
Background
If an environment chooses to use snapshot or transactional replication, one useful exercise is to ask the technical end user (or client) what they think replication does. If you have access to a white board, you can even ask them to demonstrate what they think replication will do for their data. Generally, these technical end users will plot something similar to the below image, where we see a table with data being copied to another table with data.
Replication carries many moving pieces, similar to the engine of a car where only one small piece, like a spark plug, can malfunction and cause the car to fail at starting, or experience an issue. For the sake of this article, we will discuss replication in the context of its OLTP engine – the distribution database – though this isn’t to say more is happening with the log reader, snapshot agent, etc. The goal of this article is to help people realize that the above image is nowhere close to replication so that they can optimize for increasing performance with replication.
Discussion
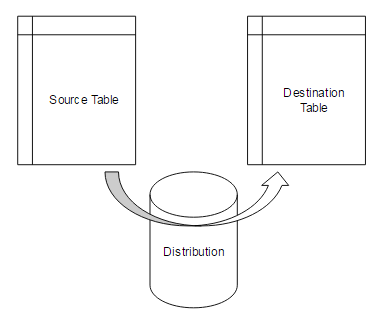
When my brothers and I were teenagers, our parents gave us a go-cart that moved a little slower than our quick dog. We didn’t like that our dog could run faster, so we discovered that the go-cart had a governor which limited how fast we could go, and removed it. Since we didn’t grasp the laws of physics, we didn’t think anything was wrong with our decision and our go-cart went as fast as we wanted when we pressed the gas pedal. This would be like a straight bulk copy without any error logging, or any logging of any kind as to what was copied. It can work, it can perform quickly, and it can result in success, but without any logging or catching of errors, we could lose data in the process, or the entire copy could fail and we wouldn’t know why. This is similar to the first image where we take a data source and copy it to a data destination; it’s quick and requires little overhead.
The distribution database for snapshot and transactional replication can act as a governor, which records the commands, the results, errors, and information about the replication. For an example, on our distribution database, we can search the publications table to see how many publications we have:
|
1 2 3 4 |
SELECT * FROM distribution..MSpublications |
The distribution database holds these publications and this table is an example of the information we can find throughout the database – we can also find information about subscribers, errors, etc. Compare this to our straight bulk copy – what’s limiting the speed of the bulk copy and where are the errors logged if we didn’t build any error catching?
The key here is that the distribution database can quickly become a bottleneck, relative to how many commands are backed up, how many errors are being generated, whether it can obtain access to the subscription servers, whether we have enough resources on the distributor, publisher and subscriber server, and a host of many other potential problems. Fundamentally, the distribution database is an OLTP engine and at the current time, Microsoft does not allow using in memory OLTP for the distribution databases’ tables (thanks to the engineer Harshal Bhargav at Microsoft for confirming this). If we don’t optimize for that, we’ll experience trouble in general because OLTP, OLAP and balanced environments can differ significantly.
This explains why you can find quite a few Microsoft MVPs who express dissatisfaction with replication. Unfortunately, for high availability solutions, each will come with both positives and negatives and if we decided to not log errors at all, as an example, then we might only be sending parts of data we need, or we might experience a failure when a data flow hasn’t fully completed. In most cases, partial data or inaccurate data is worse than no data. Instead of vetoing the idea, we can consider if it’s efficient for our environment to scale distributing data by publisher, such as using one distribution database per publisher. For an example:
distribution_publisherone
distribution_publishertwo
distribution_publisherthree
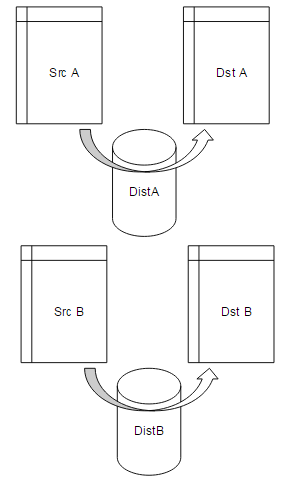
In the above example, we have a different distribution database per publisher. While this can work in some environments, if we add a large load to any particular publisher – such as publishing huge amounts of data – we could still find ourselves in a similar bottleneck. In a similar manner, we may find adding an index, or updating statistics on some of the tables in the distribution database useful, while in other cases it may do more harm than good. Generally, it is wise to use a distribution server independent of the publisher and subscriber, but for some environments, this may be too much in costs.
I wish I could write that, “Oh the best practices for your distribution database are …” but that is untrue because it depends on your OLTP load – for an example, is it even throughout the day, or does it have a peak? What are your systems limitations? And finally, tell me about your weakest point as that will really show itself in replication?
Some useful questions to consider
One of the biggest keys to success is asking the right questions because it frames the technical approach from the beginning so that we isolate the right approach. Some excellent questions to ask about transactional or snapshot replication for environments are:
- Why are we using snapshot and transactional replication?
- What are the costs of scaling snapshot and transactional replication to handle the data load?
- What are the alternatives to snapshot and transactional replication?
- How often can our data be offline when issues with snapshot and transactional replication arise?
- What other pieces (servers, databases, maintenance windows, etc) in our environment might be affected by our choice to use snapshot and transactional replication?
None of these questions eliminate replication as a possible solution, but they may indicate that for our environment it’s not the most appropriate solution. Consider that I may use a completely different approach to storing Hong Kong stocks from the Hong Kong Stock Exchange than I use to store bitcoin stocks and peer-to-peer loans; the former has downtime (like holidays) whereas the latter is never offline, except for the individual sites. How will I have the time to install service packs or perform maintenance on a system that never goes down because data must constantly be replicated? This is a simple example of where considering what I need to accomplish will limit the tools that I use.
Final Thoughts
Replication offers a useful high availability tool and in some situation offers the best tool for a business solution. DBAs and developers should still consider the limitations of replication, along with scaling it in an appropriate manner to their environment from the beginning.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020