
This article will help you understand how to analyze Azure Cosmos DB data using Azure Synapse Analytics.
Introduction
Azure Cosmos DB is a multi-model NoSQL database that supports hosting various types of data that are transactional in nature. OLTP systems employ transactional databases for hosting operational data. To analyze large volumes of transactional data, relational databases do not scale or perform to the needs of large-scale analytics. Columnar data warehouses are one of the preferred, effective, and proven means of analyzing and aggregating large volumes of data for big data scale analytics. Azure Synapse is the data warehouse offering in the Microsoft Azure technology stack. The challenge with analyzing transactional data in relational databases using columnar warehouses is that one needs to replicate and/or relocate data from operational repositories into analytical repositories. Hybrid transactional analytical processing (HTAP) is a methodology or approach where data hosted in a relational format is auto-organized in a columnar format eliminating the need to replicate and/or relocate the data to a great extent. Azure offers a feature to analyze data hosted in Cosmos DB using Azure Synapse. In this article, we will learn how to implement the same.
Pre-requisites
We are assuming that we are hosting data in the Cosmos DB instance. To simulate this assumption, we would need an Azure Cosmos DB account implemented using the Core (SQL) API, with all the preview features turned on. Once you have an account created, you would be able to see an account listed as shown below.
Open the Azure Cosmos DB account and click on the Notebooks section. Using this section, one can create a Sample DB. We would need a sample DB in the place where we would create sample data.
Secondly, we need an Azure Synapse instance with a SQL on-demand pool in place. This instance would act as the analytical repository or warehouse with which we would access the data hosted in Cosmos DB without replication or relocating this data. So we will create an Azure Synapse instance with the pool in the available state.
Configuring Azure Cosmos DB
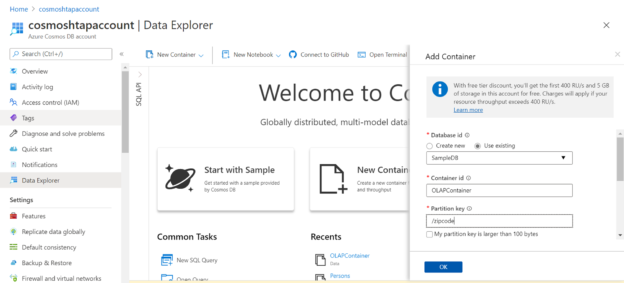
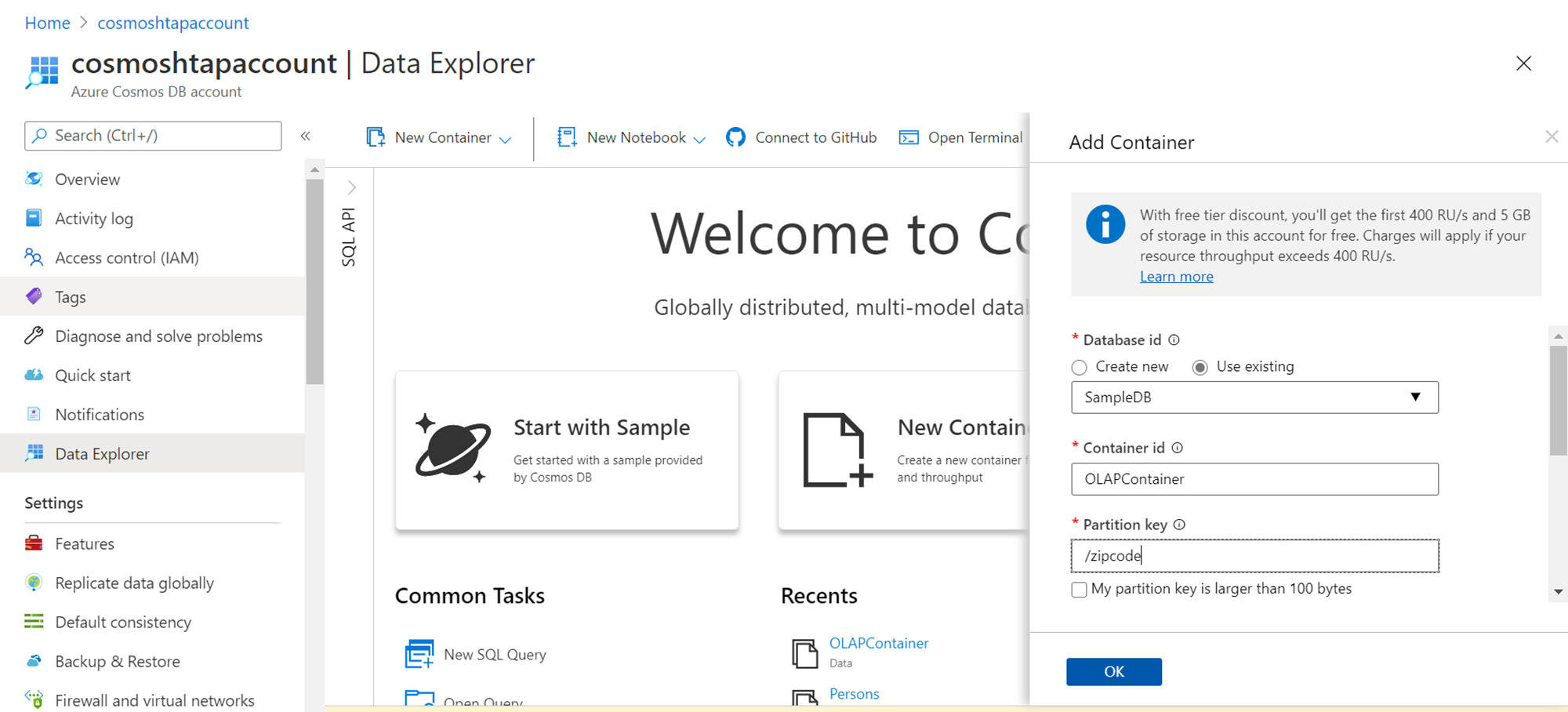
The first thing we need to do is create some sample data. Navigate to the Azure Cosmos DB account and click on the New Container button to add a new container to the blank database that has already been created. When we attempt to add a new container, a pop-up would appear, and it would look as shown below. We would be using the existing database, providing a new name for the container and specifying a partition key as shown below.
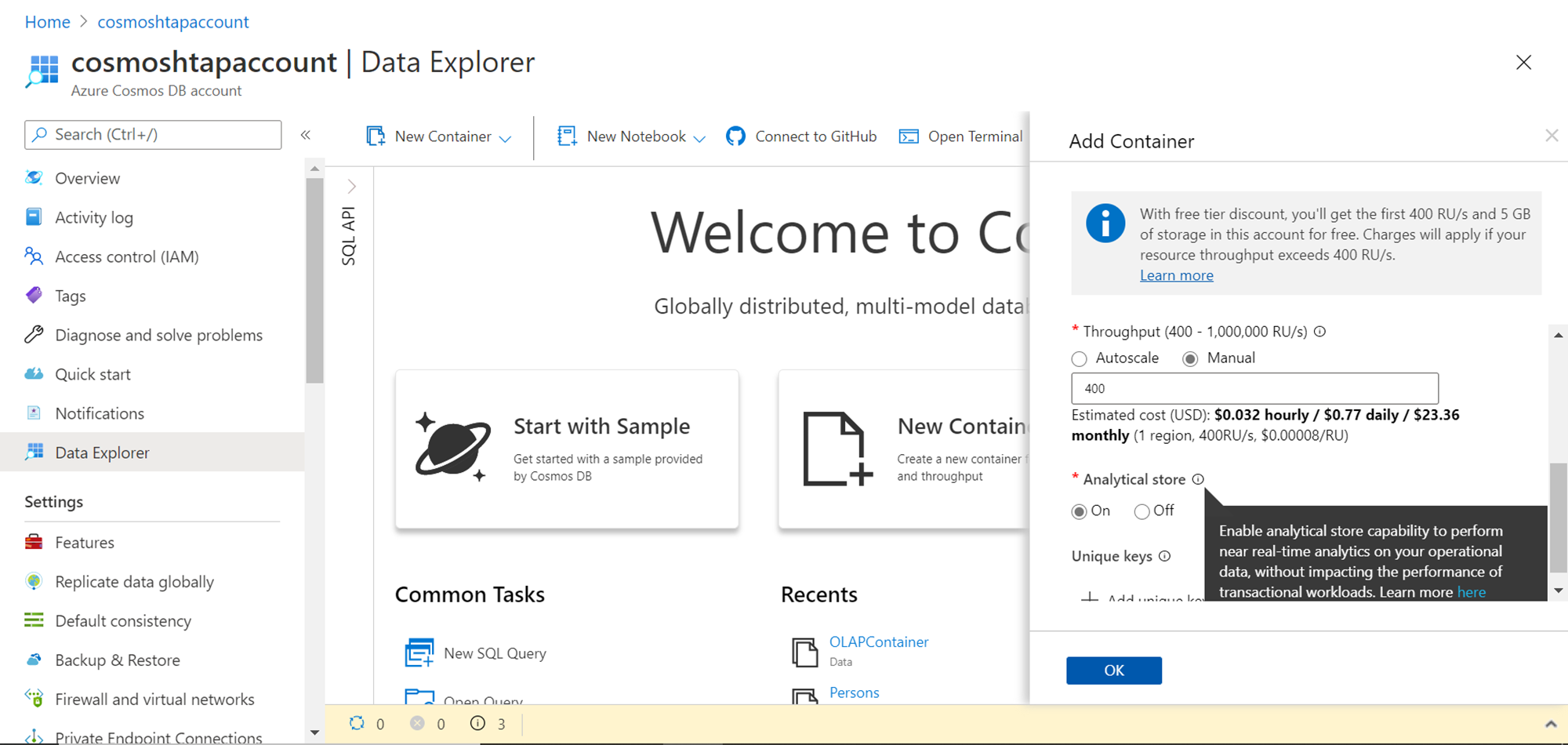
Scroll down and ensure that the options are selected as shown below. We are not going to create a large volume of data, so we do not need auto-scaling of the throughput as of now. The important option that has to be switched on is the “Analytical store” option. Enabling this option lets us analyze the operational data stored in Azure Cosmos DB using Azure Synapse in near real-time without affecting the performance of Cosmos DB itself. After selecting these options, click on the OK button to create the new container.
Now that we have the container in place, we can start adding some sample data to it. Open the container and click on New Item, and add few records as shown below. After adding the records, click on the Save button to save the record. Add at least a couple of records so that we can see the difference when we add more records later.
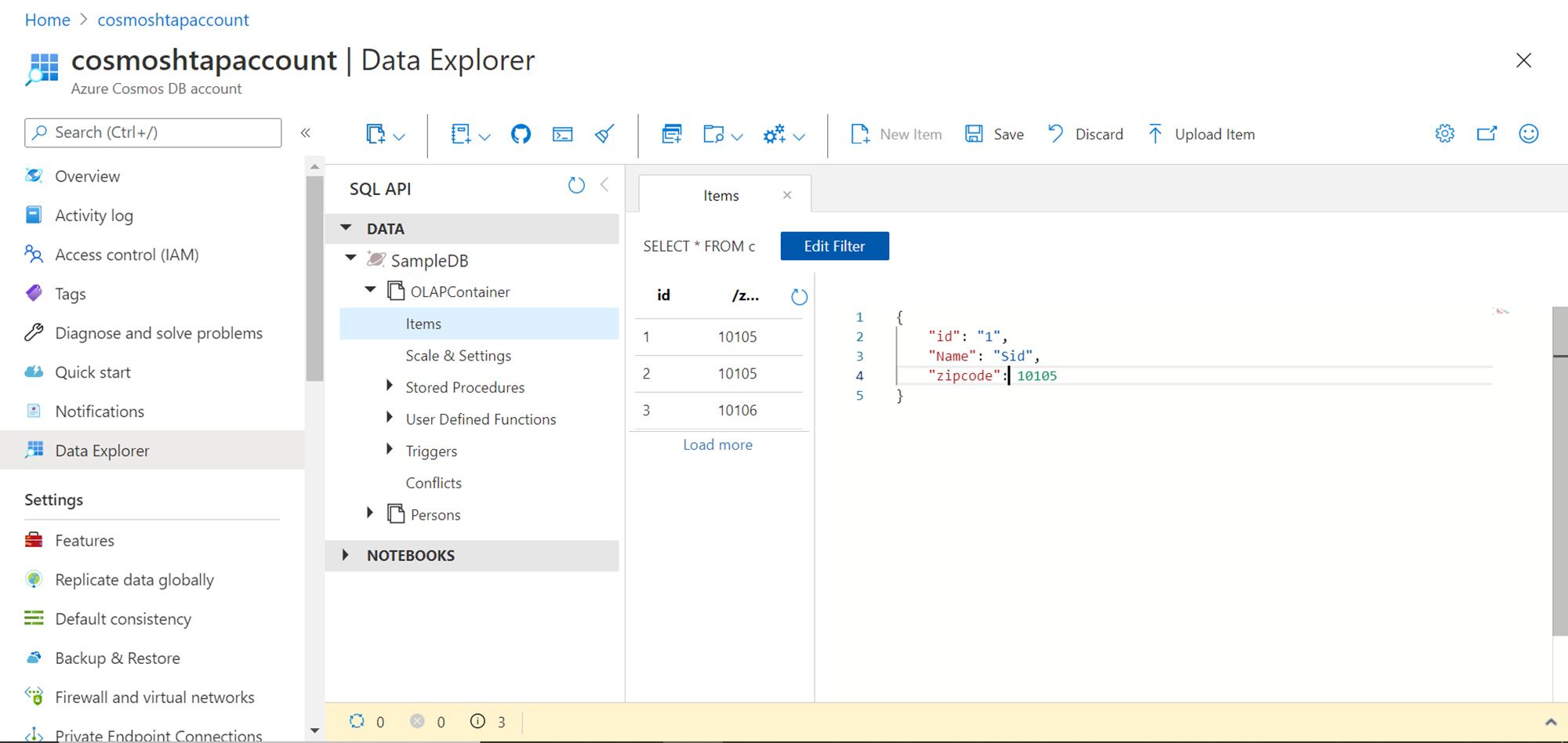
Once the data is loaded into the container, we can query this data to see the results. While adding the records, when the record is saved, it would instantly show the other metadata related fields as shown below.
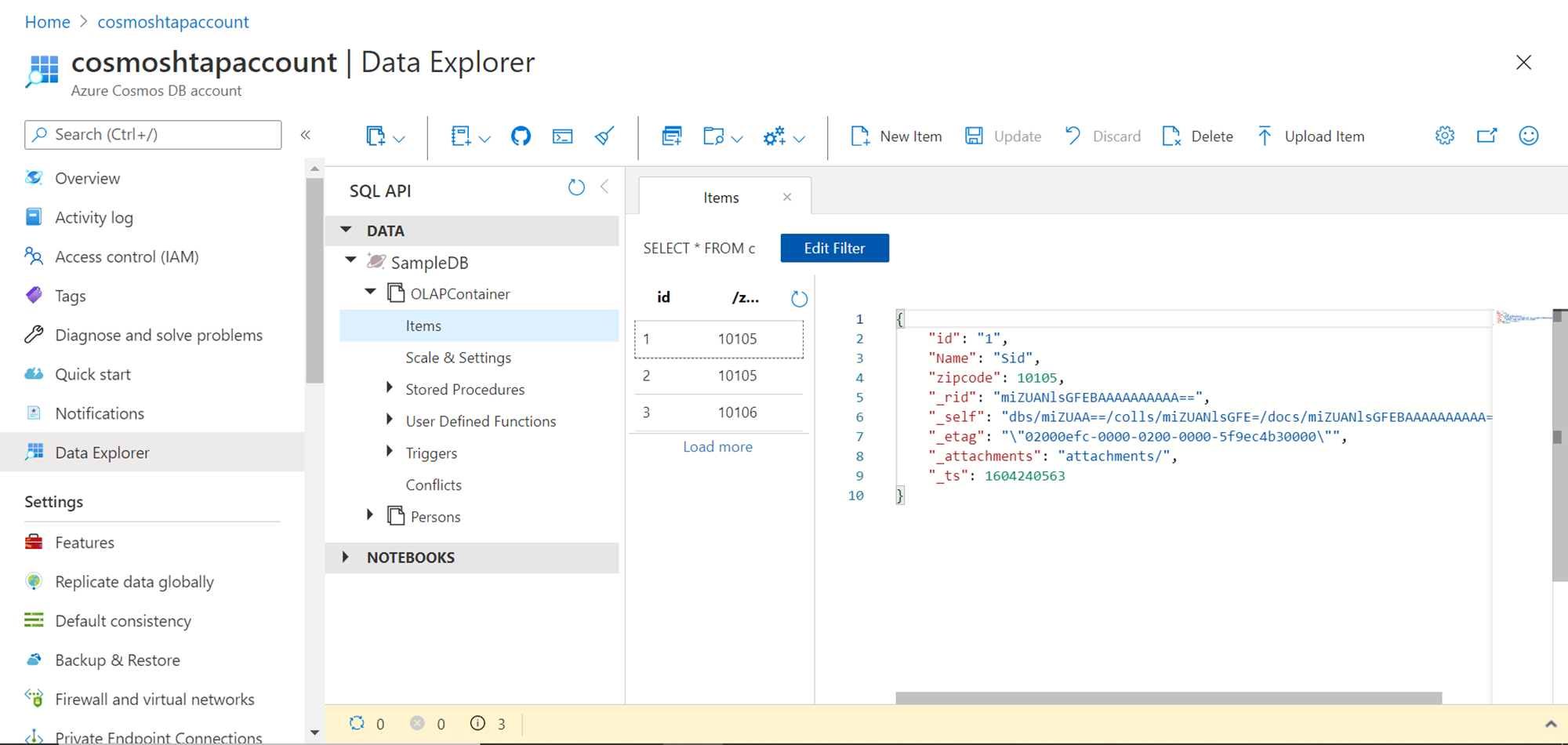
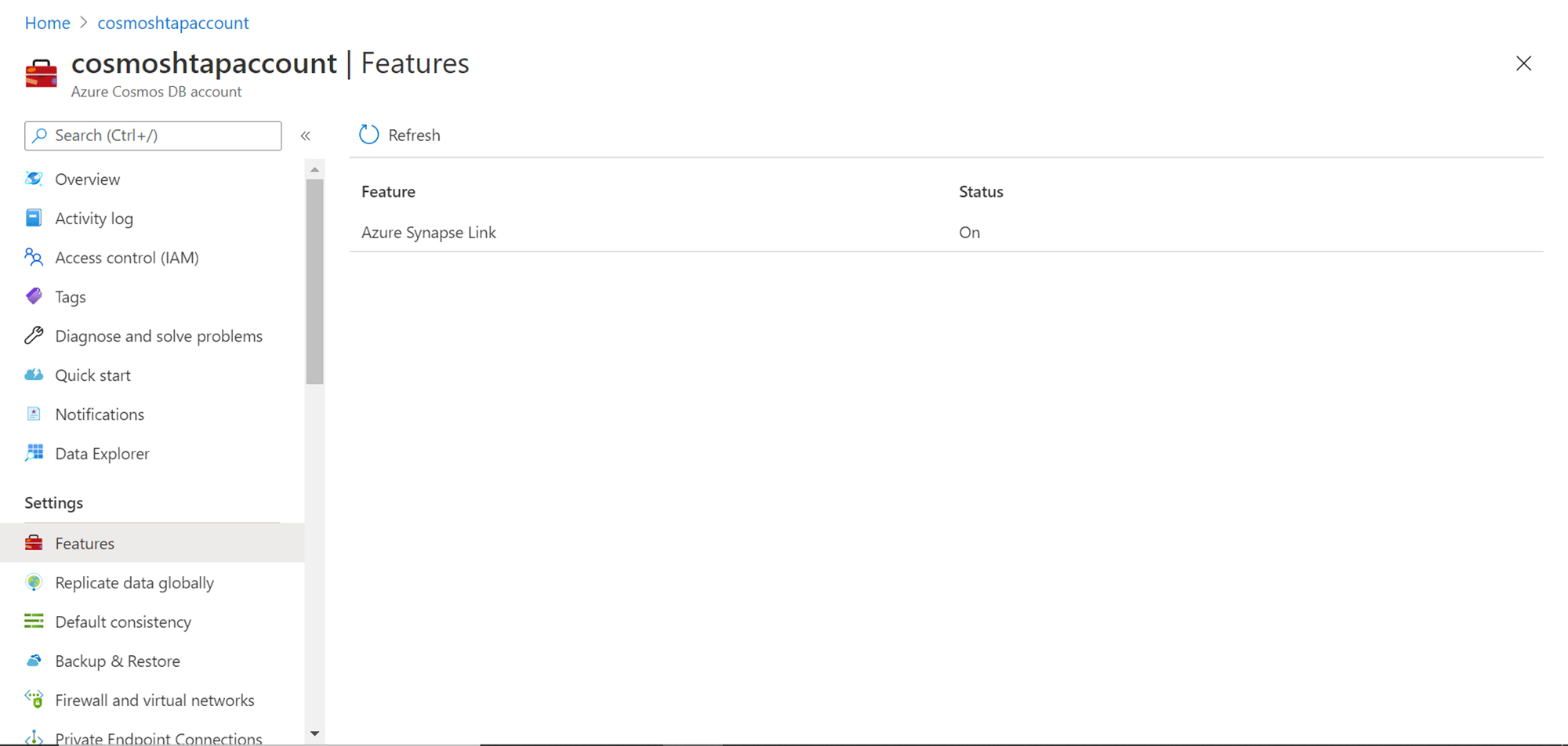
Now that we have the sample data created in the Cosmos DB container, we have earlier enabled the analytical store, now we need to enable the Azure Synapse link to allow connectivity from Azure Synapse to Cosmos DB. To enable this feature, click on the Features menu option from the left pane under the settings section. There we would find an option named Azure Synapse Link. Click on this link and ensure that the status of this feature is “On” as shown below. This completes our setup of Cosmos DB to set it up for consumption by analytics repositories like Azure Synapse.
Analyzing data with Azure Synapse
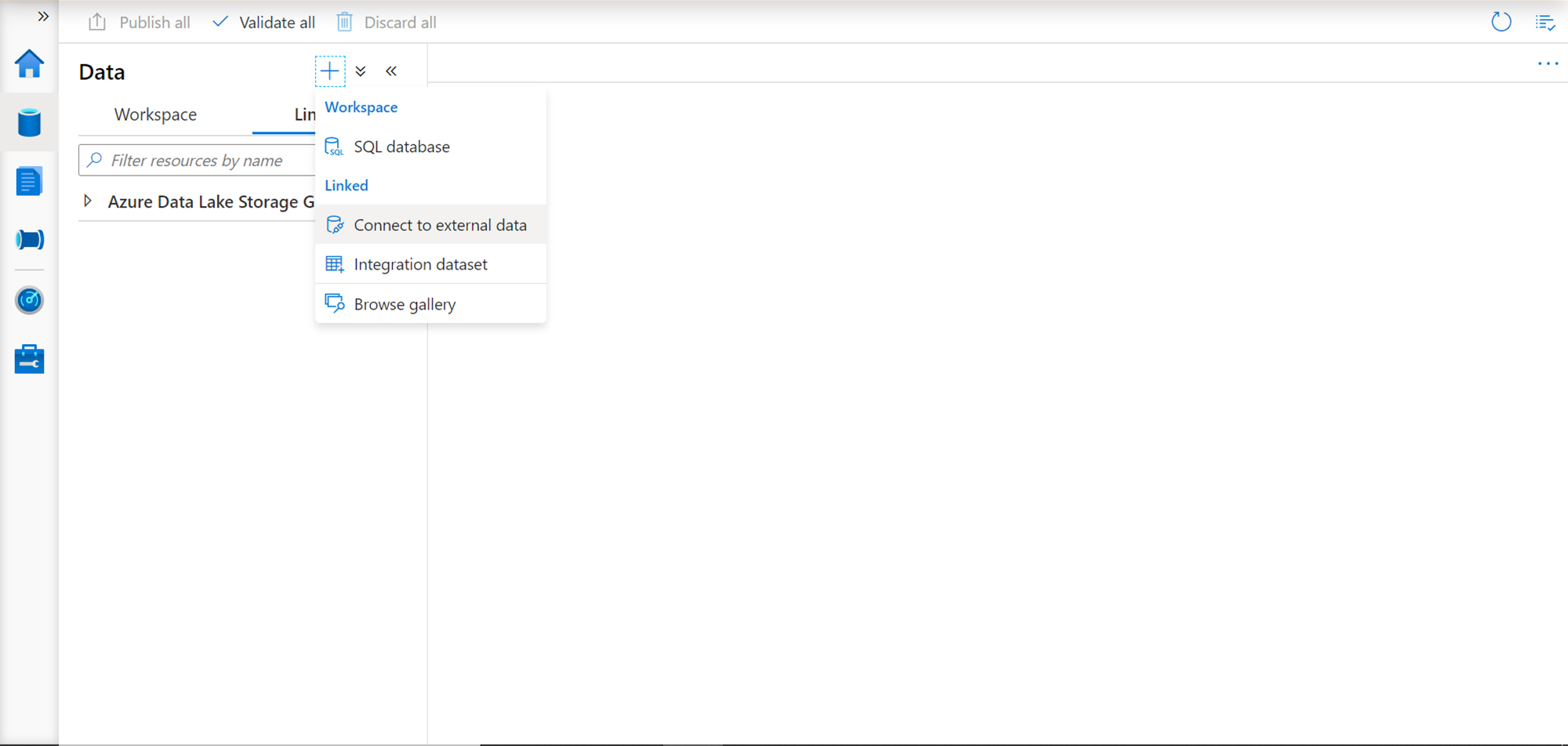
We intend to connect to the Cosmos DB analytical store from our Azure Synapse instance. For the same, open the Synapse Studio from the synapse dashboard page. Navigate to the Data section by clicking the Data icon in the left pane. Click on the plus sign as shown below and click on the Connect to external data button as shown below. This option would provide options to connect to external data repositories from Synapse.
You may find various options to connect to a number of repositories. One of our interests at present is Azure Cosmos DB (SQL API) as shown below. If you have created a Cosmos DB instance using a different API than the SQL API, this option may not work. Select this option and click on the Continue button.
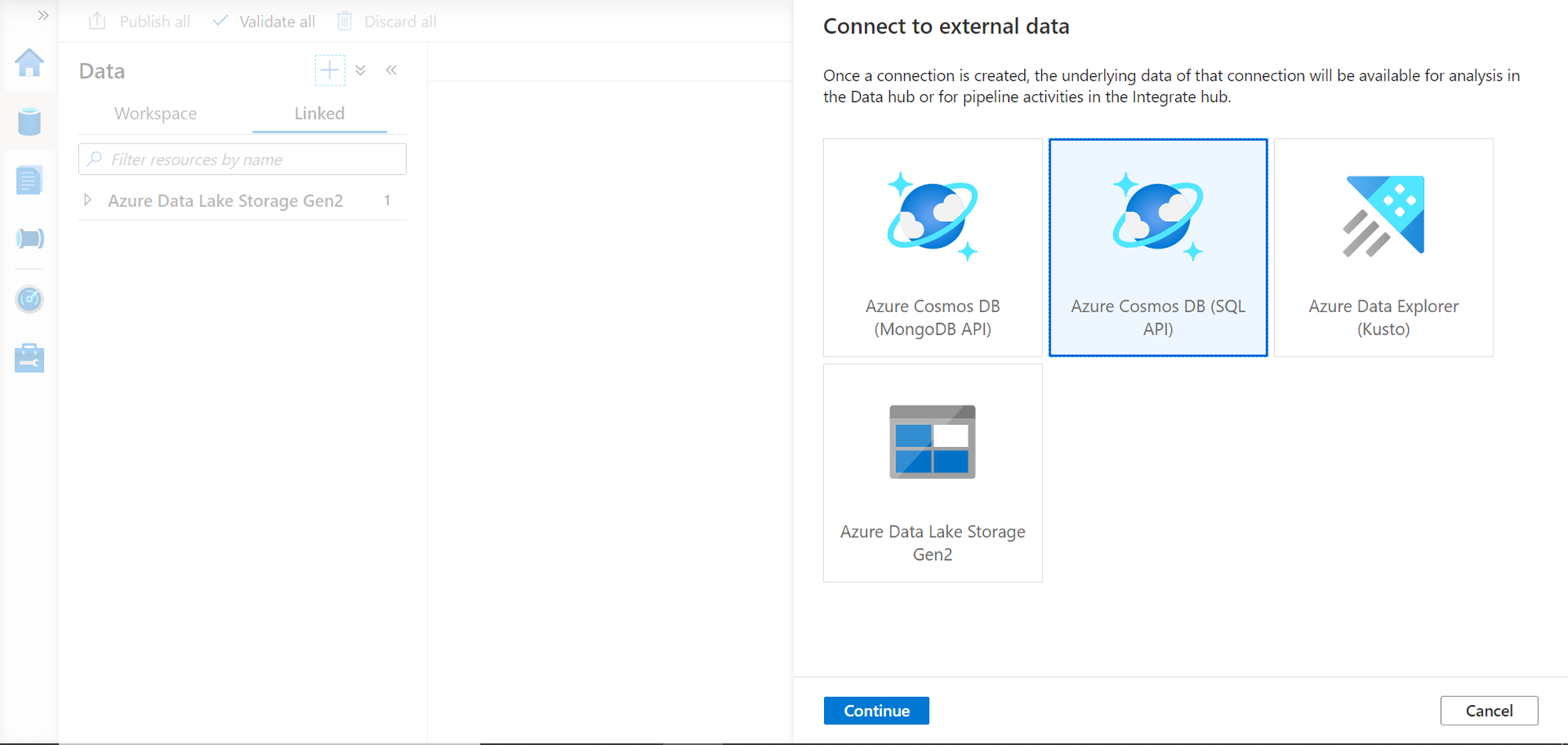
Provide the name of the linked service that we are going to create. The integration runtime option would have a default runtime already selected. We can continue with the same. We can leave the rest of the option with default values and move to the subscription details. Select the subscription and Cosmos DB account name that we configured earlier with the analytical store feature.
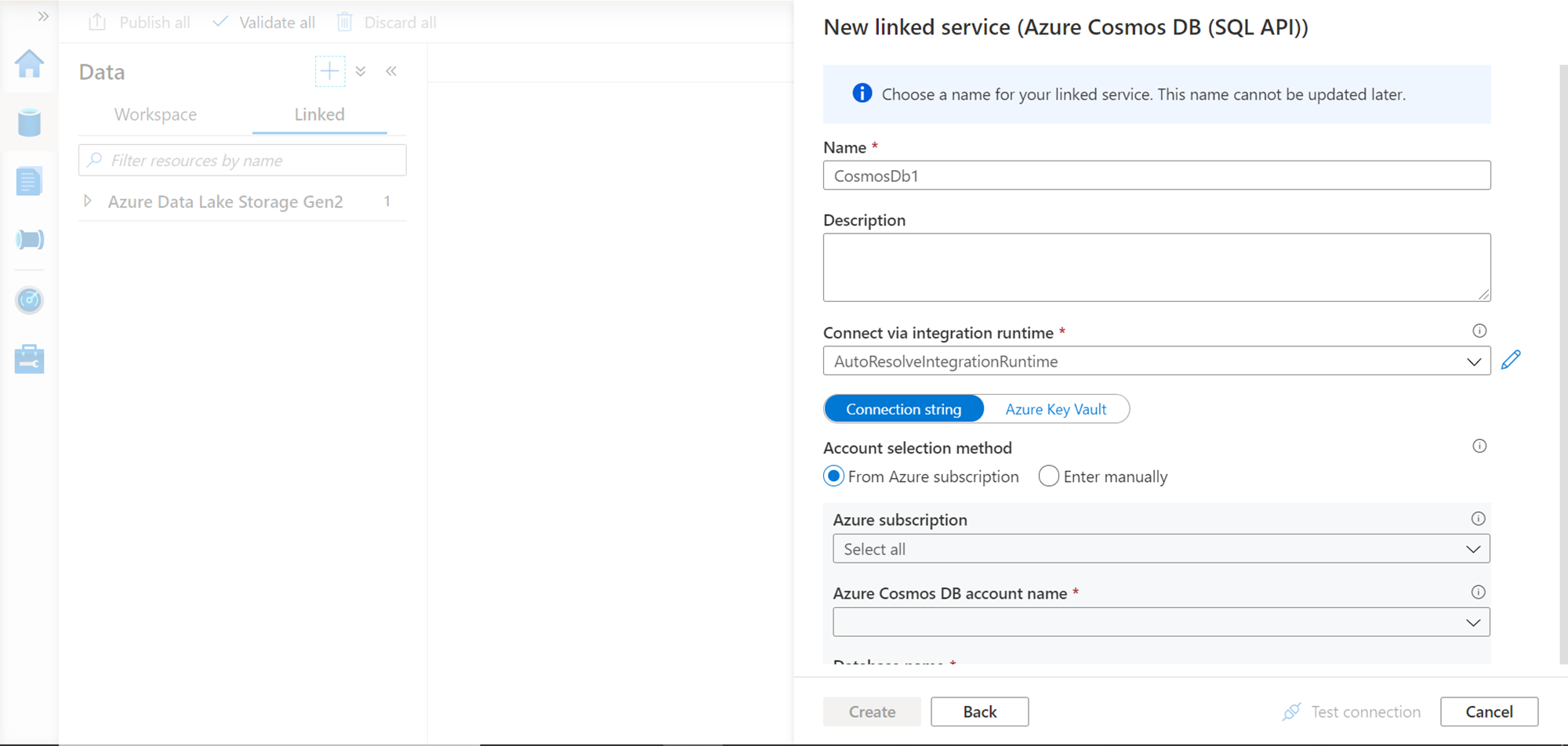
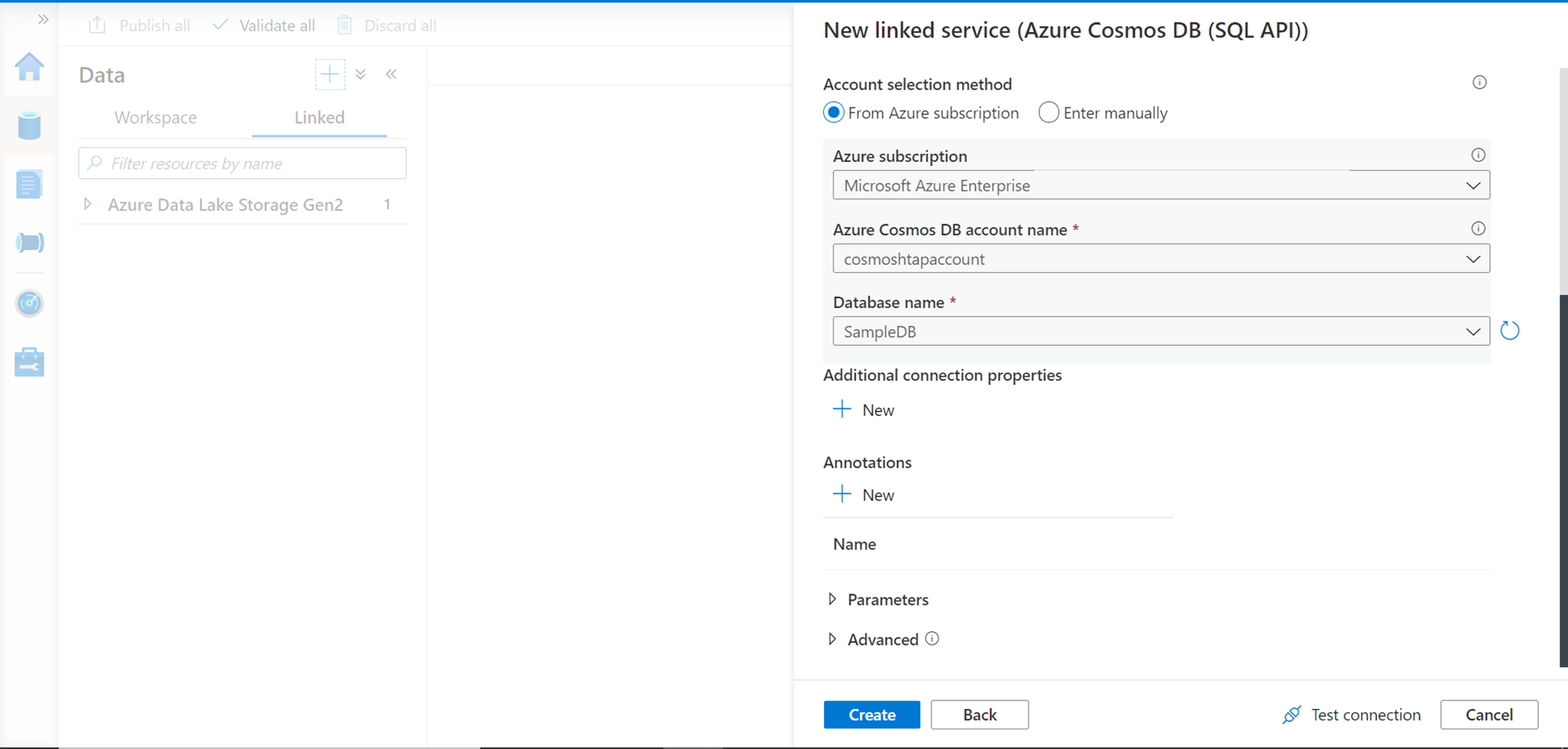
Scroll down and provide the name of the database which hosts the container on which we have enabled the analytical store. The rest of the feature can be configured as required, or in this case, it can be left with default values. Click on the Test connection button to test the connectivity. Once the connectivity is successful, click on the Create button which would create the external service.
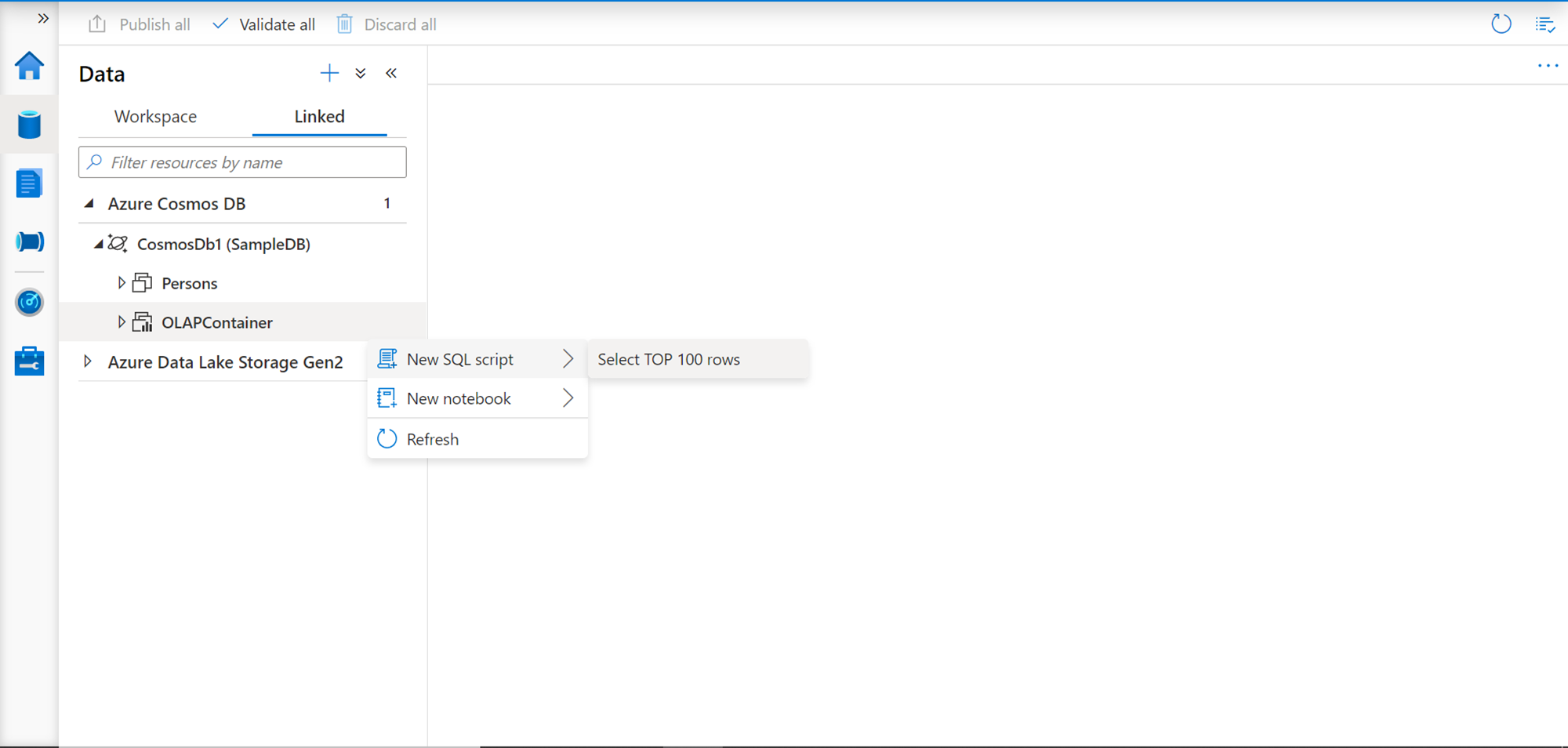
Once the external service is created, you would be able to see the linked service created under the Linked tab in the Data section. Expand the newly created linked service and you would find the sample database as well as the container listed. If we right-click on this container, we would find a pop-up menu with a few options as shown below. Select the New SQL Script button and select the Select Top 100 rows menu option.
This would result in the generation of a template script in a new tab as shown below. This script creates a select query that can be used to query the data in Azure Cosmos DB using the openrowset function. In this function, we are passing the name of the repository as “CosmosDB”, account name would be the name of the Cosmos DB account name, database name as the name of the database created in the Cosmos DB instance. The Key here is the security key of the Azure Cosmos DB account which would provide access to the data in the account. Configure these values in the query and execute the query. This would result in the data getting extracted held in the container’s analytical store and accessible in Azure Synapse.
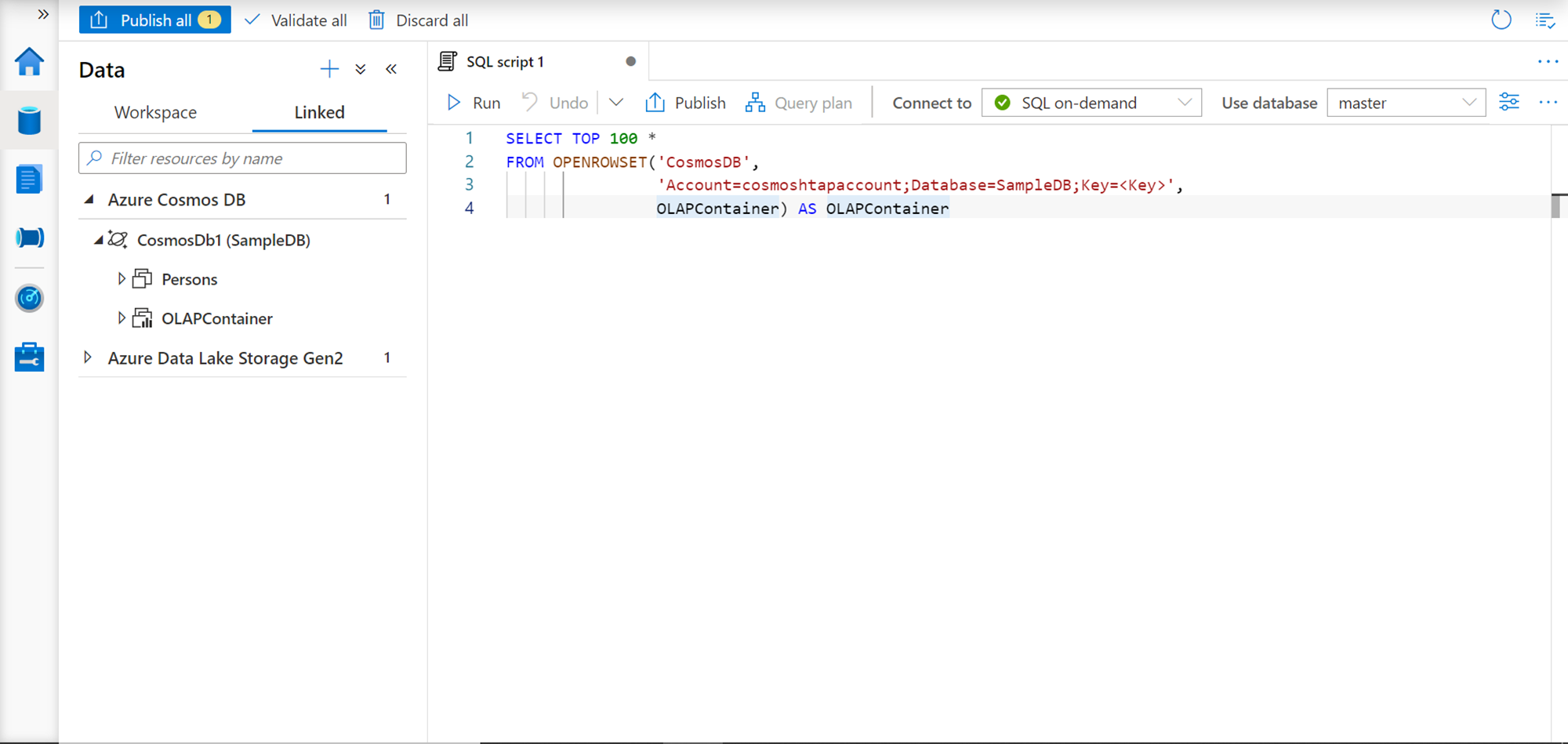
In this way, we can access and analyze data from Azure Cosmos DB using Azure Synapse. The same queries can be accessed by connecting to Synapse using SSMS.
Conclusion
We started with an instance of Synapse and Cosmos DB in Azure. We created sample data in Cosmos DB, enabled the analytical store feature on the container, switched on the Azure Synapse link, and executed a query using the Openrowset function to access data hosted in Cosmos DB.
Table of contents
| Getting started with Azure Cosmos DB Serverless |
| Analyzing data hosted in Azure Cosmos DB with Notebooks |
| Analyze Azure Cosmos DB data using Azure Synapse Analytics |
| Restore dedicated SQL pools in Azure Synapse Analytics |
| Copy data into Azure Synapse Analytics using the COPY command |

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023