
Introduction
Microsoft Azure Data Explorer handles and analyzes petabyte-masses of structured and unstructured data. In Azure Data Explorer, users lever the Kusto query language (KQL) for their data analysis work. This article, part one of a two-part article, will introduce KQL. This article will also describe a free Microsoft online interactive resource that allows for hands-on Kusto exploration and learning. Part two will describe more aspects of KQL, and use those aspects to solve a real-world data problem.
The Azure Data Explorer Learning Environment
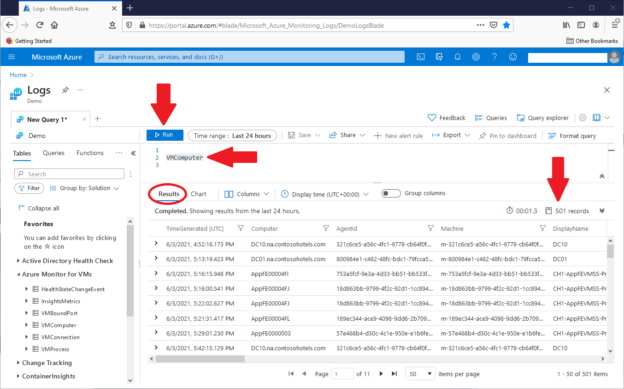
We’ll use a free Azure Data Explorer (ADE) resource that requires only a Hotmail account. It won’t need an Azure subscription. Log in if necessary, and go to the free Log Analytics resource here. This screenshot shows the Data Explorer:
In the right-hand Portal settings section, pick the circled Azure theme for the environment. On the left side, expand Azure Monitor for VMs in the Tables tab, circled on the right side. Although ADE stores data in tables, it does not have the strict database/table structure of SQL Server, for example. Instead, ADE groups tables in loose “collections” of tables. This article will first focus on the Azure Monitor for VMs collection.
The Azure Data Explorer
In the Azure Data Explorer tool, we can open different query tabs. In each tab, we can build and execute Kusto queries, as shown in this screenshot:
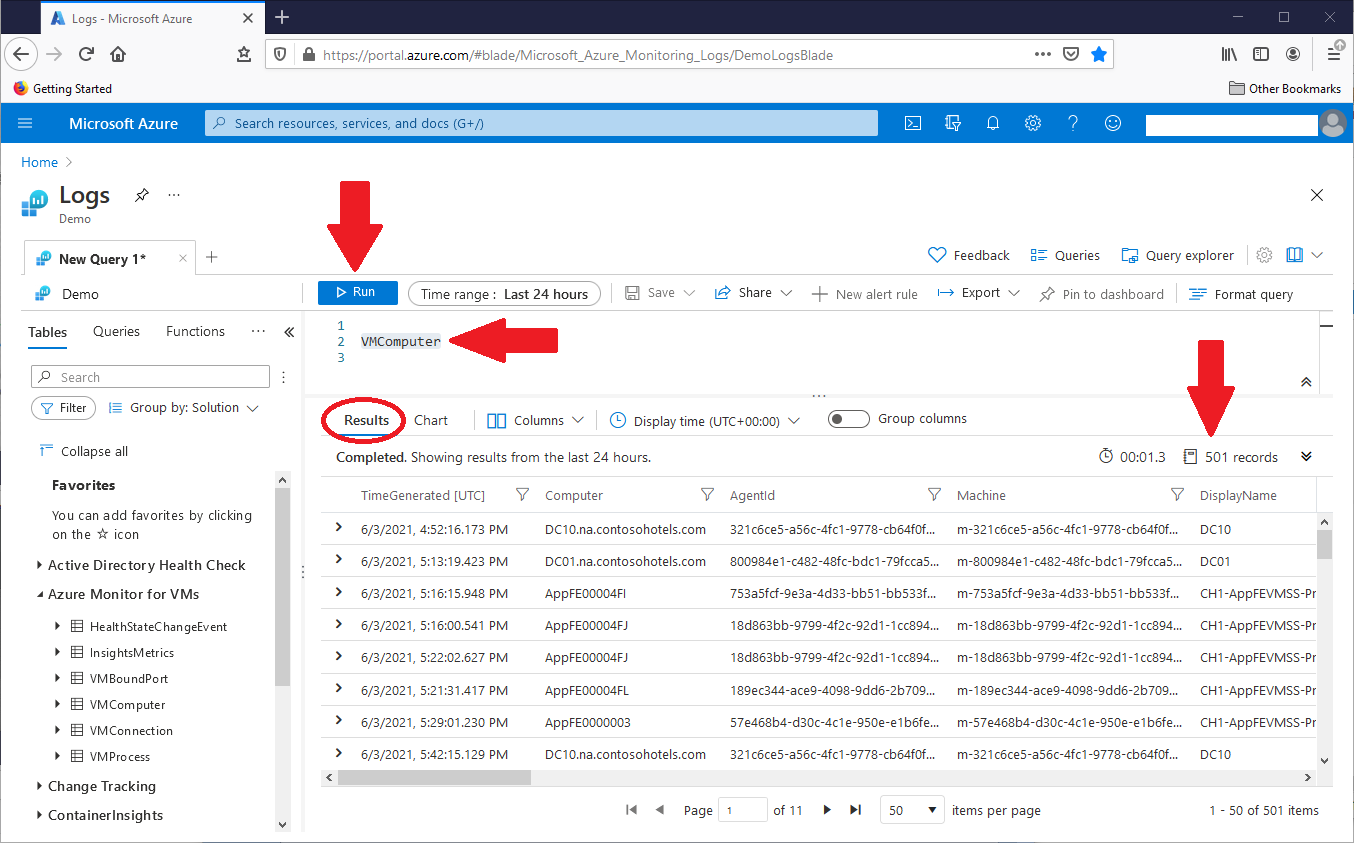
For this and the rest of the screenshots, I closed the right-hand Portal settings box to open more real estate. The screenshot shows the query in the query box, and the result set below. For this first query, type a table name VMComputer highlighted in that query box and click Run. We could also highlight the query text to run, and hit Ctl‑<Enter> to run it. The statement returned 501 records in 1.3 seconds, and we can scroll through the result set rows and columns. With this basic knowledge of the ADE tool mechanics, we can explore the Kusto language. In KQL queries, certainly the ones we’ll see in this article, we’ll start with raw data, and then pass that data through one or more individual operations that gradually bring that raw data to the solution state we need. See the Kusto language documentation from Microsoft here.
Kusto Query Language Basics
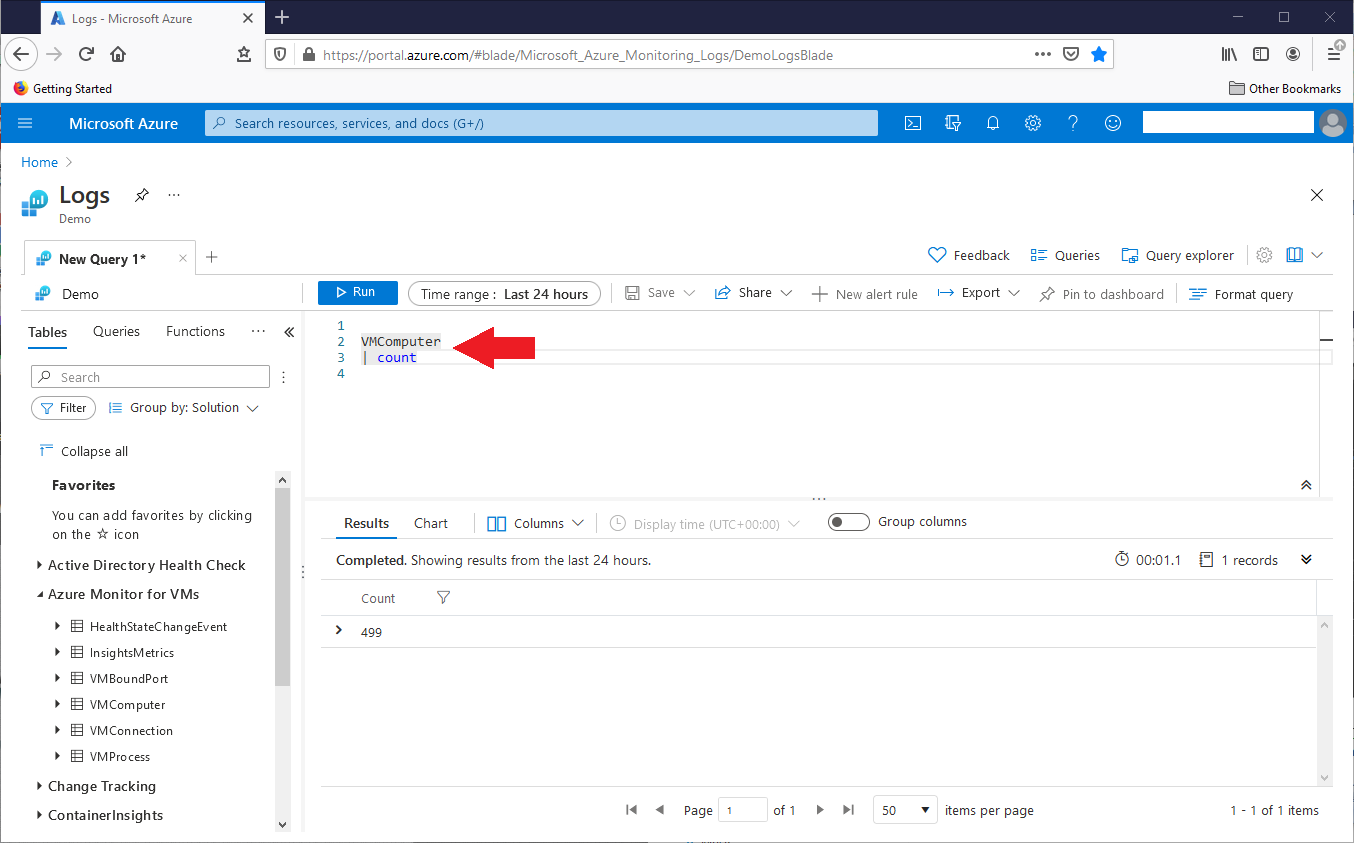
In the above query, ADE reported the VMComputer table record count. However, we can also use the count operator. The below query returns the VMComputer table record count, as shown in this screenshot:
VMComputer | count
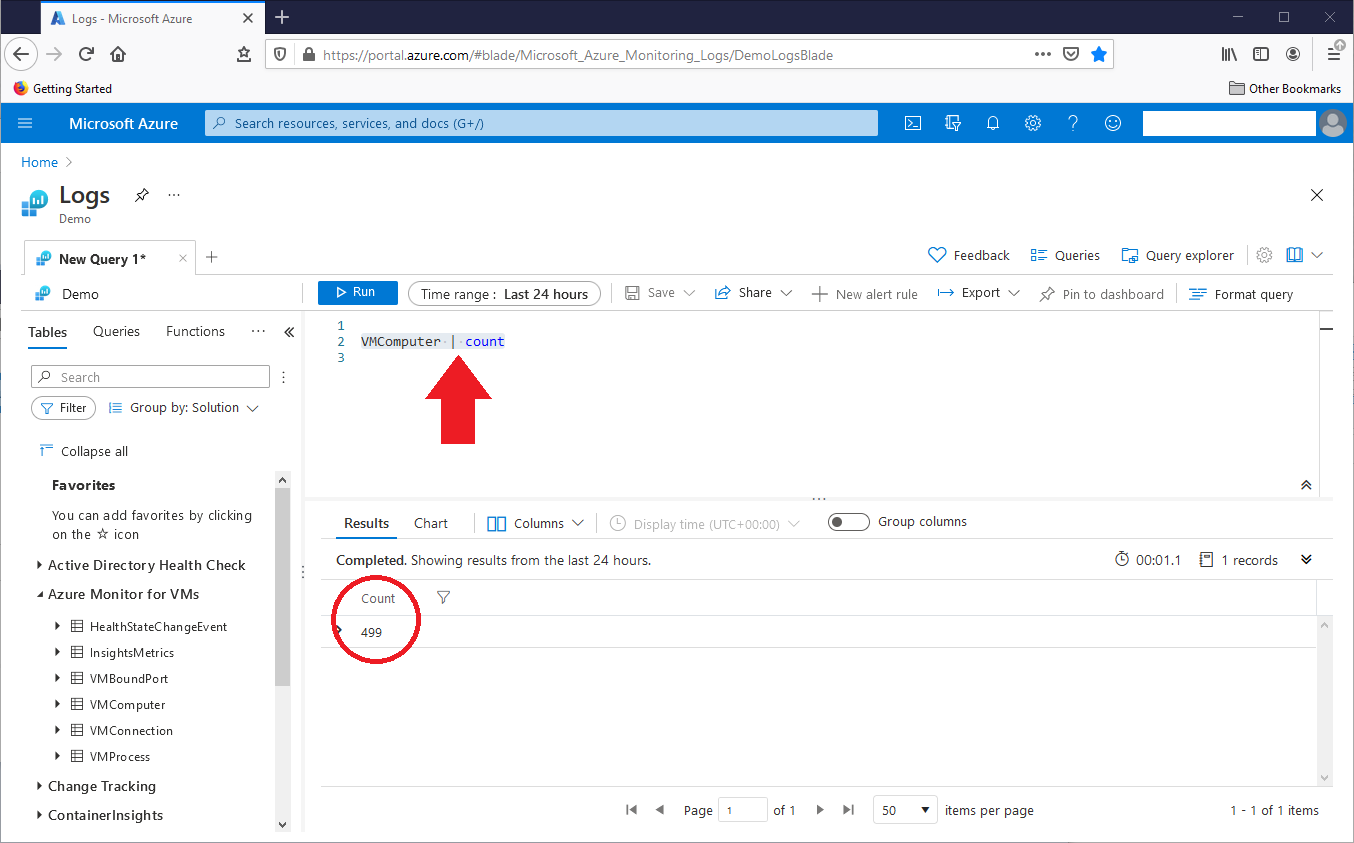
Data in the Log Analytics resource can change over time, so a specific query, or a group of related queries, might return different result sets as we work with that data. To make queries easier to read, we can place operations on separate lines. This query is valid, as shown in this screenshot:
VMComputer
| count
In these queries, the pipe symbol ” | ” separates the operations as they flow from left to right, and top to bottom. Note that KQL is case-sensitive for everything – table names, table column names, operators, functions, etc. Use double forward slashes // for comments.
KQL limit operator
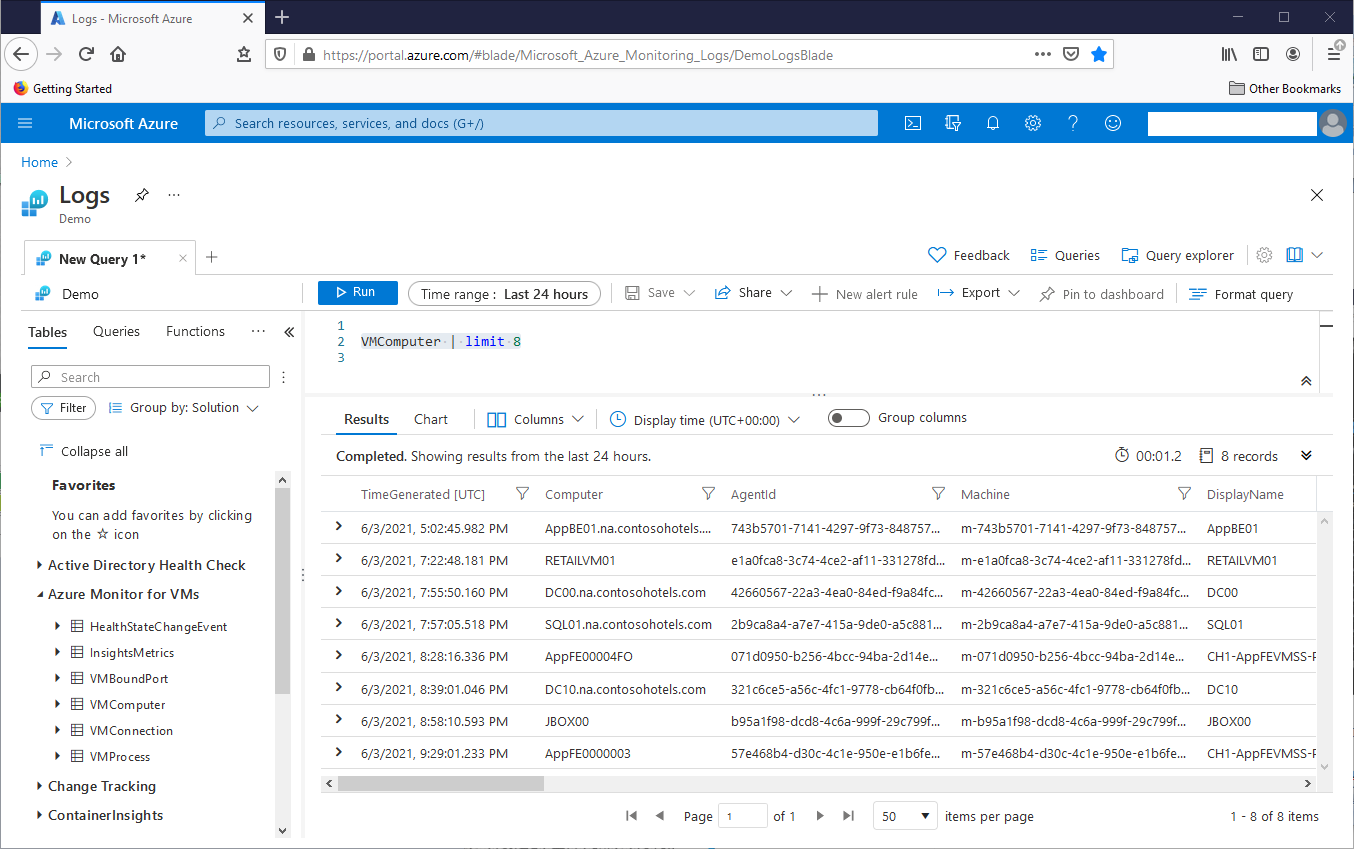
KQL can handle tables with many billions of rows. As we work with that data, the limit n operator returns a random subset n of those rows. This query returns eight rows from VMComputer, randomly chosen by KQL. This screenshot shows the result set:
VMComputer | limit 8
KQL project operator
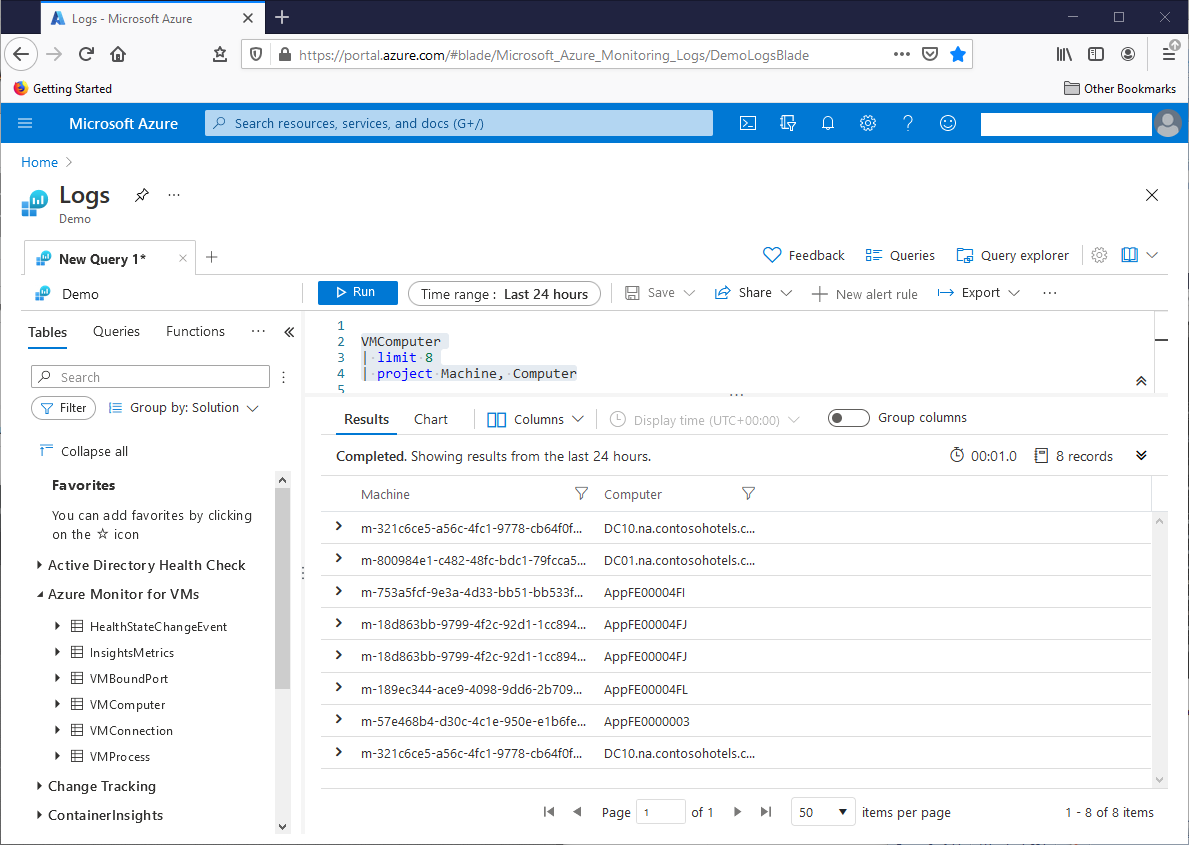
If we scroll the raw VMComputer result sets to the right, we’ll see 56 columns. We can use the project operator to return a specific subset of those columns, by name, in the result set. In this query, the project operator returns the Machine and Computer columns of eight VMComputer table rows, randomly chosen by the limit operator. This screenshot shows the output:
VMComputer
| limit 8
| project Machine, Computer
Since KQL flows data from operation to operation, we can rewrite the query like this:
VMComputer
| project Machine, Computer
| limit 8
This query will return a result set very similar to the query above. However, it first builds a Machine and Computer column subset of all 499 VMComputer table rows, and then returns eight rows from that subset. In an overall way, this involves 1014 operations, as seen here:
(499 * 2) + (8 * 2) = 1014
The earlier Kusto query first returns eight table rows, and then returns the Machine and Computer columns from those rows. That query involves 16 operations in an overall way, as seen here:
(8 * 2) = 16
This distinction between these queries leads to a key insight. Try to build KQL queries that reduce data volumes as much as possible, as soon as possible. The VMComputer table is small, so the difference might not become apparent. However, for tables with many millions, billions, or more rows, this approach can boost query speeds and reduce ADE resource demands.
KQL extend operator
We can use the Kusto query language extend operator to create a new column in a result set. Two below InsightsMetrics table columns have string data.
Computer
Namespace
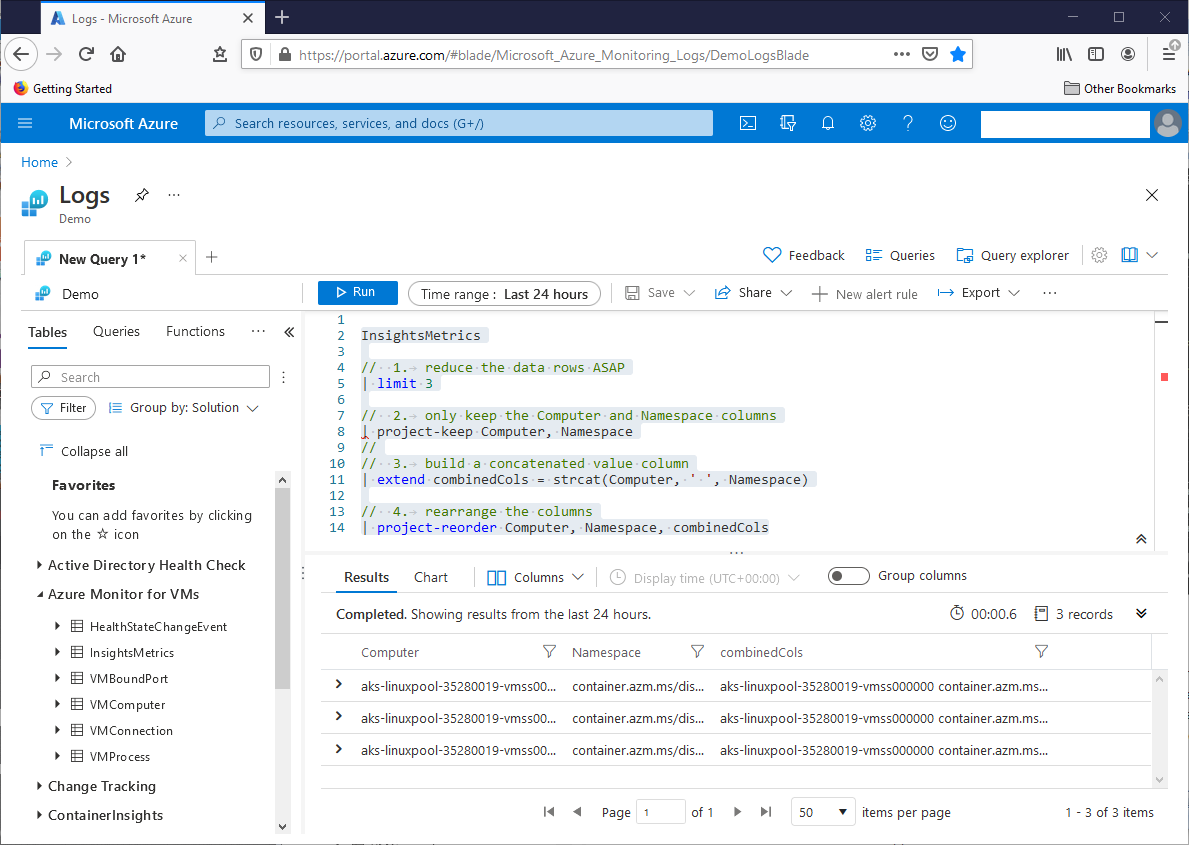
The extend operator, combined with the strcat function, will concatenate these values into a new column, for eight randomly chosen rows, as seen in this query:
InsightsMetrics
//
// 1. reduce the data rows ASAP
| limit 3
// 2. only keep the Computer and Namespace columns
| project-keep Computer, Namespace
// 3. build a concatenated value column
| extend combinedCols = strcat(Computer, ‘ ‘, Namespace)
// 4. rearrange the columns
| project-reorder Computer, Namespace, combinedCols
The InsightsMetrics table has more than one million rows, so the first operation reduced the query workload in a big way, from one million rows to three. The second operation concatenates the Computer and Namespace columns, placing the new values in the new combinedCols column. This operation calls the strcat function with the column names, and space, as parameters. The third operation uses project-reorder, a variation of the project operator, to rearrange the final result-set columns. This screenshot shows the result set:
KQL join operator
In the first screenshot above, the Azure Monitor for VMs collection has six tables. We might want to build a query that pulls data from different tables in that collection. More generally, we might want to look in tables, located in different collections, for query data. The Kusto query language offers different join operators that bring different Kusto tables together in a single query. This query shows how to do it:
// 1. Get 20K InsightsMetrics rows, and keep
// only the Computer and Origin columns
InsightsMetrics | limit 20000
// 2. Inner join to the VMConnection table, on
// the Computer column, and use 20K rows
| join kind=inner ContainerInventory on Computer
| limit 20000
// 3. Return a specific set of columns
// in a distinct row set
| project-keep Computer, Origin, ContainerHostname
| distinct Computer, Origin, ContainerHostname
In the second operation, the query inner joins rows from the InsightsMetrics table, in the Azure Monitor for VMs collection, to the ContainerInventory table in the ContainerInsights collection. Here, the join syntax starts with the output of the first operation. This becomes the left side of the join. The first line of operation two then inner joins this output to the ContainerInventory table. This second table becomes the right side of the join. The operation sets the common Computer columns of these tables as the column of the join itself. Finally, that operation returns 20000 rows. The third operation places the Computer, Origin, and ContainerHostname columns in the result set, and returns unique rows with the distinct operator. This screenshot shows the query result set:
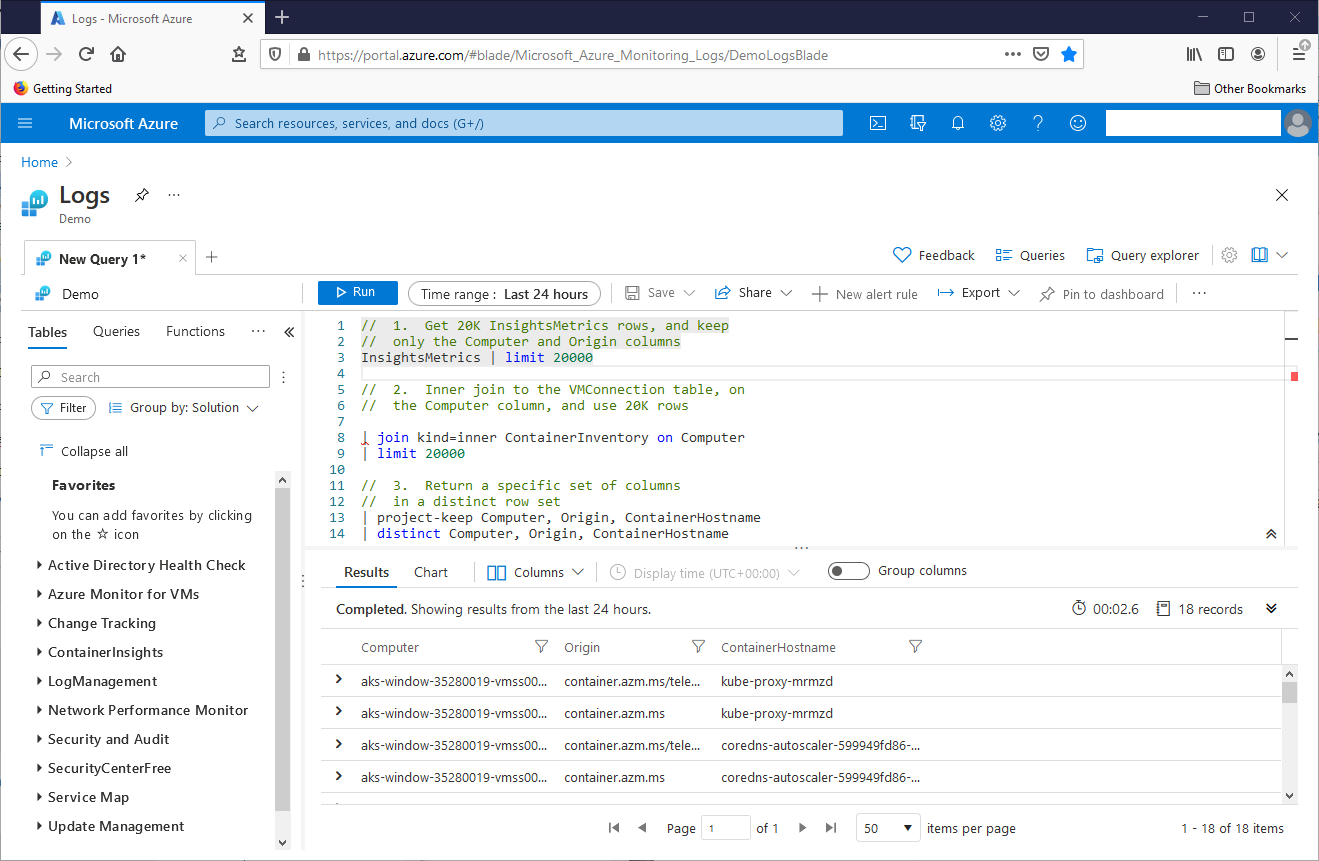
Kusto does not necessarily expect to see the kind={join flavor} keyword/parameter in a join. It will automatically default to innerunique. Carefully note, however, that a Kusto innerunique join does not operate like a SQL Server inner join. A Kusto innerunique join randomly throws out duplicate rows from the left table and then returns all rows from the right table that match the random, remaining rows from the left table. A Kusto query inner join operates the same way as a SQL Server inner join. These joins keep all rows in the left table, returning all rows from the right table that match the left table rows. Additionally, Kusto offers left and right outer joins, and more exotic joins as well. See the documentation for more.
KQL let statement
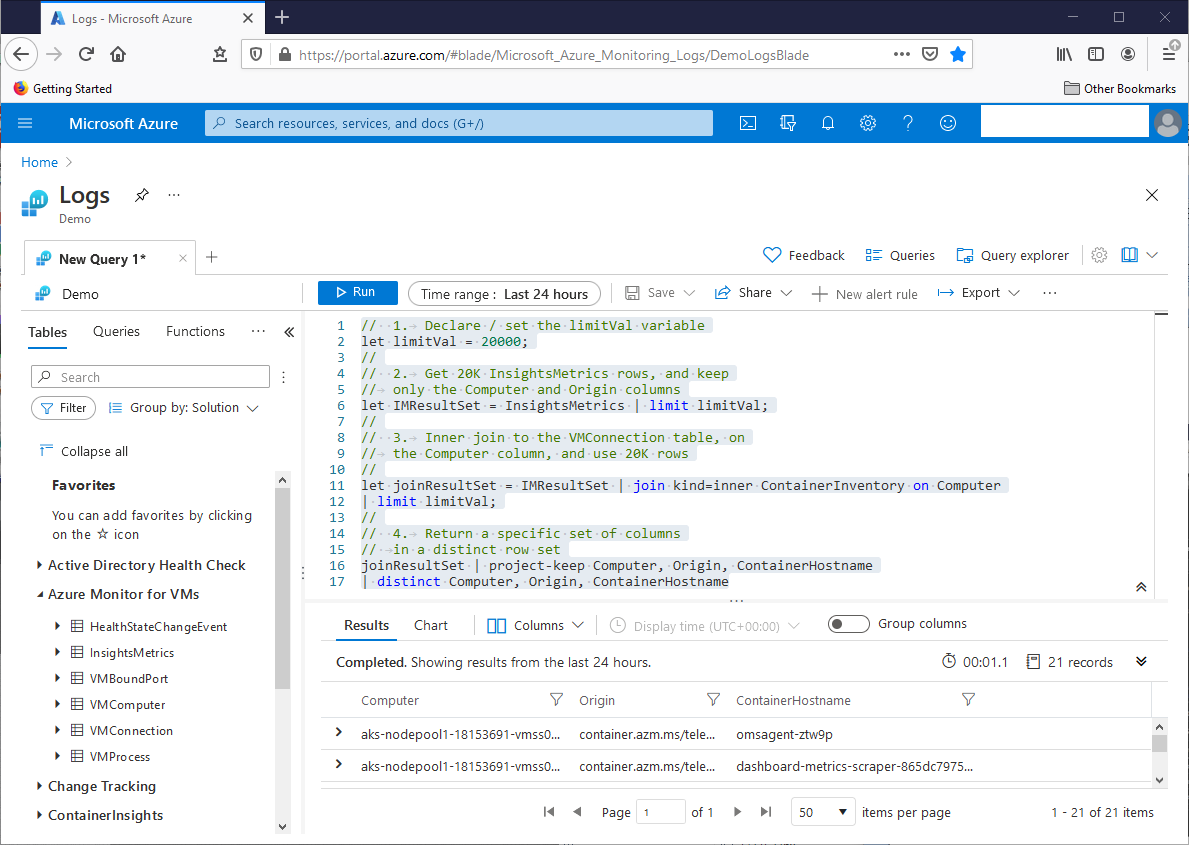
As we build Kusto query language queries, we might need the flexibility of variables, both for scalar values, like numbers or strings, or for row sets. We can use the let statement for this. The next query modifies the KQL Join Operator example query directly above, with let statements:
// 1. Declare / set the limitVal variable
let limitVal = 20000;
//
// 2. Get 20K InsightsMetrics rows, and keep
// only the Computer and Origin columns
let IMResultSet = InsightsMetrics | limit limitVal;
//
// 3. Inner join to the VMConnection table, on
// the Computer column, and use 20K rows
//
let joinResultSet = IMResultSet | join kind=inner ContainerInventory on Computer
| limit limitVal;
//
// 4. Return a specific set of columns
// in a distinct row set
joinResultSet | project-keep Computer, Origin, ContainerHostname
| distinct Computer, Origin, ContainerHostname
In the first operation, the let statement essentially declares the limitVal variable, and sets its value to 20000. The required semicolon (;) ends the statement. After this declaration, we can use limitVal in the query, as seen in operations 2 and 3. The second operation assigns a row set from the InsightsMetrics table to the IMResultSet variable. Operation three uses the limitVal variable in the join operation, and the joinResultSet variable receives the value of that operation. Note that Kusto allows no blank lines in a query with a let statement. This screenshot shows the query result set:
Conclusion
Here, we saw how to use the Kusto query language to extract information from large data masses hosted in the Azure Data Explorer. In the next article, we’ll apply these tools to solve a real problem with a real data table.

See more about Frank at LinkedIn.
Remove the non-standard characters from this address: fb} <s.author@gmail.com to reach him by email.
- Lever the TSQL MAX/MIN/IIF functions for Pinpoint Row Pivots - May 16, 2022
- Use Kusto Query Language to solve a data problem - July 5, 2021
- Azure Data Explorer and the Kusto Query Language - June 21, 2021