
In the previous article Commonly used SQL Server Constraints: NOT NULL, UNIQUE and PRIMARY KEY, we described, in detail, the first three types of the SQL Server constraints; NOT NULL, UNIQUE and PRIMARY KEY. In this article, we will discuss the other three constraints; FOREIGN KEY, CHECK and DEFAULT by describing each one briefly and providing practical examples.
FOREIGN KEY Constraint
A Foreign Key is a database key that is used to link two tables together. The FOREIGN KEY constraint identifies the relationships between the database tables by referencing a column, or set of columns, in the Child table that contains the foreign key, to the PRIMARY KEY column or set of columns, in the Parent table.
The relationship between the child and the parent tables is maintained by checking the existence of the child table FOREIGN KEY values in the referenced parent table’s PRIMARY KEY before inserting these values into the child table. In this way, the FOREIGN KEY constraint, in the child table that references the PRIMARY KEY in the parent table, will enforce database referential integrity. Referential integrity ensures that the relationship between the database tables is preserved during the data insertion process. Recall that the PRIMARY KEY constraint guarantees that no NULL or duplicate values for the selected column or columns will be inserted into that table, enforcing the entity integrity for that table. The entity integrity enforced by the PRIMARY KEY and the referential integrity enforced by the FOREIGN KEY together form the key integrity.
The FOREIGN KEY constraint differs from the PRIMARY KEY constraint in that, you can create only one PRIMARY KEY per each table, with the ability to create multiple FOREIGN KEY constraints in each table by referencing multiple parent table. Another difference is that the FOREIGN KEY allows inserting NULL values if there is no NOT NULL constraint defined on this key, but the PRIMARY KEY does not accept NULLs.
The FOREIGN KEY constraint provides you also with the ability to control what action will be taken when the referenced value in the parent table is updated or deleted, using the ON UPDATE and ON DELETE clauses. The supported actions that can be taken when deleting or updating the parent table’s values include:
- NO ACTION: When the ON UPDATE or ON DELETE clauses are set to NO ACTION, the performed update or delete operation in the parent table will fail with an error.
- CASCADE: Setting the ON UPDATE or ON DELETE clauses to CASCADE, the same action performed on the referenced values of the parent table will be reflected to the related values in the child table. For example, if the referenced value is deleted in the parent table, all related rows in the child table are also deleted.
- SET NULL: With this ON UPDATE and ON DELETE clauses option, if the referenced values in the parent table are deleted or modified, all related values in the child table are set to NULL value.
- SET DEFAULT: Using the SET DEFAULT option of the ON UPDATE and ON DELETE clauses specifies that, if the referenced values in the parent table are updated or deleted, the related values in the child table with FOREIGN KEY columns will be set to its default value.
You can add the FOREIGN KEY constraint while defining the column using the CREATE TABLE T-SQL statement, or add it after the table creation using the ALTER TABLE T-SQL statement. We will create two new tables to understand the FOREIGN KEY constraint functionality. The first table will act as the parent table with the ID column defined as a PRIMARY KEY column. The second table will act as the child table, with the ID column defined as the FOREIGN KEY column that references the ID column on the parent table. This can be achieved using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemoParent ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL ) GO CREATE TABLE ConstraintDemoChild ( CID INT PRIMARY KEY, ID INT FOREIGN KEY REFERENCES ConstraintDemoParent(ID) ) |
After creating the two tables, we will insert three records to the parent table, and two records to the child table, using the following INSERT statements:
|
1 2 3 4 5 6 7 8 |
INSERT INTO ConstraintDemoParent ([ID],[NAME]) VALUES (1,'John'),(2,'Mika'),(3,'Sanya') GO INSERT INTO ConstraintDemoChild (CID,ID) VALUES (1,1) GO INSERT INTO ConstraintDemoChild (CID,ID) VALUES (2,4) GO |
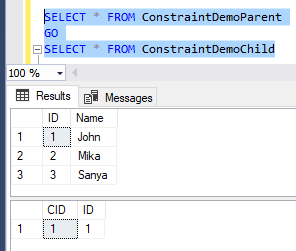
The result will show you that the three records are successfully inserted into the parent table. The first record that we tried to insert into the child table is inserted without any error as the ID value of 1 already exists in the parent table. Trying to insert the second record into the child table will fail because the ID value of 4 doesn’t exist in the parent table, and due to the FOREIGN KEY constraint, you will not be able to insert an ID value to the child table that doesn’t exist in the parent table:

Checking the parent and child tables content, you will see that only one record is inserted into the child table, as you can see below:
As we did not mention the FOREIGN KEY constraint name while creating the child table, SQL Server will assign it a unique name that we can retrieve from the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system view using the following query:
|
1 2 3 4 5 6 7 8 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA , TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME='ConstraintDemoChild' |
The result in our case for the child table is as below:

Then we can easily use the previous result to drop the FOREIGN KEY constraint using the following
ALTER TABEL … DROP CONSTRAINT T-SQL statement:
|
1 2 3 4 |
ALTER TABLE ConstraintDemoChild DROP CONSTRAINT FK__ConstraintDe__ID__0B91BA14; |
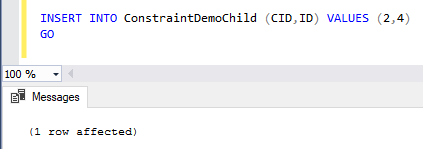
Trying to insert the second record into the child table again, the insert operation will succeed without any error as shown below:
But if we try to create the FOREIGN KEY constraint again on the ID column of the child table, using following ALTER TABLE T-SQL statement:
|
1 2 3 4 5 |
ALTER TABLE ConstraintDemoChild ADD CONSTRAINT FK__ConstraintDe__ID FOREIGN KEY (ID) REFERENCES ConstraintDemoParent(ID); |
The operation will fail, as the ID value of 4 does not exist in the parent table and breaks the referential integrity between the child and parent tables, as seen in the following error message:

To be able to create the FOREIGN KEY constraint in the child table, we have to eliminate that conflict first by deleting or updating that record. Here we will try to modify the ID value with the following UPDATE command:
|
1 2 3 |
UPDATE [dbo].[ConstraintDemoChild] SET ID =2 WHERE ID = 4 |
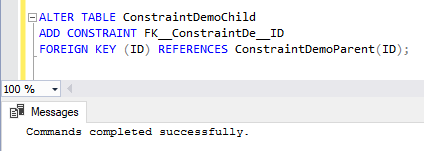
Now the FOREIGN KEY constraint will be created successfully without any error as shown below:
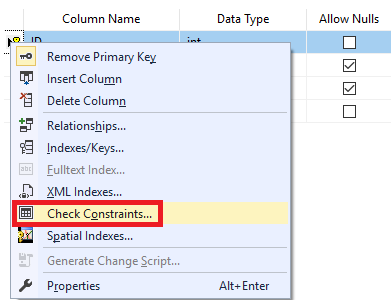
A FOREIGN KEY constraint can be defined with the help of the SQL Server Management Studio tool. Right-click on the required table and select the Design option. When the Design window is displayed right-click on it and choose the Relationships option:
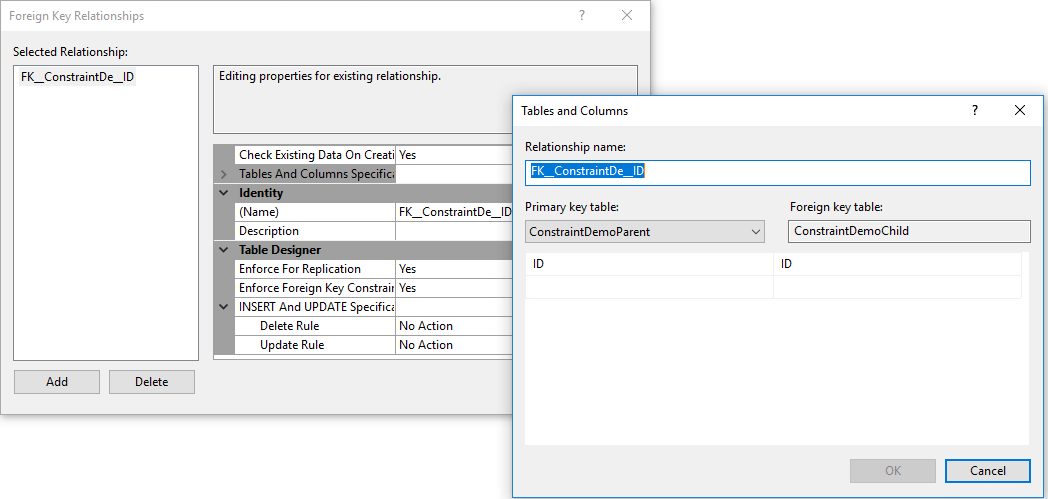
From the displayed window, you can easily specify the name of the FOREIGN KEY constraint, the tables and columns that will participate in that relation, by clicking on the Tables And Columns Specification, if checking the existing data is required, and finally the action performed when the referenced record is deleted or modified on the parent table, as shown below:
CHECK Constraint
A CHECK constraint is defined on a column or set of columns to limit the range of values, that can be inserted into these columns, using a predefined condition. The CHECK constraint comes into action to evaluate the inserted or modified values, where the value that satisfies the condition will be inserted into the table, otherwise, the insert operation will be discarded. It is allowed to specify multiple CHECK constraints for the same column.
Defining the CHECK constraint condition is somehow similar to writing the WHERE clause of a query, using the different comparison operators, such as AND, OR, BETWEEN, IN, LIKE and IS NULL to write its Boolean expression that will return TRUE, FALSE or UNKNOWN. The CHECK constraint will return UNKNOWN value when a NULL value is present in the condition. The CHECK constraint is used mainly to enforce the domain integrity by limiting the inserted values to the ones that follow the defined values, range or format rules.
Let us create a new simple table that has three columns; the ID column that is considered as the PRIMARY KEY of that table, Name, and Salary. A CHECK constraint is defined on the Salary column to make sure that no zero or negative values are inserted into that column. The CHECK constraint is defined within CREATE TABLE T-SQL statement below:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE ConstraintDemo4 ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL, Salary INT CHECK (Salary>0) ) GO |
If you execute the below three INSERT statements:
|
1 2 3 4 5 6 7 8 |
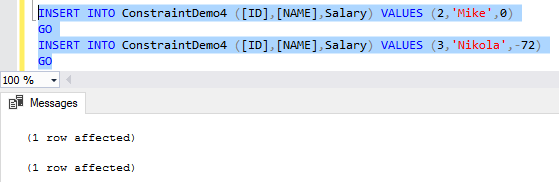
INSERT INTO ConstraintDemo4 ([ID],[NAME],Salary) VALUES (1,'John',350) GO INSERT INTO ConstraintDemo4 ([ID],[NAME],Salary) VALUES (2,'Mike',0) GO INSERT INTO ConstraintDemo4 ([ID],[NAME],Salary) VALUES (3,'Nikola',-72) GO |
It is clear from the generated result that the first record is inserted with no error as the provided Salary value meets the checking condition. The second and third INSERT statements will fail, as the provided Salary values do not meet the CHECK constraint condition due to inserting zero and negative Salary values, as you can see in the following error message:

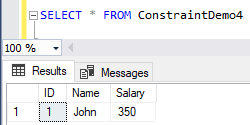
Checking the table’s data shows you that only the first row that passed the CHECK constraint condition will be inserted to the table as below:
We mentioned earlier in this article that the CHECK constraint allows inserting NULL values if the participated columns allow NULL, and the NULL values will be evaluated as UNKNOWN without throwing any error. This is clear from the below record that is inserted successfully, although the provided value of the Salary column is NULL:

If you review the CHECK constraint definition in the previous CREATE TABLE statement, you will see that we have not mentioned the name of the defined constraint. In this case, SQL Server will assign a unique name for that constraint that can be shown by querying the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system view for the ConstraintDemo4 table. The result will be as shown below:

The CHECK constraint can be dropped using the ALTER TABLE T-SQL statement. Using the CHCEK constraint name we got previously, the below command can be used to drop the CHECK constraint on the ConstraintDemo4 table:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo4 DROP CONSTRAINT CK__Constrain__Salar__0F624AF8; |
Once the CHECK constraint is dropped, the failed two INSERT statement will be executed successfully without any error, as there is no restriction on the inserted Salary values, as follows:
But if you try to define the CHECK constraint now, with the following ALTER DATABASE … ADD CONSTRAINT T-SQL statement:
|
1 2 3 4 5 |
ALTER TABLE ConstraintDemo4 ADD CONSTRAINT CK__Constrain__Salar CHECK (Salary>0); |
Adding the CHECK constraint will fail. This is due to the fact that, while the SQL Server is checking the already existing data for the CHECK constraint condition, one or more values that do not meet the constraint condition are found, as you can see in the following error message:

To be able to define the CHECK constraint again, we should modify or delete the data that prevents the constraint from being created. We will try modifying the Salary amount of the two records that break the constraint condition to a valid positive value, as in the following UPDATE statement:
|
1 2 3 |
UPDATE ConstraintDemo4 SET Salary =300 WHERE ID IN (2,3) |
Now, the CHECK constraint can be defined with no issue as shown below:
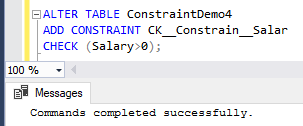
SQL Server allows you to disable the CHECK constraint for special cases, such as inserting huge amount of data without caring about meeting the constraint condition for testing purposes, or due to changing in the business logic. This case is valid only for the CHECK and FOREIGN KEY constraints that you can disable temporarily. Disabling the previously defined CHECK constraint can be achieved using the ALTER TABLE T-SQL command below:
|
1 2 3 |
ALTER TABLE ConstraintDemo4 NOCHECK CONSTRAINT CK__Constrain__Salar |
Trying to insert a negative Salary value will not fail, as there is no validation check performed on that column, as shown below:
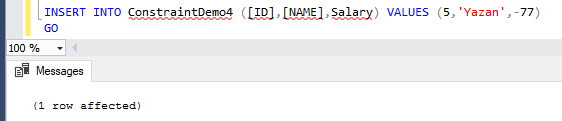
You can also disable all the table constraints using one command by providing the ALTER TABLE … NOCHECK CONSTRAINT command with ALL instead of the writing the constraint name, as in the T-SQL command below:
|
1 2 3 |
ALTER TABLE ConstraintDemo4 NOCHECK CONSTRAINT ALL |
From the CHECK constraint definition, you can specify that the constraint will be created without checking existing rows, but the constraint will be marked as not trusted. Let us check the table data first, that shows two breaking values:
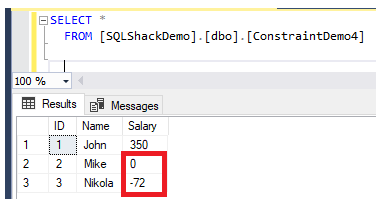
If you try to drop the CHECK constraint and create it again using the NOCHECK option, you will see that the constraint is created without checking the existing data, as shown below:
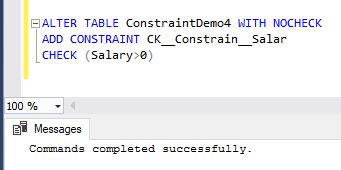
But at the same time, it will not allow you to insert any data that breaks the constraint condition, as you can clearly see in the error message below:
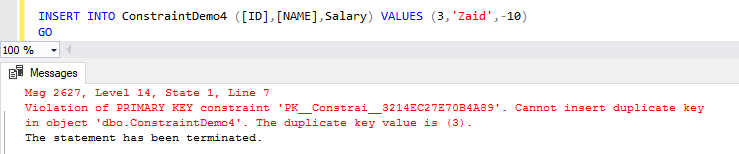
To enable the CHECK constraint again, you can use the ALTER TABLE T-SQL command, but this time using CHECK CONSTRAINT statement as in the script below:
|
1 2 3 |
ALTER TABLE ConstraintDemo4 CHECK CONSTRAINT CK__Constrain__Salar |
In addition, you can enable all CHECK constraints, all at once,using the T-SQL command below:
|
1 2 3 |
ALTER TABLE ConstraintDemo4 CHECK CONSTRAINT ALL |
While enabling the previous CHECK constraint, you will see that SQL Server will not complain about the unchecked data that breaks the constraint condition. In this case, domain integrity of the data is not maintained.
To fix this issue, the DBCC CHECKCONSTRAINTS command can be easily used to identify the data that violates the constraint condition in a specified table or constraint, taking into consideration not to run that command in the peak hours, as it will affect the SQL Server performance due to not utilizing a database snapshot.
Let us use the DBCC CHECKCONSTRAINTS command to check the data that does not meet the condition of the ConstraintDemo4 table’s constraint
|
1 2 3 |
DBCC CHECKCONSTRAINTS(ConstraintDemo4) |
The result will show you the two Salary values that break the CHECK constraint condition, as shown below:
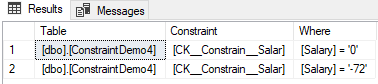
A CHECK constraint can be also created with the help of the SQL Server Management Studio tool, by right-clicking on the required table and selecting the Design option. From the displayed Design window, right-click and choose Check Constraints option as follows:
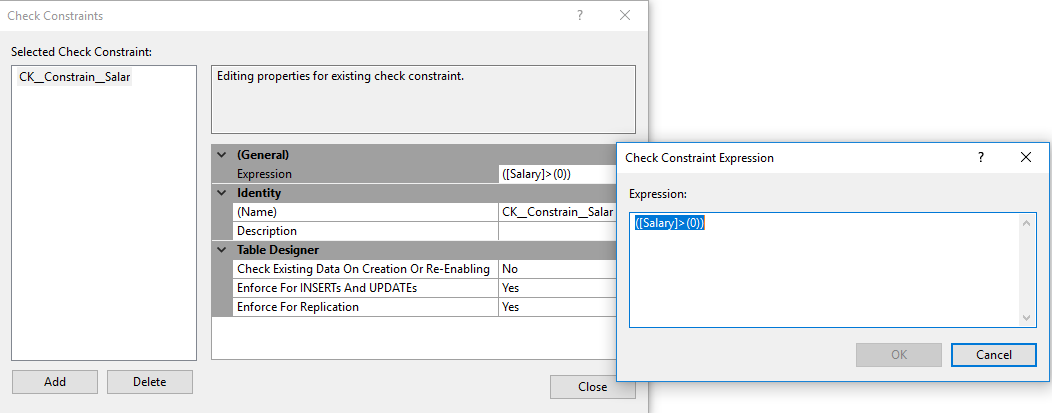
From the Check Constraints window, you can specify the CHECK constraint name, expression and if checking the existing data is required, as shown below:
DEFAULT Constraint
A DEFAULT constraint is used to provide a default column value for the inserted rows if no value is specified for that column in the INSERT statement. The Default constraint helps in maintaining the domain integrity by providing proper values for the column, in case the user does not provide a value for it. The default value can be a constant value, a system function value or NULL.
In the below CREATE TABLE statement for a simple table with three columns, a DEFAULT constraint is defined on the EmployeeDate column, that assigns the GETDATE() system function value for that column in case we miss specifying it in the INSERT statement:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE ConstraintDemo5 ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL, EmployeeDate DATETIME NOT NULL DEFAULT GETDATE() ) GO |
If we execute the two INSERT statements below:
|
1 2 3 4 5 6 |
INSERT INTO ConstraintDemo5 ([ID],[NAME],EmployeeDate) VALUES (1,'Lorance','2016/10/22') GO INSERT INTO ConstraintDemo5 ([ID],[NAME]) VALUES (2,'Shady') GO |
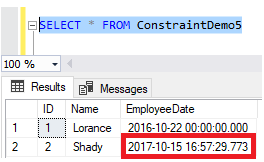
And check the inserted records, you will see that the EmployeeDate column value for the second record, that we did not mention in the INSERT statement, is assigned to the current date and time value as shown below:
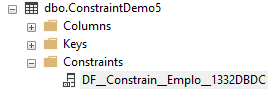
Expanding the Constraints node under the current table will show us the created DEFAULT constraint name, recalling that SQL Server will assign a unique name for it if we do not provide a name for it, as shown below:
The DEFAULT constraint can be easily dropped using the ALTER TABLE … DROP CONSTRAINT T-SQL command below:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo5 DROP CONSTRAINT DF__Constrain__Emplo__1332DBDC; |
And created using the ALTER TABLE …ADD CONSTRAINT T-SQL command below:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo5 Add Constraint DF__Constrain__Emplo DEFAULT (GETDATE()) FOR EmployeeDate |
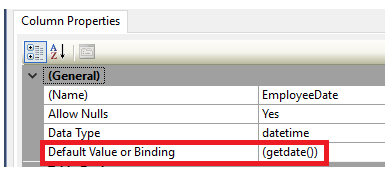
Also, the DEFAULT constraint can be defined using the SQL Server Management Studio, by right-clicking on the required table and choose Design option. Then select the column that you will assign a default value for by browsing the Column Properties window as shown below:
I hoped that this article, and the previous, have helped to explain the six SQL Server constraint types. Please feel free to ask any questions in the comments below.
The previous article in this series:
Useful links

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021