
SELECT with WHERE on a clustered index
To narrow down the number of rows returned by the query, we will add the WHERE clause with a condition for the table clustered index.
|
1 2 3 4 5 |
SELECT * FROM Person.Address where AddressID = 7 |
The SQL Server query execution plan now contains the Clustered index seek.
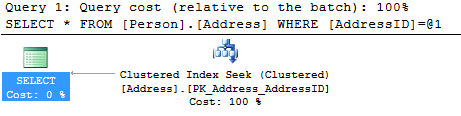
As its tooltip explains, the database engine scans a particular range of rows from the clustered index. It seeks for the clustered index, not scans for it, therefore we can expect lower query cost. The engine searches for the specific key values and can quickly find them, as the clustered index also sorts the data so the search is more efficient. Finding the right record in such ordered tables is quick and resource inexpensive, which is clearly shown by the cost numbers.
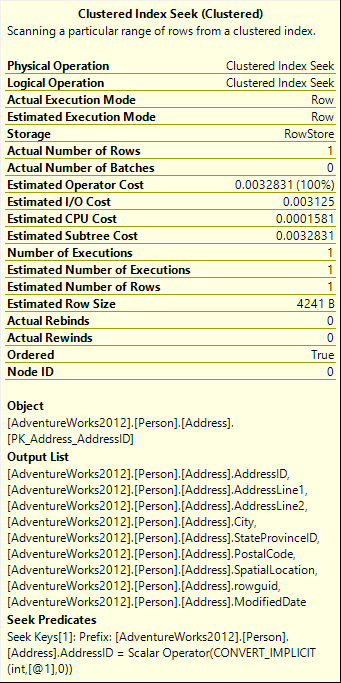
If you now compare the estimated operator, I/O, and CPU costs with the costs for the same query without WHERE, you can notice that the values when the WHERE clause is used are smaller by two orders of magnitude
SELECT with WHERE on a nonclustered index
A similar example is to use the WHERE clause with the condition on the column other than the clustered index, for example on a unique nonclustered index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE UNIQUE NONCLUSTERED INDEX [IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode] ON [Person].[Address] ( [AddressLine1] ASC, [AddressLine2] ASC, [City] ASC, [StateProvinceID] ASC, [PostalCode] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO SELECT * FROM Person.Address where City = 'New York' |
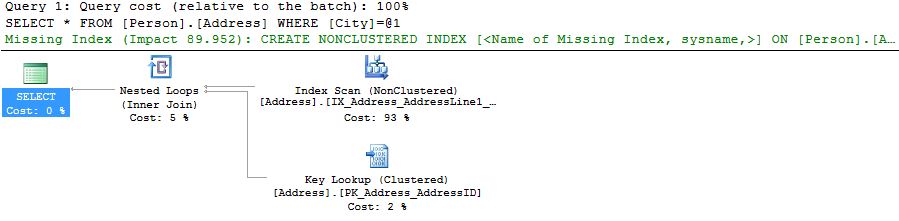
Now, there are both the Nonclustered Index Scan and Key Lookup. Keep in mind that the query execution plans are read right to left, top to bottom. Therefore, the first operator here is the NonClustered Index Scan.
The query execution plans displays the “Missing index (Impact 89.952): CREATE NONCLUSTERED INDEX [<Name Of Missing Index, sysname,>] ON [Person].Address]([City]) message
This is not an error, or warning, you should consider this message as an advice what you can do to improve the query execution performance by almost 90%. To see the recommended index, right-click the plan and select the Missing Index details option.
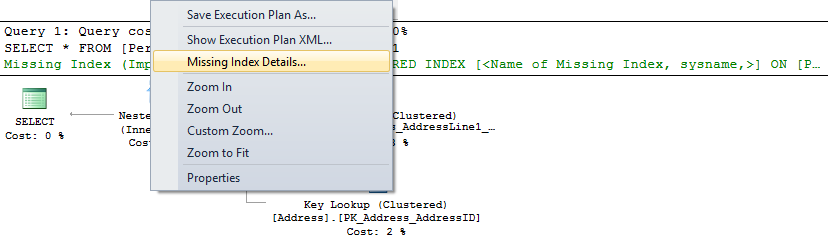
The option returns the index details along with T-SQL for creating it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* Missing Index Details from SELECT Address4.sql - FUJITSU\SQL2012.AdventureWorks2012 (sa (56)) The Query Processor estimates that implementing the following index could improve the query cost by 89.952%. */ /* USE [AdventureWorks2012] GO CREATE NONCLUSTERED INDEX [<name of missing index, sysname,>] ON [Person].[Address] ([City]) GO */ |
All you have to do is enter the index name, remove the comments, and execute code

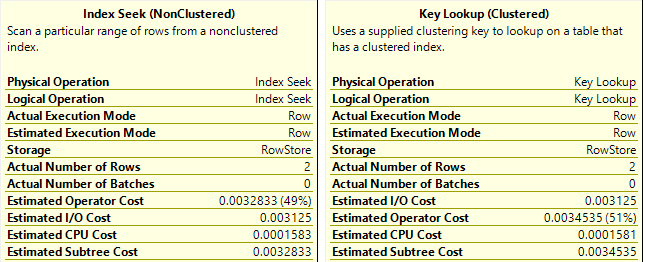
As you can see, the operators are the same, but there’s no warning anymore and the cost is distributed almost equally between the Index Seek and Key Lookup. While the Key Lookup cost stayed the same, the Index Seek cost is significantly reduced.
However, it’s highly recommended not to create all indexes that are reported as missing by Query Optimizer in the query execution plans. Keep in mind that it’s only a recommendation for the specific plan and that it doesn’t mean that the whole system and workload would benefit from the index. As indexing has benefits as well as downsides, it’s necessary to determine whether this index will really improve overall performance. There are several factors you should consider when determining necessity of the index. The first one is how often the query is executed.
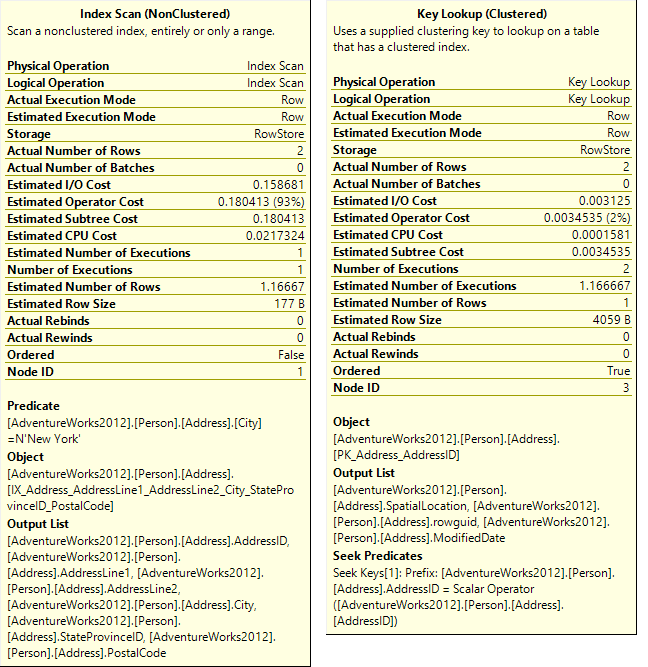
The Index Scan output list shows only some of the table columns. These are the columns specified in the IX_Address_AddressLine1_AddressLine2_City_StateProvinceID_PostalCode index: AddressLine1, AddressLine2, City,StateProvinceID, and PostalCode. The clustered index and primary key column AddressID is always returned. The SELECT statement executed must return all table columns. The rest of the columns are read by the Key Lookup operator. The key value AddressID is used in the Key Lookup. As shown, the Key Lookup returns the rest of the Person.Address columns
A Key Lookup indicates that obtaining all records is done in two steps. To return all records in a single step, all needed columns should be returned by the Index Scan.
The simplest solution is to specify the list of columns returned by the Index Scan.
|
1 2 3 4 5 |
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode FROM Person.Address WHERE City = 'New York' |

Whenever there is a Key Lookup operator, it’s followed by the Nested Loops which is actually a JOIN operator which combines the data returned by the Index Seek and Key Lookup operators. As shown in the tooltips, the Index Seek is performed only once (Number of executions = 1) and it returns 16 rows (Actual number of rows). The Key Lookup operator uses the 16 rows returned by the Index Seek and looks up for the records in the table. A lookup is performed for every row returned by the Index Seek, in this example 16 times, which is presented by the Key Lookup Number of executions.
For a small number of rows returned by Index Seek, this means a small number of executions by the Key Lookup. When the Key Lookup output is indexed, the time needed to perform a lookup is shorter, so this is a scenario with a small cost. In case the Index Seek provides all output columns, the Key Lookup is not needed as no additional columns should be retrieved, and the Nested Loops is not needed as there are no data sets to combine.
The SQL Server query execution plans can be complex and difficult to read and understand, as same code can be executed using different operators. As shown, the query execution plan structure depends on the query executed, table structure, indexing, and more. In this article, we focused on the table indexing and two basic query statements: SELECT and WHERE. We showed how a column list in the SELECT statement and WHERE condition on various columns in a table can significantly affect query execution and its performance.

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014