
SQL Server replication is a relatively old high-availability solution part of the Microsoft world. In fact, there have not been any significant changes to this solution in the recent versions SQL versions, but it is still a widespread mechanism for distributing objects from one database to another and synchronize them. Replication is very useful when you have remote and mobile users accessing your data. Let’s cut to the chase and give you more details about our specific case. 🙂
Our environment
Replication setup, that I am going to describe briefly, is a bit complex. We are using transactional type replications with two publisher instances and three subscriber instances. One of the busiest subscribers, holding five subscriptions, has been acting as a distributor as well. This has been the situation in the last years, but as the time goes and more and more data has been sending back and forth as part of the replication, the latency has been increasing and the IO subsystem was not able to serve us at the expected levels anymore. Our subscribers have been always in catching up situation with the publishers and the performance delay has already been below the critical limit. Problems with our high-availability solution has been resulting in:
- Old reporting data on the subscribers
- The permanent issue with the free space for the drive of the Distribution database as it has been holding the undistributed commands
- A long conference calls with the stakeholders
In addition to this, our transactional replication has been setup in a way, that DELETE commands are not being propagated to the subscribers which means that we have a lot more data there than on the publishers:
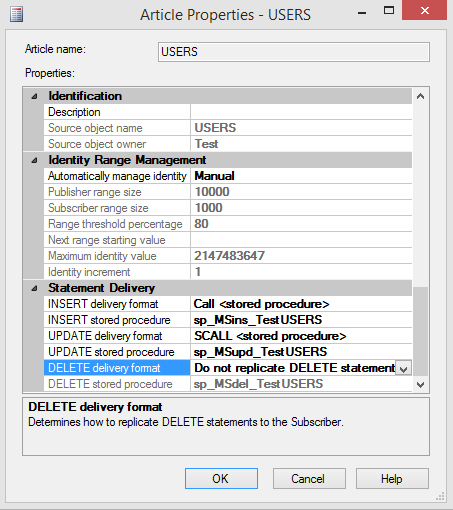
Due to this scenario, we are not able just to reinitialize the subscriptions if there are major problems with them or they just fall badly behind.
Proposed Solution
The cure to our situation was probably the very obvious choice to build a new SQL Server, include it in the replication topology and dedicate it to be acting solely as a distributor. The new high-availability schema would be: two publisher instances, three subscriber instances and one distributor instance. Luckily, we managed to convince all the important people involved, that this is the right solution for us and it has been approved. Next step, the actual work
Actual movement of the Distribution database
Initially this seemed like a piece of cake, but as we were going deeper and deeper into particular details, part of the implementation plan, this was not the case. We have read and tried literally tons of articles that we managed to find about moving the distribution database, but they were not working for us due to some reasons – either the posts were not described thoroughly enough and important details are missing or they were intended for more simple scenarios.
After countless numbers of tests, here are the particular steps, we have taken and worked for us:
On Publication server:
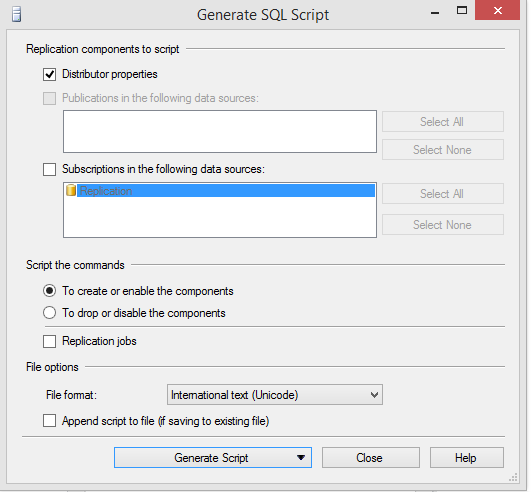
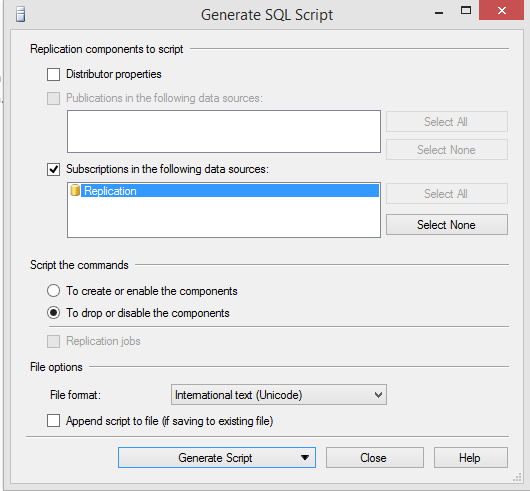
Script create plus distribution properties for the publication (Generate Script➜Save to File)

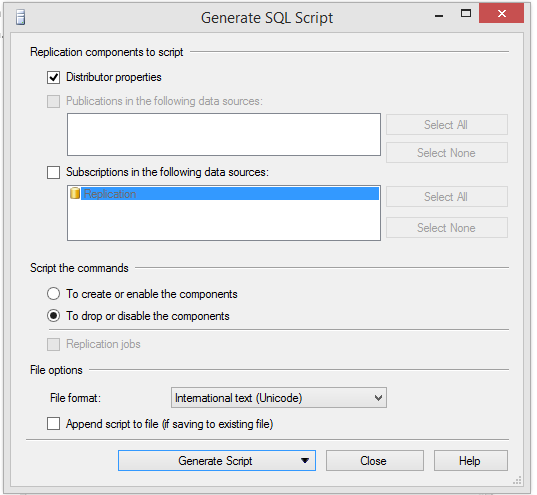
Script drop publication without distribution properties (Generate Script➜Save to File)
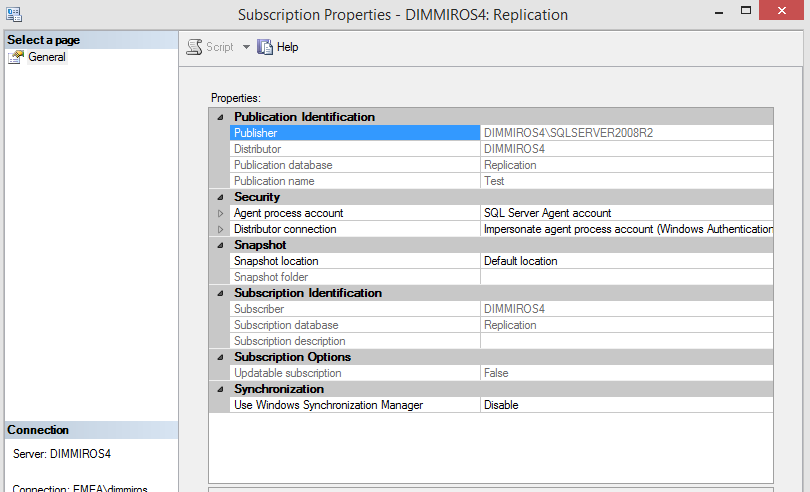
From the publications, check the subscriptions’ properties for all subscriptions (accounts being used by the replication), if it is a push subscription. If it is a pull subscription you have to check the properties for the subscriptions from the publisher (to see that it is a pull subscription) and from the subscriber to see the accounts:
Capture from the Publisher
Capture from the Subscriber
From the Distributor, script its properties:
Create distributor without the Subscriber Properties:
Drop distributor without the Subscriber Properties:
From all subscribers:
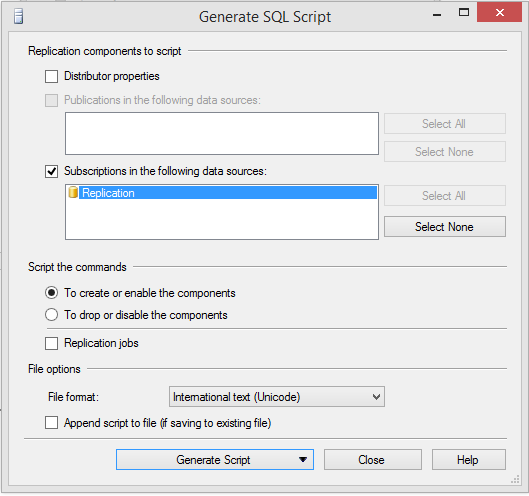
Script create the subscription without Distribution properties:
Script drop the subscription without Distribution properties:
- Drop all publications with the scripts generated from Step 1 (Run them from the respective publishers)
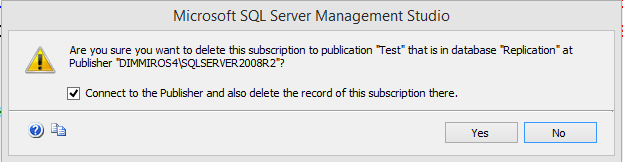
Drop all subscriptions with the scripts generated from Step 4 – you have to use only the parts to be run on the Subscribers. Another option is to Delete them via the GUI – right click on every subscriber and then click “Yes” (you will need to do it twice):
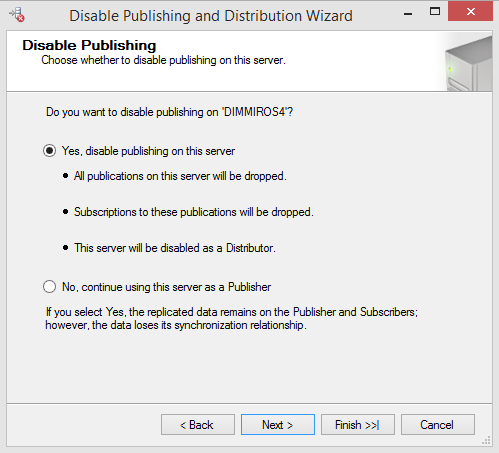
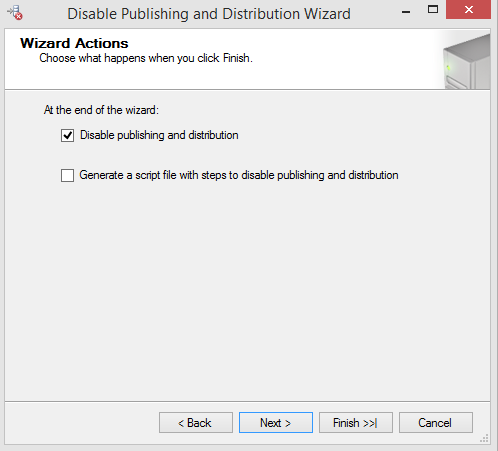
From the Distributor, go to Replication➜Right Click➜Disable Publishing and Distribution:
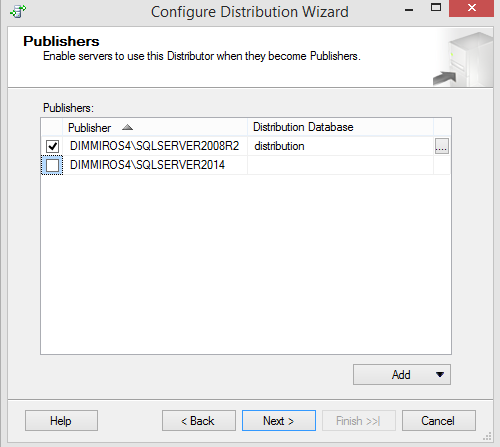
Configure the new Distributor, with enabling the Publisher (local/remote):
- Replication➜Configure Distribution
- Choose the server will act as its own distributor
- Snapshot Folder
On the Publisher page, remove the Default (local) Publisher and add the remote one (if needed):
- Enter a password that will be used for the connection (it is a new pass)
- Make sure Configure Distribution is selected
Use the scripts from Step 1 to create the publications on the respective servers. You need to change the beginning of the scripts with the name of the new Distributor and the password entered in the previous step:
12345678910111213/****** Begin: Script to be run on Publisher ******//****** Installing the server as a Distributor ******/USE masterEXEC sp_adddistributor @distributor = N'DIMMIROS4', @password = N'new_pass'GOEXEC sp_addsubscriber @subscriber = N'DIMMIROS4', @type = 0, @description = N''GO/****** End: Script to be run on Publisher ******/Use the scripts from Step 4 to create the Subscriptions – part of the script should be run on the Subscriber and the other part on the Publisher (the other option is to create the Subscriptions from the Replication wizard on every Subscriber):
- Choose the Publisher
- Choose the Publication
- Choose Push or Pull
- Choose subscription database
- Choose the security
- Choose the schedule
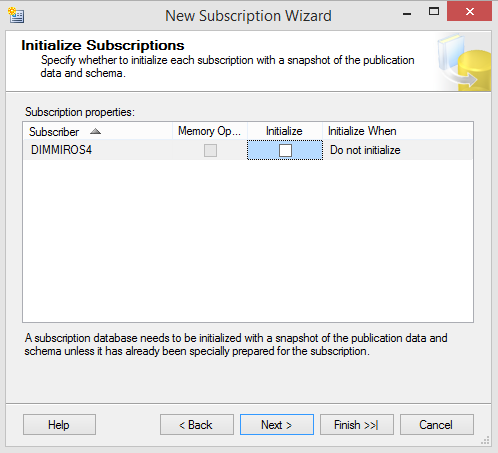
Choose carefully if the subscribers are to be reinitialized and when:
Make sure Create subscription is clicked
- Launch the Replication Monitor and check the health of the Replication
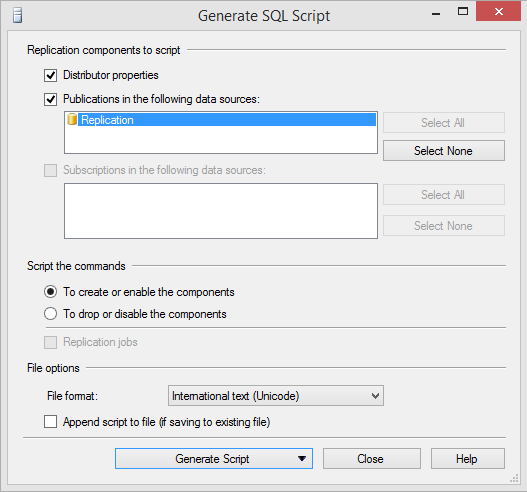
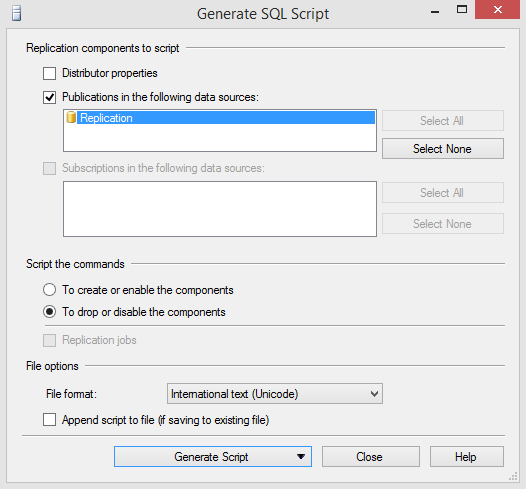
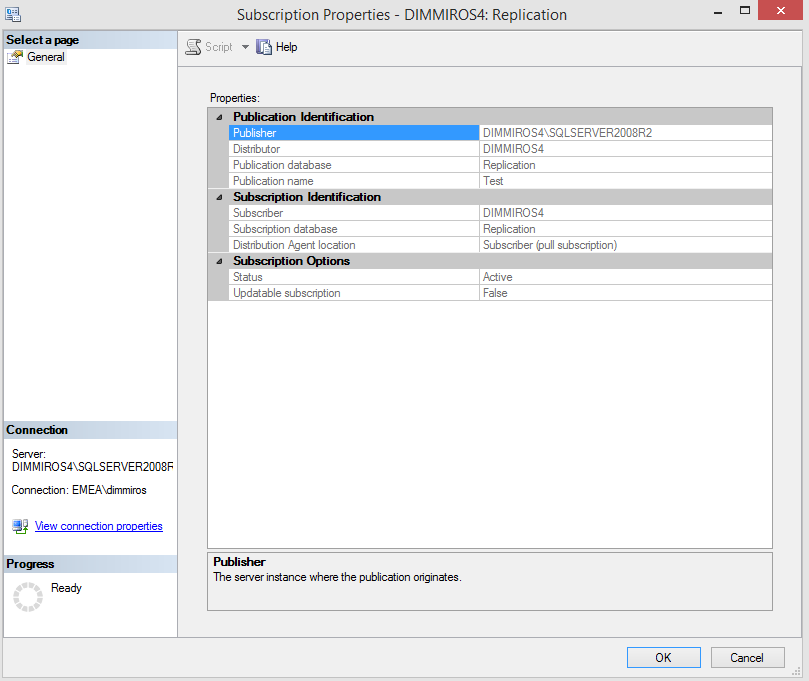
Note that depending on the specifics in your environment, some of the steps might be a little bit different in some situations (for example based on type of subscriptions or whether you have a remote or local publisher).
Moving the distribution database is not that simple task as it looks like, especially in complex replication scenarios. Hope this article will help you do this task flawlessly next time you have to
Thanks for reading!

In the last years, he is working on a great variety of customers' environments and involved in complex transitions and transformation projects.
Miroslav is also leading courses at Sofia University and participated as a speaker at various events.
View all posts by Miroslav Dimitrov
- How to perform backup and restore operations on SQL Server stretch databases - September 7, 2016
- SQL Server stretch databases – Moving your “cold” data to the Cloud - August 18, 2016
- Tips and tricks for SQL Server database maintenance optimization - January 11, 2016