
A graph database is a type of NoSQL database that is based on graph theory. Graph databases are ideal for storing data that has complex many to many relationships. In this article, we will study the very basics of graph databases with the help of a simple example.
Characteristics of a Graph Database
A graph data consists of nodes and edges. Nodes are also sometimes called vertices. The nodes represent an entity such as a Person, City, Employee, and Customer etc. Edges are used to map the relationship between entities. Graph databases are well suited to things like supply chain management systems. Graph databases have also proven efficient to develop recommender systems where the relationships like “Person who bought item X, also bought item Y,” have to be mapped.
A Simple Example of a Graph Database
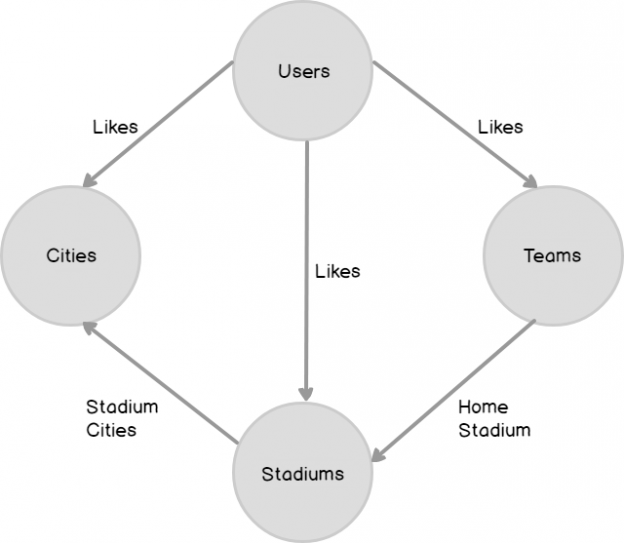
Social media platforms are one of the best examples of how graph databases work. Consider a scenario where a person likes a particular football team. A user can also like one or more football stadiums. Alternatively, one football stadium can be liked by multiple users. Users can also like football stadiums and cities. A football team has a home stadium. A stadium can be located in a particular city and one city can have multiple stadiums. A graph database is ideally suited to storing this type of information. Users, teams, stadiums and cities can be implemented as entities or nodes. On the other hand, likes, home stadium and stadium cities can be implemented as relationships or edges.
The following figure represents such a graph database:
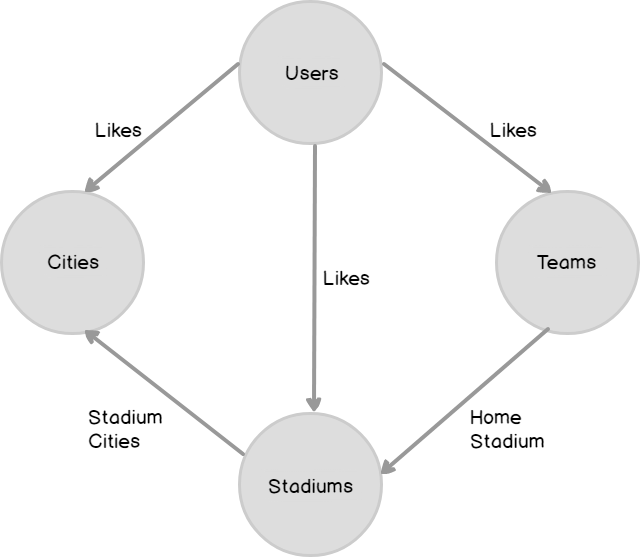
Let’s now implement the graph database for the scenario that we discussed in the last section.
Implementing a Graph Database
As discussed earlier, a graph database primarily consists of nodes and edges. Let’s first implement the nodes in our graph database. We will be using SQL Server Management Studio to run our scripts.
Let’s create our database:
|
1 2 3 4 5 6 |
USE master; GO DROP DATABASE IF EXISTS PLGraph; GO CREATE DATABASE PLGraph; GO |
In the script above, we created a database named “PLGraph”. The database will store information about users who like premier league teams. A few premier league teams will also be stored in the database along with their home stadiums and cities in which the stadiums are located.
Implementing Nodes
We identified 4 nodes in our database. Let’s implement them one by one. We will start with the Users node.
Users Node
Execute the following script to implement the Users node.
|
1 2 3 4 5 6 7 8 |
USE PLGraph; GO DROP TABLE IF EXISTS Users; GO CREATE TABLE Users ( UserID INT IDENTITY PRIMARY KEY, UserName NVARCHAR(100) NOT NULL, ) AS NODE; |
You can see that creating a node in a graph database is very similar to creating a table. The syntax is pretty similar. However, to create a node, all you have to do is specify “AS NODE” at the end of table definition as shown in the above script.
You can see that the node has one primary key UserID and one column UserName. It is important to mention that a node must contain a primary key.
To see if a table is a node or an edge, you can use the following script:
|
1 2 |
SELECT is_node, is_edge FROM sys.tables WHERE name = 'Users'; |
The output looks like this:
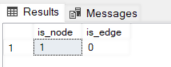
In the output, you can see a 1 in the “is_node” column and 0 in the “is_edge” column, which means that this table represents a node.
Let’s now enter some records in the Users node.
|
1 2 3 4 5 6 |
VALUES ('James'), ('George'), ('Mike'), ('Alan'), ('Joe') |
Now, execute the following script to see the records in the Users node:
|
1 |
SELECT * FROM Users |
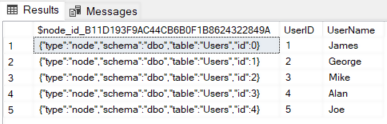
You can see that there are three columns in the Users node. Two of the columns i.e. UserID and UserName are user-defined columns. If you look at the first column it contains JSON data that contains type, scheme and id for each record in the node. By default, the id for the records in the node begins with 0.
In the same way, we can create nodes for Teams, Stadiums and Cities.
Teams
Execute the following script to create Teams node and to insert some dummy records in the Teams node.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE PLGraph; GO DROP TABLE IF EXISTS Teams; GO CREATE TABLE Teams ( TeamID INT IDENTITY PRIMARY KEY, TeamName NVARCHAR(100) NOT NULL, ) AS NODE; INSERT INTO Teams (TeamName) VALUES ('Arsenal'), ('Manchester United'), ('Tottenham'), ('Liverpool'), ('Chelsea') |
If you look at the records in the Teams node, you will see that it also contains three columns: Two user-defined columns and one default column containing information about the records in the node, as shown below:
|
1 |
SELECT * FROM Teams |
Let’s now create Stadiums and Cities nodes.
Stadiums
Execute the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
USE PLGraph; GO DROP TABLE IF EXISTS Stadiums; GO CREATE TABLE Stadiums ( StadiumID INT IDENTITY PRIMARY KEY, StadiumName NVARCHAR(100) NOT NULL, ) AS NODE; INSERT INTO Stadiums (StadiumName) VALUES ('Old Trafford'), ('Emirates'), ('Tottenham Hotspur Stadium'), ('Anfield'), ('Stamford Bridge'), ('Upton Park'), ('Goodison Park') |
Cities
Finally, let’s create the Cities node:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE PLGraph; GO DROP TABLE IF EXISTS Cities; GO CREATE TABLE Cities ( CityID INT IDENTITY PRIMARY KEY, CityName NVARCHAR(100) NOT NULL, ) AS NODE; INSERT INTO Cities (CityName) VALUES ('Manchester'), ('London'), ('Liverpool'), ('Bristol'), ('Cardif'), ('Birmingham') |
Now we have created all the four nodes in our graph database. Now it is time to create edges. As mentioned in the figure, we will create three edges: Likes, HomeStadium and StadiumCities.
Implementing Edges
Let’s first create the Likes edge.
Likes
Execute the following script:
|
1 2 3 4 |
DROP TABLE IF EXISTS Likes; GO CREATE TABLE Likes AS EDGE; |
You can see that an edge is also defined as a table. You only have to specify the keyword “AS EDGE” after table definition. It is also important to mention that primary key and user-defined columns are optional in case of edges.
Let’s now verify if the Likes table is actually an edge or not. Execute the following script:
|
1 2 |
SELECT is_node, is_edge FROM sys.tables WHERE name = 'Likes'; |
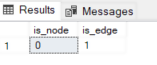
Now you can see that the “is_edge” column contains 1, which means that the “Likes” table is actually an edge.
Let’s create the HomeStadiums and StadiumCities edges in the same.
HomeStadiums
|
1 2 3 |
DROP TABLE IF EXISTS HomeStadiums; GO CREATE TABLE HomeStadiums AS EDGE; |
StadiumCities
|
1 2 3 |
DROP TABLE IF EXISTS StadiumCities; GO CREATE TABLE StadiumCities AS EDGE; |
We created our nodes and edges. Let’s now perform a few operations on the graph databases.
Performing Operations on Edges
In this section, we will see how to insert, read and delete records from an edge.
Insertion
Edges are used to define the relationship between two or more nodes. Suppose you want to implement the relation that a user likes a specific team, you can implement that by inserting a record into the Likes edge.
When you create an edge, two columns are created by default in the edge. The columns are “$from_id” and “$to_id”. To define a relationship, you have to insert the “$node_id” of the from node in the “$from_id” column and the “$node_id ” of the to node in the “$to_id” column.
Let’s implement a likes relation between the user with Id 1 and the team with id 3. The from node will be from the user and the to node will be from the team. Execute the following script:
|
1 2 3 |
INSERT INTO Likes ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Users WHERE UserID = 1), (SELECT $node_id FROM Teams WHERE TeamID = 3)); |
Let’s implement one more relation between the user with id 2 and team with id 4.
|
1 2 3 |
INSERT INTO Likes ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Users WHERE UserID = 2), (SELECT $node_id FROM Teams WHERE TeamID = 4)); |
Finally, we will implement a Likes relation between user with id 3 and stadium with id 2.
|
1 2 3 |
INSERT INTO Likes ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Users WHERE UserID = 3), (SELECT $node_id FROM Stadiums WHERE StadiumID = 2)); |
You can see that using one Likes edge, we can implement relations between more than 2 nodes. With relational databases, we have to define a foreign key column in each table and then we have to create one lookup table for each many to many relations. Here in the case of graph databases, we can use one Likes edge to implement Likes relation between any numbers of nodes.
Let’s now add a few dummy records in HomeStadiums and StadiumCities edges.
The following script adds three records in the HomeStadiums edge. Logically, this node is used to implement the relation between teams and their home stadiums.
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO HomeStadiums ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Teams WHERE TeamID = 1), (SELECT $node_id FROM Stadiums WHERE StadiumID = 2)); INSERT INTO HomeStadiums ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Teams WHERE TeamID = 2), (SELECT $node_id FROM Stadiums WHERE StadiumID = 1)); INSERT INTO HomeStadiums ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Teams WHERE TeamID = 4), (SELECT $node_id FROM Stadiums WHERE StadiumID = 4)); |
Finally, let’s insert a few records in StadiumCities nodes.
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO StadiumCities ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Stadiums WHERE StadiumID = 1), (SELECT $node_id FROM Cities WHERE CityID = 1)); INSERT INTO StadiumCities ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Stadiums WHERE StadiumID = 2), (SELECT $node_id FROM Cities WHERE CityID = 2)); INSERT INTO StadiumCities ($from_id, $to_id) VALUES ( (SELECT $node_id FROM Stadiums WHERE StadiumID = 3), (SELECT $node_id FROM Cities WHERE CityID = 2)); |
Selecting Data
To select data, you simply have to specify the column names in the select clause followed by MATCH statement in the WHERE clause.
For instance, if you want to select the UserName and the TeamName that the user Likes, you use the following script.
|
1 2 3 |
SELECT FbUser.UserName, team.TeamName FROM Users FbUser, Likes, Teams team WHERE MATCH(FbUser-(Likes)->team); |
You can see in the match clause, we specify the instance of the Users node, followed by Likes edge in the parenthesis and finally team instance after an array. In the output, you will see user names and their corresponding favorite teams.
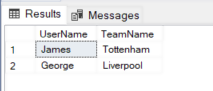
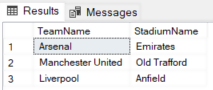
In the same way, we can retrieve team names and their corresponding home grounds as shown below:
|
1 2 3 |
SELECT team.TeamName, stadium.StadiumName FROM Teams team, HomeStadiums, Stadiums stadium WHERE MATCH(team-(HomeStadiums)->stadium); |
The output contains team names and their home stadiums.
In the same way, you can perform a compound SELECT statements. For instance, you want to see the user names along with their favorite teams and their home stadiums, you can use the following script:
|
1 2 3 |
SELECT FbUser.UserName, team.TeamName, stadium.StadiumName FROM Users FbUser, Likes, Teams team, HomeStadiums, Stadiums stadium WHERE MATCH(FbUser-(Likes)->team AND team-(HomeStadiums)->stadium); |
The output looks like this:
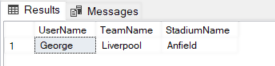
Deleting Records
To delete a record from the edge, you have to use the DELETE statement. In the where clause you have to specify the “$from_id” and the “$to_id”. For example, the following script deletes record in the HomeStadiums edge where team id is 2 and the stadium id is 1.
|
1 2 3 |
DELETE HomeStadiums WHERE $from_id = (SELECT $node_id FROM Teams WHERE TeamID = 2) AND $to_id = (SELECT $node_id FROM Stadiums WHERE StadiumID = 1); |
Conclusion
Graph databases are changing the way complex many to many operations are implemented. In this article, we briefly reviewed how to create nodes and edges in graph databases. We also saw how to implement relationships between different nodes and how to perform insert, read and delete operations on the edges. To continue your learning on Graph Databases in SQL Server, you can direct to the following articles:
- An introduction to a SQL Server 2017 graph database
- How to implement a graph database in SQL Server 2017
You can also go over my other articles below:
- Understanding SQL Server case statement
- How to use window functions
- Machine Learning Services – Configuring R Services in SQL Server

View all posts by Ben Richardson
- Working with the SQL MIN function in SQL Server - May 12, 2022
- SQL percentage calculation examples in SQL Server - January 19, 2022
- Working with Power BI report themes - February 25, 2021