
In the previous article, Analysis Services (SSAS) Multidimensional Design Tips – Data Source View and Cubes, we discussed best practices for SSAS Multidimensional cubes and data source views. In this article, we continue the series with design tips for creating dimensions as the subject. As with the previous article, most tips are suited for SSAS 2008 (most likely 2005 as well) to 2016 and later versions. Analysis Services Tabular is not covered in this article.
The best practices listed in this overview is a selection made by the author, as they are considered basic for a good dimension design. However, best practices are not carved in stone and sometimes you can deviate from them.
As in the previous article, examples and screenshots are created with the AdventureWorks 2014 Enterprise sample OLAP cube, which can be retrieved from Codeplex.
Source Data
Most likely the source data for a dimension will be derived from a data warehouse. As with cubes, make sure any calculates are done in the database layer, either persisted in the dimensions itself or in a view on top of the dimension. An example is creating a full name: FirstName + “ “ + LastName. Avoid doing such calculations in the data source view.
Although traditional dimension modeling – as explained by Ralph Kimball – tries to avoid snowflaking, it might help the processing of larger dimensions. For example, suppose you have a large customer dimension with over 10 million members. One attribute is the customer country. Realistically, there should only be a bit over 200 countries, maximum. When SSAS processes the dimension, it sends SELECT DISTINCT commands to SQL Server. Such a query on top of a large dimension might take some time. However, if you would snowflake (aka normalize) the country attribute into another dimension, the SELECT DISTINCT will run much faster. Here, you need to trade-off performance against the simplicity of your design.
Creating a Dimension
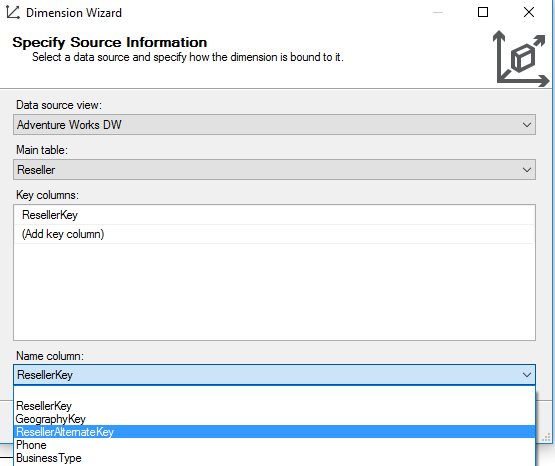
When you create a dimension with the wizard, you need to choose a key column. Make sure all your dimensions have a surrogate key. This will help with identifying a key column for your dimension but also with creating relationships between the fact tables and the dimensions.
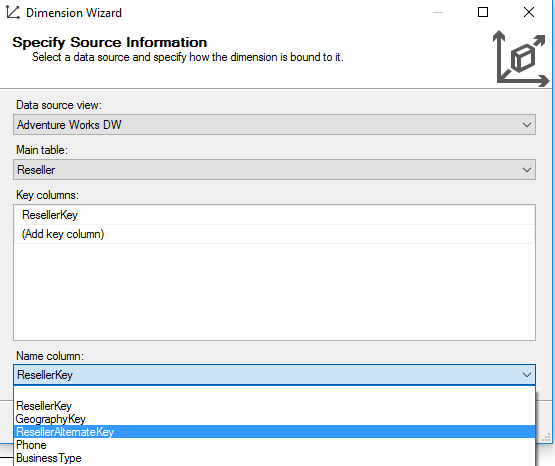
If possible, you can assign another attribute to the name column, for example, the business key of your dimension. This is an extra attribute less in your dimension (read: less confusion for end users).
Only include columns of the dimension that you will actually need. It’s might be better to start off with a small subset and only include new columns after explicit request. The more attributes, the longer processing is, the more storage you need, the more indexes and aggregations the cube must build. Smaller dimensions lead to faster cubes.
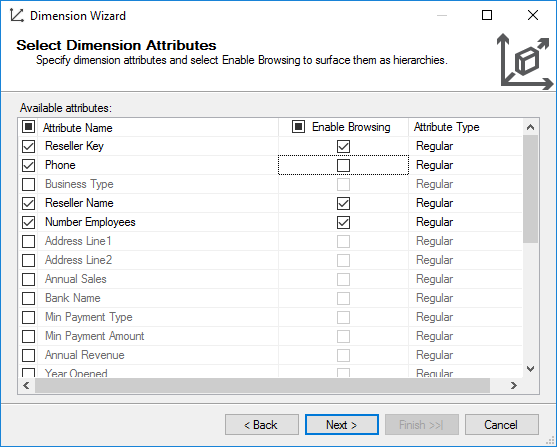
For member properties (more about them in another section), disable Enable Browsing. At the end of the wizard, give the dimension a proper name. Remember that if you rename the dimension later, there will be a mismatch between the name of the dimension and its ID. It can be confusing when you are scripting out objects with XMLA.

Basic Dimension Properties
Any attribute a user won’t use directly needs to be hidden. For example, you can hide the surrogate key of your dimension or attributes you used to sort other attributes. You can hide attributes using the AttributeHierarchyVisible property.
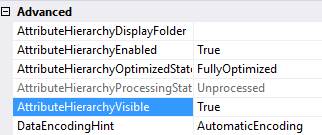
Like the key column, if you have two columns – one for the code and one for a description – try to combine them into one single dimension attribute. You can do this using the KeyColumns and NameColumns properties.
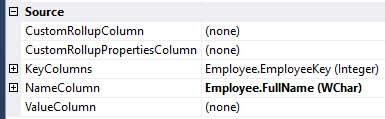
The value column is used when you want to pass a value of a specific data type to the front-end tool. For example, suppose you have three attributes to describe a specific date:
- An integer, which is the key column: 20170101
- A string, which gives you a nice formatted value for displaying purposes: January 2017, 1st
- A date value, which is in the date data type: 2017-01-01
The string is used as the name column. Now, suppose you have a client tool – like Power BI Desktop or Excel – that allows for relative date filtering. For example, select the current month. In this case, the client tool needs an actual date value. This is what the value column is for. By using these properties, you can combine three distinct attributes into a single attribute. Remember Power BI Desktop separates the key/name column from the value column when you connect using a live connection:
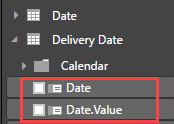
To help users with navigating larger dimensions, you can assign attributes to display folders. In the client tools, the attributes will be shown as children of the display folder.
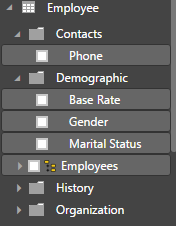
You can set the display folder using the AttributeHierarchyDisplayFolder property.
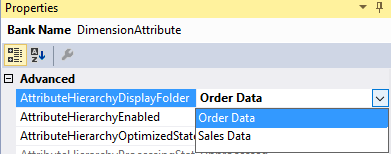
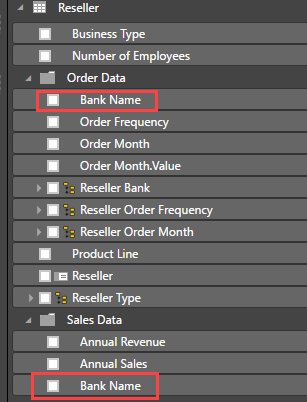
You can also assign attributes to multiple display folders by concatenating them using the semi-colon as a delimiter.
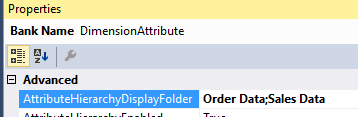
The Bank Name attribute can now be found in the two display folders:
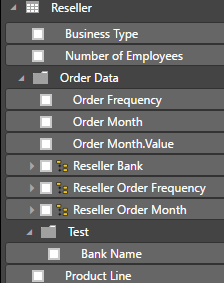
Or you can nest display folders by using a backslash.
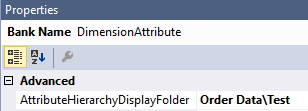
Test is now a child folder of the Order Data folder:
Some dimensions need to have a specific type for some MDX functions to work properly. The most common examples are the Time dimension (needed for time intelligence functions) and the currency dimension (needed for the currency conversion wizard).
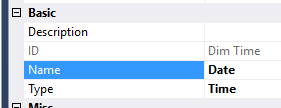
Be aware that a cube can have only one date dimension. In the case where you have multiple role-playing date dimensions (all set as type Time), only the dimension at the top of the cube dimension list will be effectively used as a time dimension. This has an impact on for example semi-additive aggregates, such as LastNonEmpty and LastChild. Those measures will only work against the first listed time dimension. In the screenshot, this is the Date dimension.

Conclusion
In this article, we went over the best practices you can apply when creating a dimension in Analysis Services Multidimensional with the Create Dimension Wizard. We also looked at how we can model the source data and we examined some basic attribute properties.
More design tips and best practices about dimensions – hierarchies, member properties etc. – will be discussed in a next article.
Other articles in this series
- Analysis Services (SSAS) Multidimensional Design Tips – Data Source View and Cubes
- Analysis Services (SSAS) Multidimensional Design Tips – Relations and Hierarchies
Reference Links
- Create a Dimension by Using an Existing Table
- Common Analysis Services design mistakes and how to avoid them
- Dimension Attribute Properties Reference

Koen has over 7 years of experience in developing data warehouses, cubes, and reports using the Microsoft BI stack. Somehow he has developed a particular love for Integration Services along the way.
He has a blog at http://www.sqlkover.com and he is a frequent speaker at local SQL Server events. You can find him on Twitter as @Ko_Ver.
View all posts by Koen Verbeeck