

This article will discuss one of the powerful analytics services in Azure – Azure Synapse Analytics, along with its components, features, security, and more.
Introduction
In the mid of 2016, Azure made Azure SQL Data Warehouse service generally available for data warehousing on the cloud. Since then, this service has gone through several iterations, and towards the end of 2019, Microsoft announced that the Azure SQL Data Warehouse service would be rebranded as Azure Synapse Analytics. This service is the de-facto service for combining data warehousing and big data analytics, with many new features of the service in preview as well. In this article, we would learn the details of this service.
High-Level Architecture
Online Transaction Processing Workloads (OLTP) typically involve transactional data that is voluminous in terms of high reads and writes. The data access pattern usually involves a lot of scalar and tabular datasets. And data ingestion generally happens through user transactions in small batches of rows. Online Analytical Processing (OLAP) applications typically store and process large volumes of data collected from various sources, which may be transformed and/or modeled in the OLAP repository, and then large datasets are aggregated for ad-hoc reporting and analytical use-cases. The latter is the use-case where Synapse Analytics fits in the overall data landscape, as shown below. Azure Data Lake Storage forms the bedrock of big data storage, and Power BI forms the visualization layer, as shown below.

Azure Synapse Components and Features
There are multiple components of Synapse Analytics architecture on Azure. Let’s understand all these components one by one.
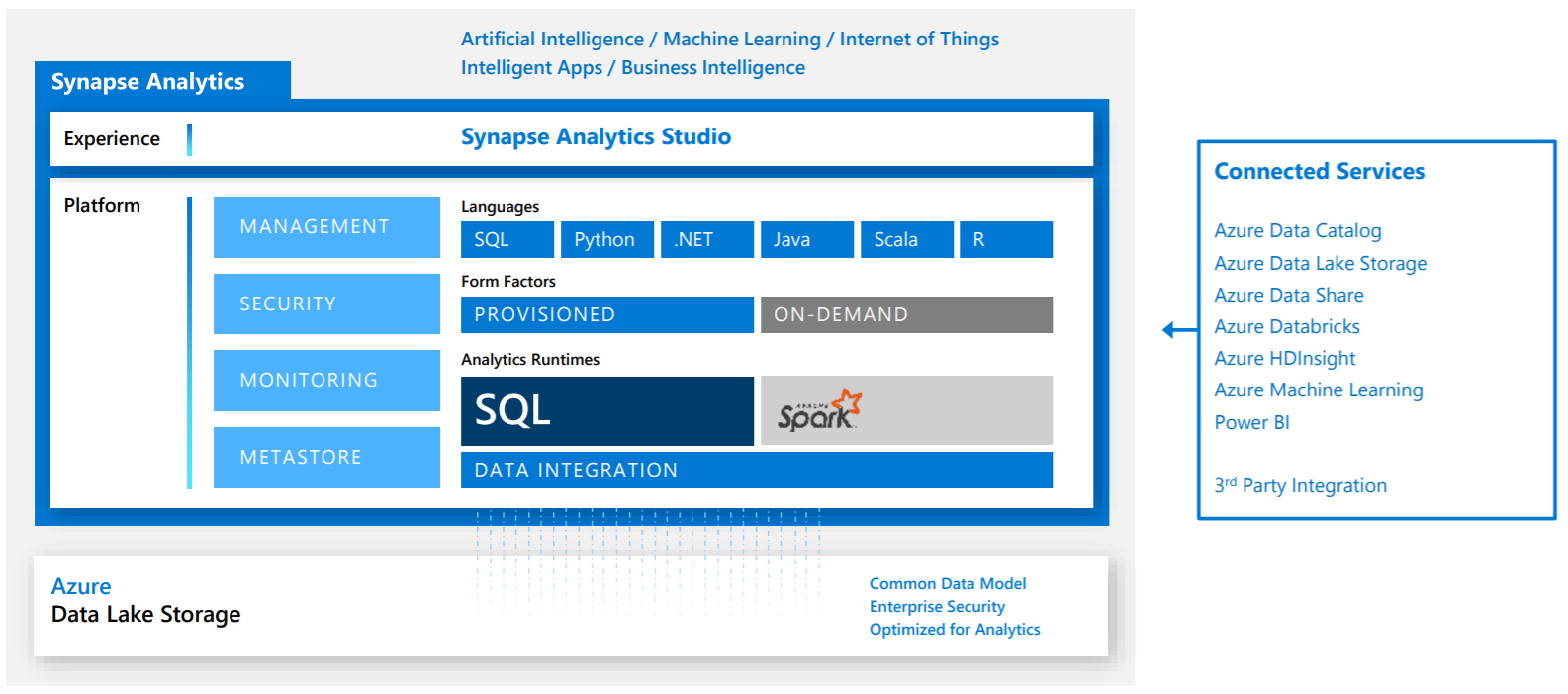
- Synapse Analytics is basically an analytics service that has a virtually unlimited scale to support analytics workloads
- Synapse Workspaces (in preview as of Sept 2020) provides an integrated console to administer and operate different components and services of Azure Synapse Analytics
- Synapse Analytics Studio is a web-based IDE to enable code-free or low-code developer experience to work with Synapse Analytics
- Synapse supports a number of languages like SQL, Python, .NET, Java, Scala, and R that are typically used by analytic workloads
- Synapse supports two types of analytics runtimes – SQL and Spark (in preview as of Sept 2020) based that can process data in a batch, streaming, and interactive manner
- Synapse is integrated with numerous Azure data services as well, for example, Azure Data Catalog, Azure Lake Storage, Azure Databricks, Azure HDInsight, Azure Machine Learning, and Power BI
- Synapse also provides integrated management, security, and monitoring related services to support monitoring and operations on the data and services supported by Synapse
- Data Lake Storage is suited for big data scale of data volumes that are modeled in a data lake model. This storage layer acts as the data source layer for Synapse. Data is typically populated in Synapse from Data Lake Storage for various analytical purposes
Now that we understand different layers or components of the architecture let’s understand the core pillars of Synapse.
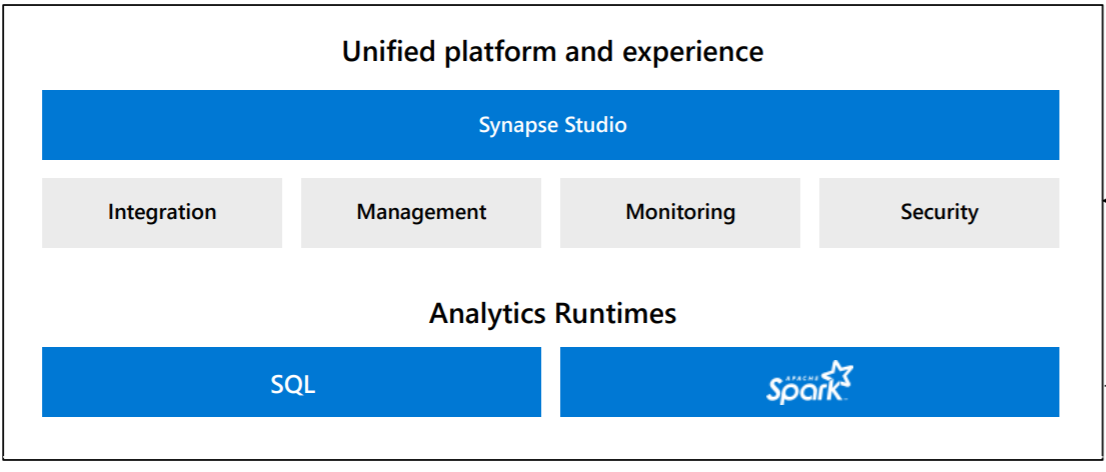
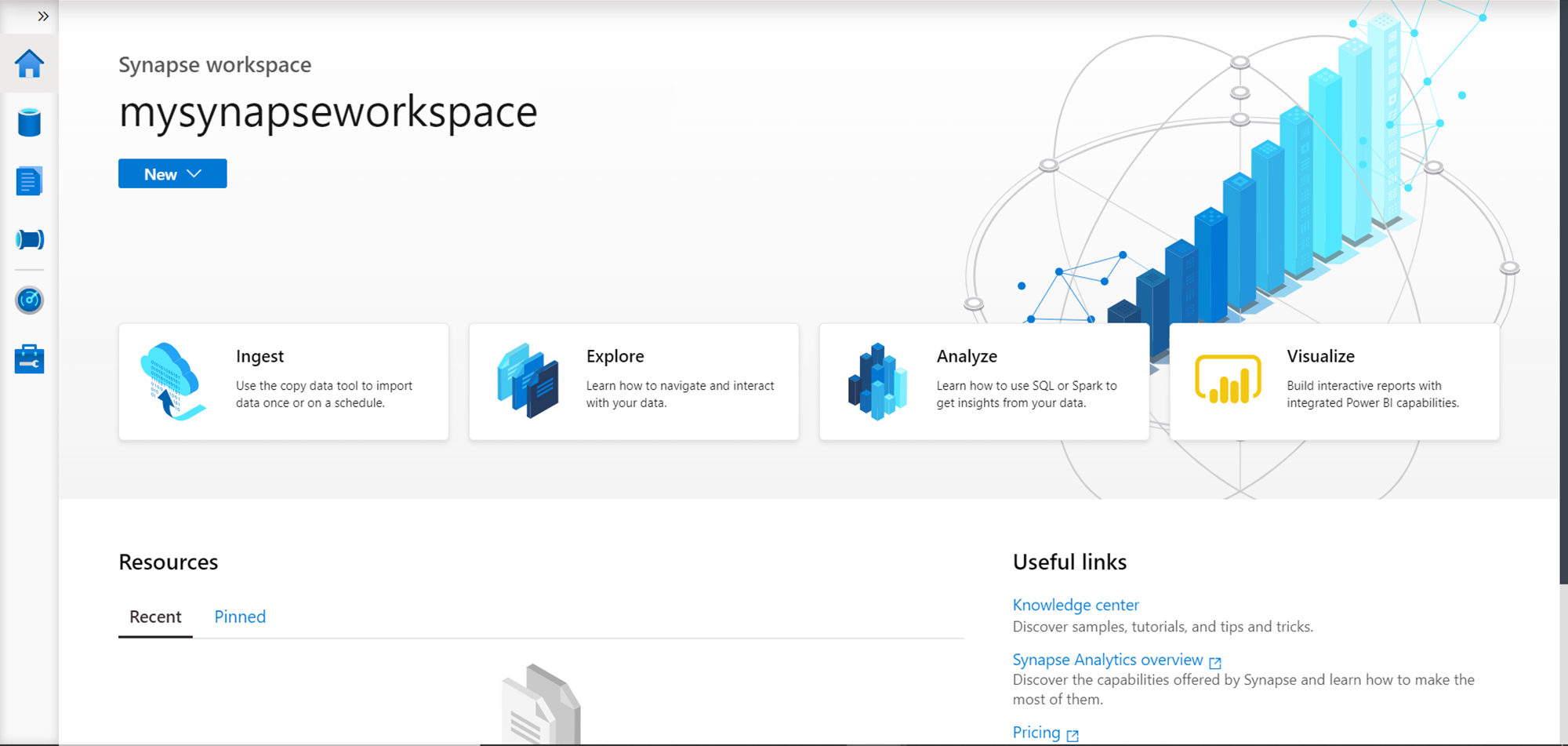
Azure Synapse Studio – This tool is a web-based SaaS tool that provides developers to work with every aspect of Synapse Analytics from a single console. In an analytical solution development life-cycle using Synapse, one generally starts with creating a workspace and launching this tool that provides access to different synapse features like Ingesting data using import mechanisms or data pipelines and create data flows, explore data using notebooks, analyze data with spark jobs or SQL scripts, and finally visualize data for reporting and dashboarding purposes. This tool also provides features for authoring artifacts, debugging code, optimizing performance by assessing metrics, integration with CI/CD tools, etc.

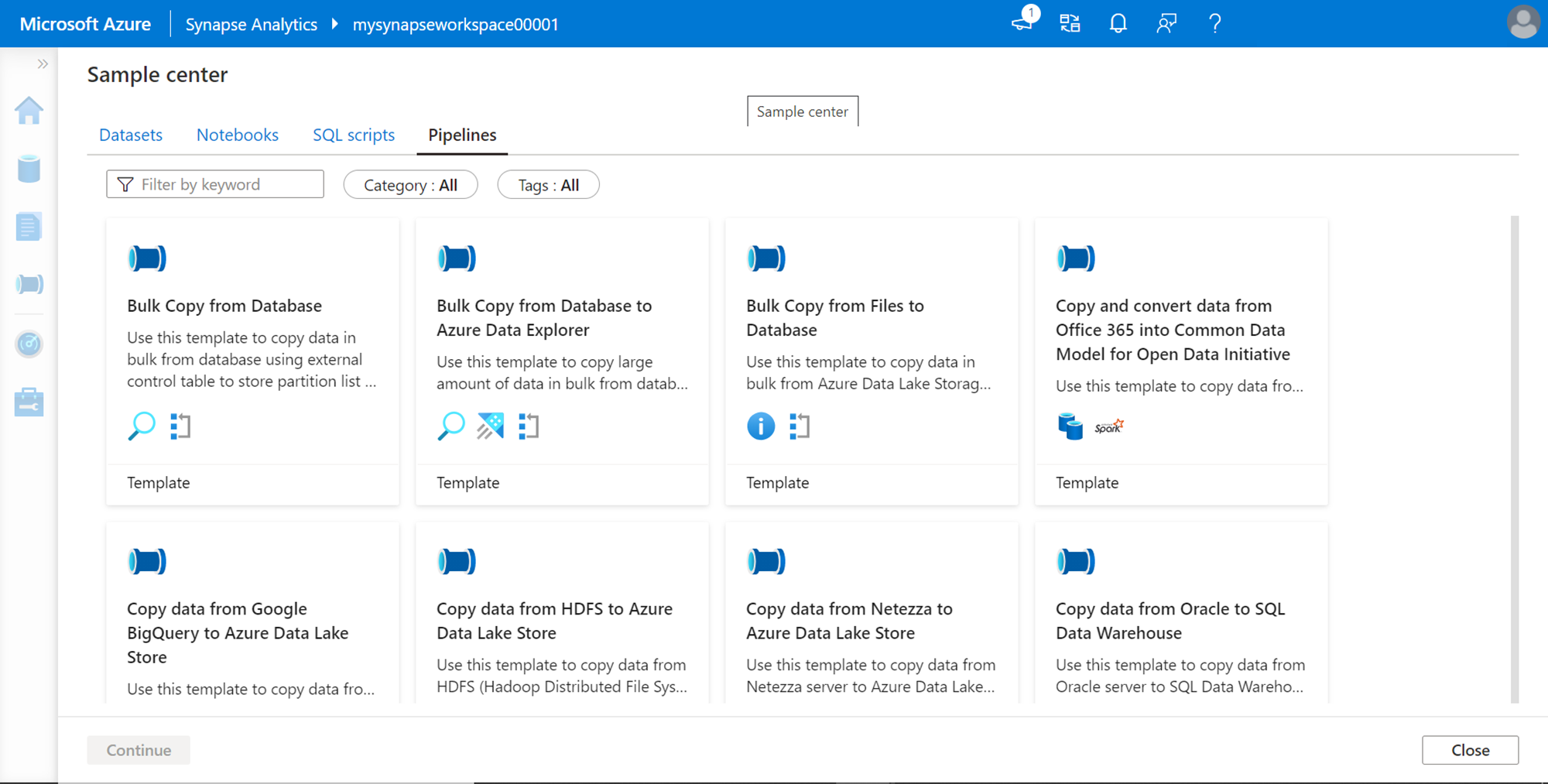
Azure Synapse Data Integration – There are different tools that can be used to load data into Synapse. But having an integrated orchestration engine help to reduce dependency and management of separate tool instances and data pipelines. This service comes with an integrated orchestration engine that is identical to Azure Data Factory to create data pipelines and rich data transformation capabilities within the Synapse workspace itself. Key features include support for 90+ data sources that include almost 15 Azure-based data sources, 26 open-source and cross-cloud data warehouses and databases, 6 file-based data sources, 3 No SQL based data sources, 28 Services and Apps that can serve as data providers, as well as 4 generic protocols like ODBC, REST, etc. that can serve data. Pipelines can be created using built-in templates from Synapse Studio to integrate data from various sources, as shown below.
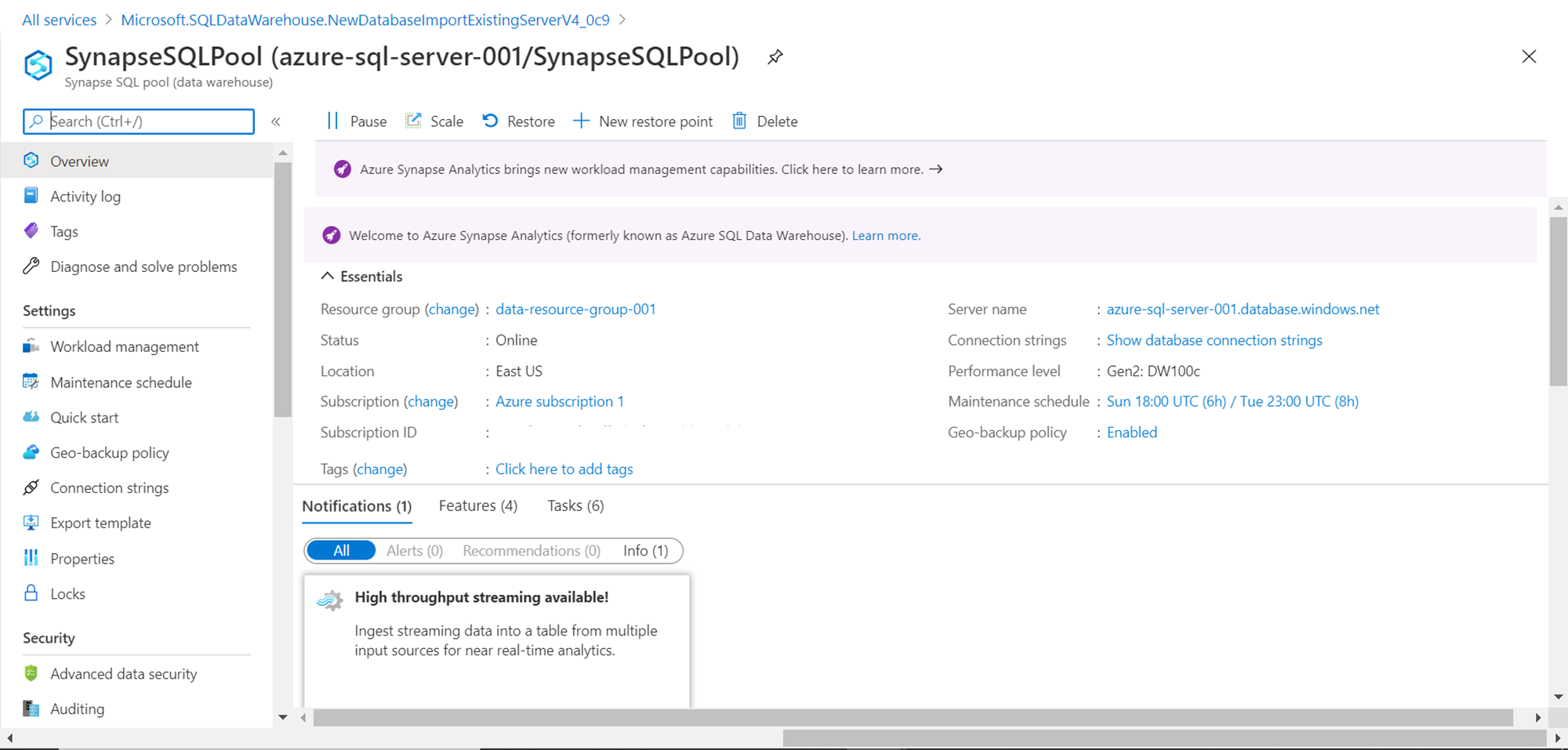
Synapse SQL Pools – This feature provides the same data warehousing features that were made available with the earlier versions of this service when it was branded as SQL DW. This feature of the service available in a provisioned manner where a fixed capacity of DWU units is allocated to the instance of the service for data processing. Data can be imported into Synapse using different mechanisms like SSIS, Polybase, Azure Data Factory, etc. Synapse stores data in a columnar format and enables distributed querying capabilities, which is better suited for the performance of OLAP workloads. SQL Pools have built-in support for data streaming, as well as few AI functions out-of-box. Shown below is a screenshot of how Synapse SQL Pool would look.
Generally, Synapse SQL Pools are part of an Azure SQL Server instance and can be browsed using tools like SSMS as well. Synapse SQL feature is also available in a serverless manner (in preview as of Sept 2020), where no fixed capacity of the infrastructure needs to be provisioned. Instead, Azure manages the required infrastructure capacity to meet the needs of the workloads. This is a data virtualization feature supported by Synapse SQL. The pricing model, in this case, is based on the data volumes processed instead of the number of DWUs allocated to the instance.
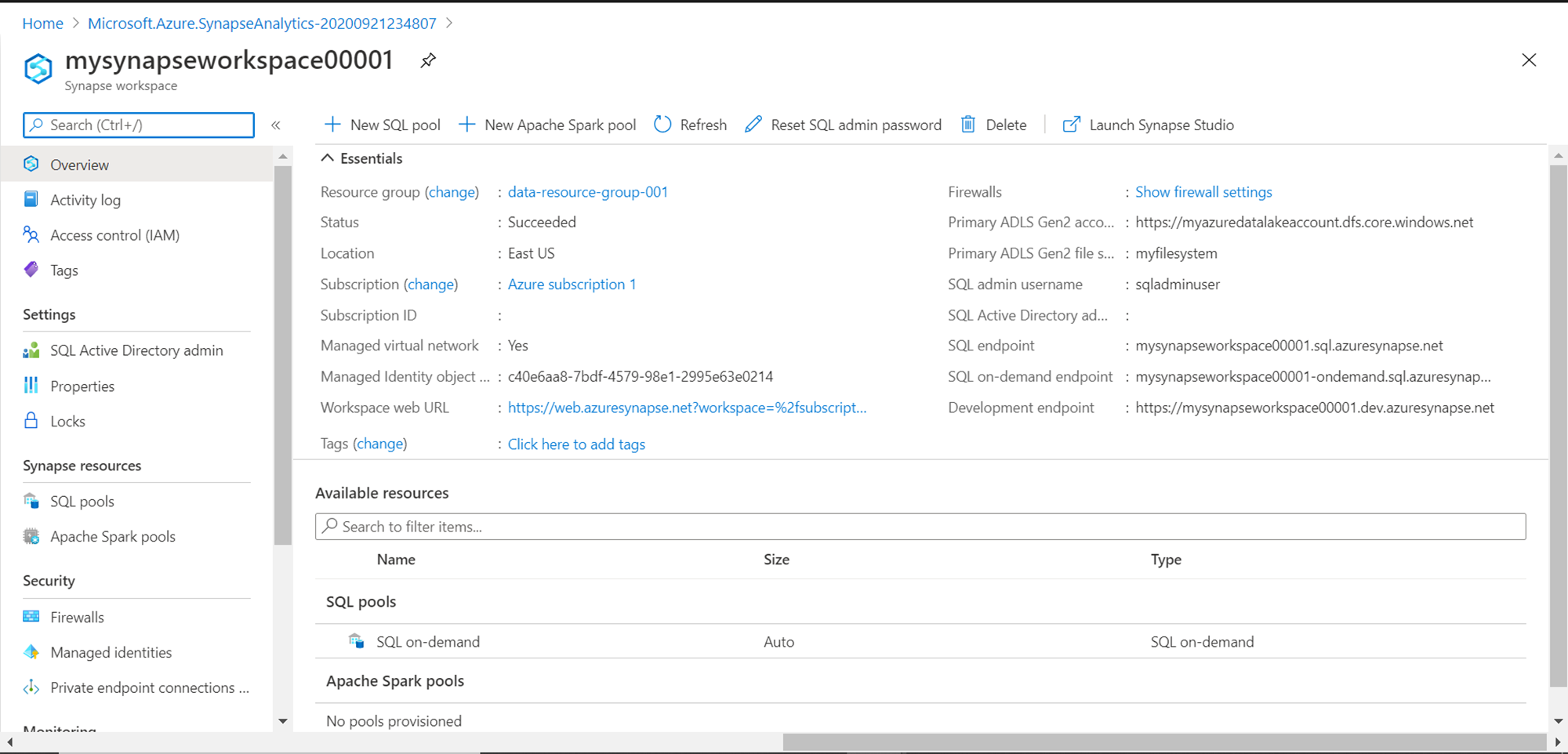
Apache Spark for Azure Synapse – This component of Synapse provides Spark runtime to perform the same set of tasks like data loading, data processing, data preparation, ETLs, and other tasks that are generally related to data warehousing. Azure provides Data Bricks, too, as a service that is based on Spark runtime with a certain set of optimizations, which is typically used for a similar set of purposes. One of the advantages of this feature compared to Azure Databricks is that no additional or separate clusters need to be managed to process data as this is an integral part of Synapse, provides Spark-based processing with auto-scaling, support for features like .NET for Spark, SparkML algorithms, Delta Lake, Azure ML Integration for Apache Spark, Jupyter style notebooks, etc. In addition, it has multi-language support for languages like C#, Pyspark, Scala, Spark SQL, Java, etc. Once a Synapse workspace is created, one can provision Apache Spark pools or Synapse SQL pools from a common interface, as shown below.
- Azure Synapse Security – Apart from the above features, one key aspect to take note of is the array of security features packed in Azure Synapse. It is already compliant with almost 30 industry-leading compliances like ISO, SOC, FedRAMP, DISA, HIPAA, FIPS, etc.
- It supports Azure AD authentication, SQL based authentication as well as Multi-factor authentication
- It supports data encryption at rest and in transit as well as data classification for sensitive data
- It supports row-level, column-level, as well as object-level security along with dynamic data masking
- It supports network-level security with virtual networks as well as firewalls
Azure Synapse is a tightly integrated suite of services that cover the entire spectrum of tasks and processes that are used in the workflow of an analytical solution. These architectural components provide a modular vision of the entire suite to get a head start.
Conclusion
In this article, we learned the fundamentals of Azure Synapse Analytics. We first looked at the high-level architecture, and then understood the inventory of components that make up the architecture. Then we finally dived deep into the core pillars of the Azure Synapse service, to build strong fundamentals of the composition and inner workings of this service.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023