
Introduction
In the previous article Azure Data Explorer and the Kusto Query Language, we saw how the Microsoft Azure Data Explorer works, and we learned about the Kusto query language (KQL). We’ll build on this here in part two, we’ll learn more about KQL, and we’ll use KQL to solve a real-world data problem.
The problem we will solve
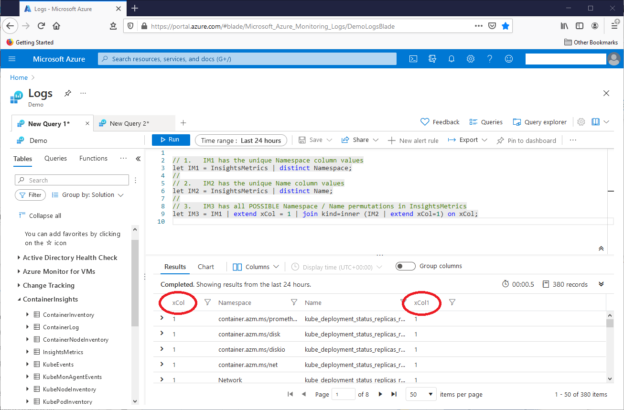
In the InsightsMetrics table, we’ll focus on the Namespace and Name columns. This query will return the number of unique Namespace, Name combinations from that table:
InsightsMetrics | distinct Namespace, Name | count
The query shows that the table has forty combinations, as seen in this screenshot:
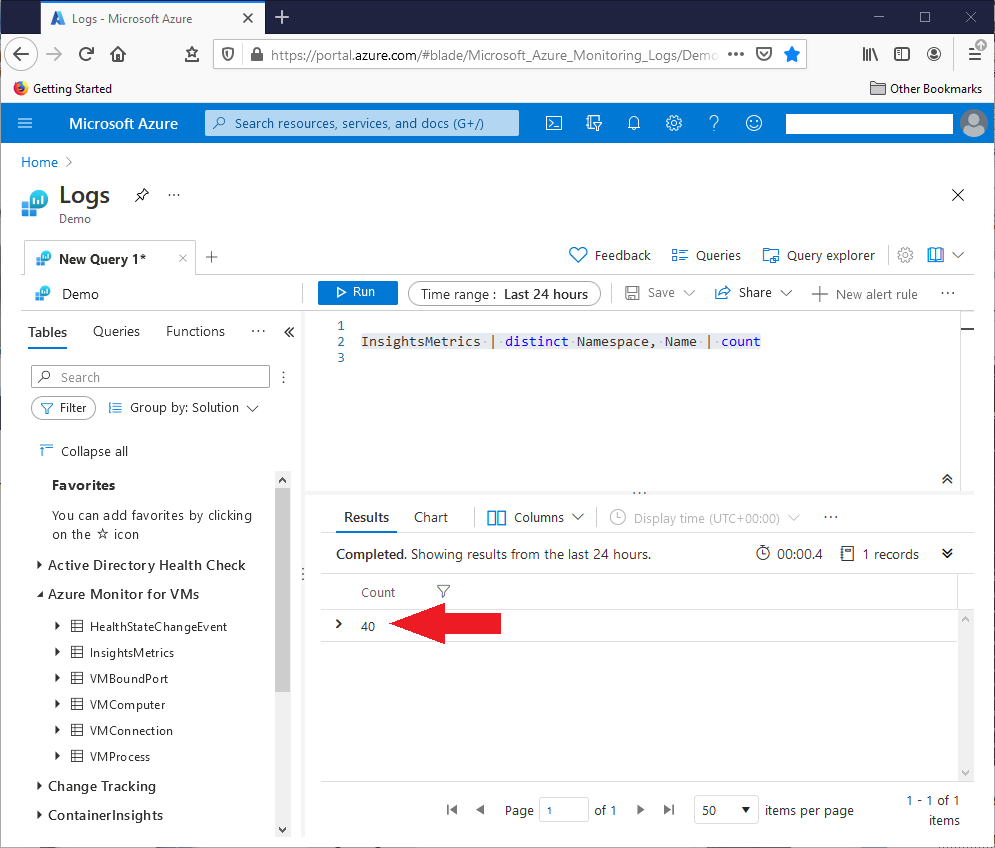
This query will show some of those unique values:
InsightsMetrics | distinct Namespace, Name | limit 8
This screenshot shows some of the combinations returned by that query:
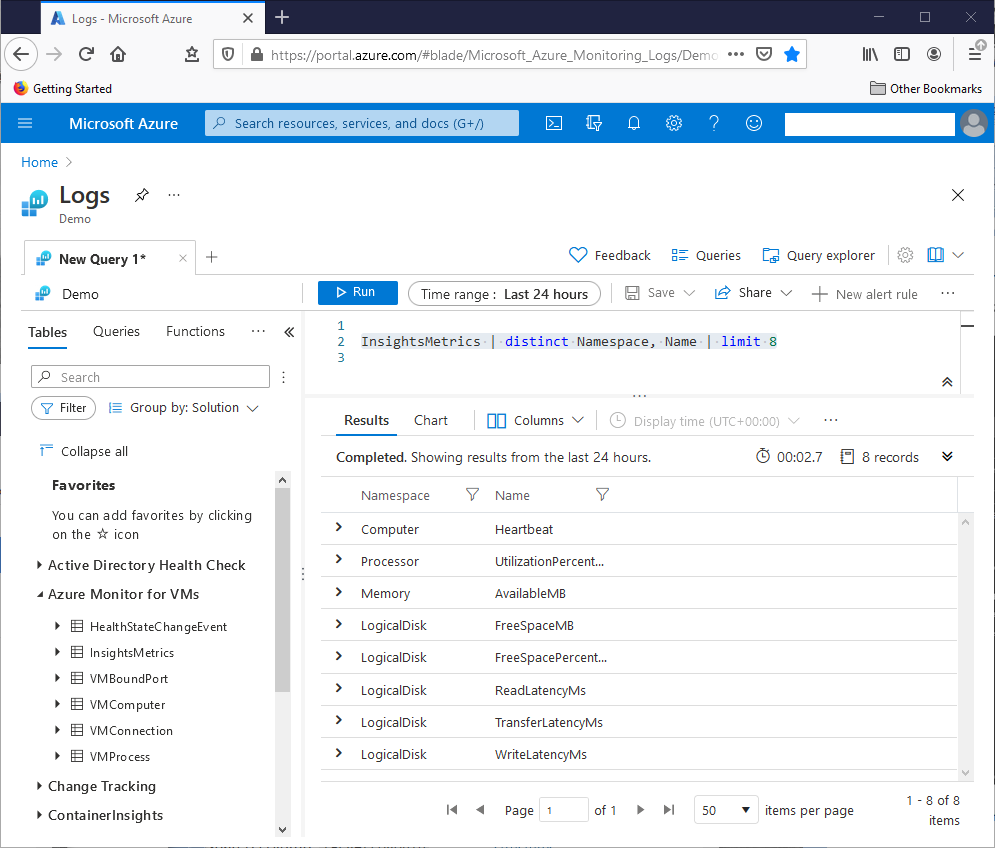
The next query counts the number of unique Namespace values, and the number of unique Name values:
let NamespaceCount = InsightsMetrics | distinct Namespace | count;
let NameCount = InsightsMetrics | distinct Name | count;
print strcat(‘NamespaceCount = ‘, toscalar(NamespaceCount), ‘ NameCount = ‘, toscalar(NameCount))
Using let operators, the query places the column count values in separate variables, and then outputs them with the print operator. The query needs the toscalar function because the count operators in the let operators essentially returned table-format data. The print operator can’t handle this data format, but it can handle scalar-format data. The toscalar function converts the data to the correct format.
This screenshot shows the query results:

The query shows that the InsightsMetric Namespace column has ten unique Namespace values, and the Name column has 38 unique Name values. This means that for these two columns, the table can have 380 unique combinations of these values. Since the table only uses 40 of these column value combinations, it does not use 340 of the possible combinations. We’ll use KQL to build a list of these unused combinations.
The Solution
This KQL query returns the rows that solve the problem:
// 1. IM1 has the unique Namespace column values
let IM1 = InsightsMetrics | distinct Namespace;
//
// 2. IM2 has the unique Name column values
let IM2 = InsightsMetrics | distinct Name;
//
// 3. IM3 has all POSSIBLE Namespace / Name permutations in InsightsMetrics
let IM3 = IM1 | extend xCol = 1 | join kind=inner (IM2 | extend xCol=1) on xCol
| project-keep Namespace, Name | order by Namespace asc, Name asc;
//
// 4. IM4 has all EXISTING Namespace / Name permutations in InsightsMetrics
let IM4 = InsightsMetrics | distinct Namespace, Name;
//
// 5. IM5 has the unused Namespace / Name combinations, not found in InsightsMetrics
let IM5 = IM3 | join kind=leftanti IM4 on Namespace, Name;
//
// 6. Output the unused Namespace / Name combinations
IM5 | order by Namespace asc, Name asc
As we step through it, we’ll learn about Kusto query language features that expand the power and flexibility of Kusto itself.
The first two operations place all unique Namespace, and all unique Name column values, in separate variables. Operation three builds a row set list of all possible Namespace column / Name column values, and places this list in variable IM3. To make this happen, operation 3 uses a cross join. In an earlier SQL Shack article, Esat Erkec explained that a cross join ” . . . is used to generate a paired combination of each row in the first table with each row of the second table.” A cross join would solve this part of the problem. Unfortunately, the Kusto query language does not directly support cross joins. However, we can manually build one, as seen in operation 3. We’ll rewrite operation 3 for clarity:
// A. Assign the query output to IM3
let IM3 = IM1
// B. Add a new ‘dummy’ column called xCol to IM1
| extend xCol = 1
// C. Add a new ‘dummy’ column called xCol
// to IM2, and join IM2 to IM1 on xCol
| join kind=inner (IM2 | extend xCol =1) on xCol
// D. Keep the Namespace and Name columns in the
// final result set, and throw away the xCol columns
| project-keep Namespace, Name
// E. Sort the result set
| order by Namespace asc, Name asc;
In this separate KQL code, operation A assigns the final query output to variable IM3, and starts with the IM1 result set. The “parent” query placed the unique Namespace column values into variable IM1. Therefore, we can use IM1 as a result set table. Query operation B extends, or adds, a new xCol column to IM1. This column has values of 1 in all rows. The Kusto query cross join happens at operation C. The operation nested in the parentheses executes first, and it extends an xCol column to IM2 – the variable from the parent query with the unique Name column values.
IM2 | extend xCol = 1
Stepping outside of the parentheses, query operation C then joins IM2 to IM1 on their common xCol columns. This join, on these table columns, becomes the cross join we need. This screenshot shows the result set of the main query, up to and including the cross join operation:
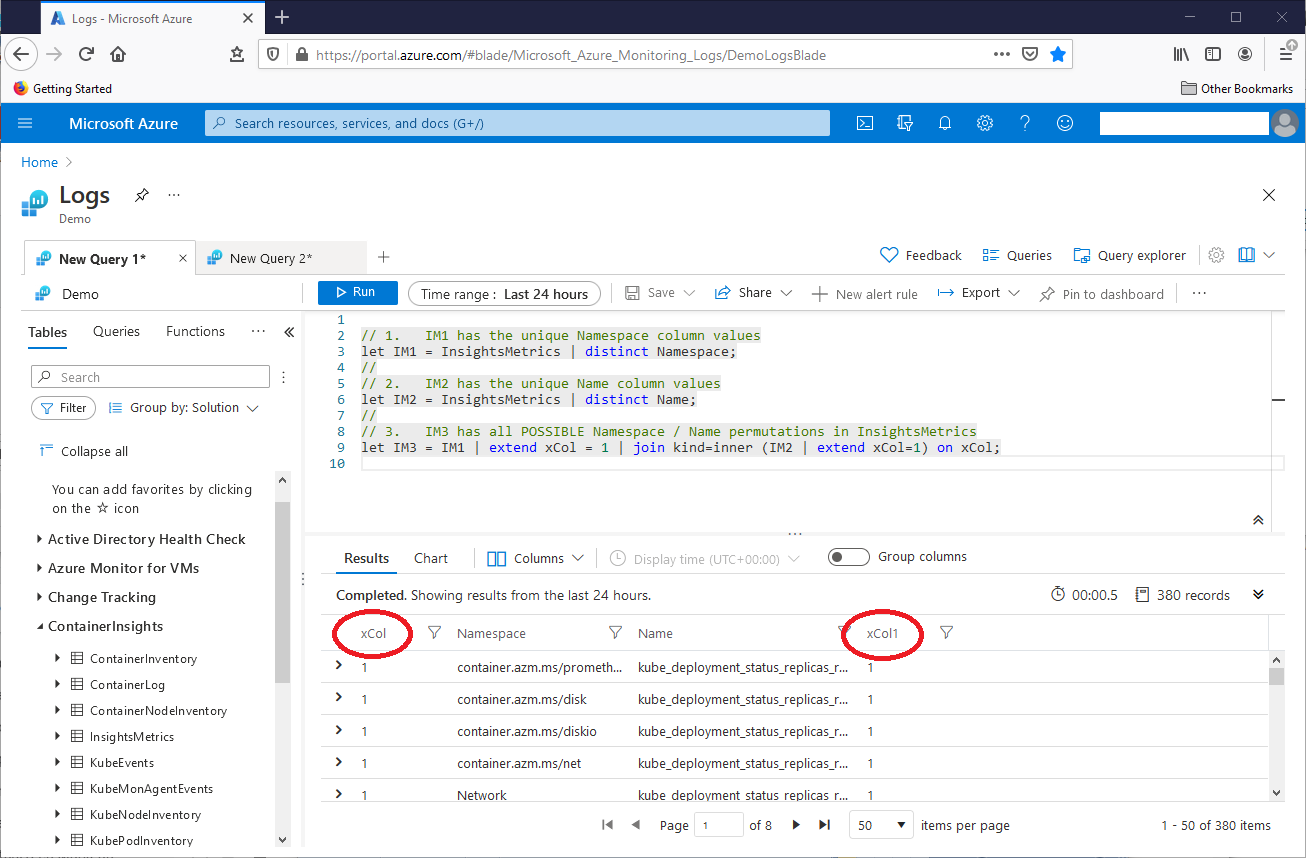
Although operation 3 added dummy column xCol to IM1, and dummy column xCol to IM2, the result set shows an xCol column, and an xCol1 column. If KQL joins tables with matching column pairs with the same name, the join will keep the names for both columns, but it will add a number to the column name from the right-hand table. In this case, the Kusto query language changed the original IM2 xCol column name to xCol1.
Query operation D keeps the Namespace and Name columns that we want, and query operation E sorts the result set that will become the IM3 variable value.
Back in the parent query, operation 4 guarantees a Namespace and Name result set that has only unique rows. Operation 5 uses the KQL leftanti join type, as seen here:
let IM5 = IM3 | join kind=leftanti IM4 on Namespace, Name;
A leftanti join returns all left-hand table rows that do not exist in the right-hand table. The Kusto query language leftanti join seen here returns all IM3-variable rows that do not exist in the IM4-variable rows. The IM3 variable has all possible Namespace / Name column combinations that InsightsMetrics could have. The IM4 variable has only the existing Namespace / Name column combinations found in InsightsMetrics. In effect, this leftanti join subtracts the existing Namespace / Name column combinations (IM4) from the possible column combinations (IM3). This technique returns exactly what we need. Note that if we rewrite the query a little, we could use a rightanti join instead.
In the main query, operation 6 returns the finished result set, sorted by Namespace and Name.
Verify the solution
To solve the original problem, we built a KQL query that seems logical, and it returns a result set that makes sense. We can use the Kusto query language to verify the solution, with this query:
// 1. IM1 has the unique Namespace column values
let IM1 = InsightsMetrics | distinct Namespace;
//
// 2. IM2 has the unique Name column values
let IM2 = InsightsMetrics | distinct Name;
//
// 3. IM3 has all POSSIBLE Namespace / Name permutations in InsightsMetrics
let IM3 = IM1 | extend xCol = 1 | join kind=inner (IM2 | extend xCol=1) on xCol
| project-keep Namespace, Name | order by Namespace asc, Name asc;
//
// 4. IM4 has all EXISTING Namespace / Name permutations in InsightsMetrics
let IM4 = InsightsMetrics | distinct Namespace, Name;
//
// 5. IM5 has the unused Namespace / Name combinations, not found in InsightsMetrics
let IM5 = IM3 | join kind=leftanti IM4 on Namespace, Name;
//
// 6. Prove that IM5 has the unused Namespace / Name permutations
//
// First, show that IM4 does not contain IM5
//
// IM4 = existing Namespace / Name permutations in InsightsMetrics
// IM5 = all unused Namespace / Name combinations
// IM6 = IM4 rows that exist in IM5
//
// 7. The leftsemi join returns all left-side table (IM5) rows found
// in the right-side table (IM4)
//
let IM6 = IM5 | join kind=leftsemi IM4 on Namespace, Name;
//
// 8. IM6Count = count of IM6 rows
let IMCount = IM6 | order by Namespace asc, Name asc | count;
//
// 9. Built variables holding output message strings
let printString1 = ‘NO Namespace / Name row combinations used in InsightsMetrics exist in the unused Namespace /
Name combinations’;
let printString2 = ‘Namespace / Name row combinations used in InsightsMetrics exist in the unused Namespace / Name
combinations’;
//
// 10. Pick one of the message strings, and print it
let printedOutput = iff(toscalar(IMCount) == 0, printString1, printString2);
print printedOutput;
In this query, the first five operations clone the first five operations of the solution query in the article section just above. In this second query, the comments in operation 6 list the relevant IM variables, as a reference. For operation 7, IM5 has the row set of unused Namespace / Name combinations that we believe will solve the original problem. IM4 has the row set of all possible Namespace / Name combination rows, from the InsightsMetrics table. As seen here, operation 7 uses a Kusto query language leftsemi join to return all left-side table (IM5) rows found in the right-side table (IM4):
let IM6 = IM5 | join kind=leftsemi IM4 on Namespace, Name;
Here, the join returns all rows from IM5, the left-hand table with unused rows, that it finds in the right-hand table (IM4), which itself has data found in the original InsightsMetrics table. If the first five query operations worked correctly, the operation 7 query should return zero rows, and IM6 should have a zero-row result set. Note here also that if we rewrite the query a little, we could use a rightsemi join instead.
Operation 8 counts the rows in IM6, placing this value in variable IM6Count. Operation 9 builds message string variables. Operation 10 tests and outputs the IM6Count value, as seen in this screenshot:
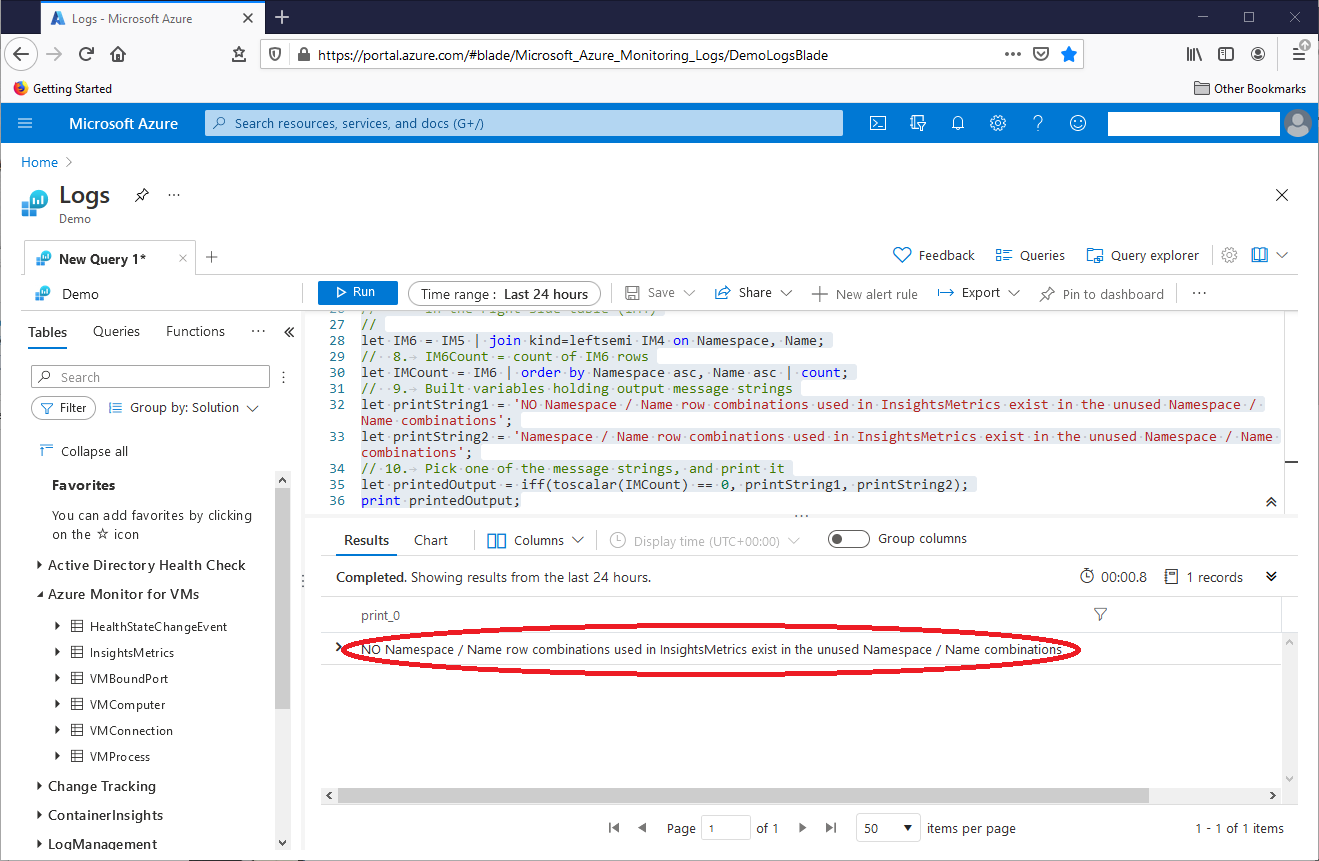
The output message shows that the original query operated correctly.
Kusto Join Syntax
Kusto handles arrays, JSON, and more. We probably could have used these features to solve the problem spotlighted above. Instead, the solution kept all the data in table variables, at an abstract level. It used table-level joins that operated on those variables. We did have to think about which columns to use to build the joins, but past that, we could almost completely avoid directly touching the data itself. Part one of this article featured this query that joined two tables:
// 1. Get 20K InsightsMetrics rows, and keep
// only the Computer and Origin columns
InsightsMetrics | limit 20000
// 2. Inner join to the VMConnection table, on
// the Computer column, and use 20K rows
| join kind=inner ContainerInventory on Computer
| limit 20000
// 3. Return a specific set of columns
// in a distinct row set
| project-keep Computer, Origin, ContainerHostname
| distinct Computer, Origin, ContainerHostname
Here, the join in the second operation joins the tables on the Computer column, as shown here:
| join kind=inner ContainerInventory on Computer
We can rewrite the second operation join this way:
| join kind=inner ContainerInventory on $left.Computer == $right.Computer
This screenshot shows the query in action:
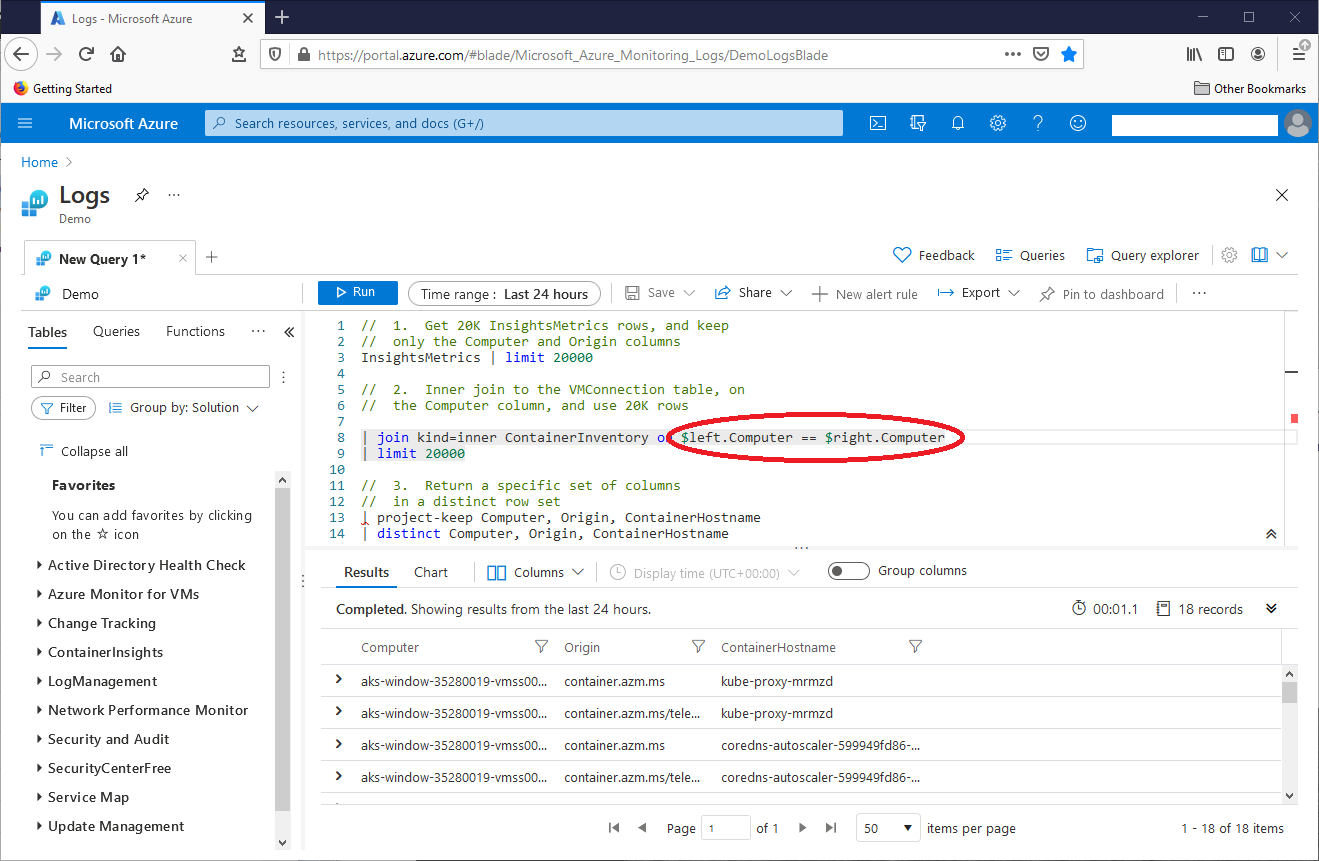
Here, the join designates the InsightsMetrics table as the “left” table for the join, and the ContainerInventory table as the “right” table. The tables join on the Computer column. This technique works for more than one column. In the first query seen in this solution section of this article, operation five joined table variables IM3 and IM4 on the Namespace and Name columns, as shown here:
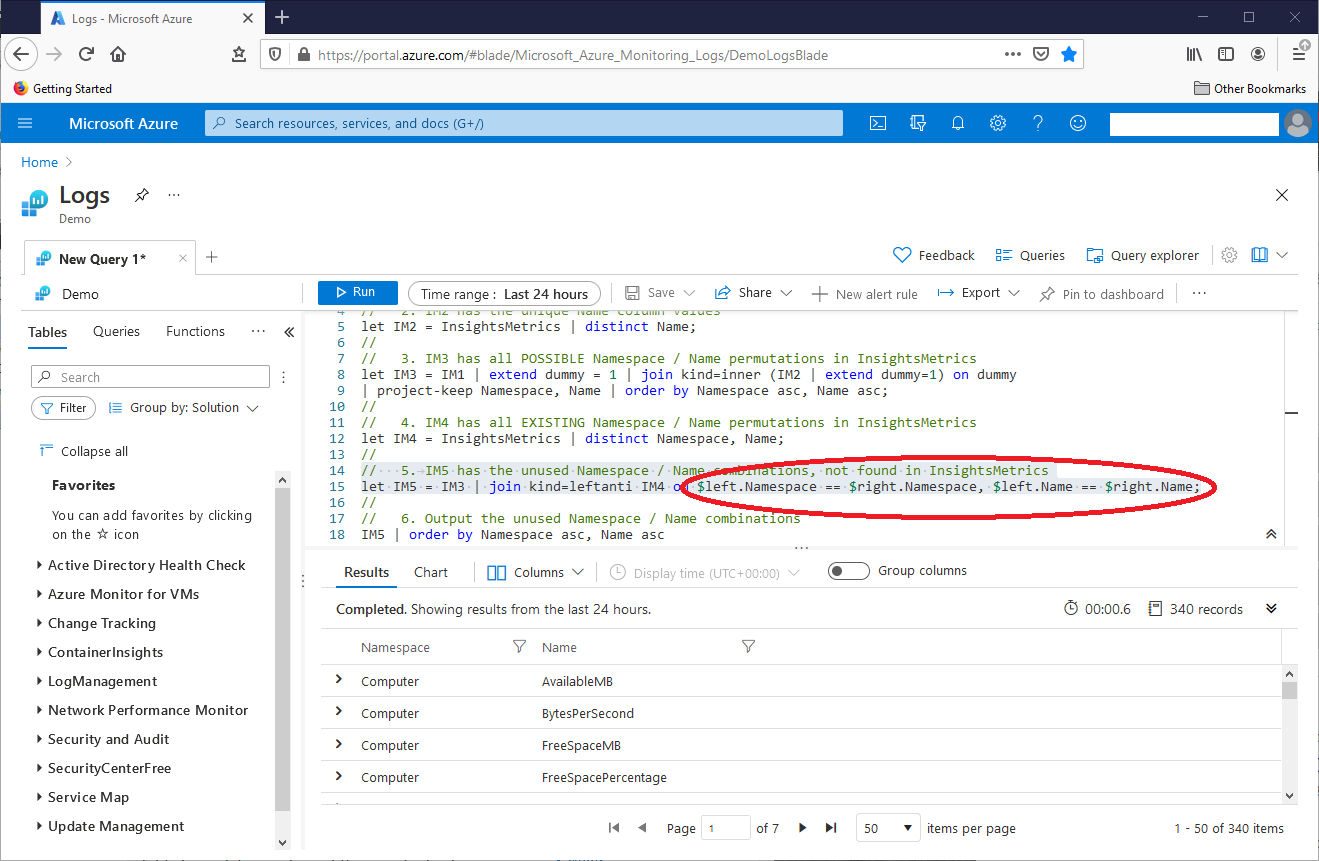
// 5. IM5 has the unused Namespace / Name combinations, not found in InsightsMetrics
let IM5 = IM3 | join kind=leftanti IM4 on Namespace, Name;
// 5. IM5 has the unused Namespace / Name combinations, not found in InsightsMetrics
// let IM5 = IM3 | join kind=leftanti IM4 on $left.Namespace == $right.Namespace,
$left.Name == $right.Name;
This screenshot shows that the new join syntax worked:
Conclusion
It can become a challenge to extract useful information from data masses with billions of rows. As we saw here, Kusto offers a clean, effective way to handle those data masses.

See more about Frank at LinkedIn.
Remove the non-standard characters from this address: fb} <s.author@gmail.com to reach him by email.
- Lever the TSQL MAX/MIN/IIF functions for Pinpoint Row Pivots - May 16, 2022
- Use Kusto Query Language to solve a data problem - July 5, 2021
- Azure Data Explorer and the Kusto Query Language - June 21, 2021