The SQL Server Query Processing Engine is the most complex and sophisticated part of SQL Server. This engine has many responsibilities, but one of the most important parts is to design the query execution plan and execute it in a best and most efficient possible manner.
I would like to mention here one of the most important factors of a SQL Server Execution Plan, which are SQL Server Statistics. Every time we issue a query, the SQL Server query-processing engine needs to estimate the data. To do so, SQL Server queries the Statistics to estimate the data. These estimates are critically important because based on the estimates; many important decisions are made about designing and finalizing SQL Server query execution plan. Therefore, keeping up to date statistics is critically important for a good query execution plan.
SQL Server 2014 introduced a huge change in the query optimizer engine and the next change made in the query optimization engine is in SQL Server 2017. I am so excited to test new changes and so far, it looks very promising.
Before SQL Server 2017, the behavior of the SQL Server query-processing engine was to analyze the query first, create the plan and then execute it. Therefore, if the plan was somehow not appropriate, the query-processing engine was not able to change it while executing the query or even after it. At times, we see the query execution plans made by SQL Server are not appropriate. There are number of reasons behind poorly designed execution plan. Mentioned below are some of the basic reasons for bad execution plans:
- Lack of appropriate indexes
- Outdated statistics
- In-appropriate query execution plans cached with outdated values are stored
- Poorly written codes
Therefore, there are two ways to fix these problems. One is that we let SQL Server fix the issue, by providing more relevant and accurate information about the query and secondly re-write the code so that it may perform in a better way.
SQL Server 2017 introduced a new way of optimizing SQL Server Execution plan by introducing the “Adaptive Query Processing”. However, not much is out there about the feature, but I have tested some examples in SQL Server 2017 CTP 2, which we can download from the link here.
The Adaptive Query Processing breaks the barrier between query plan optimization and actual execution. Now, we can have the optimization done while the actual query is executing or even after the actual query execution is completed to benefit the later executions.
Let me explain this a little bit more!
There are three parts of Adaptive Query Processing.
- Interleaved Executions
- Batch Mode Memory Grant Feedback
- Batch Mode Adaptive Joins
Interleaved Executions
For Multi Statement Table Valued Functions prior to SQL Server 2017, estimate is set to a specific number, which is the nightmare for SQL Server DBAs. This can result in wrong selection of join operator, memory grants and resulting in poorly performing queries.
The new feature can learn that even while the execution of the query, SQL Server Query Optimizer learns that if the estimates are way off than the actual ones, it adjusts the execution plan by actually executing a part of the query execution plan first and re-design the Query Execution Plan based on the actual amount of the rows. This leads to a much better plan, which is created and adjusted while the query is executing.
This feature comes right out of the box and you do not have to add any specific command to your queries to get the benefit from SQL Server 2017
For instance, if we create a simple Multi Statement Table Valued Function in SQL Server 2017 and execute it with Compatibility Level 130 (SQL Server 2016) and 140 (SQL Server 2017) then we can easily see the difference in the Estimated number of rows.
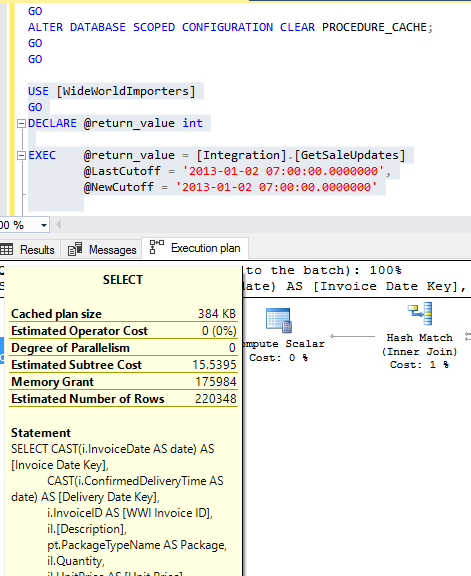
Query Execution Plan and Estimated Number of Rows in SQL Server 2016
In the screen below you can see the Estimated Number of Rows is 100 and Actual Number of rows are 10,000.
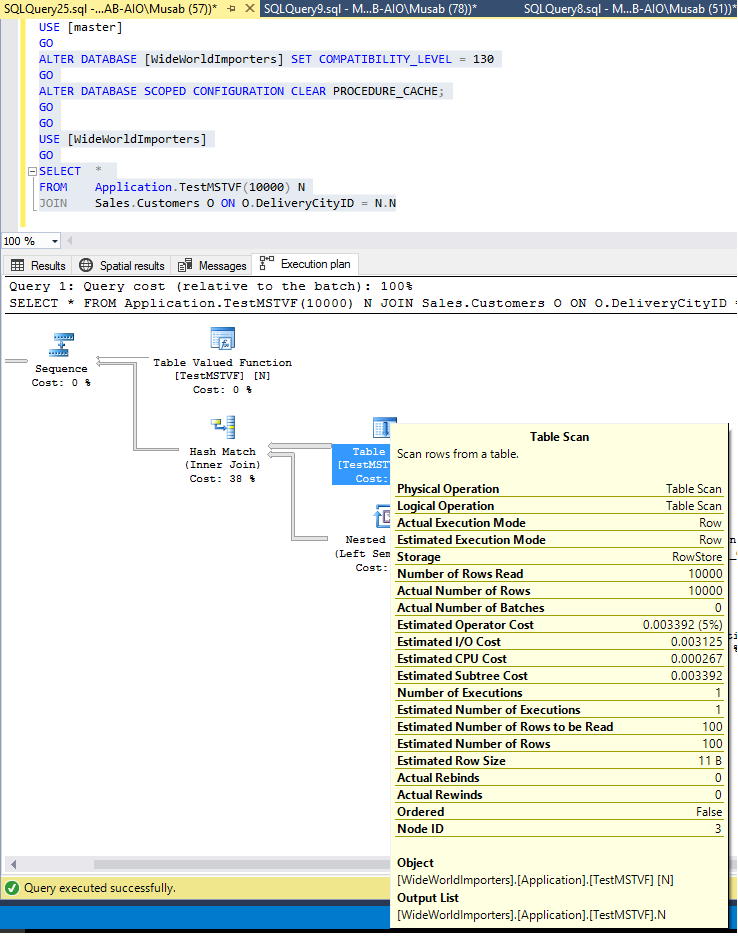
Query Execution Plan and Estimated Number of Rows in SQL Server 2017
The same query executed with compatibility level 140 with no change in any structure or data and the result is an accurate estimation.
Batch Mode Memory Grant Feedback
Memory Grant is another important process in creating an actual query execution plan. Prior to SQL Server 2017, the SQL Server Query Processing Engine used to cache a plan for stored procedures or queries and reuse them. For instance, if we have a Stored Procedure, which executed first time with a parameter resulting in a small amount of data, then the execution plan for that particular stored procedure would be cached for a small amount of data even for later larger data sets. This could result in a poor performance of the execution of the stored procedure with a parameter having a large amount of data. This could cause a small amount of memory grants for the query, but actually, it would have required more.
In SQL Server 2017, the Batch Mode Memory Grant Feedback feature enables the SQL Server Query Processing engine to learn that if the memory grants are not sufficient then the engine will change the cached execution plan and update the memory grants so that the later executions should benefit with the new grants.
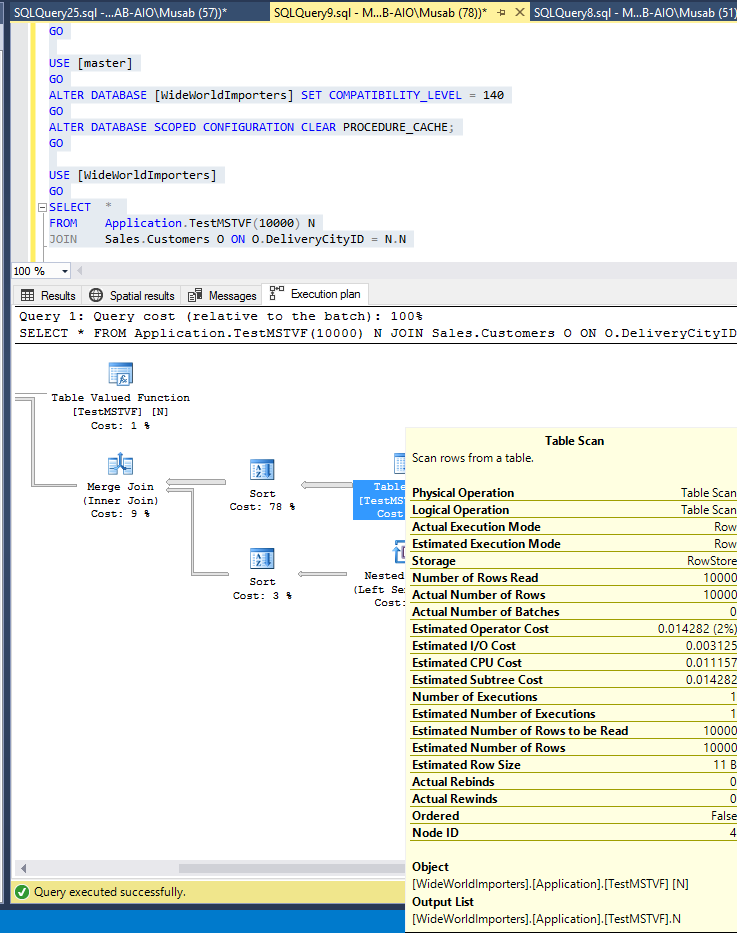
To show the Batch Mode Memory Grant in action I executed a query (Stored Procedure) which was having bad statistics and the memory grant was way off what was required.
In SQL Server 2016’s Compatibility Mode the Query performed the same in all executions:
First Execution
This execution has Memory Grant 175984, which is not appropriate, as the estimated number of rows are 220384 an actual number of rows are Zero.
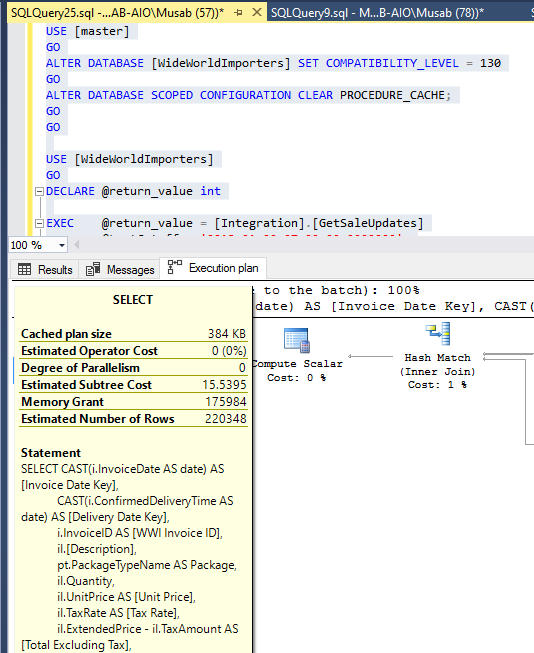
Second Execution
This execution again has the same Memory Grant and nothing was improved unless we change the statistics or the code itself.
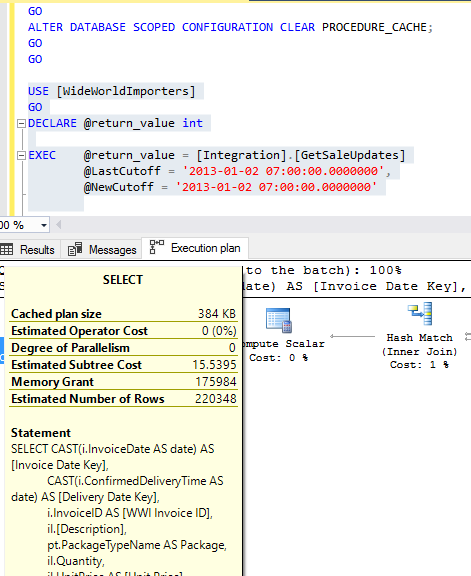
In SQL Server 2017’s Compatibility Mode, the Query performed bad in first execution, but automatically fixed the subsequent executions:
First Execution
This execution has Memory Grant 199872, which is not appropriate, as the estimated number of rows are 251091 an actual number of rows are Zero.
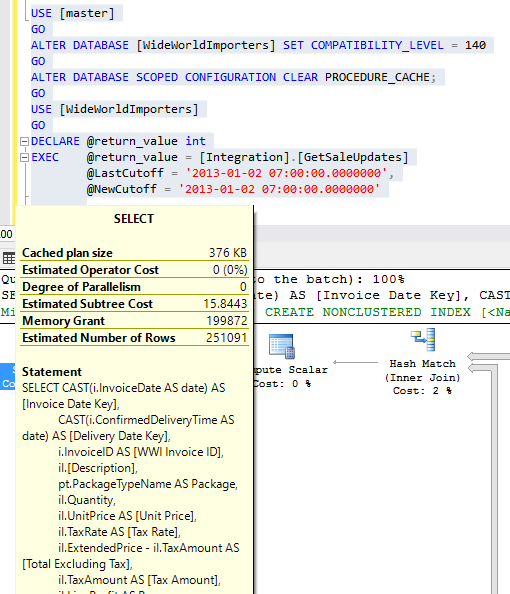
Second Execution:
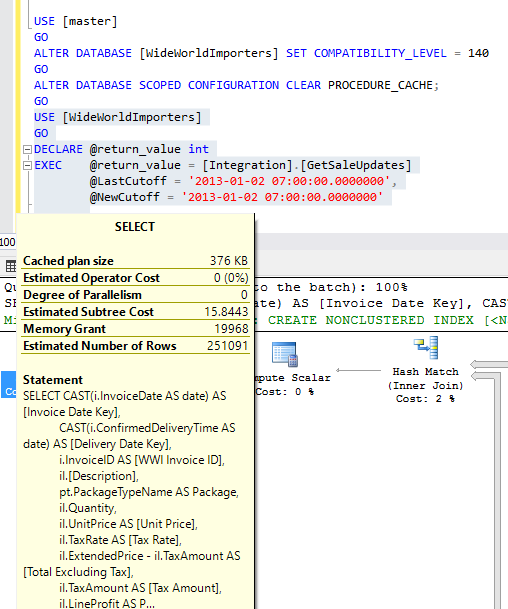
The Memory Grant has changed from 199872 to 19968 which is a huge difference and this has been done automatically without any code change or any server level configurations.
Batch Mode Adaptive Joins
Batch Mode Adaptive Joins are also a great way to improve the query performance based of the number of rows flowing through the actual execution plan. The concept here is simple; the execution engine defers the choice of a Hash Join or a Nested Loop Join until the first join in the query execution plan is made. After that first join has been executed and based on the number of records fetched, the SQL Server Query Processing engine decides whether to choose Hash Join or Nested Loop Join.
As of now, I only have only one point regarding this as the SQL Server Program Managers disclosed nothing else. This is the number of rows threshold. Generally, if the number of rows is small then Nested Loop Join is used, otherwise with large data set the Hash Join will be selected to enhance the query performance.
For the Batch Adaptive Joins I am not able to try it, as it requires some Trace Flags to be enabled, which are still not public.
Summary
SQL Server 2017 is really a big change in SQL Server and this is just the start. There are number of other features, which will make the life of Developers and Database Administrator a lot easier. Even with these enhancements in the SQL Server 2017 Query Processing engine, the results are faster queries and optimized resource consumption. I am still waiting for further announcements to be made for SQL Server 2017.
He has 9+ Years of Database Development & Administration experience with Medical Billing, Startup & Financial Companies. He is a Microsoft Certified Expert for Data Platform (SQL Server 2012/2014).
Currently, performing duties as Senior SQL Server Consultant at multiple Saudi Private and Governmental Organizations.
View all posts by Musab Umair
- How to identify slow running queries in SQL Server - May 31, 2017
- Adaptive Query Processing in SQL Server 2017 - April 28, 2017
- What is the SQL Server Virtual Log file and how to monitor it - April 26, 2017