
In our previously published articles in this series, we talked about many SSIS Hadoop components added in SQL Server 2016, such as the Hadoop connection manager, Hadoop file system task, HDFS file source, and HDFS file destination.
In this article, we will be talking about Hadoop Hive and Hadoop Pig Tasks. We will first give a brief overview of Apache Hive and Apache Pig. Then, we will illustrate the related SSIS Hadoop components and alternatives.
Apache Hive
Apache Hive is an open-source data warehousing software developed by Facebook built on the top of Hadoop. It allows querying data using a SQL-like language called HiveQL or using Apache Spark SQL. It can store data within a separate repository, and it allows building external tables on the top of data stored outside Hive repositories.
In general, these technologies work perfectly under Linux operating systems, but it can also be installed on Windows using the Cygwin tool (check the external links section for more information).
Apache Pig
Apache Pig is an open-source framework developed by Yahoo used to write and execute Hadoop MapReduce jobs. It is designed to facilitate writing MapReduce programs with a high-level language called PigLatin instead of using complicated Java code. It also can be extended with user-defined functions.
Apache Pig converts the PigLatin scripts into MapReduce using a wrapper layer in an optimized way, which decreases the need to optimize scripts manually to improve their efficiency.
Similar to Apache Hive and other software, this technology works better on Linux-based operating systems, while it can be installed on Windows (check the external links section for more information).
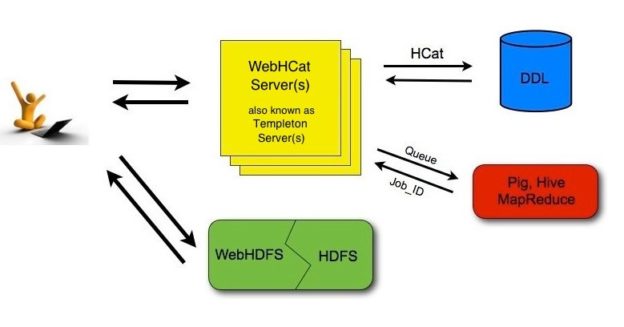
WebHDFS and WebHCat services
As we mentioned in the first article in this series, there are two types of connections within the Hadoop connection manager: (1) WebHDFS used for HDFS commands and (2) WebHCat used for apache Hive and Pig tasks.
It is worth to mention that WebHDFS and WebHCat are two REST APIs used to communicate with Hadoop components. These APIs allow us to execute Hadoop-related commands regardless of the current operating system and if Hadoop can be accessed via shell commands. Note that WebHDFS is installed with Hadoop, while WebHCat is installed with Apache Hive.
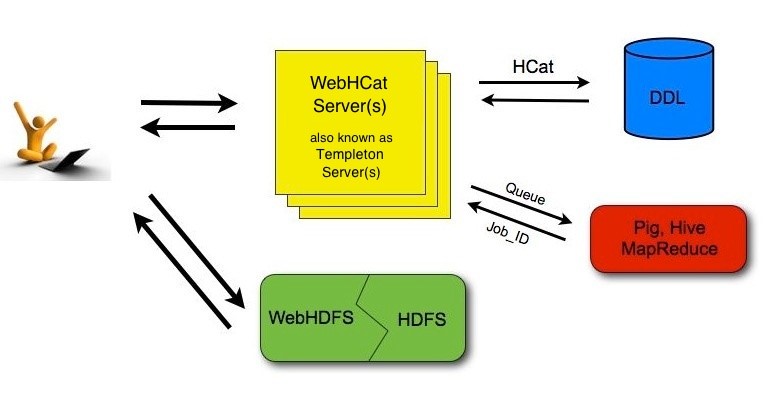
Figure 1 – WebHDFS and WebHCat APIs (Reference)
To start the WebHCat API, you should run the following command:
$HIVE_HOME/hcatalog/sbin/webhcat_server.sh start
Connecting to WebHCat using Hadoop connection manager
Connecting to WebHCat is very similar to WebHDFS, as explained in the first article. Noting that the default port is 50111.
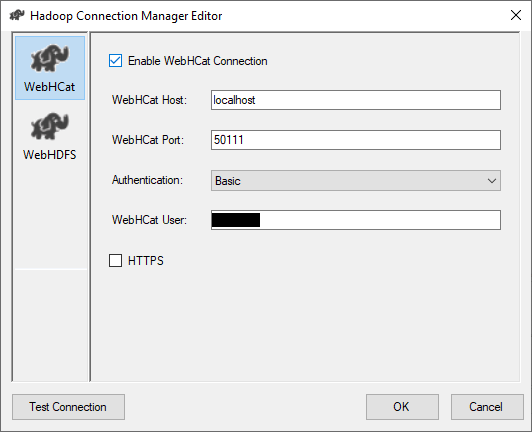
Figure 2 – Configuring WebHCat connection
To make sure that connection is well configured, we can use the “Test connection” button.
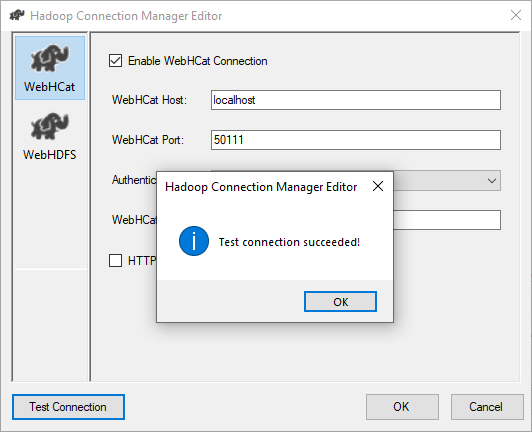
Figure 3 – Testing connection
Hadoop Hive Task
The Hadoop component related to Hive is called “Hadoop Hive Task”. This component is designed to execute HiveQL statements. It uses a WebHCat Hadoop connection to send a statement to the Apache Hive server.
This Hadoop component is very simple, as shown in the screenshot below, its editor contains only a few parameters to configure:
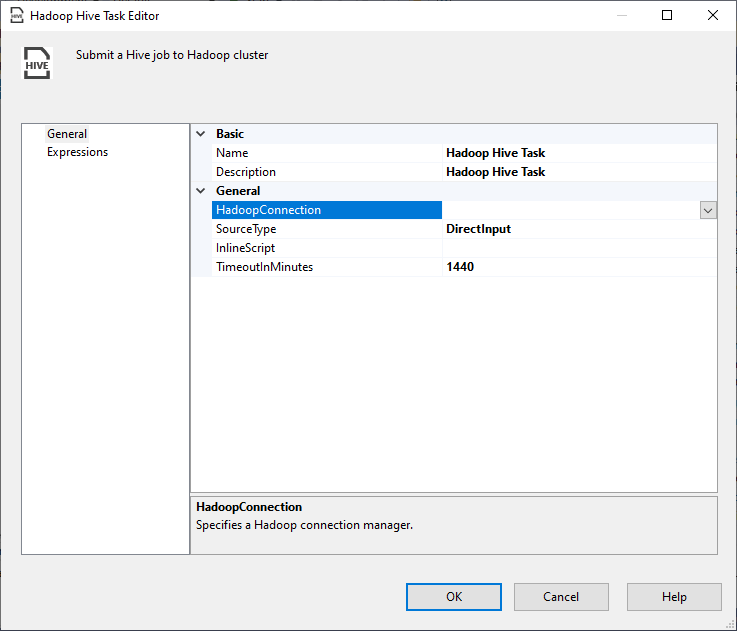
Figure 4 – Hadoop Hive Task editor
- Name: The task name
- Description: The task description
- HadoopConnection: We should select the related Hadoop connection manager
- SourceType: There are two choices:
- DirectInput: Write a HiveQL script manually
- ScriptFile: Use a script file stored within Hadoop
- InlineScript: (available for DirectInput Source), we should write here the HiveQL statement
- HadoopScriptFilePath: (available for ScriptFile Source), we should specify the Hadoop file path
- TimeoutInMinutes: The command timeout in minutes: If zero is entered, then the command will run asynchronously
Example
To run an example, we used to used the following HiveQL statement to create a Hive table:
|
1 |
CREATE TABLE IF NOT EXISTS employee (eid int, name String, salary String, destination String) STORED AS TEXTFILE; |
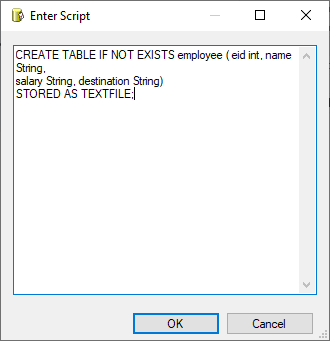
Figure 5 – HiveQL script
After executing the package, we started the Hive shell from a command prompt and executed the following command to show available tables within the default database:
|
1 |
SHOW TABLES; |
The result shows that the employee table is created:
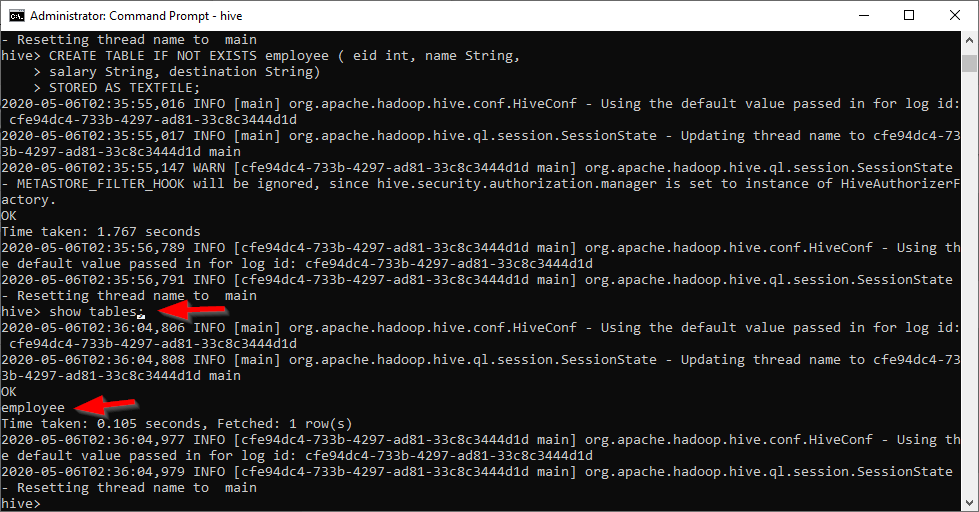
Figure 6 – Created table shown from the Hive shell
Synchronous vs. Asynchronous commands
To illustrate the difference between synchronous and asynchronous commands, we ran the following experiment:
First, we set the “TimeoutInMunites” property to 1440 (default) and executed the package. As shown in the screenshot below, the immediate window keeps showing the execution information sent from the Hive server.
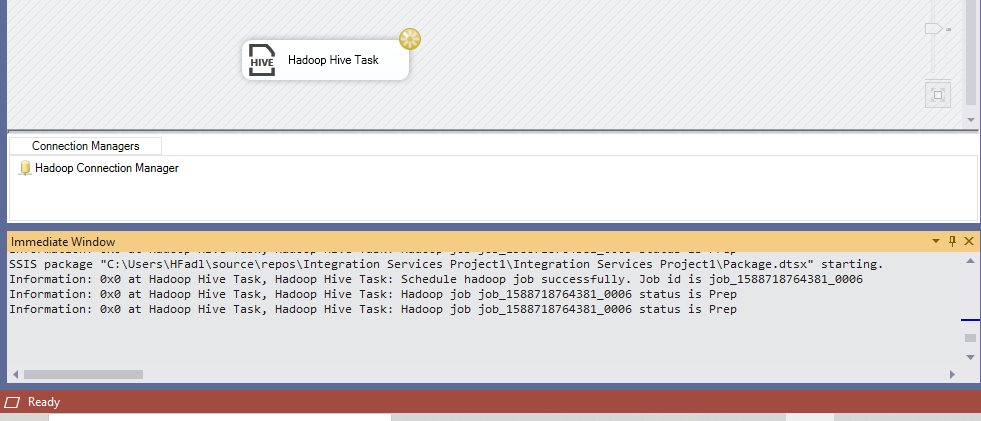
Figure 7 – Synchronous task execution
If we set the TimeoutInMinutes property to 0 and we execute the package, the task shows that it is completed successfully one a job is scheduled in the Hadoop cluster.
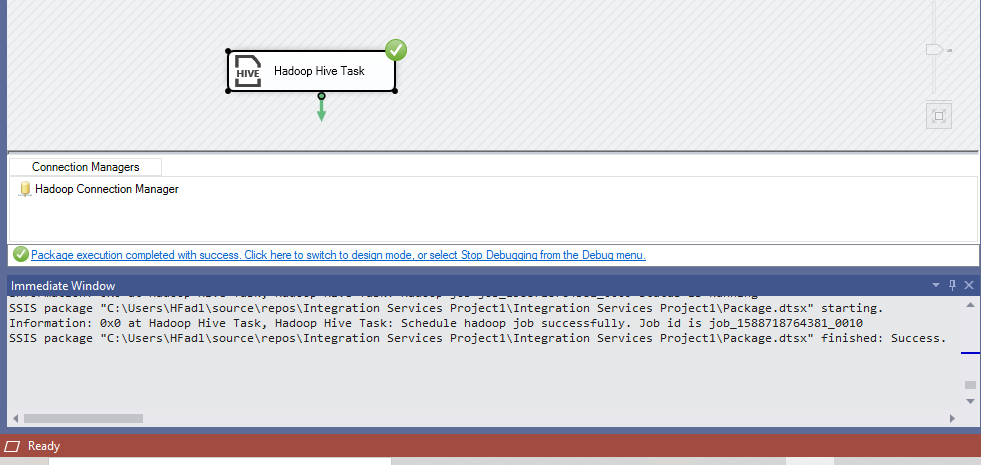
Figure 8 – Asynchronous task execution
Hadoop Pig Tasks
The Hadoop component related to Apache Pig is called the “Hadoop Pig task”. This component is almost the same as Hadoop Hive Task since it has the same properties and uses a WebHCat connection. The only difference is that it executes a PigLatin script rather than HiveQL.
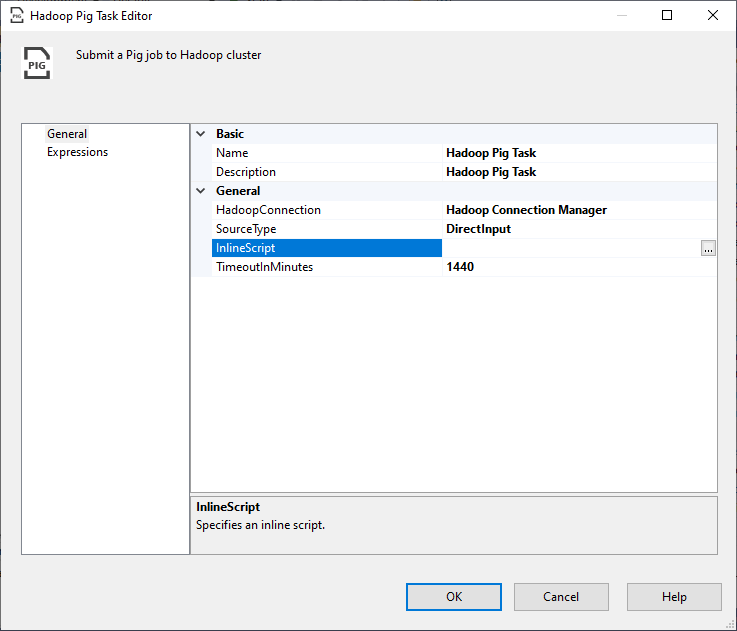
Figure 9 – Hadoop Pig Task editor
SSIS Hive Hadoop component alternative: Microsoft Hive ODBC driver
There is another method available to connect with the Apache Hive server in SSIS other than using the SSIS Hadoop components, which is the Microsoft Hive ODBC Driver. This allows creating an ODBC connection with Apache Hive. ODBC Driver connects directly to the running Hive server (HiveServer1 or HiveServer2).
First, we should download the driver from the official Microsoft Download Link. Note that there are two drivers (32-bit and 64-bit). After downloading and installing the driver, we should add an ODBC source following these steps:
- Navigate to Control Panel > System and Security > Administrative Tools
-
Open the ODBC Data Sources (32-bit or 64-bit)

Figure 10 – ODBC Data Sources shortcuts
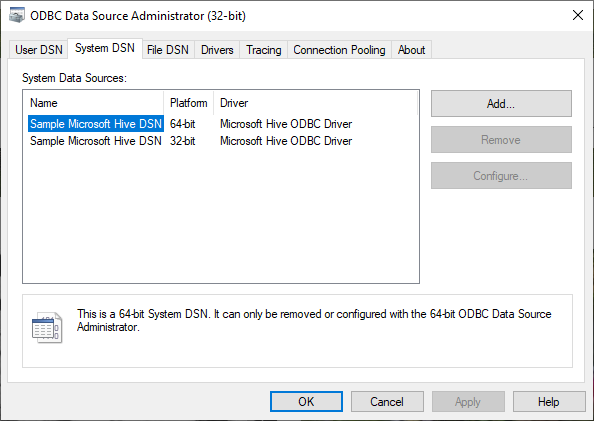
We should add a User or System DSN (note that Sample System DSN was created during installation)
Figure 11 – Sample Microsoft Hive DSN
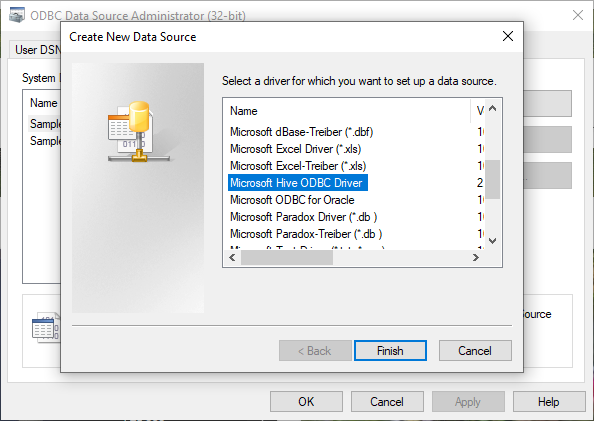
After clicking on Add button, we should select Microsoft Hive ODBC driver from the drivers’ list
Figure 12 – Selecting Microsoft Hive ODBC driver
-
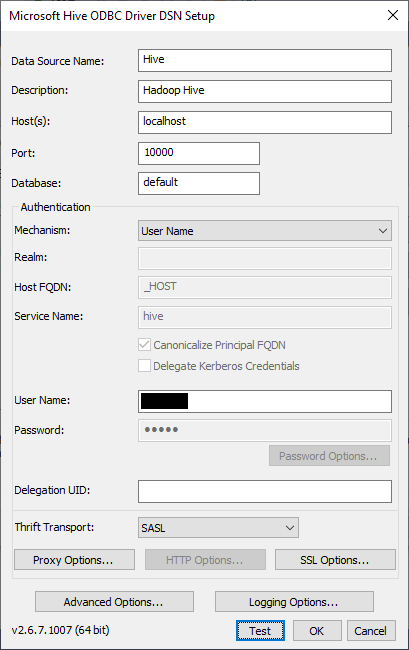
Now we should configure the Hive ODBC driver DSN:
- Host: the Hive server host address
- Port: the Hive server port number
-
Database: the database name
Figure 13 – Microsoft Hive ODBC DSN setup
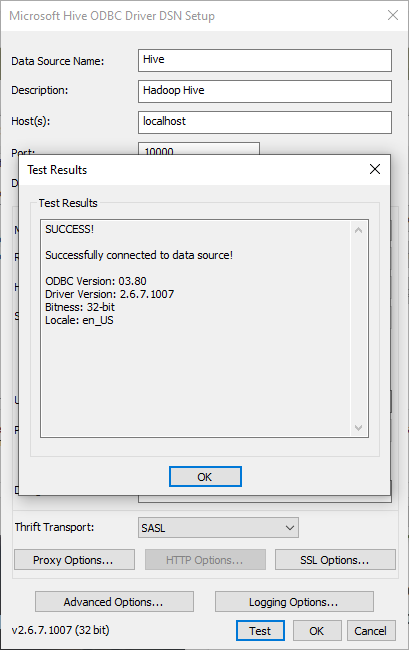
We should test the connection before creating the ODBC DSN
Figure 14 – Testing connection
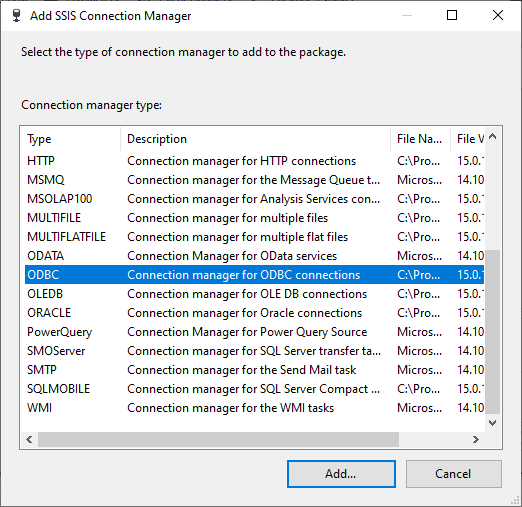
After creating the ODBC DSN, we should create a new ODBC connection manager in SSIS:
Figure 15 – Adding ODBC connection manager
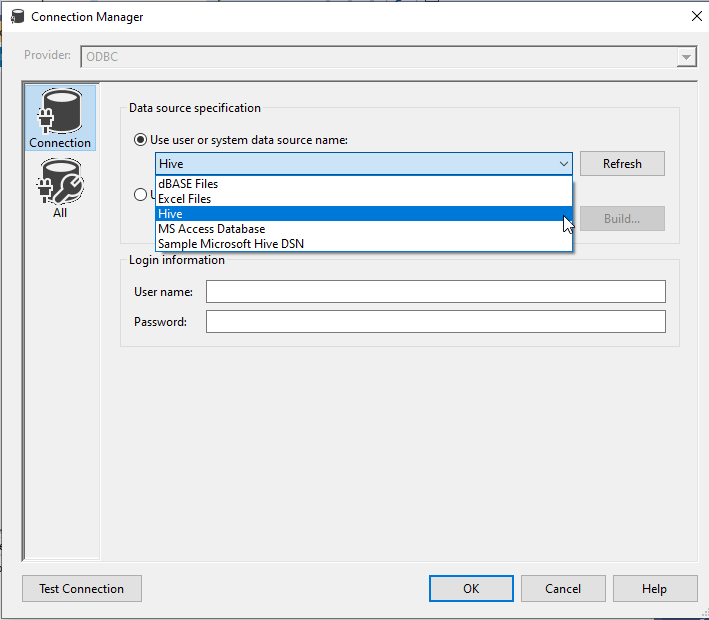
Then we should select the ODBC DSN we created while configuring the connection manager:
Figure 16 – Using the created DSN in the connection manager
Advantages
Using Microsoft Hive ODBC driver has many benefits:
- It can be used with earlier versions of SQL Server (before 2016)
- We can use apache Hive as a source or destination within the data flow task
- It can be used for cloud-based and on-premise Hadoop clusters
- Many SSIS components can use ODBC connections (example: Execute SQL Task)
External Links
- Installing Hadoop 3.2.1 single node cluster on Windows 10 step-by-step guide
- Installing Apache Hive 3.1.2 on Windows 10 step-by-step guide
- Installing Apache Pig 0.17.0 on Windows 10 step-by-step guide
Conclusion
In this article, we talked about the Apache Hive and Apache Pig. Then, we explained what WebHDFS and WebHCat services are. We illustrated the Hive and Pig related Hadoop components in SSIS. And Finally, we showed how to use Microsoft Hive ODBC driver as an alternative of the Hive Hadoop Component.
Table of contents
| SSIS Hadoop Connection Manager and related tasks |
| Importing and Exporting data using SSIS Hadoop components |
| Connecting to Apache Hive and Apache Pig using SSIS Hadoop components |

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023