
In addition to specifically addressing database normalization in SQL Server, this article will also address the following questions:
- Why is a database normalized?
- What are the types of normalization?
- Why is database normalization important?
- What is database denormalization?
- Why would we denormalize a database?
So, let’s get started with normalization concepts…
According to Wikipedia …
“Database normalization is the process of restructuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as an integral part of his relational model.
Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design).”
Database normalization
Database Normalization is a process and it should be carried out for every database you design. The process of taking a database design, and apply a set of formal criteria and rules, is called Normal Forms.
The database normalization process is further categorized into the following types:
- First Normal Form (1 NF)
- Second Normal Form (2 NF)
- Third Normal Form (3 NF)
- Boyce Codd Normal Form or Fourth Normal Form ( BCNF or 4 NF)
- Fifth Normal Form (5 NF)
- Sixth Normal Form (6 NF)
One of the driving forces behind database normalization is to streamline data by reducing redundant data. Redundancy of data means there are multiple copies of the same information spread over multiple locations in the same database.
The drawbacks of data redundancy include:
- Data maintenance becomes tedious – data deletion and data updates become problematic
- It creates data inconsistencies
- Insert, Update and Delete anomalies become frequent. An update anomaly, for example, means that the versions of the same record, duplicated in different places in the database, will all need to be updated to keep the record consistent
- Redundant data inflates the size of a database and takes up an inordinate amount of space on disk
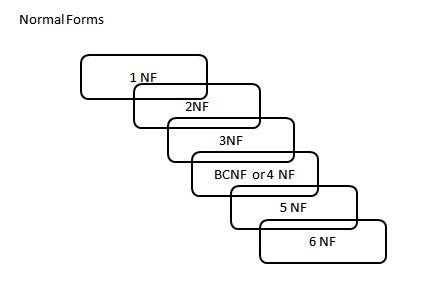
Normal Forms
This article is an effort to provide fundamental details of database normalization. The concept of normalization is a vast subject and the scope of this article is to provide enough information to be able to understand the first three forms of database normalization.
- First Normal Form (1 NF)
- Second Normal Form (2 NF)
- Third Normal Form (3 NF)
A database is considered third normal form if it meets the requirements of the first 3 normal forms.
First Normal Form (1NF):
The first normal form requires that a table satisfies the following conditions:
- Rows are not ordered
- Columns are not ordered
- There is duplicated data
- Row-and-column intersections always have a unique value
- All columns are “regular” with no hidden values
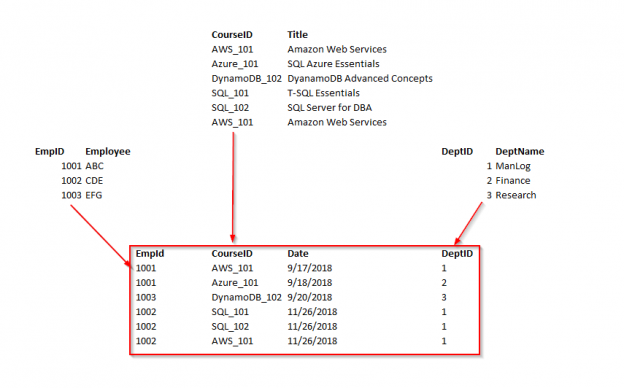
In the following example, the first table clearly violates the 1 NF. It contains more than one value for the Dept column. So, what we might do then is go back to the original way and instead start adding new columns, so, Dept1, Dept2, and so on. This is what’s called a repeating group, and there should be no repeating groups. In order to bring this First Normal Form, split the table into the two tables. Let’s take the department data out of the table and put it in the dept table. This has the one-to-many relationship to the employee table.
Let’s take a look at the employee table:

Now, after normalization, the normalized tables Dept and Employee looks like below:
Second Normal Form and Third Normal Form are all about the relationship between the columns that are the keys and the other columns that aren’t the key columns.
Second Normal Form (2NF):
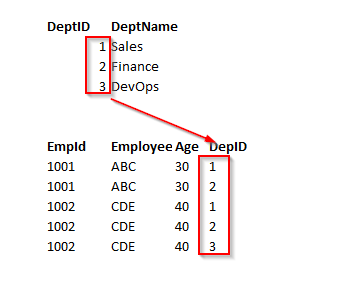
An entity is in a second normal form if all of its attributes depend on the whole primary key. So this means that the values in the different columns have a dependency on the other columns.
- The table must be already in 1 NF and all non-key columns of the tables must depend on the PRIMARY KEY
- The partial dependencies are removed and placed in a separate table
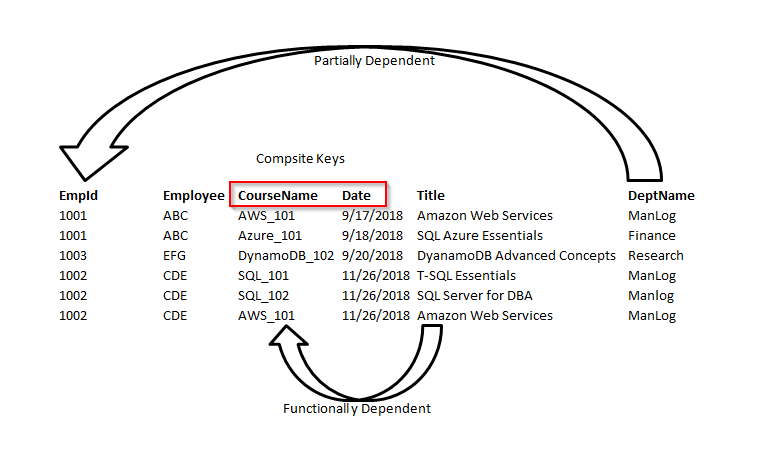
Note: Second Normal Form (2 NF) is only ever a problem when we’re using a composite primary key. That is, a primary key made of two or more columns.
The following example, the relationship is established between the Employee and Department tables.
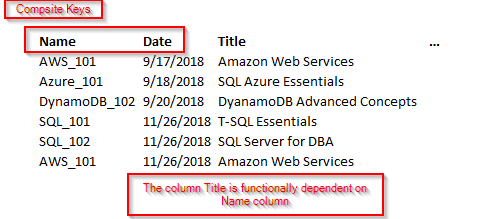
In this example, the Title column is functionally dependent on Name and Date columns. These two keys form a composite key. In this case, it only depends on Name and partially dependent on the Date column. Let’s remove the course details and form a separate table. Now, the course details are based on the entire key. We are not going to use a composite key.

Third Normal Form (3NF):
The third normal form states that you should eliminate fields in a table that do not depend on the key.
- A Table is already in 2 NF
- Non-Primary key columns shouldn’t depend on the other non-Primary key columns
- There is no transitive functional dependency
Consider the following example, in the table employee; empID determines the department ID of an employee, department ID determines the department name. Therefore, the department name column indirectly dependent on the empID column. So, it satisfies the transitive dependency. So this cannot be in third normal form.
In order to bring the table to 3 NF, we split the employee table into two.
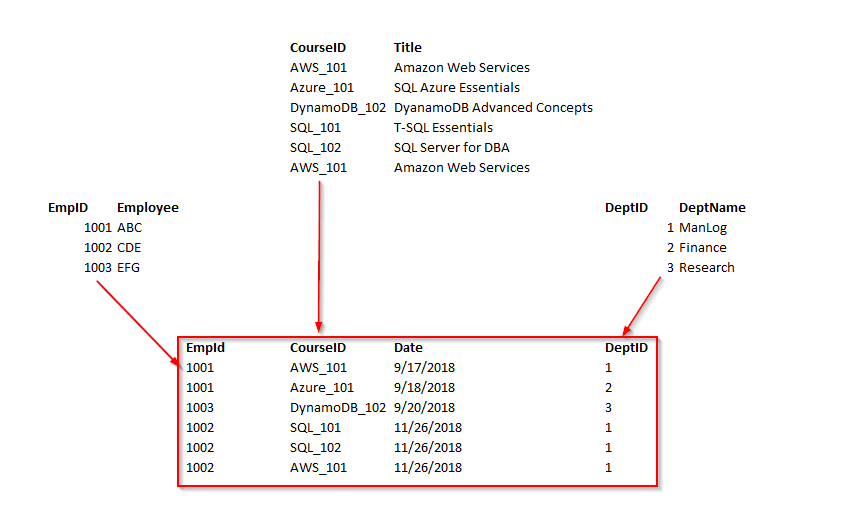
Now, we can see the all non-key columns are fully functionally dependent on the Primary key.
Although a fourth and fifth form does exist, most databases do not aspire to use those levels because they take extra work and they don’t truly impact the database functionality and improve performance.
Denormalization
According to Wikipedia…
“Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data.[1][2] It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization should not be confused with Unnormalized form. Databases/tables must first be normalized to efficiently denormalize them.”
Database normalization is always a starting point for denormalization. Denormalization is a type of reverse engineering process that can apply to retrieve the data in the shortest time possible.
Let us consider an example; we’ve got an Employee table that in-house an email and a phone number columns. Well, what happens if we add another email address column, another phone number? We tend to break First Normal Form. It’s a repeating group. But in general, it is easy to have those columns created (Email_1, and Email_2 column), or having (home_phone and mobile_phone) columns, rather than having everything into multiple tables and having to follow relationships. The entire process is referred to as a denormalization.
Summary
Thus far, we’ve discussed details of the Relational Database Management System (RDBMS) concepts such as Database Normalization (1NF, 2NF, and 3NF), and Database Denormalization
Again, the basic understandings of database normalization always help you to know the relational concepts, a need for multiple tables in the database design structures and how to query multiple tables in a relational world. It is a lot more common in data warehousing type of scenarios, where you’ll probably work on a process to de-normalize the data. Denormalized data is actually much more efficient to query than normalized data.
Taking the database design through these three steps will vastly improve the quality of the data.

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021