
A relational database system uses SQL as the language for querying and maintaining databases. To see the data of two or more tables together, we need to join the tables; the joining can be further categorized into INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, and CROSS JOIN. All these types of joins that we use are actually based on the requirement of the users.
SQL is a declarative language; we just write a query by the SQL language standard and ask for the database to fulfill the request. Now, it is the responsibility of the database to fulfill the user’s request optimally. Fortunately, SQL Server has the Query
Optimizer which is responsible for fulfilling the user requests optimally.
We need not to worry how things actually happen in the SQL Server, but it’s always good to know what’s happening behind the curtain sometimes so that we can figure out why a query is running slow.
However, in the Execution plan, there are many iterators for different operations, but in this article, we will learn one iterator only, that is, the Nested Loop Join. It is a physical join type iterator. Whenever you join a table to another table logically, the Query Optimizer can choose one of the three physical join iterators based on some cost based decision, these are Hash Match, Nested Loop Join and Merge Join. This article only focuses on the Nested Loop Join, and hence let us quickly move to the joining part.
Basics of Nested Loop Join
In relational databases, a JOIN is the mechanism which we use to combine the data set of two or more tables, and a Nested Loop Join is the simplest physical implementation of joining two tables. For example, how would you match the following data manually, if you have these two tables given below:
| StudentInfo | Attendance | |||||
| RollNumber | Name | Address | RollNumber | Present | Date | |
| 1 | A | A’s Address | 1 | 1 | 1/1/2017 | |
| 2 | B | B’s Address | 2 | 1 | 1/1/2017 | |
| 3 | C | C’s Address | 3 | 1 | 1/1/2017 | |
| 1 | 1 | 1/2/2017 | ||||
| 2 | 0 | 1/2/2017 | ||||
| 3 | 1 | 1/2/2017 |
Look at the above two result sets. StudentInfo table has student’s information; it has roll number, name and address columns. The attendance table contains daily attendance of the students; this table has the student’s roll number, present, and attendance date columns.
If you want to see a student’s name, address, present and attendance date in a new spreadsheet, you can only use one row at a time of a table. So, how would you do that?
In all probability, some of us will start with rollnumber 1 of the studentinfo table
- We shall copy the student’s name and address from Attendance table, paste it into a new spreadsheet,
- Then we shall copy all the Present and date from the attendance table for roll number 1 and paste it in the spreadsheet.
The result set will look something like this after filling the data of roll number 1:
| Name | Address | Present | Date |
| A | A’s Address | 1 | 1/1/2017 |
| A | A’s Address | 1 | 1/2/2017 |
Then we will repeat the same process for roll number 2 and roll number 3 after completing it all; your final result set will look somewhat like this:
| Name | Address | Present | Date |
| A | A’s Address | 1 | 1/1/2017 |
| A | A’s Address | 1 | 1/2/2017 |
| B | B’s Address | 1 | 1/1/2017 |
| B | B’s Address | 0 | 1/2/2017 |
| C | C’s Address | 1 | 1/1/2017 |
| C | C’s Address | 1 | 1/2/2017 |
If we try to convert what we did above in the pseudocode, then it will be like this:
For each row from StudentInfo table until end of Attendance table
Match row from table2
If StudentInfo.rollnumber = Attendance.rollnumber
Return (StudentInfo.name , StudentInfo.Address, Attendance.Present, Attendance.AttandanceDate)
Congratulations, now you already know how Nested Loop Join works.
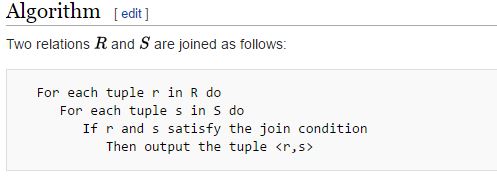
Now see this pseudocode about Nested Loop Join from Wikipedia:
And here is something from Craig Freedman’s blog about Nested Loop Join:

In a nutshell, the Nested Loop Join uses one joining table as an outer input table and the other one as the inner input table. The Nested Loop Join gets a row from the outer table and searches for the row in the inner table; this process continues until all the output rows of the outer table are searched in the inner table.
Nested Loop Join can be further categorized as Naive Nested Loop Join, Indexed Nested Loop Join and Temporary Index Nested Loop Join.
| Naive Nested Loop Join | The Nested Loop Join searches for a row in the entire inner side of the table / index (except semi-join); this is called a Naive Nested Loop Join. |
| Indexed Nested Loop Join | The Nested Loop Join searches for a row in the inner side of the index and seeks the index’s B-tree for the searched value(s) and then stops looking further; it is called an Index Nested Loop Join. |
| Temporary Index Nested Loop Join | A Temporary index Nested Loop Join is exactly like the Index Nested Loop Join. The only difference is that the temporary index is created at the run time of query and destroyed upon completion of the query; it is called a temporary index nested loop join. |
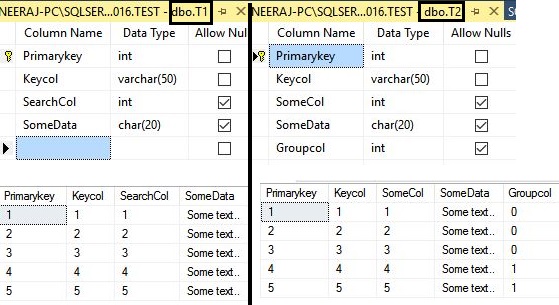
Now let us try to understand the Nested Loop Join with a few examples, and for that, we need to build at least two tables. In the example given below, we will use tables DBO.T1 and DBO.T2.
There are four columns in the DBO.T1 table: primarykey column, keycol column, searchcol column and somedata column. The DBO.T2 table is a replica of the DBO.T1 table, which consists only 300 rows, and it has one additional groupcol column which has repetitive integer values. Find the sample table structure and data in the following image:
You can find the sample table script below in the article. Now we have an idea about tables, so we can start with the examples of Nested Loop Join:
Naive Nested Loop Join
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM [DBO].[T1] JOIN [DBO].[T2] ON T1.keycol = T2.Keycol WHERE T1.Primarykey > 0 AND T1.Primarykey < 11 ORDER BY T1.Primarykey OPTION (RECOMPILE) |
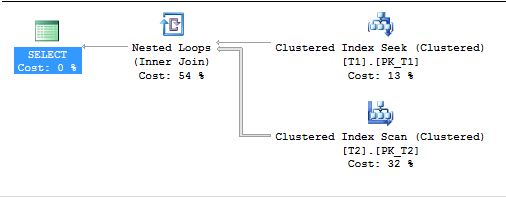
Look at the execution plan of the above query; you can see on the top right-hand side that there is a table named T1. In the execution plan, the table is displayed as tablename.indexname (if indexed), so here it is showing as T1.pk_T1; this is the outer table and the other one is the inner table.
As stated above in the article, data flow starts with the outer table. There is a range predicate on the DBO.T1 table and it starts with “>0”; so first it would seek for the first value which is 1 here and get all the associated columns of this row as requested by the query. The Nested Loop Join gets it and initiated the search to its associated keycol column in the entire inner table when it finds the matching row, then returns all the requested column as an output to the Nested Loop Join iterator; the Nested Loop Join merges both output columns and sends the result set to the parent iterator. This process keeps on repeating itself until the outer table stops sending rows to the Nested Loop Join. This entire process can be classified as a naive Nested Loop Join.
Indexed Nested Loop Join
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM DBO.[T1] JOIN DBO.[T2] ON T1.Primarykey = T2.Primarykey WHERE T1.SearchCol > 0 AND T1.SearchCol < 11 ORDER BY T1.Primarykey OPTION (RECOMPILE, FORCE ORDER, MAXDOP 1) |
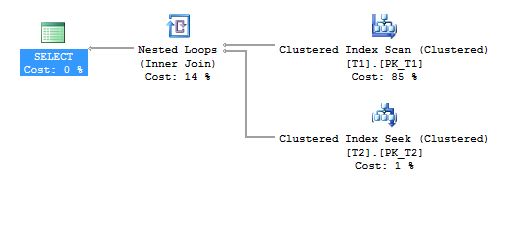
The above query is forced, so we all get the same execution plan shape. The above Nested Loop Join can be classified as indexed Nested Loop Join only for the reason that the inner side of the Nested Loop Join is indexed and seekable using the primarykey column; the explanation is almost same as Naive Nested Loop Join. Nested Loop Join gets the first value from the DBO.T1 table, then it seeks that value in the DBO.T2 table, but this time joining column is the primary key (unique clustered index) so there is no need to look for the entire index.
Temporary index nested loops join
Getting a temporary index in the Nested Loop Join is not common, since creating an index at runtime in the table requires additional cost to the query. The Query Optimizer creates a temporary index on the table when it finds that its cheap to create an index in the column compared to the non-index version of the same query. If you try to get comma separated values for a non-indexed group then there are chances to see temporary index with the Nested Loop Join on the inner table.
In our example, we have a groupcol column in the DBO.T2 table, so let us use comma separated value in the groupcol column and see the query and Execution plan below:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT Groupcol, STUFF((SELECT ',' + CONVERT(varchar, T2c.SomeCol) FROM [DBO].[T2] T2c WHERE T2.groupcol = T2c.groupcol FOR xml PATH ('')), 1, 1, ' ') CommaseperatedCOL FROM [DBO].[T2] GROUP BY Groupcol |
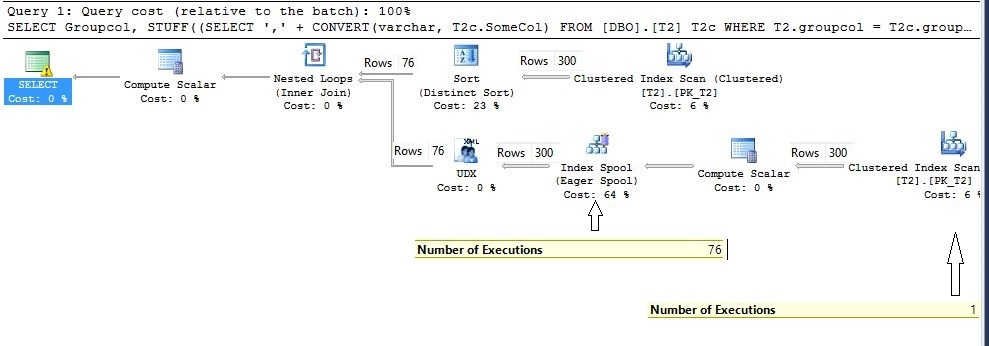
At the bottom of right side of an execution plan, there is an Index Spool (Eagar Spool), which is actually a temporary index on the groupcol column.
Explanation of execution plan:
Let’s now focus on the explanation, a bit more closely, this time. As usual, data flow starts from the top outer table, but this time our DBO.T2 table is the outer table, after fetching all the data from the top DBO.T2 table Distinct Sort iterator group all the data and passes the first value to the Nested Loop Join. On the other hand, execution starts from the inner side of DBO.T2 table, after concatenation of comma “,” (it is labeled as [Expr1002] column) this column is indexed, which is visible in the execution plan as Index spool, and after that all executions perform with this newly created index only. This can be confirmed by looking at the number of executions in the iterator’s properties. Just have a look at the execution plan above, inner side of the DBO.T2 table executed just once and index spool executed 76 times.
Costing details for Nested Loop Join for educational purpose only
The cost of the execution plan, whether its CPU, IO or any other costs do not reflect the actual cost of your hardware; these numeric values are just units of measurement used by the Query Optimizer to compare the execution plans as a whole. So a natural question arises: where do these costs come from?
The cost values were actually the number of seconds for which, that the query was expected to run on the engineer’s machine (“Nick’s machine”). Nick was the part of the Query Optimizer team and he was responsible for calculating query’s costs so he decided that if a query runs for 1 second on his own PC the cost will be 1 unit.
As this is a part of internal implementations, these costs may vary from version to version of the SQL Server. SQL Server’s Query Optimizer is a cost based optimizer, If a full cost-based optimization is performed, it creates multiple execution plans for the expressed query by the user and chooses the one which has the lowest overall cost. Each iterator in the execution plan has some cost which is roughly an addition of CPU, IO and some other variable information like histogram, data pages and statistics information etc.
The Nested Loop Join iterator does not have any initialization cost. Rather, it has got only cost per row and it does not require additional memory (except Batch sort or Implicit sort) like other join types such as hash join, which requires building a hash table in the memory and merge join requires to sort the inputs if not indexed on joining column(s).
Nested Loop Join costing is not documented, so we can only assume and this might change in the future.*
For the tests, we will create 2 basic tables with integer values, and then join those tables and finally try to identify CPU cost with different row counts, data pages count and with or without parallelism. With my quick testing, I came up with a rough formula for the CPU cost only, as there is no IO cost for the Nested Loop Join but operator costs may vary with other factors.
Below is the rough formula for CPU cost of Nested Loop Join:
| NL join CPU cost estimated formula | = 0.0000041800 * OTER * ITER |
| Parallel NL join CPU cost estimated formula | = (0.0000041800 * OTER *ITER ) / MIN (Cpu_for_query OR (Cpu_Count/2)) |
*OTER = Outer Table Estimated Rows.
*ITER = Inner Table Estimated Rows.
*Cpu_for_query = Available CPU for the query at the runtime.
*Cpu_Count= Available CPU for SQL Server instance.
*Results are calculated to decimal`s 7th place approx.
For example, if a machine has 16 CPU available, but it’s running with 4 CPU (restricted by the user) then the calculation would be: Convert (Decimal (25 ,7 ),( 0.0000041800 * OTER *ITER )) / 4.
If it’s running with all available CPUs then the calculation will be:
Convert (decimal (25 ,7), (0.0000041800 * OTER *ITER)) / 8, divided part is calculated as 16/2=8.
The interesting part about this test is NL’s CPU cost doesn’t change with the data types, data pages or with the table’s indexes. The testing is conducted with INT data type, but I tested it with CHAR, VARCHAR, NVARCHAR, NCHAR, DATETIME and CPU costing doesn’t change.
Unfortunately, my machine has only 4 virtual CPU available, so the CPU cost of the nested loop join won’t come down after DOP 2 as per the formula.
Below are the tests that I had conducted to get the above formula.**
Result and script below:
| Outer Table RC | Inner Table RC | Estimated Cpu Cost | Formula’s Calculation | Maxdrop |
| 1 | 1 | 0.0000042 | 0.0000042 | 1 |
| 1 | 10 | 0.0000418 | 0.0000418 | 1 |
| 1 | 766788 | 3.20517 | 3.2051738 | 1 |
| 88888 | 766788 | 284901 | 284901.4923 | 1 |
| 88888 | 766788 | 142451 | 142450.7461 | 2 |
| 88888 | 766788 | 142451 | 142450.7461 | 3 |
| 88888 | 766788 | 142451 | 142450.7461 | 4 |
*RC = Row Count
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
CREATE TABLE A1 ( a INT ) CREATE TABLE A2 ( a INT ) UPDATE STATISTICS a2 WITH ROWCOUNT = 1 UPDATE STATISTICS a1 WITH ROWCOUNT = 1 SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 1)) -- 0.0000042 SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE); GO UPDATE STATISTICS a2 WITH ROWCOUNT = 1 , pagecount =10000 UPDATE STATISTICS a1 WITH ROWCOUNT = 10 , pagecount =100000 SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 10)) --0.0000418 SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE); GO UPDATE STATISTICS a2 WITH ROWCOUNT = 1 UPDATE STATISTICS a1 WITH ROWCOUNT = 766788 SELECT CONVERT(decimal(25, 7), (0.0000041800 * 1 * 766788)) --3.2051738 SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE) UPDATE STATISTICS a2 WITH ROWCOUNT = 88888 UPDATE STATISTICS a1 WITH ROWCOUNT = 766788 SELECT CONVERT(decimal(25, 7), (0.0000041800 * 88888 * 766788)) --284901.4922899 SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 1, RECOMPILE) --Parallelism Test SELECT CONVERT(decimal(25, 7), (0.0000041800 * 88888 * 766788)) / 2 --142450.746144950 SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 2, RECOMPILE) SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 3, RECOMPILE) SELECT * FROM a1 JOIN a2 ON a1.a = a2.a OPTION (LOOP JOIN, MAXDOP 4, RECOMPILE) |
This article is just an introduction to Nested Loop Join. It offers a lot of variety than what people can think of. The next part in this series will build on the foundations provided in this introduction.
You can download the script to populate the Sample table here.
Footnotes
* I have tested it on Microsoft SQL Server 2016 (RTM) – 13.0.1601.5 and Microsoft SQL Server 2014 – 12.0.4100.1 (X64)
** In the test to influence the outer and inner table estimated rows, I used undocumented and unsupported update statistics options, which is not meant to be used for the production servers.
The next article in this series
See more
Consider these free tools for SQL Server that improve database developer productivity.
Useful links
- Understanding Hash Joins
- Understanding Merge Joins
- Execution plan costs
- What estimated subtree cost means
- Update statistics undocumented options


- Nested Loop Joins in SQL Server – Batch Sort and Implicit Sort - September 1, 2017
- Parallel Nested Loop Joins – the inner side of Nested Loop Joins and Residual Predicates - May 22, 2017
- Introduction to Nested Loop Joins in SQL Server - May 8, 2017