IOs much faster than the traditional Rotating Disks. On those Setup Batch Sort and Inner sort is just an additional overhead.
Batch Sort, Explicit Sort and Cold Cache Assumption
If you are following the series carefully, then you would know that the Query Optimizer considers some assumptions before generating the execution plan. One of the major assumptions which influence the plan choice is that every query starts with a cold cache, also known as Cold Cache Assumptions.
Batch and Explicit sort is not an exception. Both work well with the Cold Cache accompanied with prefetching (we will see this in the next part of this series) some organizations keep a large amount of memory on the servers, for those Batch and Explicit sort can be just an overhead.
Since Batch Sort and Explicit sort were first introduced in the SQL Server 2005, some customers reported that some queries consumed high CPU in the new version and the reason was Batch Sort, so there is a documented trace flag 2340 to disable the batch sort, and the whole article can be read here.
There is no Trace Flag to disable the explicit sort as per my knowledge.
The above query can be tested without the cleaning of Buffer cache (Remove DropCleanbuffer command) and the query may be found without the Batch/Explicit sort running slightly better than with Batch/Explicit sort.
Batch Sort (Optimized Nested Loop Join) Calculations
In the aforementioned tests, it was found that the Optimize (Batch Sort) property of Nested Loop Join is usually TRUE in the executions Plan when the inner side of the table is sorted (indexed, except when joining and where condition is in the same column), unless the inner side of the structure contains less than 1.280 +1 per MB data pages available to the SQL Server database.
For example, if the SQL Server database is configured to maximum 1000 MB only then Optimized Property will be TRUE, when the inner side of the structure would have at least (1000 *1.280 +1) = 1281.00 pages.
Even when the Optimize property is true, Optimizer does not activate the batch sort because it is a post optimization process and when the execution plan creates it has no idea that it would activate or not.
It was observed that Batch Sort is activated only when the estimated outer rows are more than or equal to 1250 (this is undocumented stuff and can change).
Batch Sort (Optimized Nested Loop Join) Tests Details
To conclude the tests, two tables are created and are named BS and BS2 respectively. BS table contains only one column with primary key (Unique Clustered Index) and the other table is BS2 which has two columns where one is the primary key (Unique Clustered Index) and another is Non-Clustered Index, we will query against the Non-clustered index.
Download the script at the bottom of the article.
Tests are conducted in SQL Server 2008 to SQL server 2016.
Note that below script contains some commands, like sp_configure ‘max server memory’ that could harm your system, so do not run the below test in the production environment.
Interesting Facts About Nested Loop Join
In SQL Server, we have three physical join types:
All three are useful in different conditions, but only Nested Loop Join is the physical join type which supports non-equality predicate while joining the other tables.
Another interesting fact about Nested Loop Join is that it does not support right outer join, it actually converts all the right outer joins to the left outer joins. Because of the above fact that Nested Loop Join does not support full outer join directly and therefore converts full outer join to one left outer join concatenated with one semi left join.
Let us test the mentioned above facts:
Test with Non-Equality Predicate Script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
PRINT 'First Query' SELECT TOP 1 * FROM OuterTable OT1 JOIN Innertable_Parallel ot2 ON ot1.Keycol <> ot2.Keycol OPTION (LOOP JOIN) GO PRINT 'Second Query' SELECT TOP 1 * FROM OuterTable OT1 JOIN Innertable_Parallel ot2 ON ot1.Keycol <> ot2.Keycol OPTION (HASH JOIN) GO PRINT 'Third Query' SELECT TOP 1 * FROM OuterTable OT1 JOIN Innertable_Parallel ot2 ON ot1.Keycol <> ot2.Keycol OPTION (MERGE JOIN) GO |

Looking at the message tab, neither the hash or merge joins are able to produce the physical plan, only the loop join is able to produce a plan for the non-equality predicate.
Nested Loop Join Does Not Support Right Outer Join Physically:
To test whether the Nested Loop Join supports the Right Outer Join physically or not, we will write a query with Right Outer Join and then we will see the execution plan.
Look at the query and its estimated execution plan below:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM T1 OT1 Right Outer Join T2 ot2 ON ot1.Keycol = ot2.Keycol OPTION (LOOP JOIN ) GO |
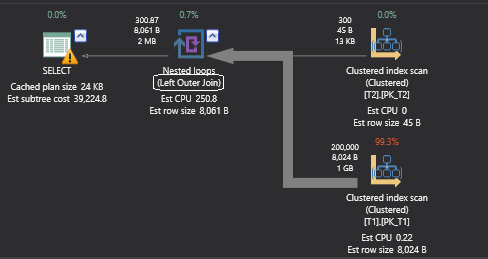
Looking at the physical join of the above query in the execution plan, in the query text it is written as “T1 Right Join T2”, but the Query Optimizer has converted it into the T2 left join T1 which is logically equivalent to the above expressed query and it is common for the Query Optimizer to choose this transformation based on costing, but on the above case the Query Optimizer is bound to choose Left Outer Join because it cannot use Right Outer Loop Join. To check that we need to force the above query.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM OuterTable OT1 RIGHT JOIN Innertable_Parallel ot2 ON ot1.Keycol = ot2.Keycol OPTION (LOOP JOIN, FORCE ORDER) GO |

Looking at the above message, we can see that the Query Optimizer is not able to produce a plan when forcing the query with the Right Join.
Nested Loop Join Does Not Support Full Outer Join Directly
We have seen above that the Nested Loop Join does not support the Right Join directly, and therefore the Nested Loop Join does not support the full outer join directly. It actually converts Full Outer Join into one Left Outer Join and concatenates with the Semi Left Join. To confirm this is to run the query and see the execution plan, look at the query and plan below:
|
1 2 3 4 5 6 7 8 |
SELECT TOP 10 ot1.SearchCol,ot2.Primarykey FROM T1 OT1 FULL JOIN T2 ot2 ON ot1.Keycol = ot2.Keycol OPTION (LOOP JOIN , Maxdop 1) GO |
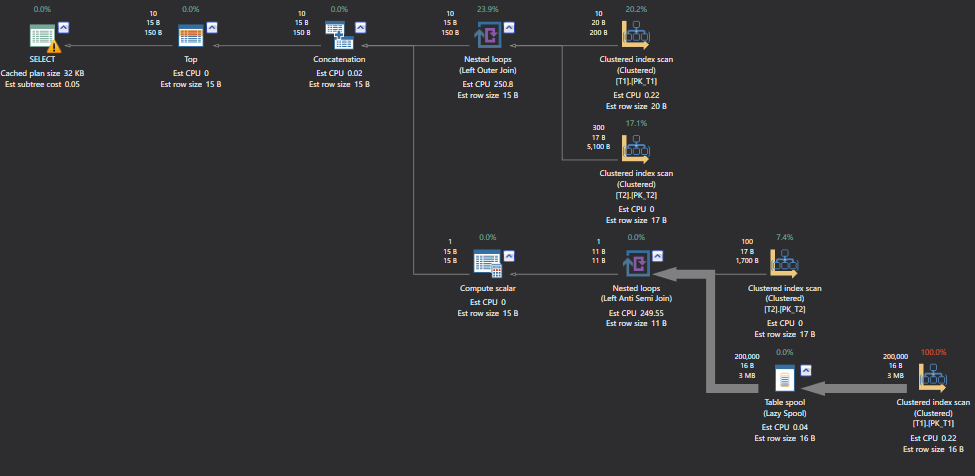
Looking at the above execution plan we observe that both the tables have been used twice to get the result for Full Outer Join.
The Query Optimizer fulfills the Joining part in three steps:
First Step: First table left join second table
Second Step: Second table left semi join first table
Third Step: Concatenate the results of both output
It is very interesting to note how the Nested Loop Join supports the full outer join. An alternative way to mimic this is by converting the above steps into a query and then looking at the execution plan, the same execution plan will be seen as in the full nested loop join.
To check this, we convert the full join query into the three steps described above and then check the execution plan.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT Top 10 * FROM (SELECT ot1.SearchCol, ot2.Primarykey FROM T1 OT1 LEFT JOIN T2 ot2 ON ot1.Keycol = ot2.Keycol UNION ALL SELECT NULL SearchCol, ot2.Primarykey FROM T2 ot2 WHERE NOT EXISTS (SELECT * FROM T1 OT1 WHERE ot1.Keycol = ot2.Keycol)) TBL OPTION (LOOP JOIN , maxdop 1) GO |
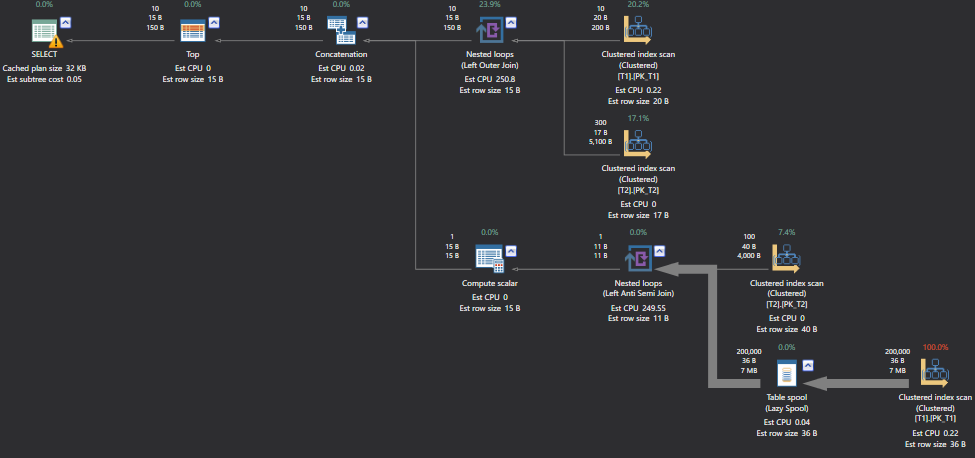
On observing the above execution plan, we see that nothing has changed and it is similar to nested loop full outer join. Moreover, the sub tree cost is equal for both.
The Nested Loop Join is an amazing physical join type which is often misunderstood. These are just a few interesting facts about Nested Loop Join, and you can feel free to add more in the comment section.
We have tried our best to cover the basics of Nested Loop Join and for better insights we recommend our readers to visit the links provided in the below section.
Downloads
Previous articles in this series:
- Introduction to a Nested Loop Join in SQL Server
- Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates
Useful links
- OPTIMIZED Nested Loops Joins
- High CPU after upgrading to SQL Server 2005 from 2000 due to batch sort
- SQL Server can’t start after accidently set the “max server memory” to 0

- Nested Loop Joins in SQL Server – Batch Sort and Implicit Sort - September 1, 2017
- Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates - May 22, 2017
- Introduction to Nested Loop Joins in SQL Server - May 8, 2017