
This is the second article in the “Backup and Restore (or Recovery) in SQL Server” stairway series (see the full TOC below). This article deals with the different phases of data management life cycle and it encompasses the following topics:
- Introduction to data corruption
- Defining data corruption and its causes
- Discussion on the impact of data corruption
- Explaining data prevention mechanisms
- Data protection
- And more…
Introduction to Data Corruption
Data is said to be corrupted when it attains an undesirable state different from the original data. Data corruption also refers to data errors that can occur during any of the stages of data writing, data processing or even reading, at the storage, or during transmission.
We all know that at the very core, data is nothing but a series of 1s and 0s. When data is written, what actually happens is that the 1s and 0s are written to the destination. This sequence of 1s and 0s is interpreted during the data reading operation, giving it some meaning. If these bits don’t get written in the intended sequence, the data is said to have been corrupted.
Small data means smaller sequences, and relatively lower chances of corruption. When the amount of data increases, the chances of corruption also increases. The chances are particularly high when data generation is high, and the subsequent storage operations hit unprecedented rates.
Some of the most common reasons for data corruption include hardware or software issues with regard to I/O subsystems.
Causes of Data Corruption
- Hardware issues or failures
- Memory issues
- Power failure or outages
-
I/O subsystem
- SAN controllers
- RAID controllers
- Disk drivers
- Bad sectors on the disks
- Operating System errors
- Virus attacks
- Antivirus, defraggers, even data encryption,
- SQL Server bugs
- Human errors
- Improper shutdown
- Hard reset
Effects of corruption
In general, SQL Server isn’t aware of data corruption until it comes across errors when accessing a resource that’s corrupt. Therefore, the issue is that if the data wasn’t backed up before the corruption occurred, there would be no way to retrieve the data, which would mean permanent data loss.
Let’s consider a scenario where a mission-critical application database encountered data corruption. Let us remember that SQL Server doesn’t notice corrupt data until it tries to access it. Suppose a certain chunk of data was not read for a few weeks, because there was no necessity to, and data backup retention period was over resulting in the backup being purged. And then one day, after the backup containing the data was purged, someone queried the data, and SQL Server reported that it was corrupt. The value of the data chunk and the impact of the loss to the business depend on the nature of that data. Had the issue been detected within the span when the data could’ve been restored, the process may have even been considered insignificant. Now, however, this may be a loss to the business or a loss of job for the database administrator. Performing required data consistency checks on the database at regular intervals is a critical responsibility of a database administrator.
Preventing corruption
SQL Server has several built-in commands to mitigate the effects of corruption on the data during data operations.
Monitor the databases for signs of corruptions
One of the ways to look for data corruption is by enabling the CHECKSUM option for page verification.
|
1 |
ALTER DATABASE ProdSQLShackDemo SET PAGE_VERIFY CHECKSUM |
This automatically checks the integrity of the data even as it is read from the table. All page verification operations are performed in the buffer pool.
Implementing a backup strategy
If the data is stored over an extended period of time, then CHECKSUM is not a good-enough option to validate the data. In those cases, we need to predominantly depend on the database consistency checker commands.
Early detection is the key for successful data management. The sooner we notice issues, the easier it would be to manage these issues and the easier would it be to control the situation.
Always plan for a good backup strategy. A good backup strategy is always helpful, and helps recover from any disaster. Not only does it guarantee smooth functioning of the business, but also protects the data against user-caused errors, along with other types of failures.
Having options
It’s best to never place all of your eggs in the same basket. That is, it’s always better to have multiple options of recovery—as many as possible. However, no matter how many options we have, they’ll be helpful only when the issue is detected at an early stage. If not, the corruption may become too expensive to handle.
SQL Server has a number of built-in tools to check the structure of the databases and their internals using DBCC commands that provide useful information to troubleshoot corruption issues. These commands can be divided into four categories:
- Informational commands
- Validation commands
- Maintenance commands
- Miscellaneous commands
The most comprehensive check for data corruption can be done using the DBCC CHECKDB command.
- It runs DBCC CHECKALLOC to check the consistency of disk space allocation structures, runs CHECKTABLE to check the table structure and pages for corruption, and then, runs CHECKCAALOG to validate the catalog consistency.
- It validates every index view
- It validates the links between the files on the disk, and in the metadata store of the table for filestream-enabled databases.
- It validates the service broker data.
We have three options for the DBCC CHECKDB command:
- Repair allow data loss, which deallocates pages and wipes out the data
- Repair Fast, which is used for backward compatibility
- Repair Build, which yields to no data loss. It performs quick repairs on missing rows and non-clustered indexes.
It’s interesting to know that the DBCC commands actually create an internal snapshot of the database, and then performs checks against that snapshot. This prevents concurrency issues. There are a few instances where the snapshot isn’t created, as well, for example, in a read-only database or a database in single-user mode or using hints.
On a VLDB database, CHECKDB command may take a while to complete. If the database design uses multiple file groups, we can reduce the load by initiating the CHECKDB process on individual file groups. It can also be scheduled to run at a larger interval, such as alternate days in place of every day.
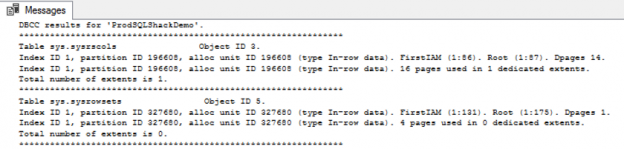
Let’s now dive into some examples to understand the DBCC concepts and syntax:
|
1 2 3 4 5 6 7 8 9 |
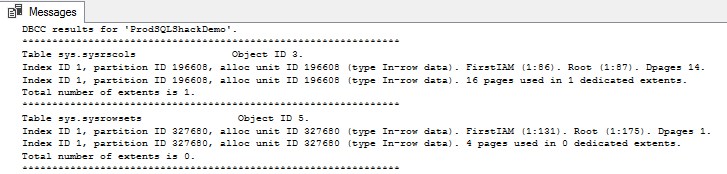
-- Chnge the databases USE ProdSQLShackDemo; GO -- run DBCC command DBCC CHECKDB; GO -- The CHECKDB runs the following three console commands DBCC CHECKALLOC; |
|
1 2 3 4 5 6 7 8 9 |
DBCC CHECKTABLE ('SQLShackAuthor') WITH PHYSICAL_ONLY; DBCC CHECKCATALOG WITH NO_INFOMSGS DBCC CHECKCATALOG (ProdSQLShackDemo); -- Checktable can be further simplified for specific index DECLARE @indid int; SET @indid = (SELECT index_id FROM sys.indexes WHERE object_id = OBJECT_ID('SQLShackAuthor') AND name like '%PK__SQLShack__3214EC27014935CB%') DBCC CHECKTABLE ('SQLShackAuthor',@indid); |

|
1 2 3 4 5 6 7 8 9 10 |
-- If corruptions are identified the repair options are available -- database must be in single user mode DBCC CHECKDB ('ProdSQLShackDemo', REPAIR_ALLOW_DATA_LOSS); -- REPAIR_FAST or REPAIR_REBUILD -- CHECKFILEGROUP for specific filegroup USE ProdSQLShackDemo; GO DBCC CHECKFILEGROUP (0, NOINDEX) WITH PHYSICAL_ONLY, ESTIMATEONLY; GO |

With the CHECKFILEGROUP command, we need to specify the name of the file group or its filegroupID. In this example, 0 is used, which represents primary filegroups. The NOINDEX option ignores the non-clustered index and runs only for clustered indexes and heap. The physical_only option validates the structure of the data pages, page headers and structure of the files on the disk. The estimate_only option figures out how much space is required in tempdb to create the snapshot.
Protecting the database
Database protection is the process of safeguarding the data from corruption. We are in the era of little-to-no tolerance for outages and downtime. Hence, data protection is the key for many successful organizations.
Data protection can be classified further into Availability and Management
Data availability is a process to ensure to smoothly run the business without any interruptions or data loss.
Data management is a process used to understand the nature of the data, govern the data in such a way that the data is available at any cost irrespective of any forms corruption and it’s agreed with the framework of business policy and government bodies. Here are a few points to keep in mind:
- Detect issues early
- Have a good backup strategy
- Run DBCC commands frequently
SQL Server has several built-in mechanisms called page protection options to automatically identify data corruption.
- TORN_PAGE_DETECTION allows SQL Server to identify incomplete writes.
- CHECKSUM uses negligible CPU and is an error-detection mechanism, however, is not a protection mechanism. It does a comprehensive evaluation of the data pages and is the recommended option to use while deciding the data protection and backup protection process.
Summary
It’s important for any database administrator to understand the data lifecycle and the nature of the particular business, in order to have the ability to recover artifacts of business value from any sort of data disruptions.
There are a number of ways in which corruption can creep into the system, and what makes it worse is its random nature, on when and where it occurs. In other words, corruption can never be eliminated from the systems. The administrators should perform proactive monitoring and guard the data against undesirable but inevitable issues of corruption. If corruption gets more frequent, then you should start working on a migration plan to move the database to a new hardware.
Educate yourself—As the preceding points have noted, many causes of data corruption and loss can be avoided by taking appropriate measures to protect your data and avoid the common causes of data corruption.
Implement a comprehensive Backup and Restore/Recovery solution and test it regularly to ensure everything is squeaky clean.
Repair options should be considered as the last resort. It is advisable to make sure that you’re working on a cloned copy of the database; that way you can investigate what data, if any, was actually lost or modified.
Understand the scope of the business before tailoring the high availability feature set for the enterprise. No matter what high availability features we enable, ultimately, in most of the cases, recovering from a corruption relies on having a good backup strategy and routine monitoring.
Table of contents
References

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021