
In this article, we will learn to create external tables in Azure Synapse Analytics with dedicated SQL pools.
Introduction
In the previous parts of the Azure Synapse Analytics article series, we learned how to use SQL Server Integration Services (SSIS) to populate data. At times, one may need to access data in-place without the need to copy the entire dataset to Azure Synapse. Typically, the Azure Data Lake Storage account is used to host a large volume of data files. Accessing data from data files stored in Azure Data Lake Storage without the need to physically create a copy of this data in the Azure Synapse Analytics dedicated SQL pool on the local storage can provide fast and ad-hoc data access to data that is hosted outside the bounds of Azure Synapse Analytics. Let’s go ahead to understand the creation of external tables in an Azure Synapse Analytics with dedicated SQL pools.
Pre-requisites
Azure Synapse Analytics offers two types of SQL pools – SQL on-demand pool and dedicated SQL Pool. SQL on-demand pools do not have any local storage at all, so the only option is to access data from different sources in-place. In the case of dedicated SQL pools, it offers a distributed parallel-processing engine with the option to store massive data volumes locally as well. This local data may need to reference data stored externally i.e. outside Azure Synapse Analytics. This is the exact use-case we are going to address in this article. For this, we would need an Azure Synapse Analytics workspace and a dedicated SQL pool in place, as covered in the previous part of this article series.
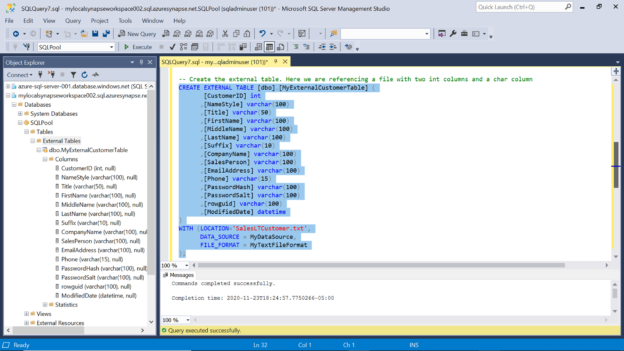
When we create a Synapse workspace account, by default it creates an Azure Data Lake Storage Gen2 account. We would need some sample data on this storage account, as it would act as the external data which we will attempt to access from the SQL Pool instance. In this case, we have the sample data available in the Azure SQL database exported in CSV format and stored in text files on the Azure Data Lake Storage account. Open Synapse Studio from the Synapse workspace account. In the Data section under the linked tab, one can explore the files stored in the Azure Data Lake Storage account. Right-click on the file and select Preview to explore the data in the file as shown below. This data file named SalesLTCustomers.txt is the file that we intend to access from the SQL pool instance.
External tables in Azure Synapse Analytics
Assuming that pre-requisites are in place, we now need to connect to the Synapse dedicated SQL pool instance using SSMS. After successfully connecting to this instance, create a new query and type the SQL script as shown below.
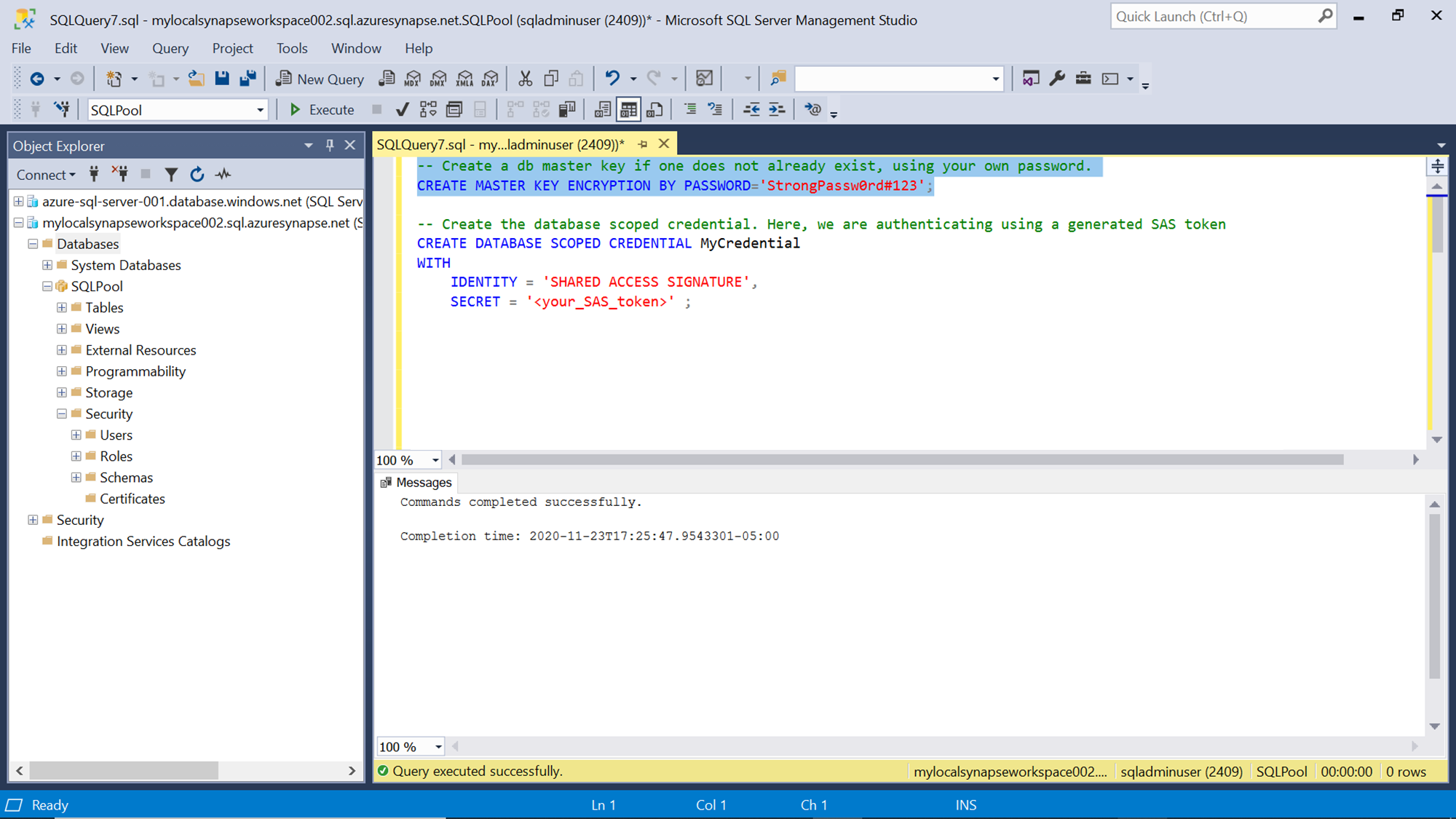
The first step is to create a master key in the database that would be used for encryption. This can be done using the CREATE MASTER KEY command as shown below. Ensure to specify a complex password else the command would fail as it would not pass the requirements enforced by the security policy for creating master keys.
In the next step, create a database scoped credential that would be used by the Synapse dedicated SQL pool to connect to the Azure Data Lake Storage Gen2 account. We are going to use the Shared Access Signature Key, so we would be specifying the keyword “SHARED ACCESS SIGNATURE” as the identity and the value of the secret as the SAS key of the storage account.
Execute both the commands which should result in the creation of the master key as well as a database scoped credential.
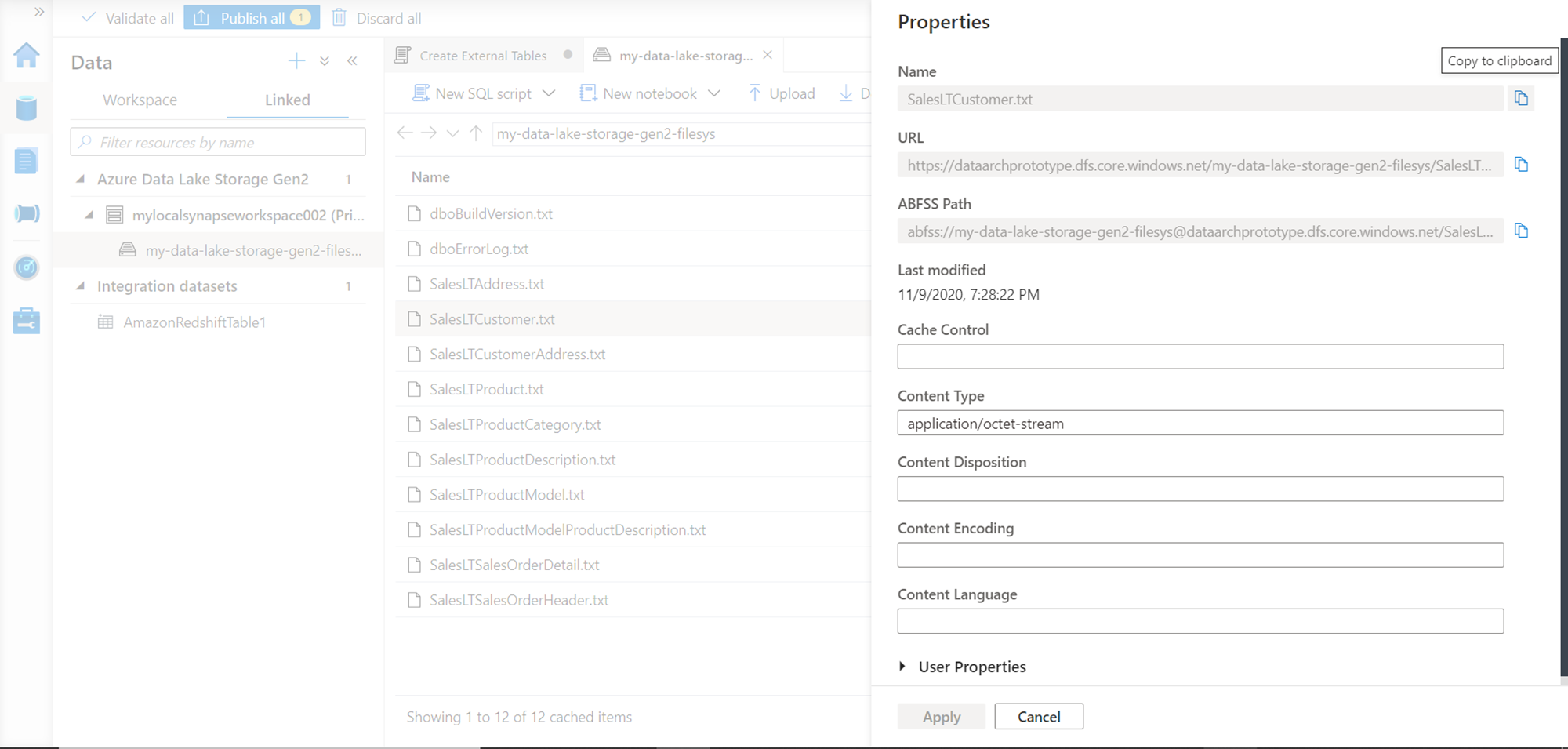
Navigate to the data file in the Azure Data Lake Storage Gen2 account, right-click and select the Properties menu option. It would pop-up a property page as shown below. Copy the ABFSS path of the file as we would need this in the next step.
In this step, we need to register a new data source as well as a new file format with the SQL pool, before we can create database objects pointing to the external data source.
We can create an external data source using the CREATE EXTERNAL DATA SOURCE command. We need to specify the type as “HADOOP”, the value of the location would be the value that we copied in the previous step, and the credential would be the name of the credential that we created earlier using the SAS key of the storage account. After registering the data source, we need to register a file format that specifies the details of the delimited file that we intend to access. This can be achieved using the CREATE EXTERNAL FILE FORMAT command. The type of format would be delimited text as CSV, TXT, TSV, etc. are delimited file formats. In the format options, we need to specify details like field delimited, row terminator, etc. as shown below. Execute both the command as shown below, and it would create a new data source and file format. Refresh the object explorer pane, and expand the external resources section and we should be able to see the newly created data source and file format listed in the object explorer pane.
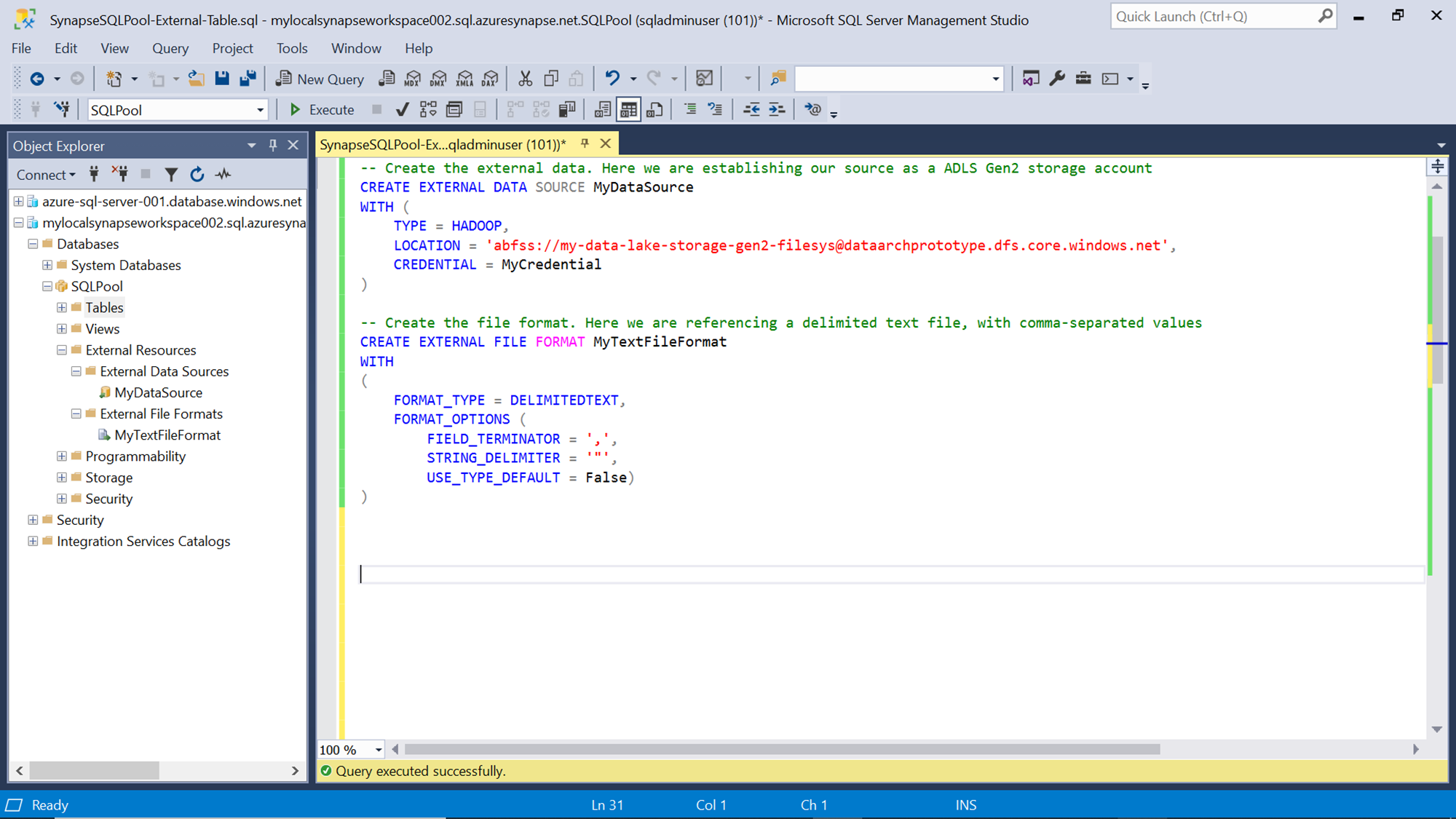
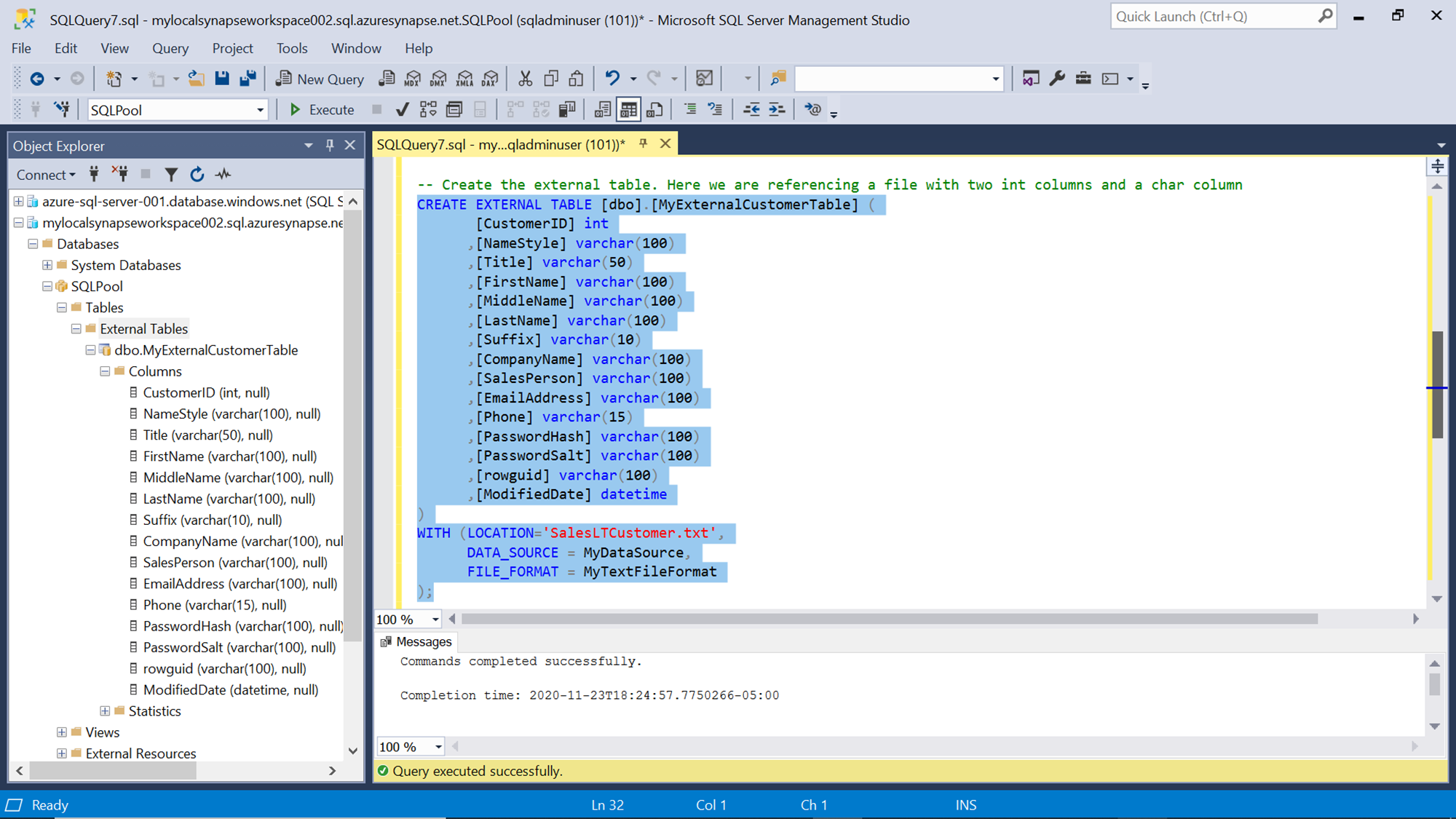
Now we have the required objects to create an external table that would point to the data file stored in the Azure Data Lake Storage Gen2 account. Type the script of the table that matches the schema of the data file as shown below. We can create the external table using the CREATE EXTERNAL TABLE command. The syntax is almost the same as we create a normal table in SQL Server. The column definition can use the same datatypes that are available in SQL Server. In the WITH clause of the command, we need to specify the data source and file format that we have registered earlier. In the location attribute, we need to specify the path to the file excluding the data source path. In case if the file is hosted in a hierarchy of containers on the storage account, we need to specify the path starting from the name of the top-most level of the container. In this case, the file is hosted at the root level in the storage account, so only the name of the file has been mentioned in the location attribute. Execute this command and it would create an external table as shown below. Refresh the object explorer pane and we would be able to see the external table as shown below.
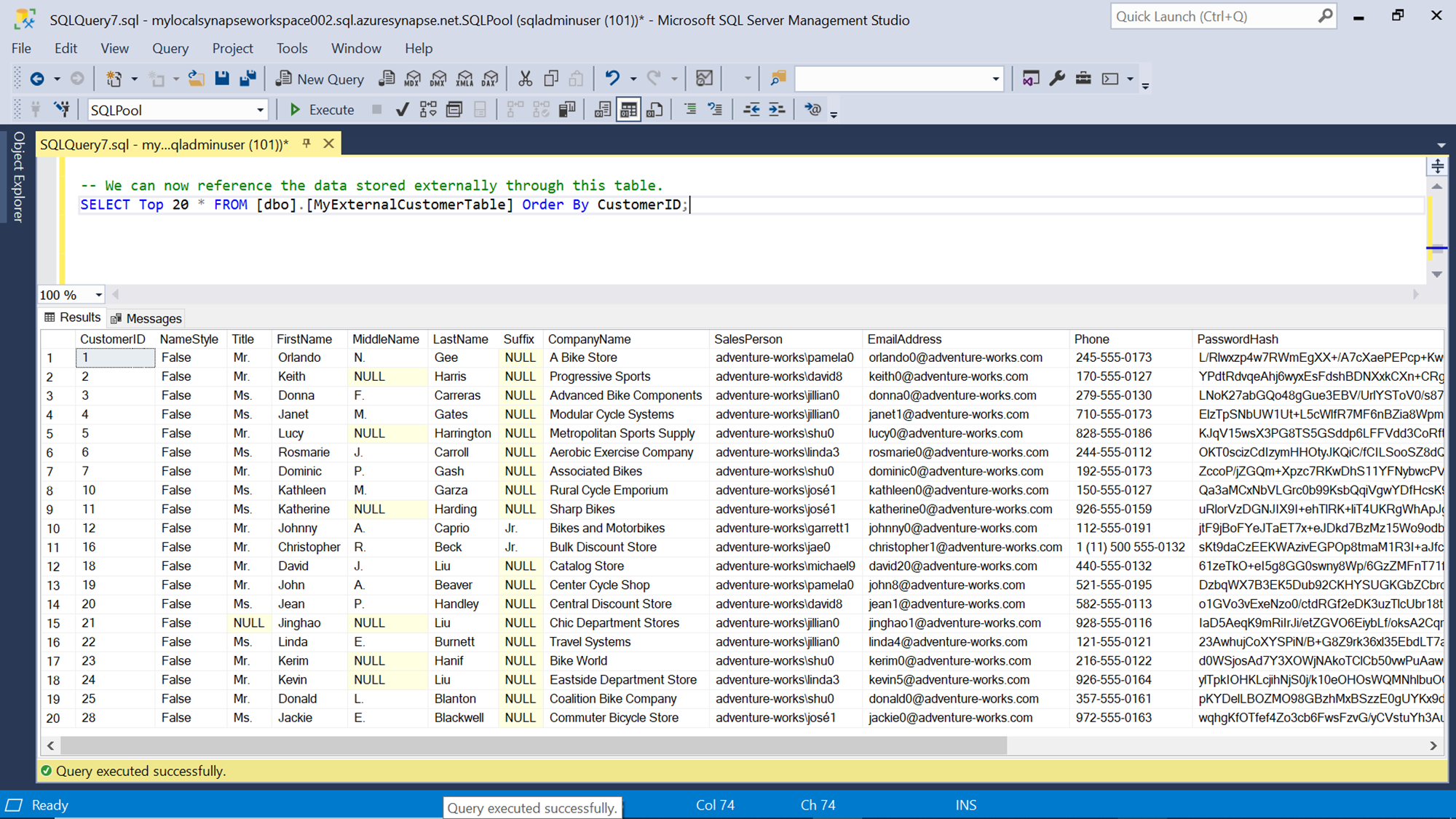
Now it’s time to test whether the external table is working as expected. It can be the case that the table gets created but only when we access the table, it may surface errors as the table does not bind to the data file directly. It reads from the data file only when it’s accessed. So, to test the table, execute a select query on the table as shown below. Here we are trying to get the top twenty records from the data file and sorting it by an attribute. If the credential, data source, file format and the schema of the data file coincides perfectly with the schema of the external table, the result would appear as shown below.
The performance of such a table is limited to the data repository and the type of data file from where the data is being sourced. At times one may want to extract this data from the external table and store it in a local table as the dedicated SQL pool in Azure Synapse Analytics offers local storage which is much faster than accessing external data. This can be achieved by creating a local table using the output of an external table as shown below.
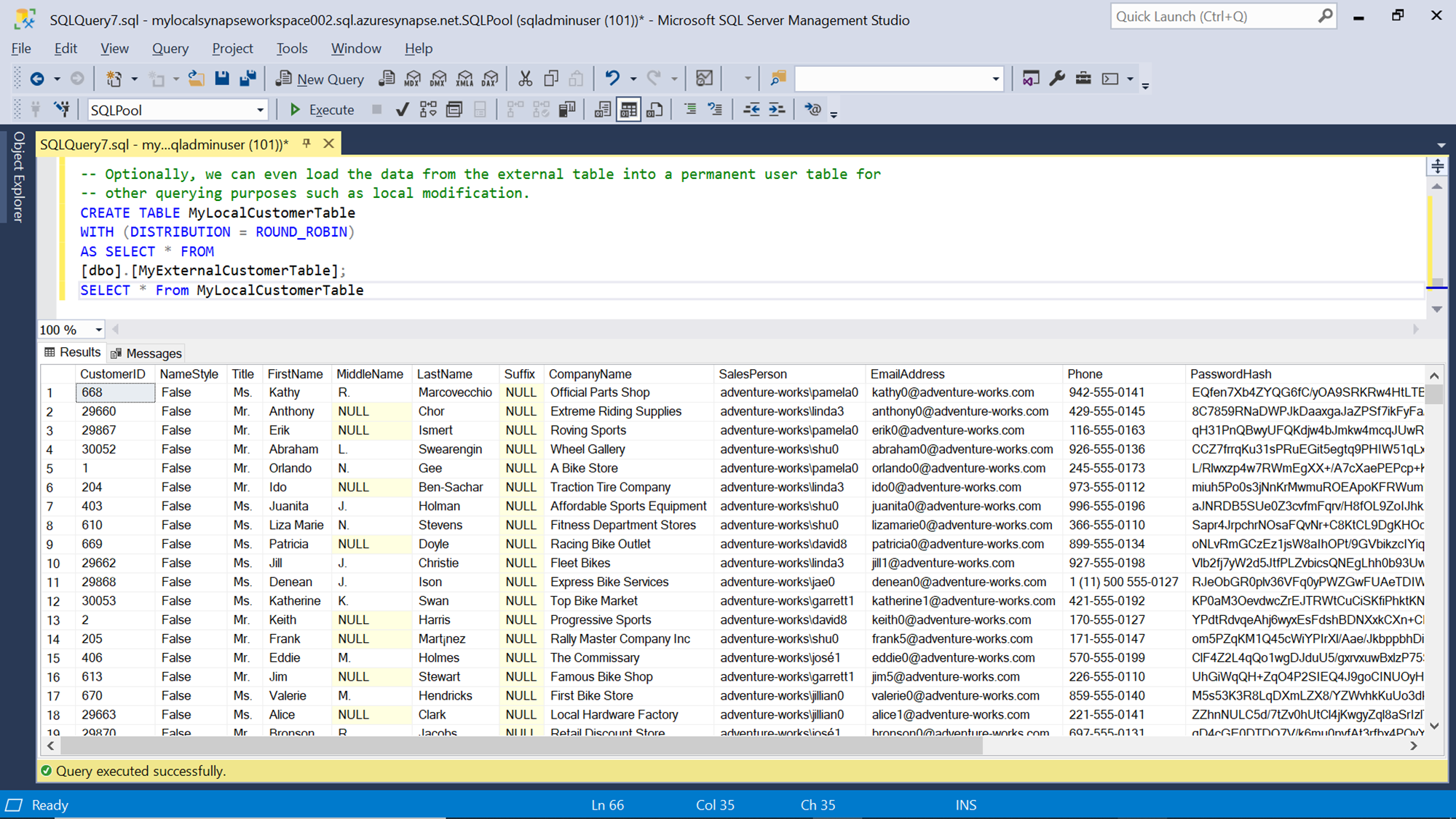
In this way, we can create external tables in Azure Synapse Analytics to access external data.
Conclusion
In this article, we started with a setup of a dedicated SQL pool in Synapse. We created a new database scope credential, a new data source and a new file format. After registering these objects, we created an external table pointing to a data file stored in Azure Data Lake Storage using these objects. We also learned how to create a local table in Azure Synapse Analytics using data from an external table.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023