
Before going through the main concern of this article, indexing the foreign key columns, let’s take a small trip back to review the SQL Server Indexes and Foreign Key concepts.
SQL Server Indexes Overview
A SQL Server index is considered as one of the most important performance-tuning factors. They are built on a table or view in the shape of the B-Tree structure to provide a fast access to the requested data, based on the index column’s values, speeding up the query processing. Without having an index in your table, the SQL Server Engine will scan all the table’s data in order to find the row that meets the requested data criteria. You can imagine the table scan as reading all the book pages in order to find a specific word, where the book index will help you in finding the requested information quickly.
SQL Server offers mainly two types of indexes, a Clustered index that stores the actual data of the table at the leaf level of the index, including all the table columns, and control its sort in the disk. A Non-clustered index contains only the index key columns values in addition to a pointer to the actual data rows stored in the clustered index or the actual table, without specifying the real data order. You can create only one clustered index per each table, with the ability to create up to 999 non-clustered indexes on each table. A table with no clustered index is called a Heap table, with its actual data not sorted in the disk. There are other index types available in SQL Server, such as the Composite index that contains more than one key column, the Unique index that enforces the column values uniqueness and the Covering index that contains all columns needed by the query.
Creating a suitable index is not an easy task, as you need to balance between the need to speed up the data retrieval process and the drawback of the index creation on the data insertion and modification processes. You need also to make sure that the index size is as small as possible, due to the disk space that will be consumed by the index, in addition to the index maintenance overhead. So, it is better always to test index efficiency on a development server before performing that change in the production environment.
Foreign Key Overview
A Foreign Key is a database key that is used to link two tables together by referencing a field in the first table that contains the foreign key, called the Child table, to the PRIMARY KEY in the second table, called the Parent table. In other words, the foreign key column values in the child table must appear in the referenced PRIMARY KEY column in the parent table before inserting its value to the child table. This reference performed by the foreign key constraint will enforce database referential integrity. You may recall that the PRIMARY KEY is a table constraint that maintains the uniqueness and non-NULL values for the chosen column or columns values, enforcing the entity integrity for that table, with the ability to create only one PRIMARY KEY per each table. You can include the foreign key creation while creating the table using CREATE TABLE T-SQL statement or create it after the table creation using ALTER TABLE T-SQL statement.
Benefits of indexing Foreign Key Columns
When a PRIMARY KEY constraint is defined, a clustered index will be created on the constraint columns by default, if there is no previous clustered index defined on that table. So, we can expect that everything is configured well at the parent table’s side. The case may differ with the foreign key constraint at the child table’s side, where no index will be created on the constraint keys automatically, and it is the database administrator’s or developer’s responsibility to create the index on the child table manually.
It is highly recommended to create an index on each foreign key constraint on the child table, as it is very common when calling that key on your queries to join between the child table and the parent table columns, providing better joining performance. Indexing foreign key columns also help in reducing the cost of maintaining the relationship between parent and child tables that is specified by the (CASCADE) or (NO ACTION) option. This option comes into play when an UPDATE or DELETE operation is executed, by speeding up the process of retrieving the common reference values that the action will be performed on.
Let us see the benefits of indexing the foreign key columns practically. We will create four tables under the SQLShackDemo testing database, with the relations specified by the database diagram shown below:
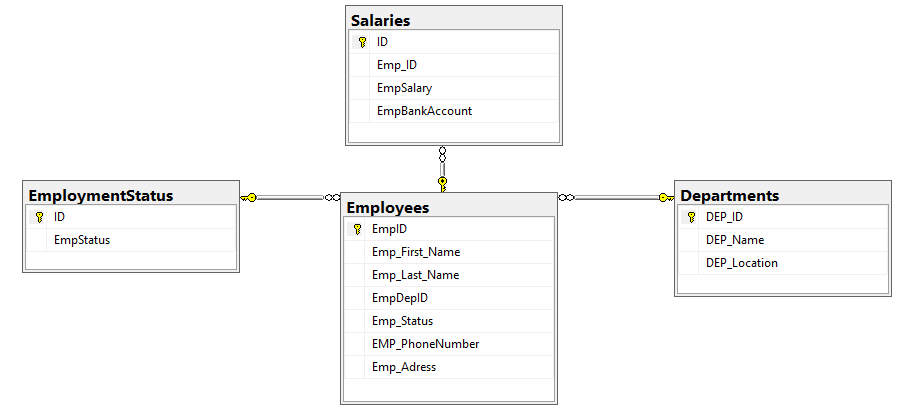
The relations between the tables shown in the previous database diagram can be summarized as:
- The EmpDepID column from the Employees table references the Dep_ID column from the Department table.
- The EmpStatus column from the Employees table references the ID column from the EmploymentStatus table.
- The Emp_ID column from the Salaries table references the EmpID column from the Employees table.
The T-SQL script below is used to create the four new tables with the three foreign key constraints described previously:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
USE [SQLShackDemo] GO CREATE TABLE [dbo].[Departments]( [DEP_ID] [int] NOT NULL PRIMARY KEY , [DEP_Name] [nvarchar](50) NULL, [DEP_Location] [nvarchar](max) NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[EmploymentStatus]( [ID] [int] NOT NULL PRIMARY KEY , [EmpStatus] INT NULL, ) ON [PRIMARY] GO CREATE TABLE [dbo].[Employees]( [EmpID] [int] NOT NULL PRIMARY KEY, [Emp_First_Name] [nvarchar](50) NULL, [Emp_Last_Name] [nvarchar](50) NULL, [EmpDepID] [int] NOT NULL CONSTRAINT [FK_DEP] FOREIGN KEY([EmpDepID]) REFERENCES [dbo].[Departments] ([DEP_ID]) ON DELETE CASCADE, [Emp_Status] [int] NOT NULL CONSTRAINT [FK_Stat] FOREIGN KEY([Emp_Status]) REFERENCES [dbo].[EmploymentStatus] ([ID]) ON DELETE CASCADE, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Adress] [nvarchar](max) NULL ) ON [PRIMARY] GO CREATE TABLE [dbo].[Salaries]( ID INT IDENTITY (1,1) PRIMARY KEY, [Emp_ID] [int] NOT NULL CONSTRAINT [FK_Sal] FOREIGN KEY([Emp_ID]) REFERENCES [dbo].[Employees] ([EmpID]) ON DELETE CASCADE, [EmpSalary] INT NULL, [EmpBankAccount] VARCHAR(100) ) ON [PRIMARY] GO |
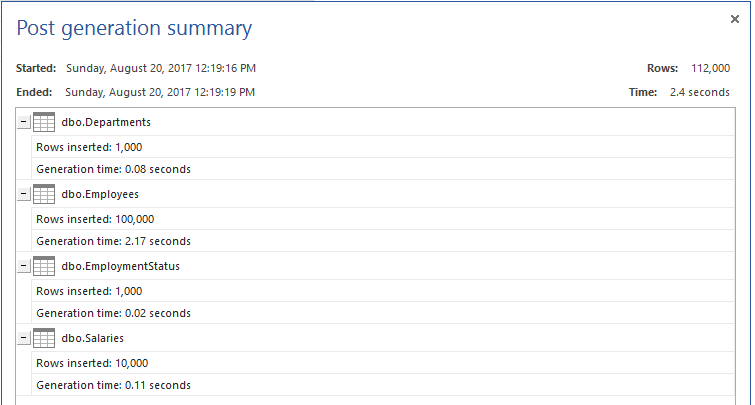
The tables are created successfully now. To have a fair testing scenario, we will fill these tables with testing data using ApexSQL Generate as shown below:
Once the tables are filled with synthetic test data, we will run a SELECT query that joins the four tables together using the foreign keys columns to retrieve data from the Employees table that meets specific criteria. We will start with enabling IO and TIME statistics for performance comparison purposes. We will also free up the procedure cache each time we run the SELECT query to make sure that a new plan will be generated with each run. The T-SQL script to achieve that is as shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC FREEPROCCACHE; SELECT EMP.Emp_First_Name , EMP.Emp_Last_Name FROM [Employees] AS EMP JOIN [Departments] AS DEP ON EMP.EmpDepID =DEP.DEP_ID JOIN [EmploymentStatus] AS Stat ON EMP.Emp_Status =Stat.ID JOIN [Salaries] AS Sal ON EMP.EmpID =Sal.Emp_ID WHERE EMP.Emp_Status =370 AND EMP.EmpDepID =370 AND Sal.EmpSalary>0 AND EMP.Emp_Adress LIKE '%enim%' |
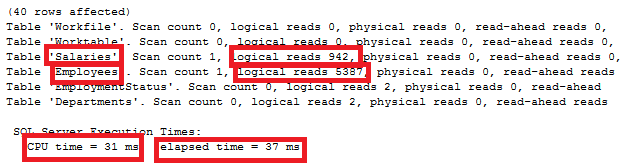
The IO statistics generated by running the previous query shows that 942 logical reads performed on the Salaries table and 5387 logical reads performed on the Employees table to retrieve the requested data. The previous query took 37ms to execute completely, consuming 31ms from the CPU time as shown below:
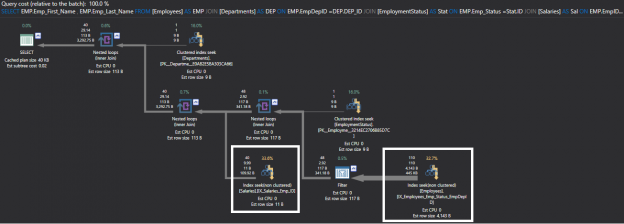
Also, the execution plan generated from the previous query using ApexSQL Plan, shows that a Clustered Index Scan is performed on both Employees and Salaries tables in order to retrieve the requested data, consuming the highest weights from the overall query weight as shown in the execution plan below:
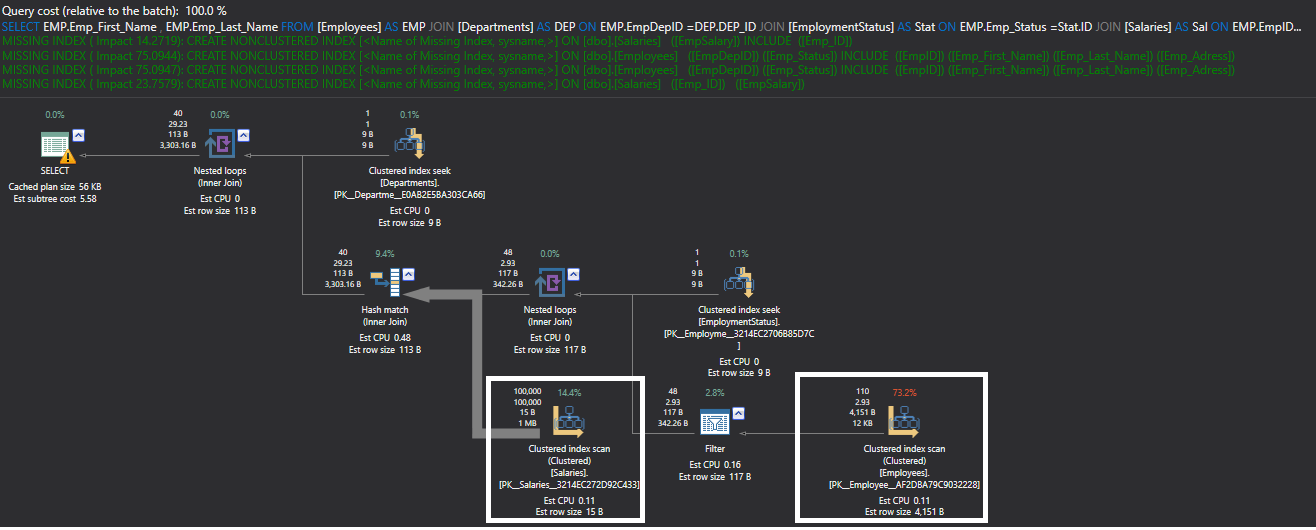
From the previous execution plan, you will find a number of suggested indexes, in green, that SQL Server found that may enhance query performance. You can clearly see that these suggested indexes are on foreign keys columns. It is better always to handle suggested indexes carefully, and make sure that it will speed up the queries without causing any side effects.
In addition to the suggested indexes warning provided within the execution plan, we can search for all the foreign keys columns in all the database tables that are not indexed yet. In order to create indexes on these columns. What we will do is:
- Retrieve all foreign keys from all database tables by querying the sys.foreign_keys system object and fill its information in the #TempForeignKeys temp table.
- Retrieve all indexed foreign keys columns from all database tables by querying the sys.foreign_keys_columns system object joined with the #TempForeignKeys temp table and sys.index_columns system object and fill the object IDs information in the #TempIndexedFK temp table.
- Retrieve the foreign keys from all database tables that columns are not indexed yet by excluding the result filled in the # TempIndexedFK temp table from the result filled in the #TempForeignKeys temp table.
Gathering all together, the below T-SQL script can be used to retrieve all foreign keys that columns are not indexed yet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE TABLE #TempForeignKeys (TableName varchar(100), ForeignKeyName varchar(100) , ObjectID int) INSERT INTO #TempForeignKeys SELECT OBJ.NAME, ForKey.NAME, ForKey .[object_id] FROM sys.foreign_keys ForKey INNER JOIN sys.objects OBJ ON OBJ.[object_id] = ForKey.[parent_object_id] WHERE OBJ.is_ms_shipped = 0 CREATE TABLE #TempIndexedFK (ObjectID int) INSERT INTO #TempIndexedFK SELECT ObjectID FROM sys.foreign_key_columns ForKeyCol JOIN sys.index_columns IDXCol ON ForKeyCol.parent_object_id = IDXCol.[object_id] JOIN #TempForeignKeys FK ON ForKeyCol.constraint_object_id = FK.ObjectID WHERE ForKeyCol.parent_column_id = IDXCol.column_id SELECT * FROM #TempForeignKeys WHERE ObjectID NOT IN (SELECT ObjectID FROM #TempIndexedFK) DROP TABLE #TempForeignKeys DROP TABLE #TempIndexedFK |
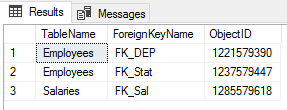
The result will show that no index found on the three foreign keys created previously:
Let us create the below two indexes that include the foreign key columns on both the Employees and Salaries tables using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_Employees_Emp_Status_EmpDepID] ON [dbo].[Employees] ([Emp_Status],[EmpDepID]) INCLUDE ([EmpID],[Emp_First_Name],[Emp_Last_Name],[Emp_Adress]) GO CREATE NONCLUSTERED INDEX [IX_Salaries_Emp_ID] ON [dbo].[Salaries] ( [Emp_ID] ASC ) INCLUDE ([EmpSalary]) GO |
Then try to run the previous SELECT statement again, to check if these two new indexes will enhance the query performance.
The IO statistics gathered from the new run of the query shows that the number of logical reads on the Salaries table decreased to 96, compared with the 942 logical reads performed before adding the index, with about 90% enhancement to the logical reads on the Salaries table. For the Employees table, the number of logical reads on the table after creating the index is decreased to 9, compared with the 5,387 logical reads performed before adding the index, with about 99% enhancement to the logical reads on the Employees table. The enhancement is clear also from the TIME statistics gathered from the query, where the query took only 1ms to execute completely, compared with the 37ms required to execute the query before adding the indexes, with about 97% enhancement to the total query execution time. No CPU time was consumed to run the query now, compared with 31ms of CPU time consumed before creating the indexes, with 100% enhancement as shown below:

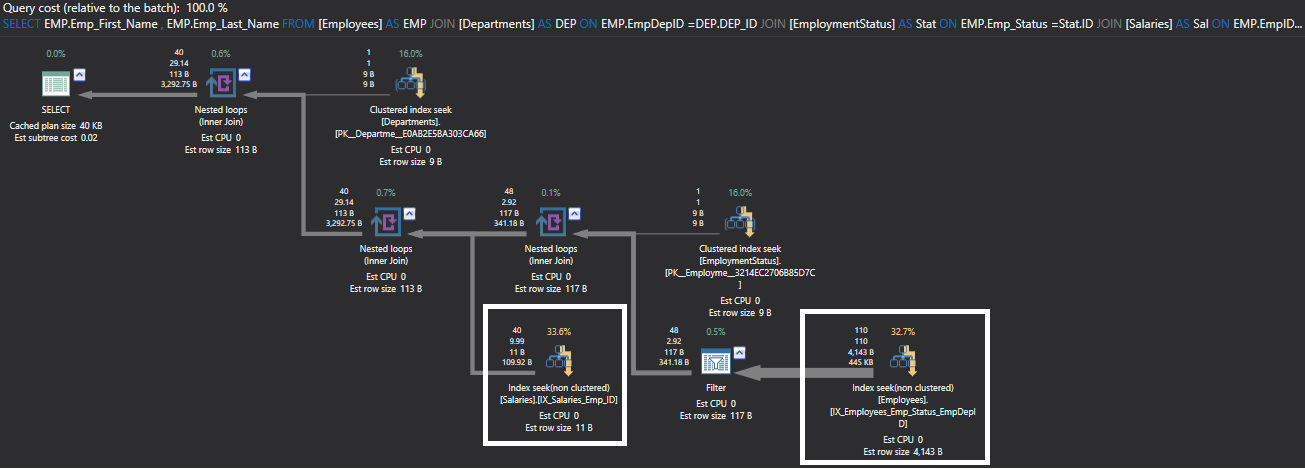
Checking the execution plan that is generated from the previous query after creating the indexes, using ApexSQL Plan. You can clearly see that a much faster index seek process is performed on both the Employees and Salaries tables in order to retrieve the requested data instead of the Clustered Index Scan performed previously, as shown in the execution plan below:
Conclusion
When you define a foreign key constraint in your database table, an index will not be created automatically on the foreign key columns, as in the PRIMARY KEY constraint situation in which a clustered index will be created automatically when defining it. It is highly recommended to create an index on the foreign key columns, to enhance the performance of the joins between the primary and foreign keys, and also reduce the cost of maintaining the relationship between the child and parent tables. Before adding any new indexes, it is better to test on a development environment and monitor the overall performance after the implementation, to make sure that the added indexes improve performance and do not negatively impact the system performance.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021