
Abstract
It is common assumption that an Index Seek operation in a query plan is optimal when returning a low number of output rows. In a scenario involving residual predicates, an Index Seek operation could be reading a lot more rows than it needs into the memory, then each row is evaluated and discarded in memory based on the residual predicate and returns low number of output rows.
This article will explain the concept and the impact of Residual Predicates in a SQL Server Index Seek operation.
Index Seek Operation
SQL Server accesses a table or an index via the mean of a lookup, scan or a seek operation. In an index seek operation, a Seek Predicate is when SQL Server is able to get the exact filtered result. In the case of an index seek on multi-column, SQL Server may introduce a Predicate in the Index Seek operation. This Predicate is often referred as residual predicate because SQL Server performs additional filtering on the resultset from the index seek operation.
To understand the behaviour of residual predicate in SQL Server, we will walk-through two scenarios
- Index Seek
- Index Seek with Residual Predicate
The scenarios will utilize WideWorldImportersDW database on SQL Server 2016 Developer Edition Service Pack 1.
Index Seek Predicate
This scenario will walkthrough a common index seek predicate operation. First, we will create a non-clustered index on [Fact].[Order] table as below
|
1 2 3 4 5 6 |
USE WideWorldImportersDW GO CREATE NONCLUSTERED INDEX IX_SQLShack_StockItemKey ON [Fact].[Order] ([Salesperson Key]) INCLUDE ([Stock Item Key]) |
We will now execute the query below and look at the query plan and the I/O statistics
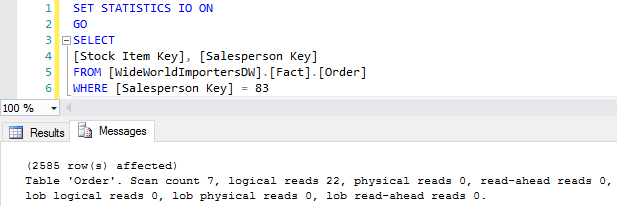
A total of 2,585 rows returned and the logical reads incurred are 22 reads.
We need to pay attention to a new SQL Server XML attribute Number of Rows Read in the query plan which was introduced in the SQL Server Service Pack level listed below to diagnose query plan which involved predicate pushdown.
- SQL Server 2012 Service Pack 3
- SQL Server 2014 Service Pack 2
- SQL Server 2016 Service Pack 1
The XML attribute will not appear your query plan if the service pack level is lower than the list above or on a SQL Server version lower than SQL Server 2012.
Estimated Number of Rows to be Read is another new XML attributed introduced in SQL Server 2016 Service Pack 1. But to diagnose query plan with residual predicate, this article will focus on the XML attribute Number of Rows Read.
| XML attribute | Description |
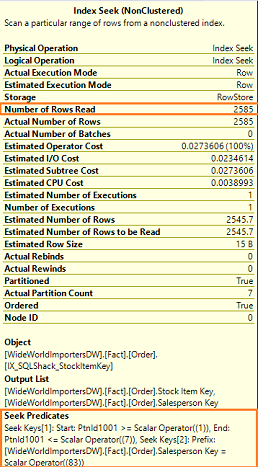
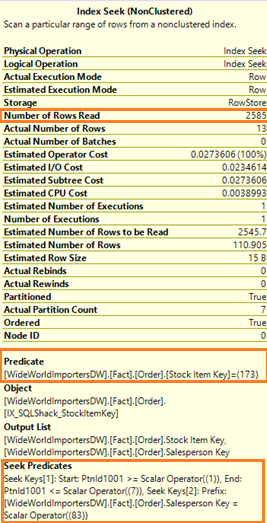
| Number of Rows Read (**New) | Number of actual rows accessed by SQL Server. In this example, SQL Server read 2,585 rows |
| Actual Number of Rows | Number of rows output from the index seek operation. In the example, all the 2,585 rows satisfies the condition in the index seek |
In this scenario where there is no residual predicate, the Index Seek operator properties shows that SQL Server reads and outputs the same number of rows. It means that SQL Server only reads the rows that it requires and spool the rows to the next operator.
Index Seek with Residual Predicate
The first scenario is an Index Seek with Seek Predicates. We will now modify the query slightly and introduce a second predicate on column [Stock Item Key] into the query. Since this column is an included column in the index definition IX_SQLShack_StockItemKey, SQL Server would still be able to perform an index seek on the same non-clustered index.
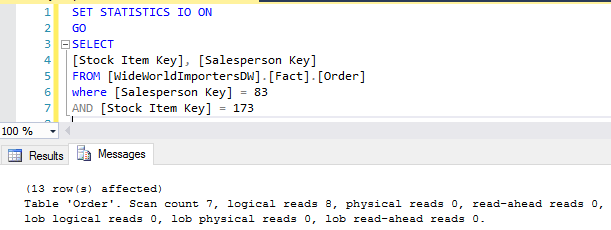
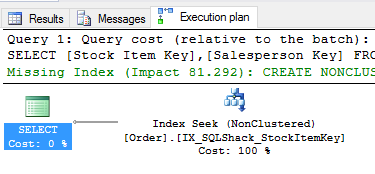
The query plan looks the same as before and the logical reads incurred are still 22 reads. The query returns 13 rows, but the statistics I/O reads is same as if 2,585 rows were read.
Looking at the Index Seek operator properties, SQL Server read 2,585 rows (indicated by the new XML attribute Actual Number of Rows), then performs a filtering based on the Predicate ([Stock Item Key] = 173) and the actual rows spooled to the next operator is only 13 rows (indicated by the Actual Number of Rows).
Explanation on Residual Predicate Pushdown
We can learn a bit more about residual predicate behaviour using an undocumented trace flag 9130. Before SQL Server introduced Number of Rows Read attribute, trace flag 9130 is the workaround to troubleshoot queries which contains residual predicate.
We will use the trace flag as a query option as below.
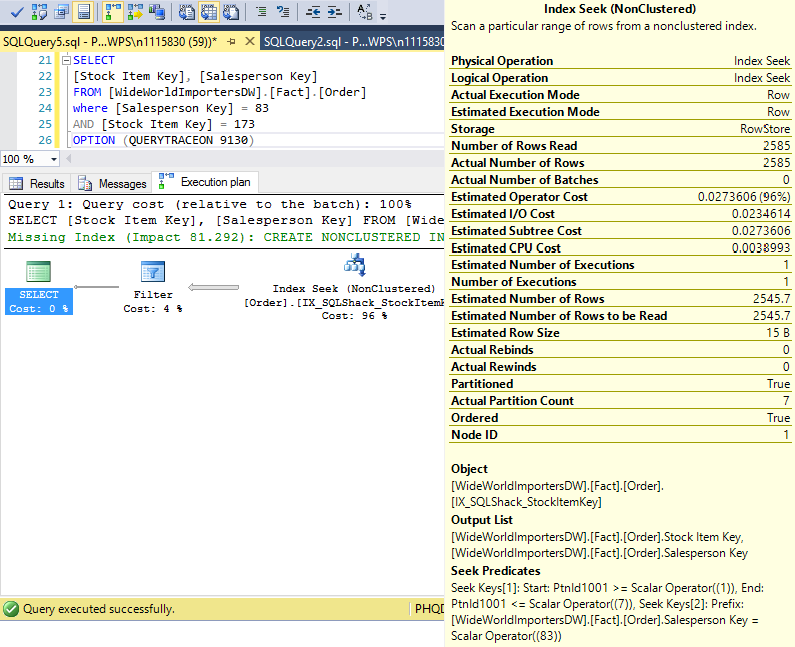
What the trace flag shows us is that SQL Server first reads all the 2,585 rows into memory, then evaluate each row and discard rows which do not satisfy the condition in the Filter operator based on the second predicate. This explains why the same I/O reads were incurred by both queries in the two scenarios.
Performance Impact due to Residual Predicate
We now move on to an example to compare the query performance of an Index Seek with and without residual.
We will use the query below as an example. One of the reasons to use query hint LOOP JOIN is the ease in demonstrating a scenario where residual predicate can really hurt query performance.
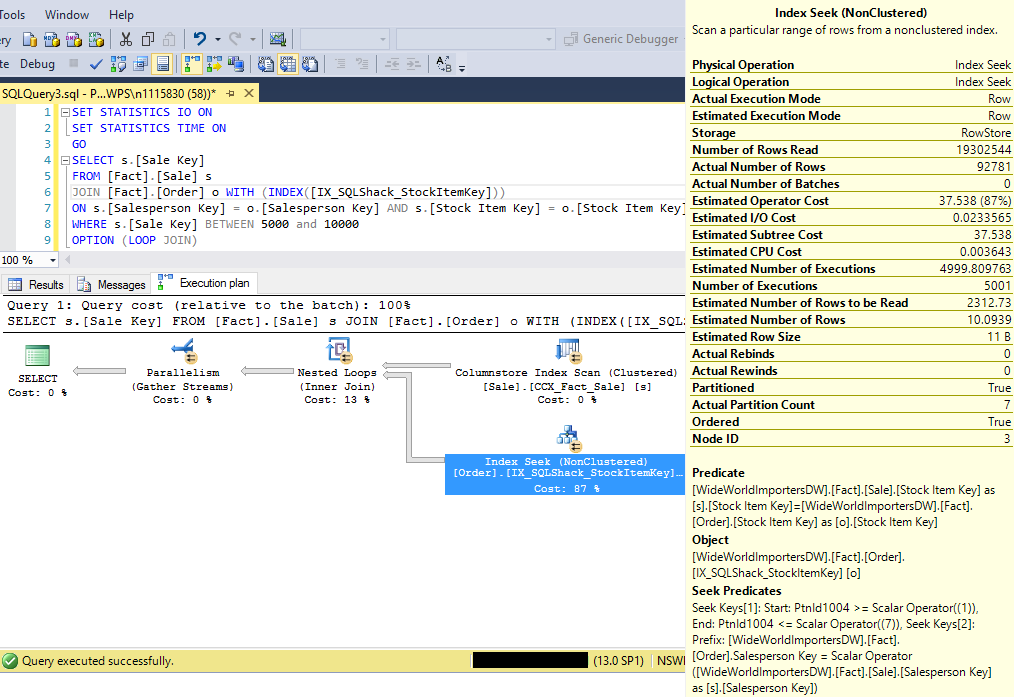
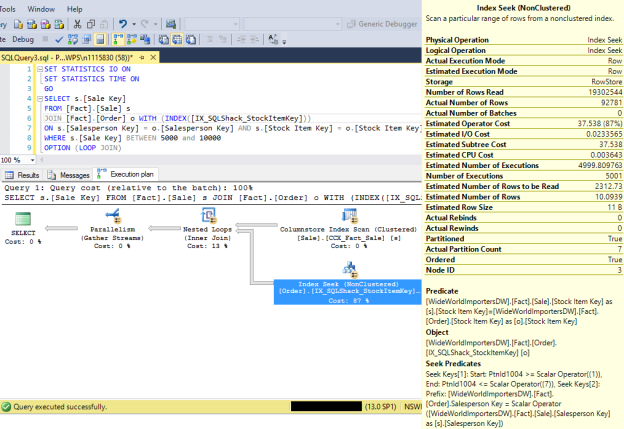
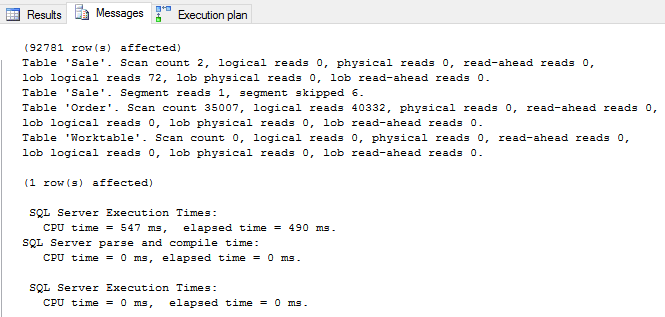
The query incurred 127,851 logical reads on [Fact].[Order] table and took almost 3 seconds to complete execution. The Index Seek properties indicate that SQL Server read over 19 million rows into memory, but really only requires 92,781 rows.

We will now create another index definition and forces the query to use this index instead.
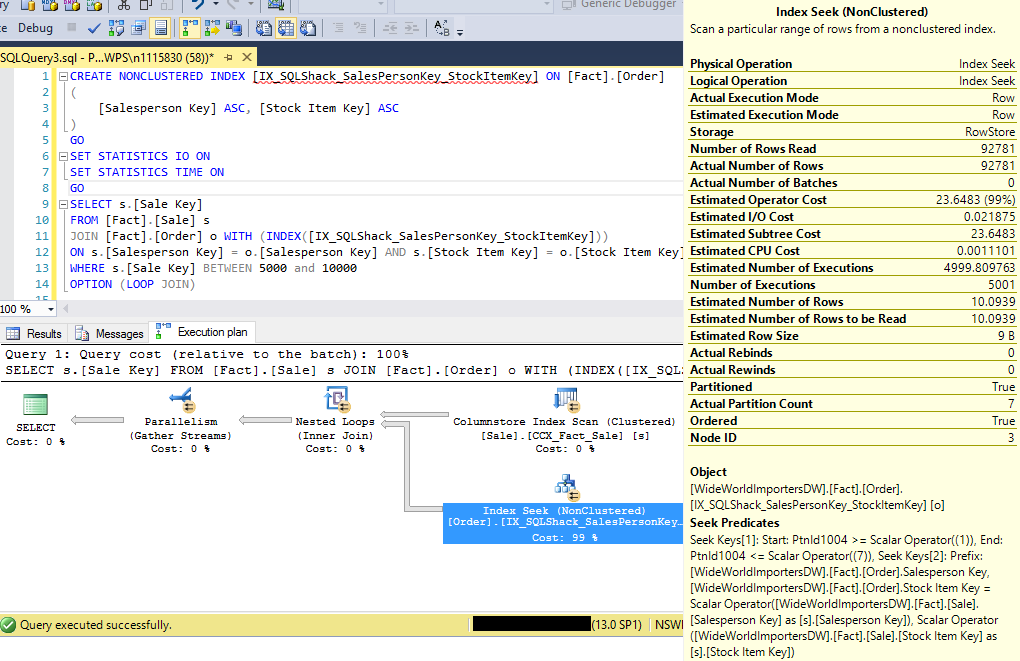
This query incurred 40,332 logical reads on [Fact].[Order] table and took less than half second to complete execution. This query is 6 times faster without residual. In this scenario, SQL Server pushes the filter down to the table access operator itself and only read exactly 98,781 rows that it needs.
Summary
Predicate pushdown is important because you would want SQL Server to filter the results as early as possible in the query plan. The more rows that SQL Server operator has to access, the longer the operation will take.
A Residual predicate scenario can occur in many forms and scenarios other than the examples in this article. Understanding the behaviour of residual predicates will allow better analysis in relation to performance tuning and troubleshooting.
In addition, SQL Server now has introduced new XML attributes to better diagnose query plans that involve residual predicate pushdown.

Simon has over 15+ years of database design, implementation, administration and development in SQL Server. He is a Microsoft Certified Master for SQL Server 2008 and holds a Master’s Degree in Distributed Computing. Achieving Microsoft masters-level certifications validate the deepest level of product expertise, as well as the ability to design and build the most innovative solutions for complex on-premises, off-premises, and hybrid enterprise environments using Microsoft technologies.
View all posts by Simon Liew