
Query Optimizer is a SQL Server component that creates query execution plans based on the database objects used, indexes, joins, number of output columns, etc. The plans are represented graphically where each operator is represented with an icon
In this article, we will show a series of examples for basic T-SQL queries, explain the SQL Server query execution plan, and its components for each example. We will show why indexing is important and how it affects the query execution plan structure and cost
Clustered and nonclustered indexes
Indexes are used to enable faster access to table and view records. When executing a SELECT statement against a table without indexes, SQL Server has to read all records, one by one, to find the records requested by the statement. Thanks to indexes, SQL Server can easily find the rows associated to the key values, therefore doesn’t have to read every table row and the data obtaining process is more efficient
Indexes can be built on one or more table or view columns. A nonclustered index contains a pointer to the data row that contains the key value. A clustered index stores and sorts the data based on the key values. Searching for a specific value in a clustered table (a table with a clustered key) is easy like searching for a name in an alphabetically ordered address book. When there is no clustered index on the table, the data is unordered and searching for a specific value requires more time and resources
One of the disadvantages of using indexes is that the table indexes are automatically updated whenever table data is changed (inserted, deleted, updated), thus increasing performance costs. Another cost is that more disk space is used
A table can have only one clustered index and multiple nonclustered ones. The logical explanation for this is that a clustered index sorts the data by the index value, and the data in the table can be sorted only in one order
SELECT * on a table with a clustered index
In the first example, we’ll use the Person.Address table in the AdventureWorks database. Note that the table has a clustered index created on the AddressID column and a nonclustered key on the StateProvinceID column
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE TABLE [Person].[Address]( [AddressID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AddressLine1] [nvarchar](60) NOT NULL, [AddressLine2] [nvarchar](60) NULL, [City] [nvarchar](30) NOT NULL, [StateProvinceID] [int] NOT NULL, [PostalCode] [nvarchar](15) NOT NULL, [SpatialLocation] [geography] NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Address_AddressID] PRIMARY KEY CLUSTERED ( [AddressID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] CREATE NONCLUSTERED INDEX [IX_Address_StateProvinceID] ON [Person].[Address] ( [StateProvinceID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO |
We’ll analyze the query execution plan for the following statement:
|
1 2 3 4 |
SELECT * FROM Person.Address |
The estimated and actual SQL Server query execution plans are identical. As the query is simple, there’s no doubt how it will be executed

As the query execution plans are read from right to left, we’ll start with the Clustered Index Scan and it takes 100% of the whole execution plan time. The Select icon represents execution of the SELECT statement, and as shown in the plan, its cost is 0%
Table and index scans should be avoided as they are resource expensive and require more time. Having a seek operator in the query execution plan is preferred over scan. As the scan operator reads every row, its cost is proportional to the number of table rows. The seek operator does not read all records, just the specific ones that correspond to the query condition. Whenever possible, use a list of columns in the SELECT statement and a WHERE clause to narrow down the rows and columns returned by the query
The Clustered Index Scan tooltip shows the operator details
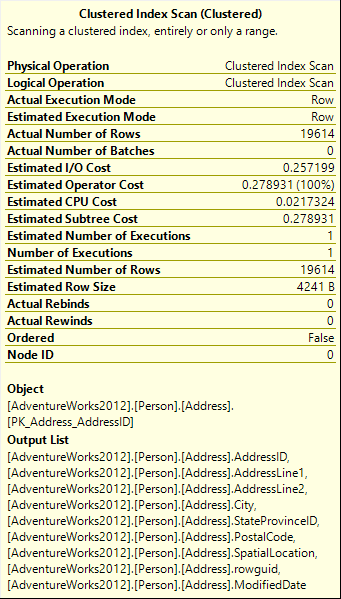
Although the estimated cost values have no units, it’s the estimated time in seconds, needed to execute the analyzed query. The cost is calculated by Query Optimizer. These values are compared to the costs calculated for alternative plans, and the lowest cost plan is shown as the optimal one
As said, the Person.Address table has the PK_Address_AddressID clustered index created on the primary key. When SELECT is executed on a table with a clustered index, the table is scanned in order to find the needed records. The Object in the clustered index scan tooltip is PK_Address_AddressID, which means that it’s used to scan the table rows. As all columns are returned, and the WHERE clause is not used, the database engine must scan all index values
The number of rows returned by the query is 19,614, which is shown as the Actual Number of rows. The Output List shows all Person.Address table columns, as these are the columns returned by the query
SELECT <column list> on a table with a clustered index
In this example, we will use a list of columns in the SELECT statement, instead of SELECT *
|
1 2 3 4 |
SELECT AddressID, AddressLine1, AddressLine2 FROM Person.Address |
The SQL Server query execution plan is similar to the one in the previous example. The difference is that now, a NonClustered Index Scan is used

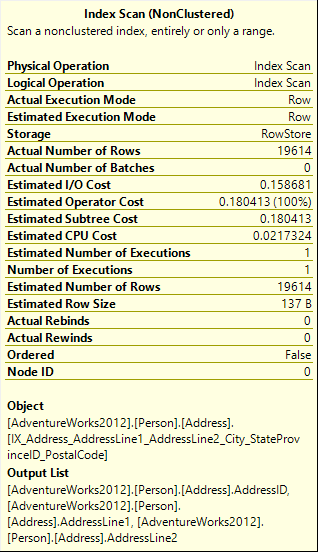
Note the shorter Output List and up to 50% lower estimated cost values
SELECT * on a table with no clustered indexes
In this example, we’ll show how the SELECT statement is executed on a table without a clustered index. For this example, we created a copy of the Person.Address table, and removed all indexes except the non-clustered index on the StateProvinceID column. The records in the Address and Address1 tables are identical, so we can use the estimated costs for comparison
Execute the following SELECT statement
|
1 2 3 4 |
SELECT * FROM Person.Address1 |
The actual and estimated query execution plans are again identical
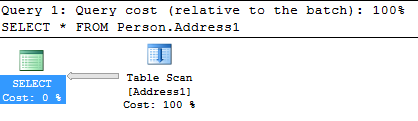
Unlike in the previous example, there is the Table Scan icon now shown instead of the Clustered Index Scan. The difference in the query execution plan operators is caused by having a non-clustered index instead of a clustered one
When all rows from a table are returned (a SELECT statement without a WHERE clause) and no clustered index is created on the table, the engine has to go through the whole table, scanning row after row
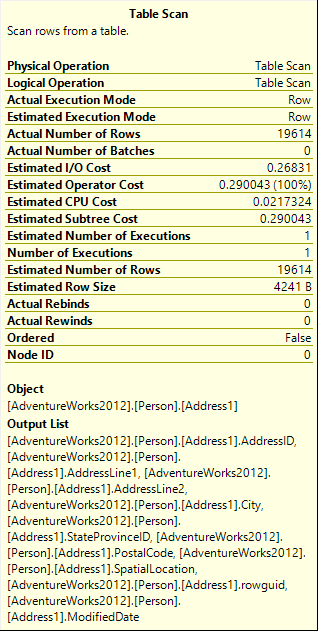
When the number of records in the table is not large, the complete table scan doesn’t require too much time. If you compare the estimates costs for Address1 and Address tables, there is only a slight difference. If we created the same test on a table that contains millions of records, the difference would be significant
In all real-world scenarios, it’s highly recommended to use the WHERE clause and qualify the columns you want to select, instead of using the * wildcard
In this article we explained why indexing is important and how clustered and nonclustered indexes can affect query execution. We showed the simplest T-SQL examples and query execution plans created for them. In the next part of this article, we will present more T-SQL examples in order to explain the difference clustered and nonclustered indexes make when it comes to execution operators and cost

She has been working with SQL Server since 2005 and has experience with SQL 2000 through SQL 2014.
Her favorite SQL Server topics are SQL Server disaster recovery, auditing, and performance monitoring.
View all posts by Milena "Millie" Petrovic
- Using custom reports to improve performance reporting in SQL Server 2014 – running and modifying the reports - September 12, 2014
- Using custom reports to improve performance reporting in SQL Server 2014 – the basics - September 8, 2014
- Performance Dashboard Reports in SQL Server 2014 - July 29, 2014