

By default, SQL Server stores data logically in the tables as rows and columns, which appear in the result grid while retrieving data from any table and physically in the disk in the row-store format inside the data pages. A new data store mechanism introduced in SQL Server 2012, based on xVelocity in-memory technology, in which the data is stored in the column-store data format. This data store mechanism called the Columnstore index.
The standard row-store index is useful when searching for a particular value on small tables and small ranges of values, which is suitable for the transactional workload. But for analytical workload like the data warehousing and business intelligence (BI) in which the queries will perform full scan for huge amount of data on very large tables such as fact tables, the Columnstore index is better here.
In the Columnstore index, the data is organized as individual columns that form together the index structure. Each column is located in its own highly compressed data container, called a Segment. This segment will contain values from this column only, and for large tables it will be distributed to multiple segments, as the segment can contain only one million rows which is called a Rowgroup. The segment consists of one or multiple pages. The data will be transferred between the memory and the disk as segments.
A columnstore index improves the performance of the data warehousing queries up to 10x the normal execution speed. This performance gain of the Columnstore index is achieved by storing the data in a compressed columnar data format, which offers seven times greater compression ratio than the normal B-Tree structure. Also the Columnstore index uses batch mode execution, where the data is processed in batches, reducing CPU usage. A columnstore index enhances query performance by retrieving the data faster, as the columns needed in the query will only be read instead of searching all the columns for the requested rows. Because of this, less data will be transferred from the disk to the memory and from the memory to the processor cache for processing purpose. These factors will clearly reduce the disk I/O needed to retrieve the data, which will improve the overall query performance.
Columnstore indexes can work with SQL Server table partitioning. But anon-clustered Columnstore index can be created only if the partitioning column is part of the index.
In order to create a Columnstore index, you just need to add the COLUMNSTORE keyword to your index creation statement. And whatever columns you will add to your index, it will be stored as columns in the index.
There are some limitations of the Columnstore index. You can include up to 1024 columns in your index. The Columnstore index can’t be defined as unique index, it can’t be created on a view and you can’t include a sparse column in it. ALTER INDEX statement can’t be used to change the index, you need to drop it and create it again. You can’t use the INCLUDE keyword. Sorting the columns is not allowed in it using the ASC and DESC keywords. And you can’t include a column with a FILESTREAM attribute.
There are some SQL Server data types that can’t be included in the Columnstore index, such as binary , varbinary , ntext , text, , image, varchar(max) , nvarchar(max), uniqueidentifier, rowversion , sql_variant , decimal with precision greater than 18 digits, datetimeoffset with scale greater than 2 , CLR and xml.
On the other hand, the index column size limitation of 900 bytes is not applicable in the Columnstore index.
In SQL Server 2012, you have the option to create non-clustered Columnstore index only. And the table with the Columnstore index can’t be updated. In order to update it you should drop the Columnstore index, perform your INSERT, UPDATE or DELETE statement then rebuild the Columnstore index again.
In SQL Server 2014, the Columnstore index enhanced by eliminating the Read-Only restriction and the table with Columnstore index become updatable. This enhancement achieved by supporting the Clustered Columnstore indexes, which enables the table with Columnstore index to be updatable.
Clustered Columnstore index can be created only in the Enterprise, Developer and evaluation SQL server 2014 editions. The Columnstore Clustered index is the primary storage method for the table, it will store all the table’s data including all the table’s columns.
While the Read-Only Non-Clustered Columnstore index can be combined with other indexes in your table, creating Clustered Columnstore index will prevent you from defining any other indexes in your table.
Using the Clustered Columnstore index, you will be able to update the entire table without dropping the index. To achieve this, Clustered Columnstore index uses an intermediate storage location called deltastore that keeps the data until it is compressed and moved to the Columnstore segment.
If you manage to INSERT a new row, the value will be stored in the deltastore until it reaches the minimum rowgroup size, then it will be compressed and moved to the Columnstore segment.
If you try to DELETE a row, this row will be deleted from the deltastore storage, but it will be marked as deleted on the Columnstore index segment until the index is rebuilt.
When performing an UPDATE operation on a row, the row will be deleted from the deltastore storage, and marked as deleted in the Columnstore segment and the new value will be inserted to the deltastore.
When you rebuild a Columnstore index, SQL Server will delete all rows marked as deleted from the segments, the data stored in the deltastore will be merged with the segments and the segment will be compressed.
Let’s have a small demo to show how we could take benefits from the Columnstore index.
We will start with creating the FactFinance table in our SQLShackDemo test database with the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
USE [SQLShackDemo] GO CREATE TABLE [dbo].[FactFinance]( [FinanceKey] [int] NOT NULL, [DateKey] [int] NOT NULL, [OrganizationKey] [int] NOT NULL, [DepartmentGroupKey] [int] NOT NULL, [ScenarioKey] [int] NOT NULL, [AccountKey] [int] NOT NULL, [Amount] [float] NOT NULL, [Date] [datetime] NULL ) ON [PRIMARY] GO |
Once the table created, we will create a Clustered index on that table as follows:
|
1 2 3 4 5 |
CREATE CLUSTERED INDEX [IX_FactFinance_FinanceKey_DateKey] ON [dbo].[FactFinance] ( [FinanceKey],[DateKey]) GO |
Now the table is ready. If we run the below simple SELECT statement on the created table and check its execution plan generated using the APEXSQL PLAN application, a Clustered Index Scan operator will be resulted:
|
1 2 3 4 5 6 7 |
SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] |

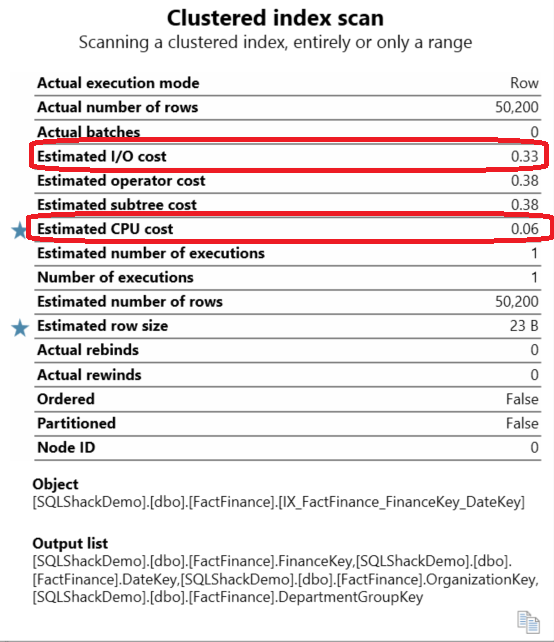
Let’s check the Clustered Index Scan operator, more closely, to get the Estimated I/O Cost which equals to 0.33 and the Estimated CPU Cost which equals to 0.06, in order to compare it with the new values later:
Now we will create the ColumnStore Non-Clustered index simply using the normal CREATE NONCLUSTERED INDEX statement with specifying the COLUMNSTORE keyword:
|
1 2 3 4 5 6 |
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey] ON [FactFinance] ([FinanceKey],[DateKey],[OrganizationKey],[DepartmentGroupKey]) GO |
If we execute the same SELECT statement below and check execution plan using the APEXSQL PLAN application for that query:
|
1 2 3 4 5 6 7 |
SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] |
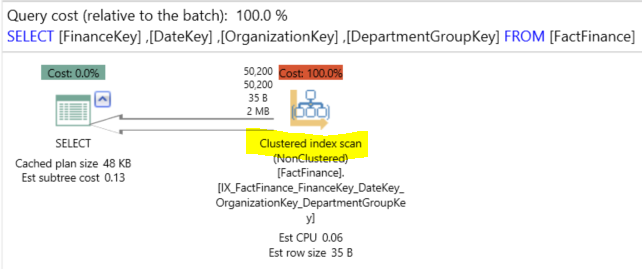
The ColumnStore Index scan operator will be shown here. Nothing till now tell us that there is any enhancement. Let’s again go deeply with that operator to check the same parameters taken before as follows:

As you can see, the Estimated I/O Cost decreased clearly from 0.33 when using the row-store standard index to 0.07 in the Columnstore index case. This is because the SQL engine retrieves only the requested columns from the table without wasting I/O and Memory resources to retrieve the data.
The Estimated CPU time still the same, as the query is retrieving small amount of data and no batch execution required here.
The I/O enhancement is shown clearly from the previous numbers. We can also check the overall performance enhancement by comparing the two cases together; the first one using the standard Clustered index and the second one using the Columnstore index, enabling the I/O statistics also to check the number of I/O hits performed by these queries as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SET STATISTICS IO ON GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index (IX_FactFinance_FinanceKey_DateKey)) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index(IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey)) |
As you can see when comparing the execution plan for the two queries using the APEXSQL PLAN application, using the Columnstore index is 3 times better than using the standard Clustered index for this simple query. Expect an improvement of up to 10 times for queries that process a huge amount of data.

Also you can find the same result when comparing the number of logical reads performed by each query. It is clear also that the number of reads using the standard Clustered index is 4 times the number of reads using the Columnstore index.

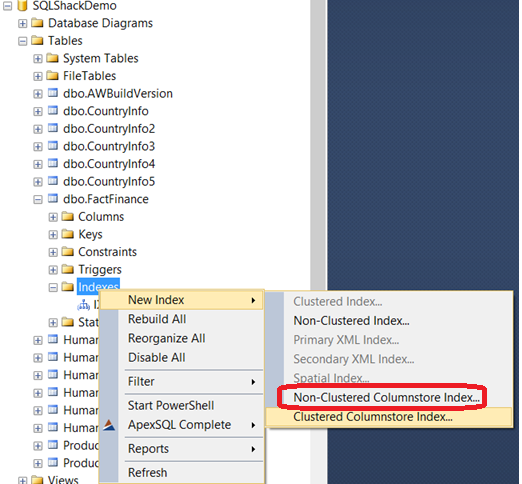
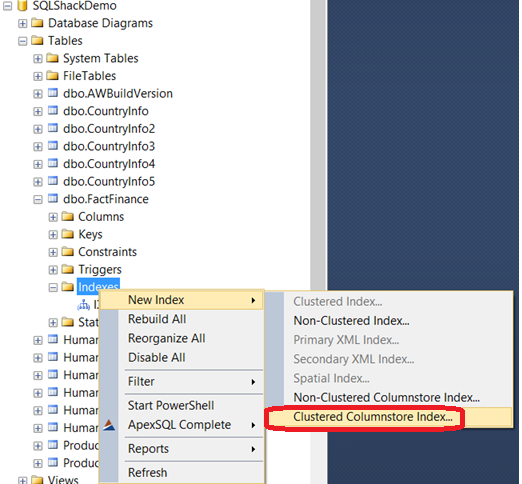
You can also create the Columnstore index using SQL Server Management Studio by expanding the table in the object explorer and right-click on the Indexes -> New Index ->Non-Clustered Columnstore Index as below:
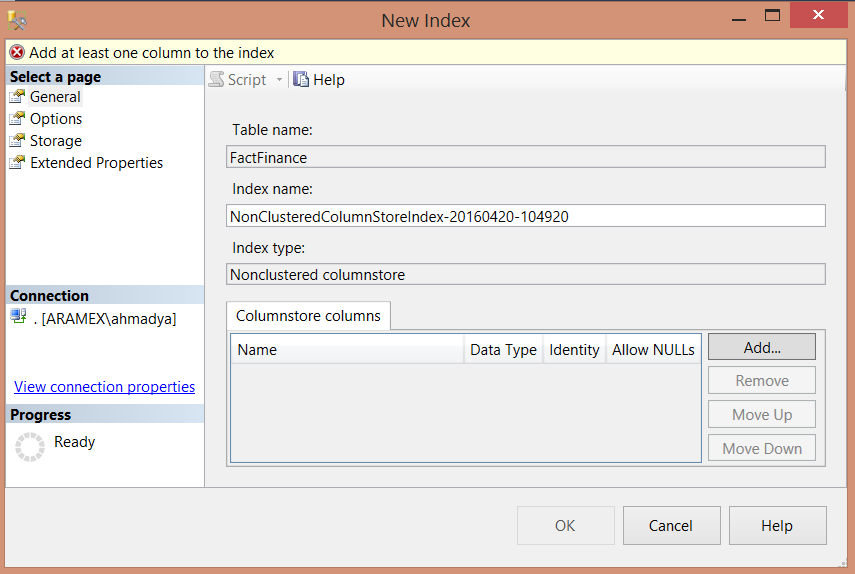
Just like any normal Non-Clustered index creation, choose the columns that will be used in that index, with the limitations that no choice for the ASC or DESC sort of that columns and no INCLUDE option can be used here:
As I am using here SQL Server 2014 Enterprise Edition, I am able to create Clustered Columnstore index as follows:
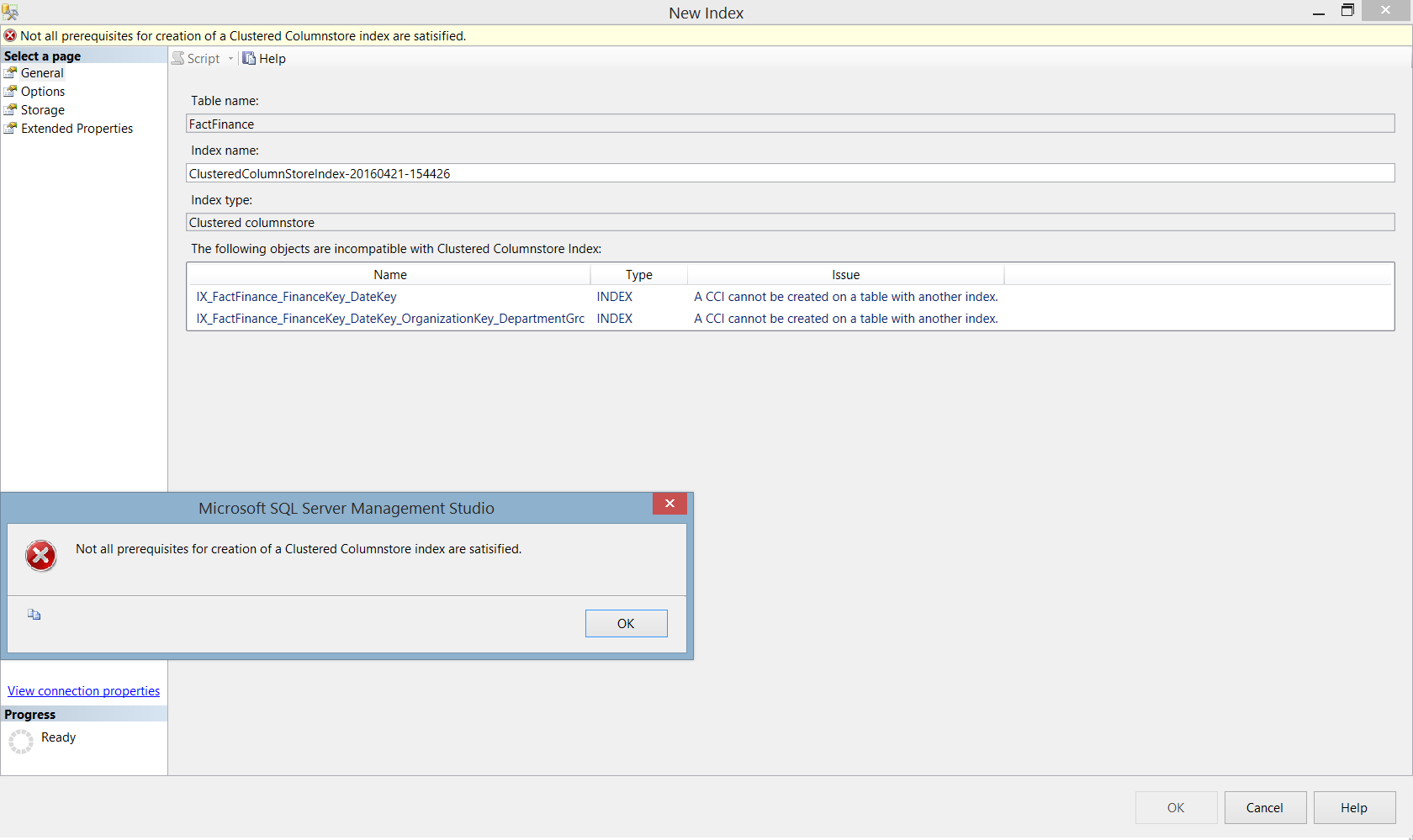
If we try to create a Clustered Columnstore index in our table, it will fail as we already have other indexes on that table, and as we mentioned previously, the Clustered Columnstore index can’t be combined with other indexes in the same table:
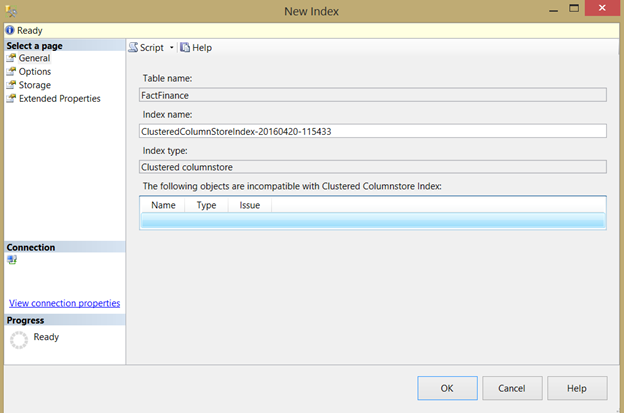
Assume that you don’t have any index in your table, you will be able to create the Clustered Columnstore index successfully, without having the option to choose the included columns, as all the columns will be included in that index, which will be the main data store for that table:
Conclusion
A Columnstore index is a useful SQL Server performance enhancement option that reduces the IO cost of data warehouse and BI workload queries, by storing the data as column-store compressed fashion and processing the data in batches. As an experienced DBA, you need to make sure that you will benefit from it and it is suitable for your environment. A SQL Server Columnstore index can slow down your queries when there is no join, filtering, or aggregation resulting huge amount of data that will not fit the available memory and must split to the disk. Try many scenarios in your test environment then decide if you can use it in your production environment or not.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021