

Introduction
Lever T-SQL to handle duplicate rows in SQL Server database tables article highlighted T-SQL features that detect and handle duplicate SQL Server table rows. The techniques work well, but they rely on fixed duplicate row definitions. This article extends those techniques, showing how to define duplicate rows in a dynamic way.
The Sample Database
For this article, we’ll slightly modify the OFFICE_EQUIPMENT_DATABASE database,first described in the earlier article. I built this new database version in SQL Server 2014 Standard Edition, on an updated Windows 10 PC. For this article, we’ll add some rows to the original OFFICE_EQUIPMENT table, and we’ll add a stored procedure. Run this script to build the complete database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 |
USE [master] GO -- This script will place -- -- OFFICE_EQUIPMENT_DATABASE -- -- in the -- -- C:\OFFICE_EQUIPMENT_DATABASE -- -- directory. The -- -- xp_create_subdir -- -- will create this directory. However, because of its extended stored procedure status, -- Microsoft might scrap it, but it still works as of April, 2020. -- EXEC xp_create_subdir N'C:\OFFICE_EQUIPMENT_DATABASE' /****** Object: Database [OFFICE_EQUIPMENT_DATABASE] Script Date: 4/27/2020 1:49:59 PM ******/ CREATE DATABASE [OFFICE_EQUIPMENT_DATABASE] CONTAINMENT = NONE ON PRIMARY ( NAME = N'OFFICE_EQUIPMENT_DATABASE', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE.mdf' , SIZE = 4096KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'OFFICE_EQUIPMENT_DATABASE_log', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO USE [OFFICE_EQUIPMENT_DATABASE] CREATE TABLE [dbo].[OFFICE_EQUIPMENT]( [OFFICE_EQUIPMENT_ID] [int] NOT NULL, [OFFICE_EQUIPMENT_NAME] [nvarchar](750) NULL, [OFFICE_EQUIPMENT_DESCRIPTION] [nvarchar](max) NULL, [PURCHASE_PRICE] [money] NULL, [PURCHASE_QUANTITY] [int] NULL, [PURCHASE_DATE] [datetime] NULL, CONSTRAINT [PK_OFFICE_EQUIPMENT] PRIMARY KEY CLUSTERED ( [OFFICE_EQUIPMENT_ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (1, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (2, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (3, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (4, N'STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (5, N'ENVELOPE', N'#10 BUSINESS SECURITY ENVELOPES - SINGLE WINDOW', 0.0400, 500, CAST(N'2019-08-22 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (6, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (7, N'ERASER', N'TICONDEROGA PINK ERASER', 1.6700, 3, CAST(N'2020-01-22 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (8, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (9, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (10, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (11, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 120, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (12, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (13, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (14, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2018-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (15, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.8900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (16, N'PRINTER PAPER', N'35 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (17, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 3.4900, 22, CAST(N'2020-01-18 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (18, N'PAPER CLIP', N'SMALL AND MEDIUM PAPER CLIPS', 3.1900, 8, CAST(N'2019-01-28 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (19, N'ENVELOPE', N'PRE-ADDRESSED AND PRE-STAMPED', 0.0500, 750, CAST(N'2019-08-22 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (20, N'PAPER CLIPS', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 8, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (21, N'PEN', N'PENTEL BALLPOINT PEN (RED)', 0.7000, 42, CAST(N'2019-01-08 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (22, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (23, N'GRAY STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (24, N'GRAY STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)) GO /****** Object: StoredProcedure [dbo].[DYNAMIC_ROW_NUMBER_PARTITIONS] Script Date: 4/27/2020 1:49:59 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE PROCEDURE [dbo].[DYNAMIC_ROW_NUMBER_PARTITIONS] @PARTITION_COLUMN_LIST int AS /* To use: EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 */ SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM FROM ( SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY IIF(RIGHT((@PARTITION_COLUMN_LIST / 100000), 1) = 1, OFFICE_EQUIPMENT_ID, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 1000), 1) = 1, OFFICE_EQUIPMENT_DESCRIPTION, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 100), 1) = 1, PURCHASE_PRICE, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10), 1) = 1, PURCHASE_QUANTITY, NULL), IIF(RIGHT(@PARTITION_COLUMN_LIST, 1) = 1, PURCHASE_DATE, NULL) ORDER BY OFFICE_EQUIPMENT_DESCRIPTION -- THIS ORDER BY DOES NOT SORT THE OUTER RESULT SET ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) TMP WHERE ROW_NUM > 1; |
See the earlier article for more details about the script, the table, and the table structure. This article will focus on the T-SQL features in the stored procedure, and will describe how these features offer a flexible, dynamic way to define duplicate table rows.
The Stored Procedure in action
The OFFICE_EQUIPMENT_DATABASE database has one stored procedure DYNAMIC_ROW_NUMBER_PARTITIONS with this code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
CREATE PROCEDURE [dbo].[DYNAMIC_ROW_NUMBER_PARTITIONS] @PARTITION_COLUMN_LIST int AS /* To use: EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 */ SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM FROM ( SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY IIF(RIGHT((@PARTITION_COLUMN_LIST / 100000), 1) = 1, OFFICE_EQUIPMENT_ID, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 1000), 1) = 1, OFFICE_EQUIPMENT_DESCRIPTION, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 100), 1) = 1, PURCHASE_PRICE, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10), 1) = 1, PURCHASE_QUANTITY, NULL), IIF(RIGHT(@PARTITION_COLUMN_LIST, 1) = 1, PURCHASE_DATE, NULL) ORDER BY OFFICE_EQUIPMENT_DESCRIPTION -- THIS ORDER BY DOES NOT SORT THE OUTER RESULT SET ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) TMP WHERE ROW_NUM > 1; |
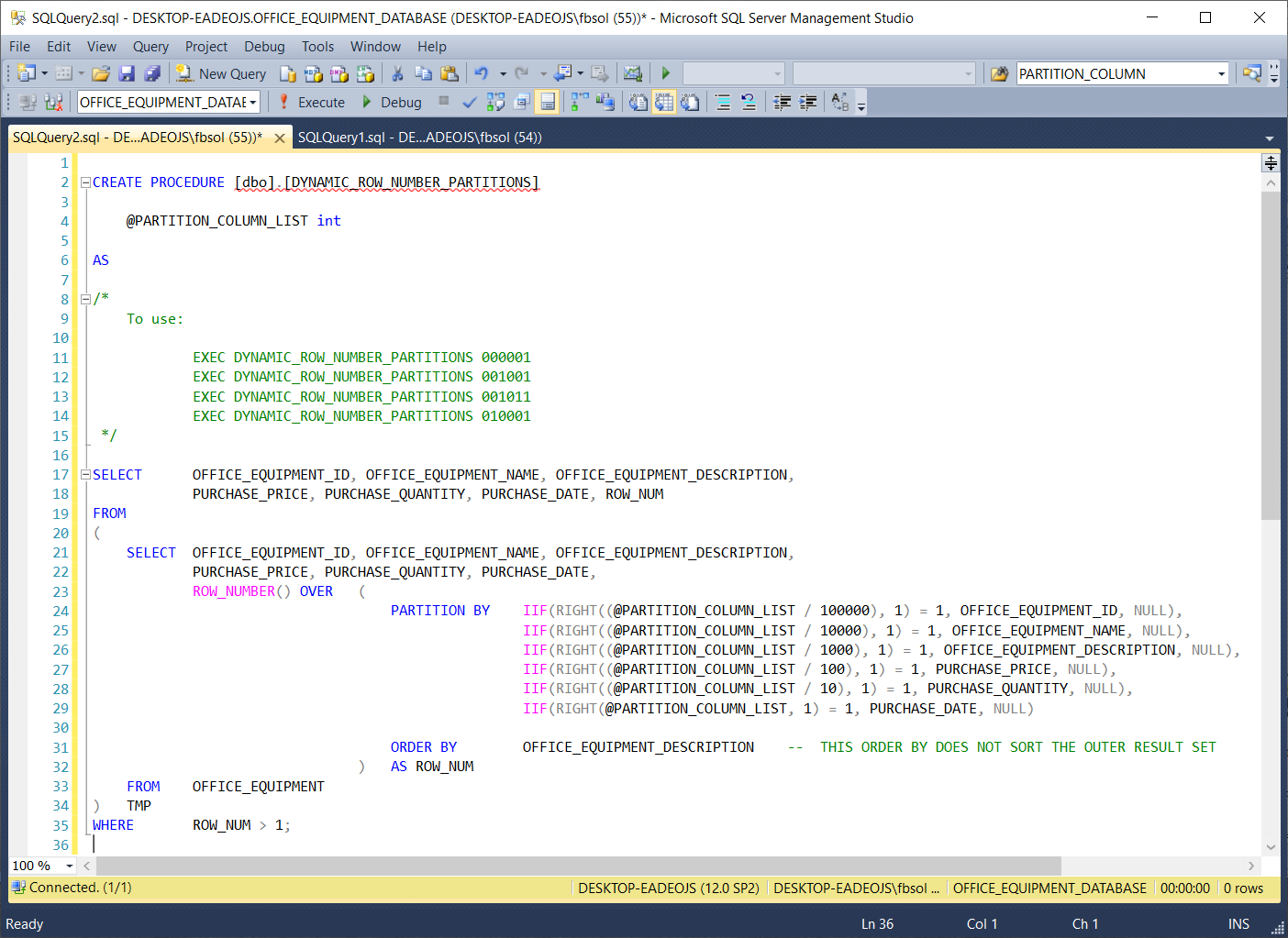
As seen in the above screenshot, the stored procedure has one integer data type parameter @PARTITION_COLUMN_LIST at line 4. We can manually “paint” and run lines 11 through 14 to test the stored procedure. This screenshot runs line 11 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 with a 000001 argument value:
The result set defined duplicate rows based on the PURCHASE_DATE column values. Later on, we’ll see how different argument values drive these definitions. This screenshot runs line 13 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 with a 001011 argument value:
The result set defined duplicate rows based on the below column values:
- OFFICE_EQUIPMENT_DESCRIPTION
- PURCHASE_QUANTITY
- PURCHASE_DATE
The stored procedure filters out rows with ROW_NUM values below 1, with the T-SQL WHERE clause at line 35. The stored procedure does not necessarily need this filter, but with it, we can more clearly see how the engineering works.
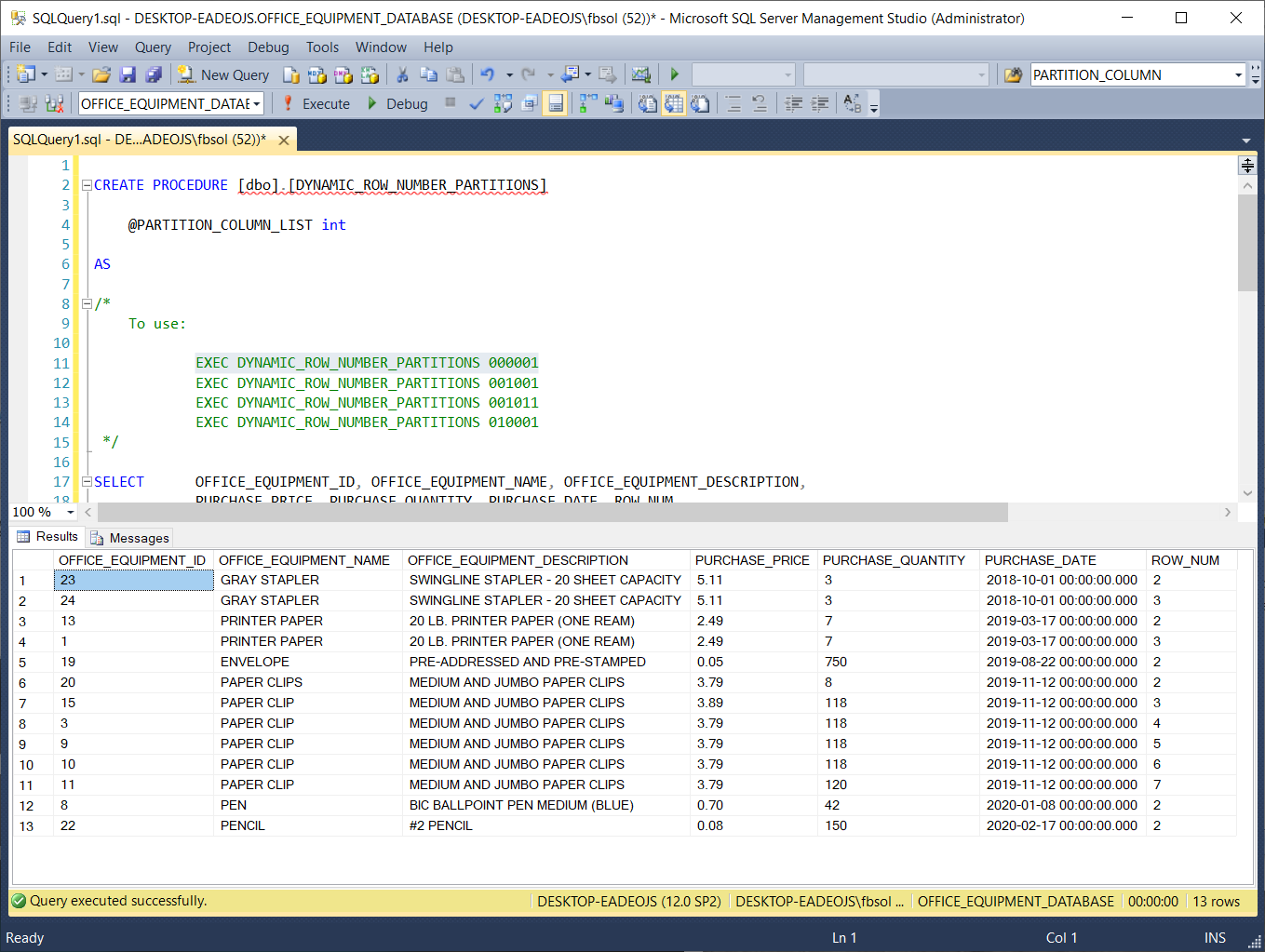
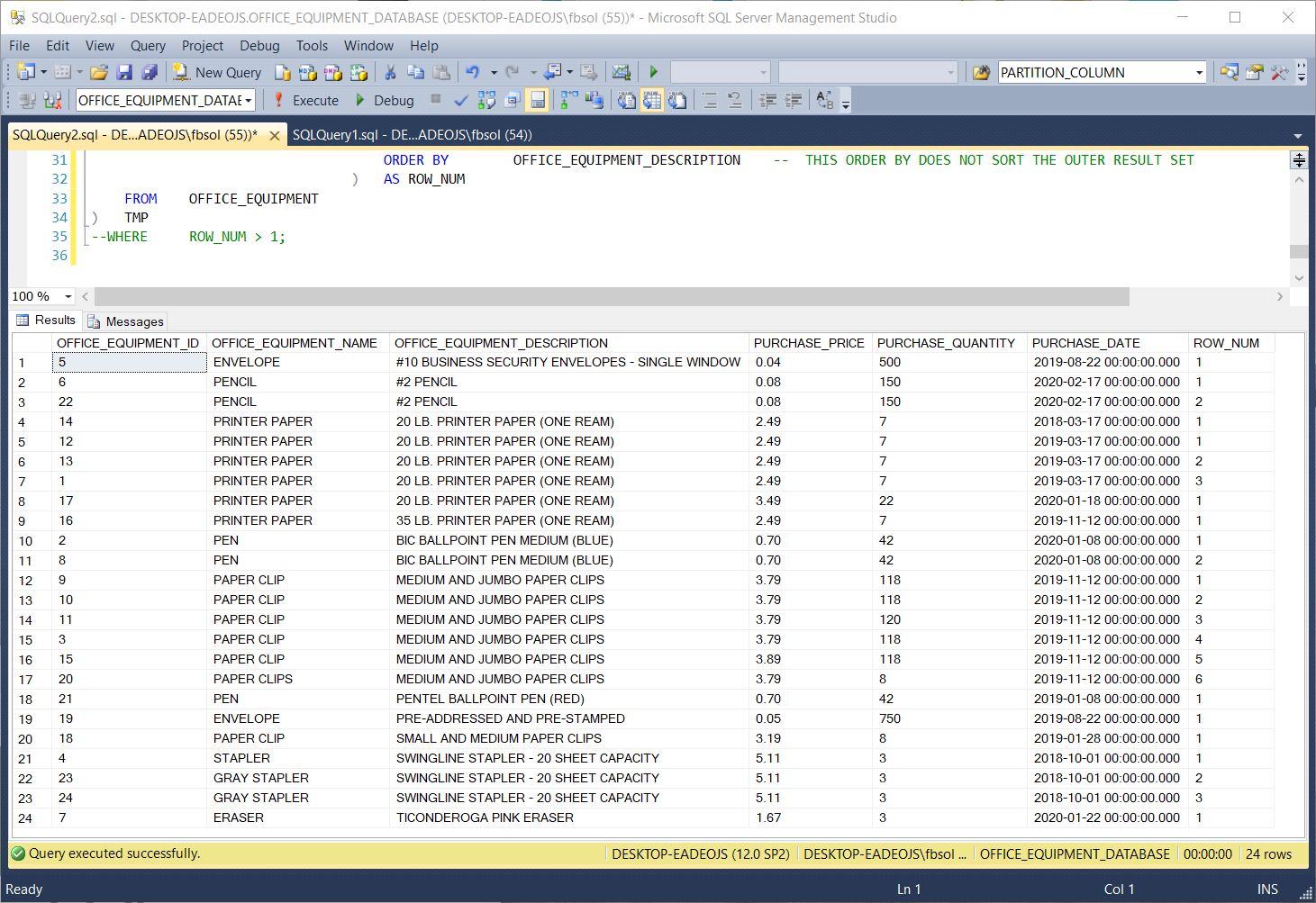
If we comment out line 35 and run line 12 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001, the result set defines duplicate rows based on the OFFICE_EQUIPMENT_DESCRIPTION PURCHASE_DATE column values. The stored procedure returns a result set with 24 rows, as shown in this screenshot:
If we restore the line 35 T-SQL WHERE clause and again run line 12, the stored procedure returns the result set shown in this screenshot:
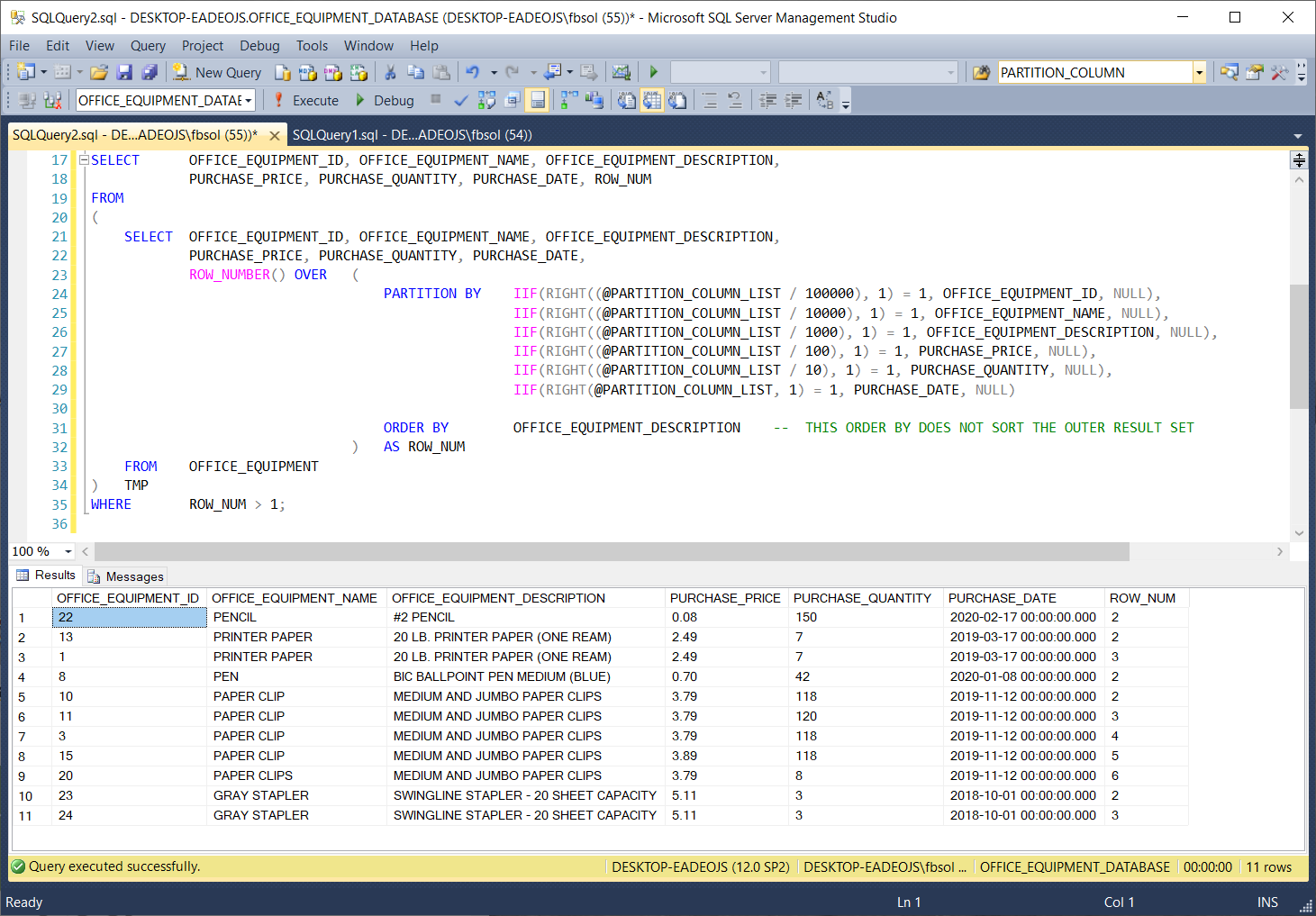
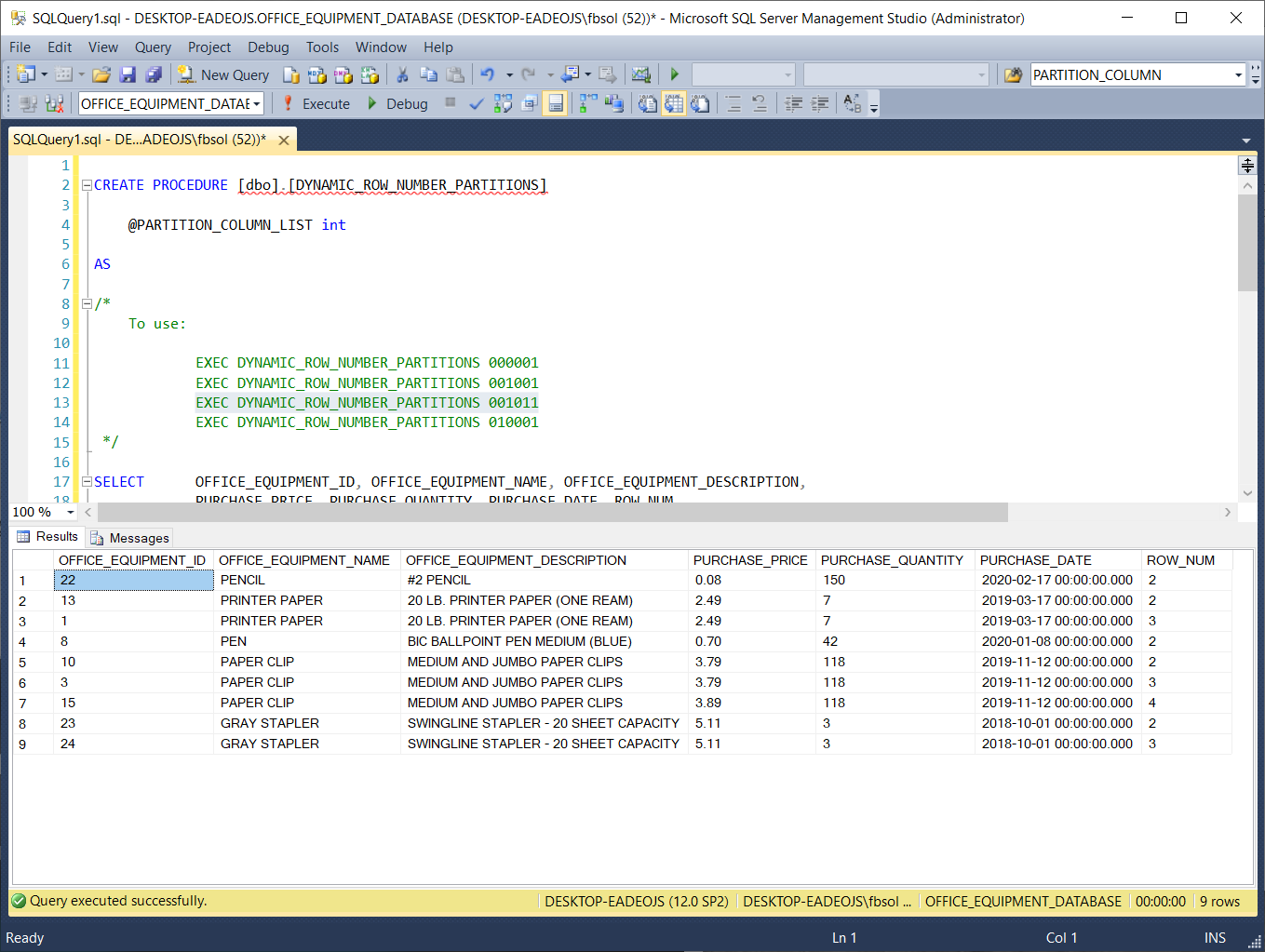
If we comment out line 35 and run the stored procedure with line 14 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 the result set defines duplicate rows based on the OFFICE_EQUIPMENT_NAME and PURCHASE_DATE column values. Compared to EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 this result set looks very different, but it still returns 24 rows, as shown in this screenshot:
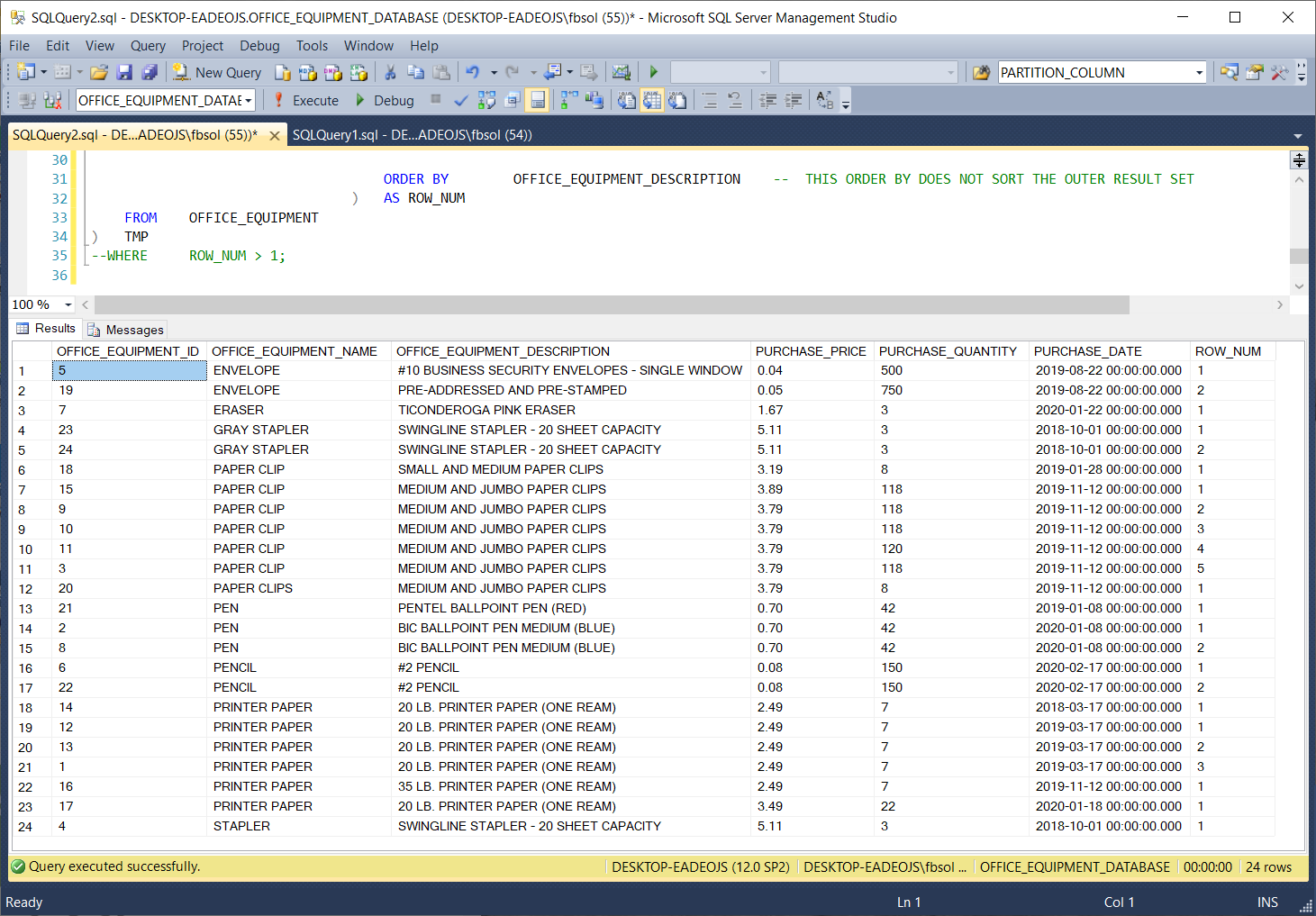
If we restore the line 35 T-SQL WHERE clause and again run line 14 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001, we will get a different result set, as seen in this screenshot:
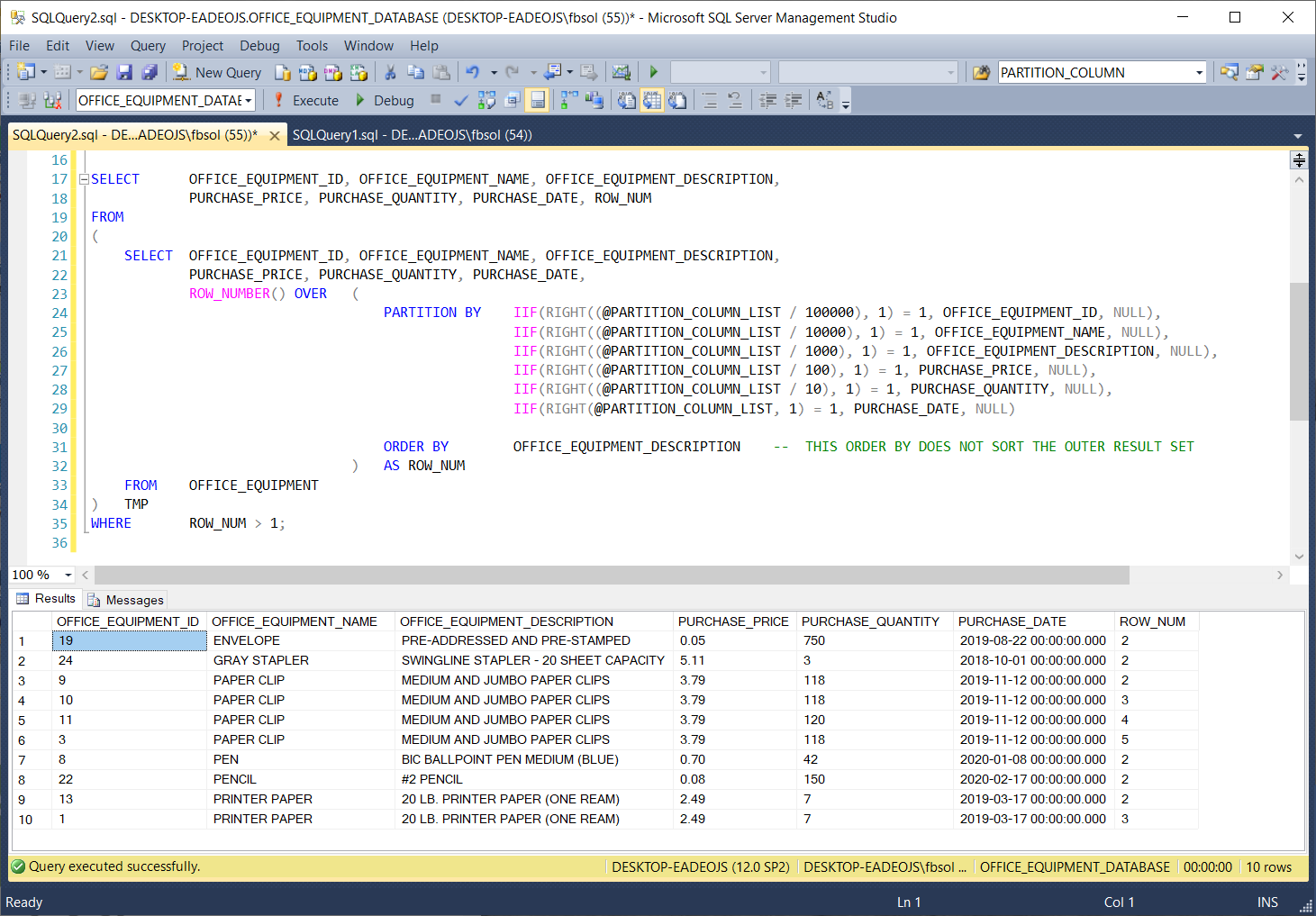
Clearly, the line 35 WHERE clause helps show how the stored procedure works, because when we disable it, the stored procedure returns 24 rows, for all input parameter values. In these 24-row result sets, the ROW_NUM values show that the stored procedure builds different “groups” based on the different @PARTITION_COLUMN_LIST values. This behavior makes it harder to see how the stored procedure operates.
The Stored Procedure Engineering
In this article, the first screenshot showed the DYNAMIC_ROW_NUMBER_PARTITIONS stored procedure, but as we study its engineering, it will help to see the screenshot again:
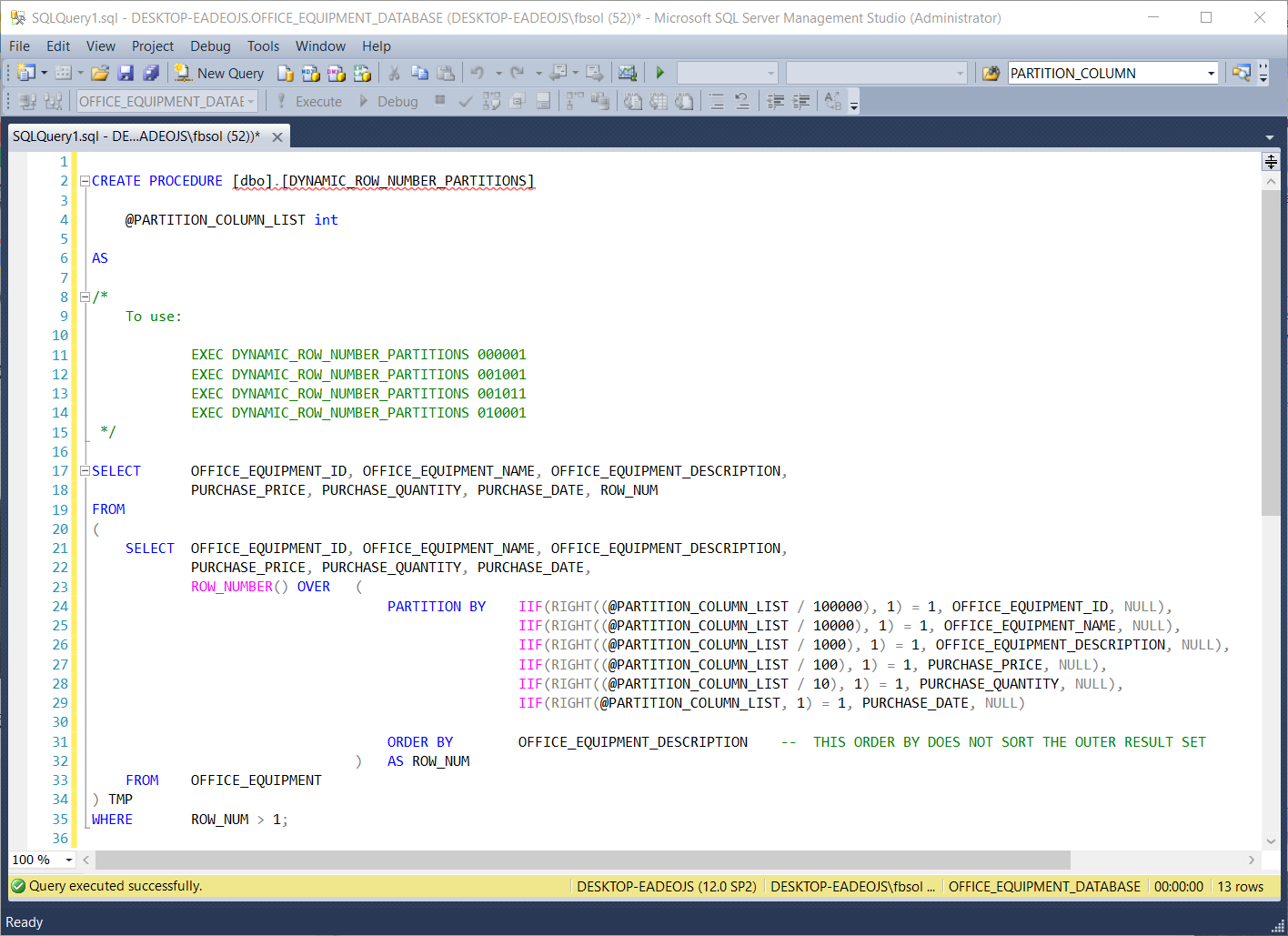
Lever T-SQL to handle duplicate rows in SQL Server database tables article explained that a T-SQL query with ROW_NUMBER() and PARTITION BY clauses can’t directly filter its result set with a WHERE clause. However, the article also showed that if we place that query in a FROM clause subquery, and then SELECT from it, we can add a WHERE clause to the outer query. With this approach, we can filter the result set. In the DYNAMIC_ROW_NUMBER_PARTITIONS stored procedure, the subquery, between lines 21 and 31, has a ROW_NUMBER() clause at line 23. It also has a PARTITION BY clause between lines 24 and 29. In the stored procedure, the line 35 WHERE clause filters the result set that the subquery returns. At lines 17 and 18, the outer query T‑SQL SELECT clause selects columns from the inner subquery. Line 34 aliases the subquery as ‘TMP’.
The PARTITION BY clause, seen here between lines 24 and 29, builds the duplicate row definition. Each PARTITION BY clause line extracts a specific parameter digit, and indirectly maps to one column in the SELECT clause of lines 21 and 22. We’ll focus on line 25 as an example, and work from the inside out to see the technique.
The DYNAMIC_ROW_NUMBER_PARTITIONS stored procedure returns result sets with these six columns:
- OFFICE_EQUIPMENT_ID
- OFFICE_EQUIPMENT_NAME
- OFFICE_EQUIPMENT_DESCRIPTION
- PURCHASE_PRICE
- PURCHASE_QUANTITY
- PURCHASE_DATE
The test code examples of lines 11 to 14 use six-digit integer arguments:
|
1 2 3 4 |
EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 |
In the T-SQL PARTITION BY clause, we can map the individual digits in the arguments to specific columns. Then, the PARTITION BY clause can use those values to define duplicate rows, if we use only ones or zeros for each digit in the original argument values.
For example, EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 sets @PARTITION_COLUMN_LIST to 001001. With this value, line 25
|
1 |
IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL) |
maps digit 2 to the OFFICE_EQUIPMENT_NAME column. We’ll unpack this line from the inside out.
The @PARTITION_COLUMN_LIST / 10000 calculation divides @PARTITION_COLUMN_LIST by 10000, and truncates, or throws away, the remainder. Dividing a six-digit integer by 10000 in this way removes the four digits on the right, as seen in this screenshot:
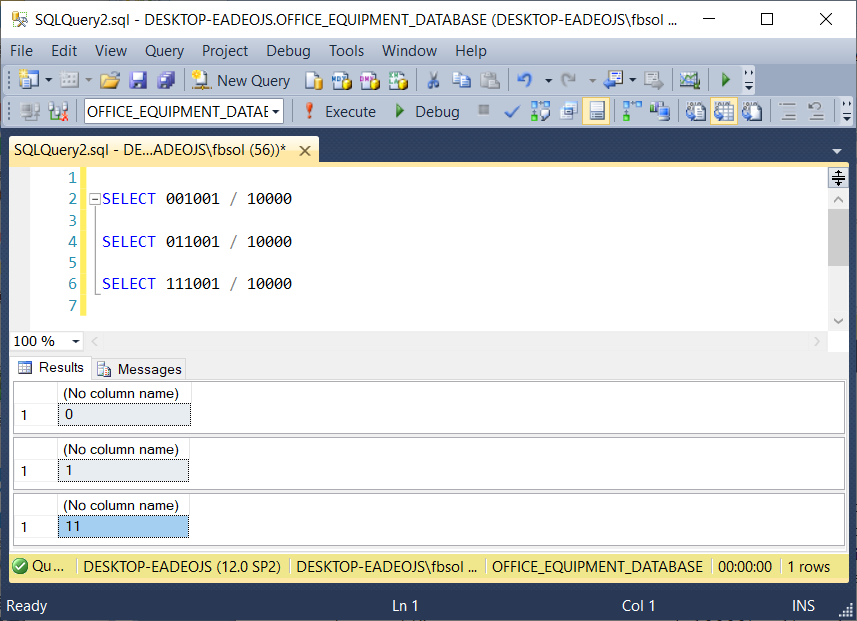
The next function RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) extracts the first right digit of 00100 – in this case, a zero (0). The third query in the previous screenshot shows that we need the T‑SQL RIGHT() function, to extract the specific right-most digit. Finally, the IIF() function on the “outside” looks at the value that the T-SQL RIGHT() function returns, as seen here:
|
1 |
IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL) |
The IIF() function short-hands the SQL Server CASE expression. As used here, if the RIGHT() function returns 1, or TRUE, IIF() returns OFFICE_EQUIPMENT_NAME and places the OFFICE_EQUIPMENT_NAME column in the PARTITION BY column list. When the RIGHT function returns 0, or FALSE, IIF() returns NULL. The stored procedure ignores these NULL values as it dynamically builds the PARTITION BY clause, and when IIF() returns a NULL value, the stored procedure never sees the column name in the IIF() function. As a special case, line 29
|
1 |
IIF(RIGHT(@PARTITION_COLUMN_LIST, 1) = 1, PURCHASE_DATE, NULL) |
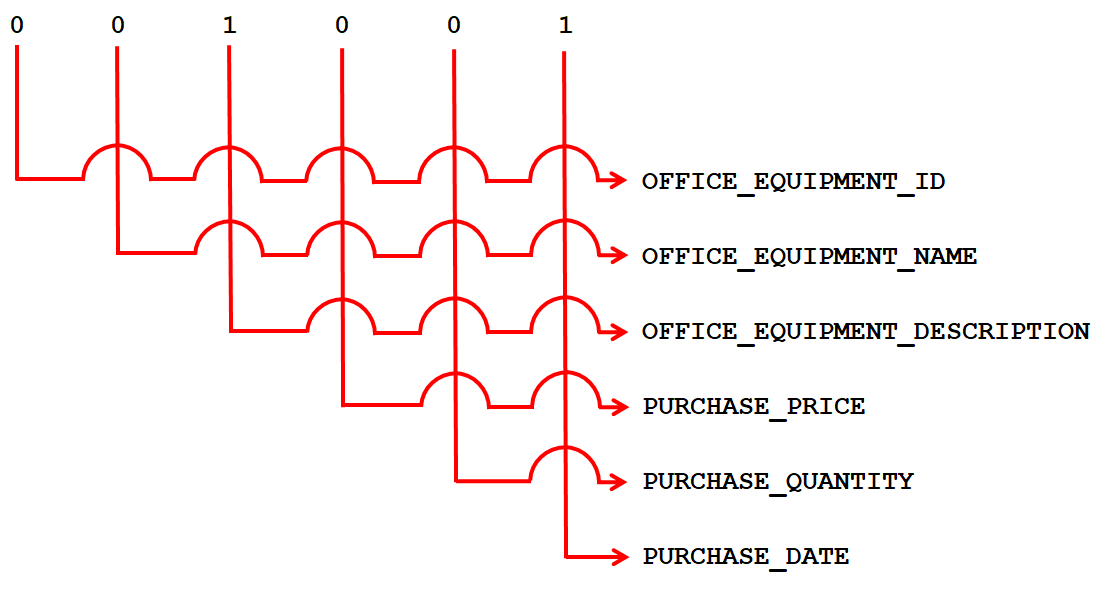
avoids the division calculation, because the RIGHT() function can directly extract the far-right digit of the @PARTITION_COLUMN_LIST value. With this technique, a six-digit integer maps to all six columns. For example, 001001 maps to all six columns as seen in this diagram:
The T-SQL PARTITION BY clause requires at least one column in the line 31 ORDER BY clause, but this ORDER BY clause does not operate on the finished result set. It independently operates inside each row partition, sorting by the columns specified in its column list. As explained above, the line 35 T-SQL WHERE clause removes rows with ROW_NUM values of 1.
The Order of PARTITION BY Columns
The technique behind this stored procedure, in part, involves the below:
- The PARTITION BY column list, between lines 24 and 29
- The ORDER BY clause, at line 31
- The WHERE clause, at line 35
We can easily add an ORDER BY clause after line 35. The stored procedure, and the engineering behind it, all work in a consistent way. However, we should keep the listed aspects in mind, because stored procedures that use them can build result sets that might seem unexpected.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
CREATE PROCEDURE [dbo].[DYNAMIC_ROW_NUMBER_PARTITIONS] @PARTITION_COLUMN_LIST int AS /* To use: EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 */ SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM FROM ( SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY IIF(RIGHT((@PARTITION_COLUMN_LIST / 100000), 1) = 1, OFFICE_EQUIPMENT_ID, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 1000), 1) = 1, OFFICE_EQUIPMENT_DESCRIPTION, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 100), 1) = 1, PURCHASE_PRICE, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10), 1) = 1, PURCHASE_QUANTITY, NULL), IIF(RIGHT(@PARTITION_COLUMN_LIST, 1) = 1, PURCHASE_DATE, NULL) ORDER BY OFFICE_EQUIPMENT_DESCRIPTION -- THIS ORDER BY DOES NOT SORT THE OUTER RESULT SET ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) TMP WHERE ROW_NUM > 1; |
If we run the stored procedure we saw above with this statement EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001, we will get this result set as seen in this screenshot:
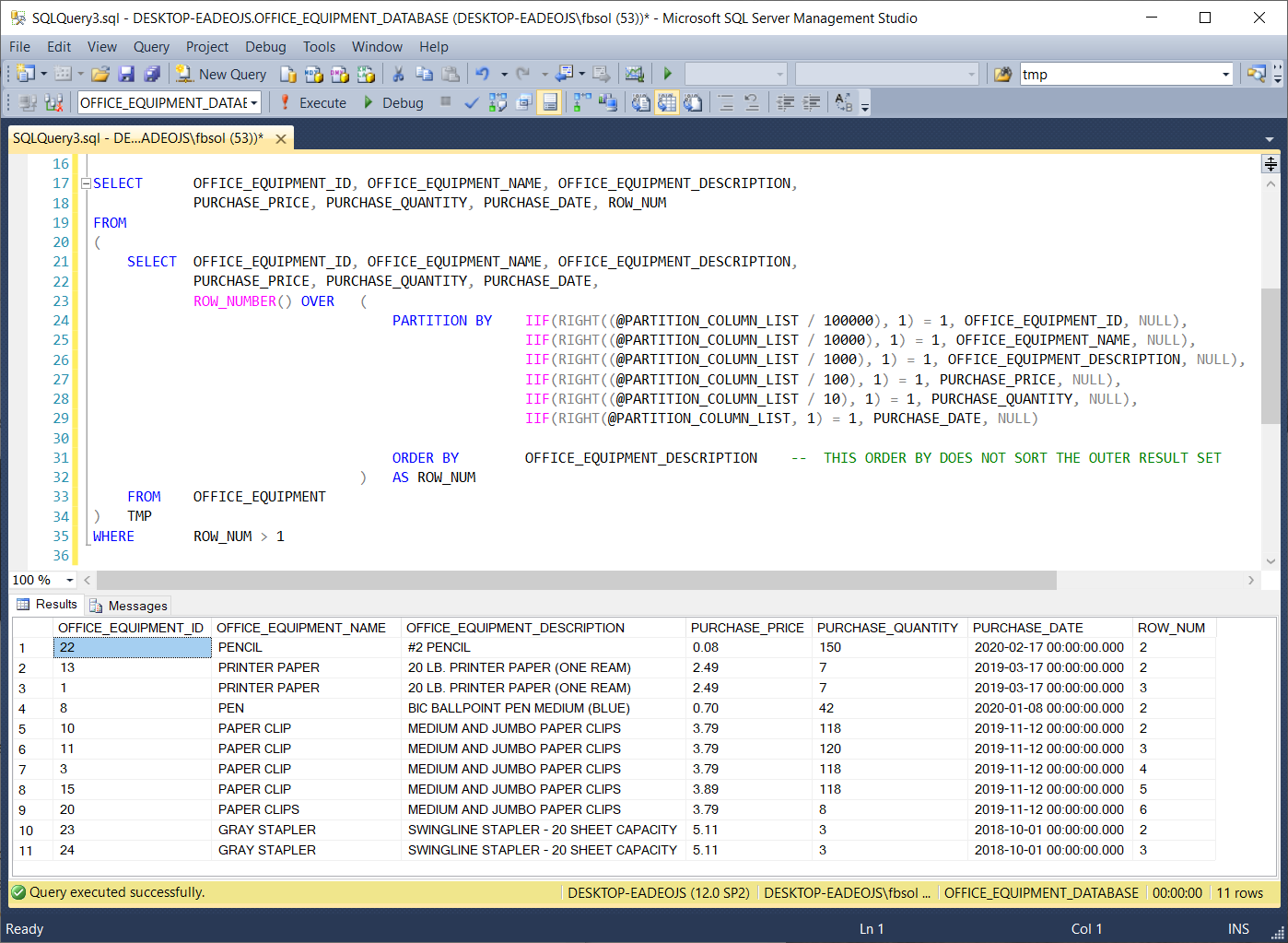
We can exchange lines 26 and 29, as seen here:
|
1 2 3 4 5 6 7 |
CREATE PROCEDURE [dbo].[DYNAMIC_ROW_NUMBER_PARTITIONS] @PARTITION_COLUMN_LIST int AS /* |
To use:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 000001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001011 EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 010001 */ SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM FROM ( SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY IIF(RIGHT((@PARTITION_COLUMN_LIST / 100000), 1) = 1, OFFICE_EQUIPMENT_ID, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10000), 1) = 1, OFFICE_EQUIPMENT_NAME, NULL) , /* LINE 26: SWITCHED LINE */ IIF(RIGHT(@PARTITION_COLUMN_LIST, 1) = 1, PURCHASE_DATE, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 100), 1) = 1, PURCHASE_PRICE, NULL), IIF(RIGHT((@PARTITION_COLUMN_LIST / 10), 1) = 1, PURCHASE_QUANTITY, NULL) , /* LINE 29: SWITCHED LINE */ IIF(RIGHT((@PARTITION_COLUMN_LIST / 1000), 1) = 1, OFFICE_EQUIPMENT_DESCRIPTION, NULL) ORDER BY OFFICE_EQUIPMENT_DESCRIPTION -- THIS ORDER BY DOES NOT SORT THE OUTER RESULT SET ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) TMP WHERE ROW_NUM > 1; |
When we run the stored procedure with the SQL Server statement used above EXEC DYNAMIC_ROW_NUMBER_PARTITIONS 001001, we’ll get this result set:
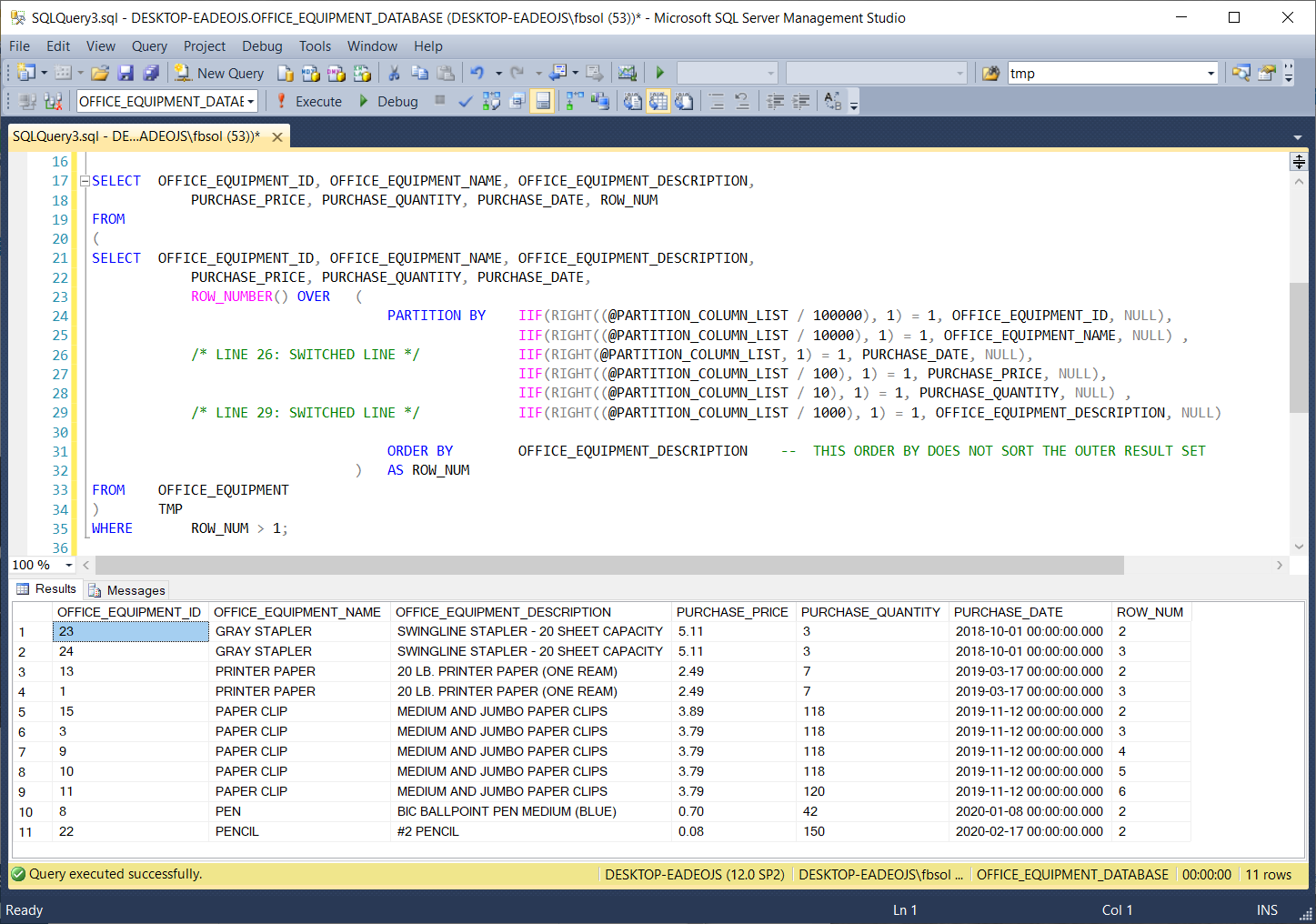
Because of the ways, the factors listed above can interact, combined with a potential ORDER BY clause at the outer query, we need to test queries and stored procedures built with this technique, to verify that they operate as expected.
Conclusion
The PARTITION BY clause gives us a powerful tool, right out of the box, to define duplicate rows in a database table. This article showed how to combine the PARTITION BY clause with other available SQL Server tools, to define duplicate rows in a dynamic, granular way.

See more about Frank at LinkedIn.
Remove the non-standard characters from this address: fb} <s.author@gmail.com to reach him by email.
- Lever the TSQL MAX/MIN/IIF functions for Pinpoint Row Pivots - May 16, 2022
- Use Kusto Query Language to solve a data problem - July 5, 2021
- Azure Data Explorer and the Kusto Query Language - June 21, 2021