
In the world of SSIS development architecture, preference should be given to extracting data from flat files instead of non-Microsoft relational databases. This is because you often don’t have to worry about driver support and compatibility issues in your SSIS development/server machine that is often attributed to non-Microsoft database vendors. In fact, I’ve been in several situations whereby we cannot upgrade to another version of SSIS (i.e. BIDS to SSDT) due to the lack of external vendor driver compatibility issues in the newer versions of SSIS.
Although preference should be given to importing flat files, it must be noted that wherever possible, the desired flat format should be delimited. This is because properly delimited files reduce time spent on column mapping configuration as SSIS is able to detect row and column delimiters. You may not realise the benefit of having SSIS automatically do column mappings for you until you are sitting with a fixed width dataset that you have to manually break down into 100+ output columns. Figure 1 illustrates a perfect world scenario of a fictitious Fruit Sales transaction file that has rows separated by carriage return/line feed and columns delimited by a vertical bar (also known as Pipe).
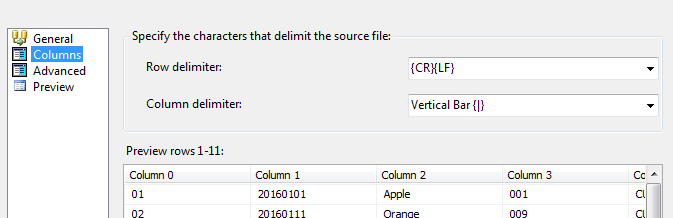
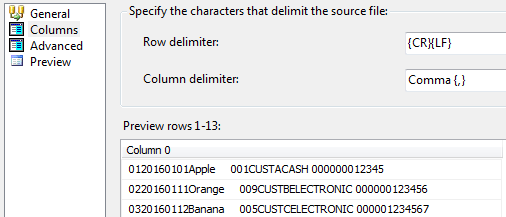
Unfortunately, as ETL developers, we often have to extract data from an imperfect world which has flat files formatted in all sorts of ways. Figure 2 illustrates another representation of our fictitious Fruits sales dataset with SSIS unable to detect column delimiters. Whenever you encounter such files, you are limited to two more options in SSIS and that is either you treat them as Fixed Width formatted or Ragged Right formatted. The aim of this article is to explore different ways of working with the latter formatting option, Ragged Right.
Defining Ragged Right Format
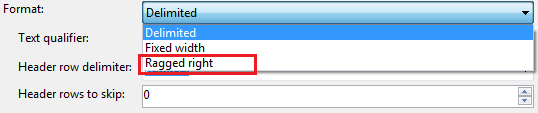
Whether you are importing flat files using SQL Server Integration Services (SSIS) or SQL Server Management Studio (SSMS), the Ragged right option in the Format drop-down box in both tools, can be found at the bottom of the list as shown in Figure 3. This shouldn’t be mistaken as the preferred order of file format rather is nothing more than an alphabetical list of available file format. In fact, I strongly believe that Ragged right option is actually a hybrid between Delimited and Fixed width formats. Unlike delimited files, where both column and row delimiters are required, in Ragged right format only row delimiters are auto-detected with the content of the rows stored within a single column. Should you want to break the row into several columns, then you have to manually specify column limit. This is contrary to Fixed width format where you should not only specify column limits but row delimiters too.
Configuring Columns
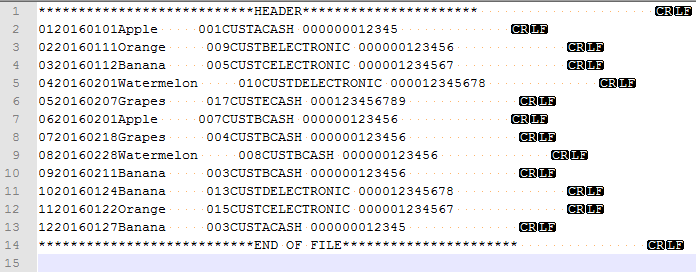
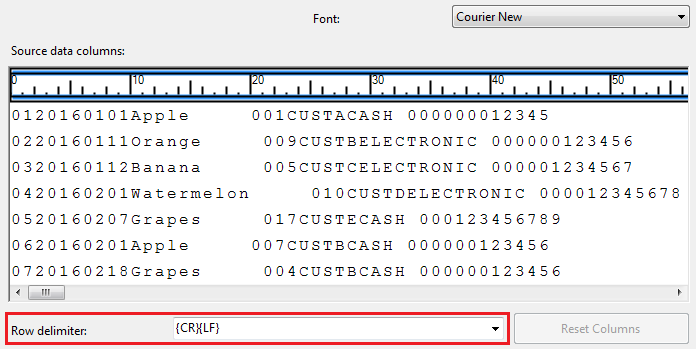
The configuration of columns is perhaps a critical part of the entire ETL process as it helps us build mapping metadata for your ETL. In fact, regardless of where or not SSIS/SSMS can detect delimiters, if you skip Column Mapping section – your ETL will fail validation. In order to clarify how Ragged right formatted files work, I have gone a step back and used Figure 4 to actually displayed a preview of our fictitious Fruits transaction dataset from Notepad++. It can already be seen from Notepad++ that the file only has row delimiter in a form of CRLF.
When the file shown in Figure 4 is imported into SSIS, it looks as shown in Figure 5 and immediately the row delimiter is automatically detected.
At this point, we can deal with column configuration in one of two ways:
Single Column Mapping
Single column mapping is available by default when working with Ragged right format. This default mapping is the simplest yet most error prone. It is simpler because you don’t have to spend time breaking down data rows into two or more columns. However, such an approach usually result into a Text truncation error similarly to the one shown in Figure 6.

Figure 6: Text Truncation Error Text truncation error is one of the common errors you are likely to come across when importing files. It doesn’t matter whether you are dealing with Delimiter, Fixed width or Ragged Right delimited files. In flat files, column length is never dynamic, which means that when you previously configured your connection in such a way that [Column 0] has a length of 5 but you later load a file with a length of 6, you will run into a truncation error.
The easiest way to avoid truncation issues is by adding fat to your column length (i.e. if you know the length of your given column is 75 make it into a 100).
Another disadvantage of mapping all rows against a single column is that in order to break down row values into several columns, you will have to conduct additional transformation (either within SSIS using transformation tasks or in SQL Server database using T-SQL).
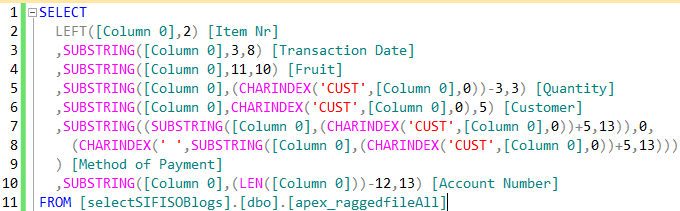
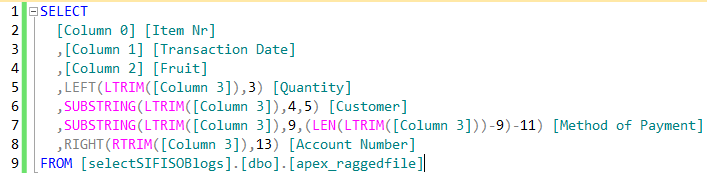
For instance, the script in Figure 7 shows several T-SQL substring logic that was used to break values from single column ([Column 0]) into separate columns.
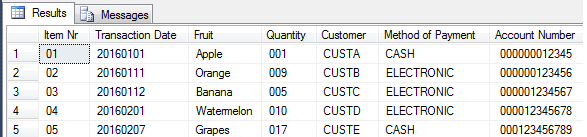
Figure 7: Single Column T-SQL Transformation The results of execution of the script in Figure 7 are shown in Figure 8.
Figure 8: Execution Result of Single Column T-SQL Transformation Script Multiple Column Mappings
An alternative to single column mapping is to use markers to specify several column limits. For instance, looking at our fictitious dataset given in Figure 4, we can guess several column headings. Thus, at the beginning of every row, the first two characters look like item numbers; while next 6 characters look like a transaction date followed by what looks like fruit names.
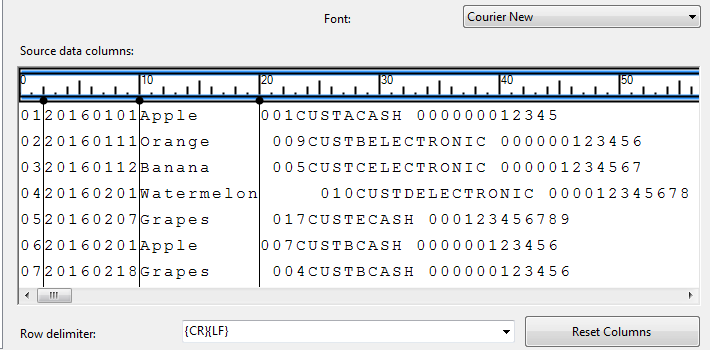
The rest of the column limit look as shown in Figure 9.
Figure 9: Multiple Column Limit The biggest benefit of attempting to specify column limit is that when it comes to data transformation, we have less data manipulation to do compared to single column mapping. Figure 10 shows that we didn’t have to manipulate the first three columns because we knew what they represented instead we focused on splitting data from [Column 3].
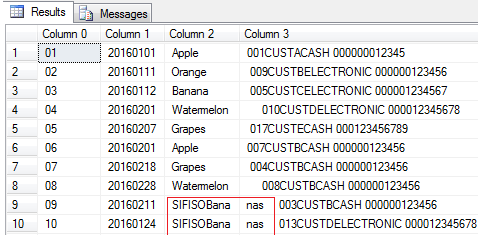
Figure 10: Multiple Column Limit Data Transformation Just like single column mapping, specifying column limit has its own shortcomings. For instance, if the length of values that are mapped against [Column 2]) suddenly increases, some of those values will be carried over to next columns (should there be no subsequent columns, truncation error will be raised). Figure 11 shows a revised fictitious dataset with Banana fruit names in rows 9-10 renamed to SIFISOBananas. Unlike before, [Column 2] is now unable to store the extended fruit name thereby causing a split on the fruit name with the last three characters (i.e. nas) being stored in [Column 3].
Figure 11: Increased Length of Expected Value

Conclusion
In this article we established that we are often not presented with well formatted flat files. Instead, we have to deal with Ragged right formatted flat files. We identified several ways of dealing with column configurations in Ragged right format, namely that row data could either be mapped against a single column or across multiple columns.
Download article scripts/demo material here
Reference:

Sifiso's LinkedIn profile
View all posts by Sifiso W. Ndlovu