
Introducción
Sin lugar a dudas, pocas tecnologías en SQL Server provocan tanta confusión y difusión de información errónea como los mencionados índices. Este artículo analiza algunas de las preguntas más frecuentes y otras más que deberían formularse pero que a menudo no lo son. Utilizaremos SQL Server 2016 para los ejemplos y una herramienta gratuita, para el análisis del plan de ejecución de consultas de SQL Server, ApexSQL Plan, para explorar los efectos de los índices referidos a un problema comercial típico: una tabla de clientes.
Pregunta 1: ¿Qué es un índice?
Había una vez una época en que los ejemplos más comunes dónde se utilizaban los índices eran los diccionarios y las guías telefónicas. En la sociedad conectada de hoy con recursos en línea disponibles que hubieran sido considerados hace tan solo veinte años como pura fantasía, ¡es completamente posible que nunca haya tenido ninguno de los dos esa disponibilidad en sus manos! Entonces, veamos un recurso en línea: la lista de especies en peligro de extinción que mantiene el Fondo Mundial para la Naturaleza en su sitio web en www.worldwildlife.org. La lista comienza así:
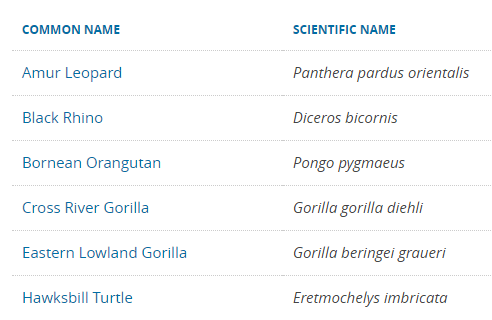
Continúa y tiene dos páginas a partir de este escrito. Un rápido vistazo a la lista le dice que las especies están ordenadas alfabéticamente por su nombre común. Sin embargo, imagine que usted es biólogo y está acostumbrado a usar los nombres latinos. ¿Cómo encontrarías la designación para las especies Thunnus y Katsuwonus? Bueno, deberías leer hasta el final de la lista, ya que tiene el nombre común de atún (¡como el de tu sándwich!) Y es el último en la lista alfabética por nombre común. “¡Bien!”, Piensas. En este caso no es tan difícil leer dos páginas para encontrar lo que estoy buscando.
Ahora, imagine que esta lista contiene todas las especies conocidas en el mundo (alrededor de 8.7 millones) las mismas que están organizadas de manera similar. Leer esa lista para encontrar una especie por su nombre en latín no sería muy divertido ni rápido para usted y necesitaría mucha E/S en una computadora. En una base de datos, la E/S es a menudo (si no siempre) el mayor cuello de botella.
Si podemos reducir la información de la E/S requerida para encontrar la referencia que queremos, podemos darle un cuello más ancho a la botella.
Esta reducción también conducirá a beneficios adicionales, como tiempo de CPU reducido, esperas, uso de caché y más.
El objetivo de un índice en una tabla de base de datos es reducir E/S. Para entender cómo funciona esto, primero debemos mirar una tabla que no tiene índices.
Pregunta 2: ¿Cómo se ve una tabla sin índices?
SQL Server almacena todos los datos en todos sus archivos para todas las bases de datos en páginas de 8K. Cuenta al menos con dos archivos para cada base de datos: uno destinado para los datos, que tiene el tipo de archivo predeterminado .mdf, y otro designado para el registro, que usa la extensión .ldf para el tipo de archivo predeterminado. Cada tabla en la base de datos tiene una o más páginas. Para realizar un seguimiento de esas páginas, SQL Server utiliza un conjunto especial de páginas, llamadas páginas IAM (para el Mapa de asignación de índice). Sin embargo, a pesar de la palabra “Índice” en el nombre, los IAM los mismos también se usan para tablas no indexadas. Estos se llaman cúmulos o montones.
Un montón es muy parecido a lo que su nombre implica: un cumulo o montonera de cosas desordenadas. Esa podría ser su ropa sucia, o los materiales de construcción sobrantes como si fueran escombros, o el desastre dejado en la playa por una marea alta o, como en este caso, un montón de páginas para una tabla en SQL Server. Nada está organizado sin ningún tipo de orden, de ninguna forma o manera, excepto las páginas de IAM, que están encadenadas para que SQL Server pueda encontrar todas las páginas de datos de la tabla. Gráficamente se parece un poco a esto:
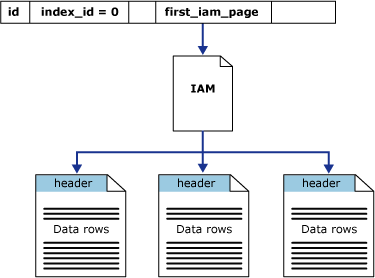
Fuente: ©Microsoft.com
Todos los datos están ahí, pero la única forma de encontrar algo es leerlo completamente desde el principio. Para una tabla muy grande, esto sería terriblemente ineficiente. Veamos qué sucede con una tabla así.
Inicialmente empecemos creando una tabla de clientes. Primero, aquí está el DDL para la tabla de clientes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE [dbo].[Customers]( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](255) NULL, [LastName] [nvarchar](255) NOT NULL, [Street] [nvarchar](255) NOT NULL, [StreetNumber] [nchar](10) NOT NULL, [Unit] [nchar](10) NULL, [City] [nvarchar](255) NOT NULL, [StateProvince] [nvarchar](255) NOT NULL, [ISO3_Country] [char](3) NOT NULL, [EmailAddress] [varchar](254) NULL, [HomePhone] [numeric](15, 0) NULL, [MobilePhone] [numeric](15, 0) NULL ) ON [PRIMARY] |
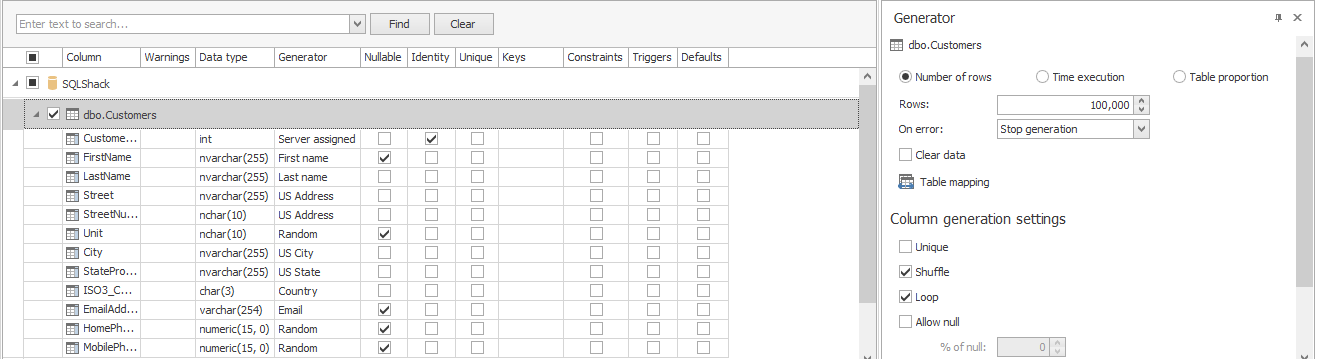
A continuación, completémoslo con datos utilizando ApexSQL Generate:
Ahora, usemos el Plan ApexSQL para explorar esta simple consulta:
|
1 2 3 |
SELECT * FROM Customers where CustomerID = 50000; |
Cuando vemos el plan de ejecución estimado vemos:
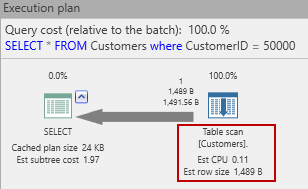
Lo primero y lo prioritario que SQL Server hará es un escaneo de tabla. Eso significa que leerá todas las filas de esta tabla hasta que encuentre una con una identificación correspondiente a un cliente de 50000. Curiosamente, si pasamos el cursor sobre la flecha grande de derecha a izquierda en el plan considerado, vemos esto:

¡Filas estimadas = 1! Esto se debe a que SQL Server espera que exista solo un cliente con la identificación correspondiente. Podría haber más (ya que en este momento no hay nada que lo evite), pero no hay forma de saberlo con certeza.
Bien, ahora ejecutemos esta pregunta o consulta para ver qué podemos averiguar. Lo más interesante para ver es la pestaña de lecturas de E/S.

Hay 2506 lecturas lógicas, una para cada página de la tabla. Además, hay un número igual de lecturas de lectura anticipada. Estas son lecturas físicas que SQL Server realiza previamente con la anticipación de su requerimiento o necesidad. Entonces, ¿cuánto de esto corresponde a la tabla? Esta consulta nos dice cuántas páginas utiliza esta tabla:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT t.NAME AS TableName, p.rows AS RowCounts, SUM(a.total_pages) AS TotalPages, SUM(a.used_pages) AS UsedPages, (SUM(a.total_pages) - SUM(a.used_pages)) AS UnusedPages FROM sys.tables t INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE t.NAME = 'Customers' AND t.is_ms_shipped = 0 AND i.OBJECT_ID > 255 GROUP BY t.Name, p.Rows ORDER BY t.Name |
Y esta consulta nos dice:

¡Eso es correcto! Esto significa que ¡SQL Server tuvo que leer todas las páginas de la tabla menos una! Una opción fue que ¿Quizás pensó que encontraría la fila correspondiente a mitad de camino? ¿Sera que ese correspondería al tiempo de ejecución esperado, verdad? ¿O n/2? Recuerde que considerando que SQL Server está realizando operaciones de lectura anticipada, se tiene que minimizar el número de operaciones de lectura, terminara leyendo todas las páginas de datos. (La otra página contiene metadatos).
Si esta tabla fuera parte de un sistema OLTP ocupado y tuviera millones de filas y miles de búsquedas simultáneas, esto supondría una carga innecesaria y desagradable para los recursos del sistema. Incluso si pudiera mantener toda la tabla en el grupo de búferes, eso haría que esos búferes estuvieran ocupados para otras consultas. De cualquier manera, esto hará que el servidor sea ineficiente y enfermizo. ¡La indexación adecuada es la cura!
Pregunta 3: ¿Qué tipos de índices están disponibles en SQL Server?
SQL Server soporta y admite la indexación para una variedad de necesidades. Tomando prestado de la documentación de Microsoft, estos documentos están disponibles en SQL Server 2016:
| Type | Description |
| Clúster | Un índice clúster ordena y almacena las filas de datos de la tabla o vista por orden en función de la clave del índice clúster. El índice clúster se implementa como una estructura de árbol b que admite la recuperación rápida de las filas a partir de los valores de las claves del índice clúster. |
| No agrupado | Los índices no clúster se pueden definir en una tabla o vista con un índice clúster o en un montón. Cada fila del índice no clúster contiene un valor de clave no agrupada y un localizador de fila. Este localizador apunta a la fila de datos del índice clúster o el montón que contiene el valor de clave. Las filas del índice se almacenan en el mismo orden que los valores de la clave del índice, pero no se garantiza que las filas de datos estén en un determinado orden a menos que se cree un índice clúster en la tabla. |
| Único | Un índice único se asegura de que la clave de índice no contenga valores duplicados y, por tanto, cada fila de la tabla o vista sea en cierta forma única. |
| Index with included columns | Índice no clúster que se extiende para incluir columnas sin clave además de las columnas de clave. |
| Texto completo | Tipo especial de índice funcional basado en símbolos (token) que compila y mantiene el motor de texto completo de Microsoft para SQL Server. Proporciona la compatibilidad adecuada para búsquedas de texto complejas en datos de cadenas de caracteres. |
| Espacial | Un índice espacial permite realizar de forma más eficaz determinadas operaciones en objetos espaciales (datos espaciales) en una columna del tipo de datos de geometry . El índice espacial reduce el número de objetos a los que es necesario aplicar las operaciones espaciales, que son relativamente costosas. |
| Filtered | Índice no clúster optimizado, especialmente indicado para cubrir consultas que seleccionan de un subconjunto bien definido de datos. Utiliza un predicado de filtro para indizar una parte de las filas de la tabla. Un índice filtrado bien diseñado puede mejorar el rendimiento de las consultas y reducir los costos de almacenamiento del índice en relación con los índices de tabla completa, así como los costos de mantenimiento. |
| XML | Representación dividida y persistente de los objetos binarios grandes (BLOB) XML de la columna de tipo de datos xml. |
Fuente: ©2017 Microsoft
Debido a que los índices de texto completo, espacial y XML están fuera del alcance de este artículo. Nos concentraremos en considerar solo en los índices agrupados y no agrupados y veremos algunas de sus extensiones, incluidos los índices únicos y filtrados, y la utilidad y funcionalidad de las columnas incluidas. Aunque no se mencionó anteriormente, es importante mencionar que tampoco veremos los índices de almacén de columnas en este artículo, ni las tablas en memoria.
Como se describió anteriormente, podemos indicar que un índice agrupado afecta cómo se almacenan realmente los datos. En un cumulo o montón, las filas de datos se almacenan sin ningún orden en particular. Se escriben donde caben de tal forma que ponen la carga al mínimo esfuerzo los recursos de SQL Server, utilizando las mismas como la agrupación de almacenamiento intermedio y el subsistema de E/S. Por otro lado, cuando crea un índice agrupado en una tabla, la organización de los datos cambia para que ahora esté en orden de acuerdo con las claves especificadas. Todo el índice está organizado como un árbol B (“B” significa equilibrado), donde los nodos de cada hoja son las páginas de datos reales y uno o más niveles de nodos de índice se construyen sobre los nodos de hoja hasta el nodo de la raíz única. El resultado proporciona algunas garantías con respecto al rendimiento asintótico del índice. La mayoría de las operaciones (buscar, insertar y eliminar) operan en O (log n) donde n es el número de entradas en el índice.
Es importante mencionar que Un índice no agrupado comparte el concepto de árbol B para los nodos de índice con las mismas garantías de rendimiento. Recuerde, sin embargo, que dichos índices no afectan la organización de las páginas de datos, las mismas que pueden estar agrupadas o no. Algunas características opcionales de los índices no agrupados son:
- Índices únicos – donde las entradas de índice deben ser únicas y SQL Server se asegura de que sean
- Índices filtrados – que son índices creados con una cláusula WHERE para limitar lo que se incluye en el índice
- Columnas incluidas – que pueden llevar un subconjunto de columnas sin clave como parte del índice
Si piensa en las implicaciones de estas descripciones, entonces usted debería poder observar que una tabla o es un cumulo o montón o de otra forma un índice agrupado. Otras implicaciones son que, dado que el nodo hoja de un índice agrupado es una página de datos, no hay necesidad de columnas incluidas (ya que todas las columnas están en la página de datos) o tratarse de índices filtrados (ya que por definición el índice agrupado es la tabla completa). Una idea más sutil es esta: dado que la teoría de B-Tree no estipula la unicidad de la clave, un índice agrupado puede tener filas con claves duplicadas. En ese caso, SQL Server agregará un unificador oculto (un entero de 4 bytes) al índice para forzar la unicidad.
Pregunta 4: ¿Qué sucede cuando crea un índice agrupado?
Como se explica previamente en la respuesta a la pregunta 3, cuando usted crea un índice agrupado, se cambia el orden de las filas en las páginas de datos. Agregando un índice agrupado a nuestro ejemplo de trabajo, el comando es un simple:
|
1 2 3 4 |
CREATE CLUSTERED INDEX CIX_Customers_CustomerID ON dbo.Customers (CustomerID); |
Podemos ver y ejecutar esto en el Plan ApexSQL. Primero, veamos el plan de ejecución estimado:
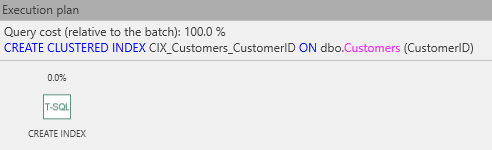

El plan estimado muestra solo una operación para crear un índice. Eso significa que se maneja internamente y/o SQL Server prefiere no exponer los detalles. Sin embargo, es fácil deducir lo que debe suceder:
- Lee todas las páginas de la tabla
- Ordena las filas por la clave especificada
- Rellena nuevas páginas con las filas ordenadas (hasta el factor de relleno)
- Endurece las nuevas páginas para el almacenamiento persistente
- Libere las páginas utilizadas por las filas de datos antes del índice de creación
En el caso de que, si realmente ejecutamos esto, deberíamos poder ver algo de esta acción::

Verificamos entonces que ¡esto es más o menos como se esperaba! Leyendo de derecha a izquierda, se lee el contenido de la tabla (escaneo de la tabla), luego se envían 100000 filas para su clasificación, posteriormente el conjunto de datos ordenados se envían a una operación IndexInsert, que crea los nodos de índice. El operador de paralelismo nos indica que la provisión para una operación de IndexInsert paralela, puede ejecutarse en muchos flujos paralelos dependiendo del número de CPU disponibles. Finalmente, se puede observar que las nuevas filas se INSERTAN en la tabla. No vemos un operador para liberar las páginas ahora no utilizadas, pero esa es una operación en segundo plano que nunca podrá usted verificar en un plan de ejecución.
Ahora que tenemos un índice agrupado, ¿afectará eso a nuestra consulta original?
|
1 2 3 |
SELECT * FROM Customers where CustomerID = 50000; |
Como resultado entonces ahora el plan estimado se ve así:
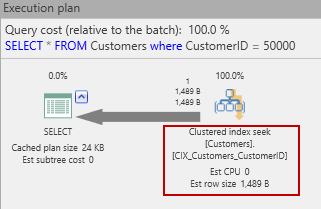
El escaneo original de la tabla ha sido reemplazado por una búsqueda de índice agrupado. ¿Eso ayudará a reducir la E/S utilizada para obtener esa fila? ¡Veamos!

¡Esa es una gran diferencia! De las originales 2500 lecturas las mismas se han reducido a solo tres. Ya que como sabemos solo hay una página de datos para esta fila (dado que la fila tiene una longitud total < 8090, este como vera es un tema para un artículo diferente), podemos inferir que las otras dos E/S son para páginas que contienen los nodos de índice. Podemos confirmar esto con una simple consulta:
|
1 2 3 4 5 |
SELECT INDEXPROPERTY(OBJECT_ID('dbo.Customers'), 'CIX_Customers_CustomerID','IndexDepth') AS [Index Depth] |
Que devuelve:
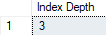
coincidiendo con nuestras expectativas, y las lecturas de E/S.
Gráficamente, nuestro índice agrupado ahora tiene esta estructura:
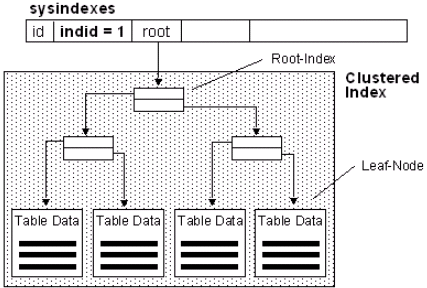
Fuente: ©Microsoft.com
Pregunta 5: ¿Qué pasa con los índices no agrupados?
Como se podrá observar hasta ahora, solo hemos estado buscando clientes en base a su ID de cliente. ¿Qué pasaría si quisiéramos buscar un cliente por su nombre? Algo como esto, tal vez:
|
1 2 3 |
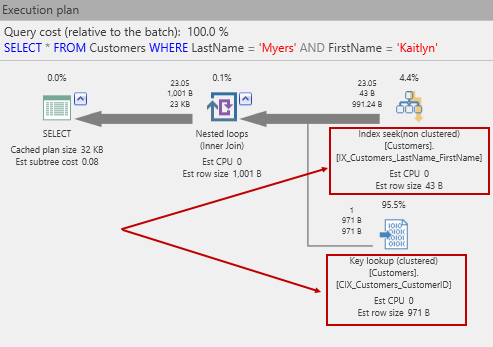
SELECT * FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
El plan de ejecución estimado es ahora:
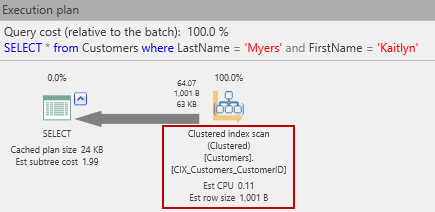
¡Oh no! Resulta entonces que volvemos a ejecutar una operación de escaneo. (Esta vez, es un escaneo de índice agrupado, ya que, como se mencionó anteriormente, una tabla es ya sea un cumulo o montón o puede tratarse de un índice agrupado, y además previamente ya acabamos de convertir la tabla Clientes. ¡Pero la situación realmente empeora! Las lecturas de E/S reales han desaparecido ¡arriba!

Esto se debe a que SQL Server ahora también está utilizando los nodos de índice al escanear las páginas de datos. ¿Qué se puede hacer en esta situación? Pues la solución es entonces ¡Agregar un índice no agrupado, por supuesto!
Usemos este DDL para crear el índice:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers (LastName, FirstName); |
Con eso en su lugar, intentemos nuevamente hacer SELECT. Esta vez el plan se ve así:
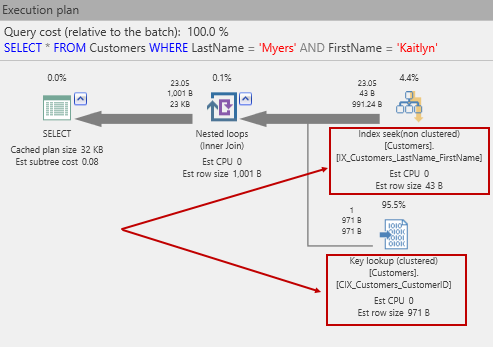
Ahora, podemos ver lo que realmente busca un índice, usando el nuevo índice, seguido de una búsqueda clave. La búsqueda de claves es necesaria ya que hemos escrito:
|
1 2 3 |
SELECT * FROM Customers … |
y debido a que el SQL Server tiene que volver a las páginas de datos el mismo podrá entonces obtener las otras columnas en la fila. La razón es una búsqueda de claves debido a cómo SQL Server crea índices no agrupados. En este caso sería perdonable el pensar que el índice no agrupado contiene un puntero a las páginas que contienen la fila de datos. En realidad, no es así como funciona. Esto debido a que en lugar de un puntero (por ejemplo, un número de sector en el disco), un índice no agrupado mantiene la clave de índice agrupado si es que hay un índice agrupado. ¡Por supuesto, antes de llegar aquí, colocamos un índice agrupado en la tabla clientes! Como consecuencia, de esta situación obtendremos una búsqueda clave. O sea que si usted si adivinó lo que esto significa: una búsqueda separada en el índice agrupado, ¡usted tiene razón!
Entonces, ¿el índice no agrupado reduce nuestras E/S? Hagamos una ejecución real y veamos:

Entonces como a continuación se muestra, hay una reducción sustancial en E/S. esto debido a que quizás esperaba solo 3 lecturas como en el ejemplo de índice agrupado que usamos antes. Sin embargo, no hay garantía de que haya solo una Kaitlyn Myers en la mesa. Vamos a comprobar que:
|
1 2 3 4 |
SELECT COUNT(*) AS Kaitlyns FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
devoluciones:

Entonces, las lecturas de E/S son en realidad bastante realistas.
El nombre “no agrupado” se deriva e implica del simple hecho de que este tipo de índice no es un índice agrupado. Lo que es, es un árbol B construido sobre una tabla (que puede estar agrupada o en un cumulo o montón). Entonces, si también hay un índice agrupado, el índice no agrupado existe junto al índice agrupado, y sus entradas apuntan al nivel de hoja de ese índice: las páginas de datos. Un índice no agrupado tiene una estructura como esta:
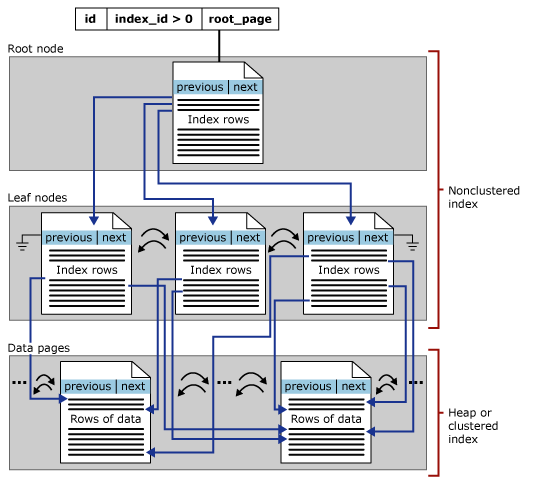
Fuente: ©Microsoft.com
Pregunta 6: ¿Qué pasa con las columnas incluidas? ¿Cómo pueden ayudar?
Es muy importante indicar el hecho de que ya usted vio que una consulta que usaba un índice no agrupado tenía que buscar otras columnas con una búsqueda clave en el índice agrupado. ¿Qué sucede si consulta con frecuencia solo un subconjunto de las otras columnas? ¿Qué pasa si a menudo estabas buscando el número de teléfono del cliente? Ahí es donde entran las columnas incluidas. Si yo modifico el índice no agrupado de esta manera:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers (LastName, FirstName) INCLUDE(HomePhone); |
luego ejecute esta consulta:
|
1 2 3 4 |
SELECT HomePhone FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
El plan de ejecución cambia a esto:
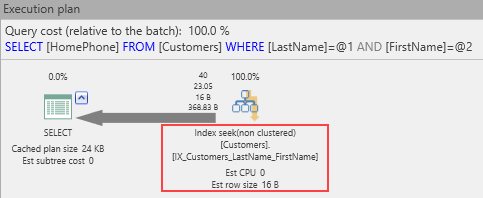
¡No más búsquedas clave! Las lecturas de E/S también se reducen:

Entonces, podemos ver cuál es el beneficio positivo de las columnas incluidas. Naturalmente, esto plantea la pregunta: “¿Por qué en primer lugar no solo agregar las columnas incluidas al índice?” Para comprender por qué, primero considere esto: si bien las columnas clave se almacenan en todos los niveles del índice, las columnas no clave se almacenan solo en el nivel de la hoja Para que no haya confusión, aunque un índice no agrupado apunta a las páginas de datos, sus hojas son parte del árbol B en sí.
¿Por qué no poner las columnas incluidas en las claves de índice? Hay unas varias razones:
- Costo de almacenamiento. Si las columnas incluidas no son necesarias para otros tipos de búsquedas, las mismas se deberán mantener fuera de la lista de claves lo que genera entradas de índice más cortas y un árbol B más plano. Eso da como resultado menos E/S de índice.
- Límites de SQL Server. Actualmente, no puede tener más de 16 columnas clave en un índice, y en total esas columnas clave no pueden exceder el tamaño máximo de índice de 900 bytes.
- Las columnas incluidas pueden ser tipos de datos que no están permitidos como columnas de índice. Por ejemplo, nvarchar (max), varbinary (max), xml y otros no pueden ser columnas clave, pero pueden incluirse columnas.
Vale la pena mencionar que cuando un índice contiene todas las columnas necesarias para satisfacer una consulta, la misma se denomina índice de cobertura. La inclusión de columnas estratégicas en un índice no agrupado puede permitirle garantizar que las consultas más frecuentes podrán satisfacerse por completo desde el índice sin la necesidad de búsquedas clave en el índice agrupado.
Aunque pese a que no lo hemos mencionado, usted puede poner un índice no agrupado en un cumulo o montón, es decir, conformar una tabla sin un índice agrupado. En ese caso, cualquier búsqueda en las páginas de datos es búsqueda RID. La “R” significa Fila y RID consiste en una dirección virtual que incluye el número de archivo y el número de página de la página de datos y el espacio de fila dentro de la página de datos.
Pregunta 7: ¿Qué pasa con las claves primarias (y las claves en general)?
Hasta ahora, hemos evitado cualquier discusión sobre las claves principales. Eso se debe a que no ha sido un accidente. Con demasiada frecuencia, los índices agrupados y las claves primarias se combinan como si fueran la misma cosa. ¡Pues resulta que No lo son! Por eso los hemos dejado hasta ahora. Es mejor tener una idea sólida sobre los tipos de índices antes de introducir claves.
Indudablemente es importante mencionar que, para ser una relación en el sentido formal y relacional algebraico de la palabra, una tabla (lo que la mayoría de los RDBMS llaman relaciones) la misma debe tener una clave: alguna columna o colección de columnas que, en conjunto, identifiquen de manera única una fila en una tabla. Pese a ello, Sin embargo, una clave no es un índice. Puede ser (y generalmente es) compatible con un índice, pero en esencia, hay que recordar que una clave es una restricción, resulta de ser una condición de que la base de datos se debe mantener para preservar la integridad referencial. Usted entonces podrá ver la diferencia creando una clave principal en la tabla Clientes en el ejemplo que estamos usando:
|
1 2 3 4 |
ALTER TABLE dbo.Customers ADD CONSTRAINT PK_Customers_CustomerID PRIMARY KEY (CustomerID); |
Observe que la declaración agrega una restricción, no un índice. Agrega justamente tal restricción en la columna CustomerID. Ahora, dado que ya tenemos un índice agrupado y un índice no agrupado, esto producirá un resultado interesante. En SSMS Object Explorer, ¡ahora vemos tres índices!
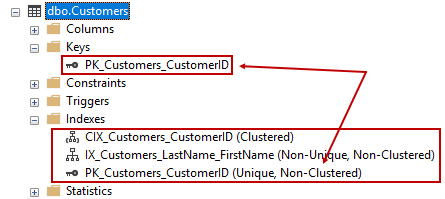
Verificamos entonces que el nuevo se ha creado como un índice de respaldo para implementar la restricción. Tenga en cuenta que el mismo índice no está agrupado. Si pensabas que las claves primarias tenían que ser índices agrupados, piénsalo de nuevo. Es interesante que SQL Server no reconoció el hecho de que ya existe un índice agrupado de cobertura y pese a ello lo usó. Sospecho que construir índices de la forma en que lo hacemos aquí es bueno para la instrucción y los fines didácticos, pero para fines prácticos no es óptimo para un diseño adecuado, por lo que el equipo de desarrollo de SQL Server aún no ha trabajado en este caso límite y puede que nunca lo haga.
Antes de agregar la restricción de clave principal, era posible y permisible agregar nuevos clientes con los mismos ID de cliente que los clientes existentes. ¡es una interesante alternativa Adelante, pruébalo! Pero ahora que la PK está en su lugar, eso ya no es posible.
Aunque solo puede haber una clave principal, puede haber otras claves, si otras combinaciones de columnas son verdaderamente únicas. Crearlos usa una sintaxis similar:
|
1 2 3 4 5 |
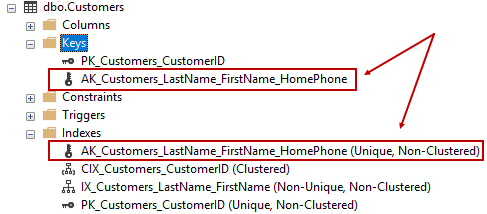
ALTER TABLE dbo.Customers ADD CONSTRAINT AK_Customers_LastName_FirstName_HomePhone UNIQUE (LastName, FirstName, HomePhone); |
Esta operación crea una restricción única y también agrega un índice de respaldo:
Las claves primarias son necesarias para hacer que una tabla se ajuste a la teoría relacional. En la práctica, son muy útiles (como son las claves únicas) para la integridad referencial y una buena manera de hacer que la base de datos verifique sus suposiciones sobre los datos entrantes.
Pregunta 8: ¿Mi clave principal también debería ser la clave de índice agrupada?
De manera predeterminada, SQL Server efectúa la creación de un índice agrupado cuando elabora una nueva tabla con una clave primaria:
|
1 2 3 4 5 6 |
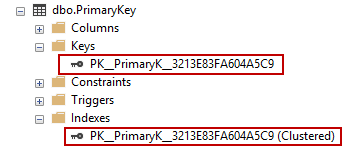
CREATE TABLE PrimaryKey (id INT IDENTITY PRIMARY KEY, name VARCHAR(50) ); |
Este comando crea una clave respaldada por un índice agrupado (con un nombre proporcionado por el sistema):
Sin embargo, es importante mencionar el hecho de que solo porque es la acción predeterminada, eso no significa que siempre sea la mejor opción. Si bien una clave principal debe estar respaldada por un índice para implementar la restricción, el índice no necesita estar agrupado, tal como pudimos observar anteriormente. Además, los objetivos de las claves primarias y los índices agrupados pueden no ser los mismos.
Básicamente, una restricción de clave principal permite que SQL Server mantenga la propiedad básica e importante de que una tabla puede no tener filas duplicadas. De hecho, las restricciones únicas hacen exactamente lo mismo. Debido a que están respaldados por índices, las claves también son útiles para las búsquedas, ya que
- Solo puede haber una fila para una clave determinada
- El índice permite utilizar una operación de búsqueda, que normalmente requiere menos E/S
Por otro lado, los índices agrupados pueden proporcionar una ventaja de rendimiento al momento de que usted pueda leer la tabla en orden que indica el índice. Esto permite que SQL Server utilice mejor las lecturas de lectura anticipada, que son asintóticamente más rápidas que las lecturas página por página. Además, un índice agrupado no requiere unicidad. Si dos o más filas tienen la misma clave de índice agrupada, se agrega un unificador para garantizar que todas las filas del índice sean únicas.
Volviendo a nuestra tabla de Clientes, esta es una configuración de índice/clave perfectamente válida:
|
1 2 3 4 5 6 7 8 |
CREATE CLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers(LastName, FirstName); ALTER TABLE dbo.Customers ADD CONSTRAINT PK_Customers_CustomerID PRIMARY KEY NONCLUSTERED(CustomerID); |
Aquí, en este caso en particular debemos asumir que la mayoría de las lecturas se realizan por apellido, nombre (el índice agrupado) y que la mayoría de las búsquedas se realizan por CustomerID (la clave principal). (SQL Server agregará un uniquifier (unificador) al índice agrupado ya que no sabe si habrá colisiones clave o no). El punto aquí es considerar cuidadosamente qué disposición podría resultar ser la mejor para una nueva tabla. Consulte con los usuarios comerciales sobre cómo se usará la tabla. Recuerde que la mayoría de los informes son de naturaleza secuencial. Consecuentemente elija su indexación en de forma adecuada y lógica, luego pruébelo. Use cargas de trabajo reales y vea si el uso real sigue siendo una buena combinación para el esquema de indexación. Caso contrario usted debería ajustarlo a su gusto.
Pregunta 9: ¿Cuáles son esos “índices faltantes” en un plan de ejecución
A veces, se puede apreciar que se visualizarÁ la inclusión de un mensaje con el plan de ejecución de que falta un índice. Por ejemplo, si elimino los índices de la tabla Cliente e intento realizar una búsqueda por CustomerID, el plan resultante se verá así:
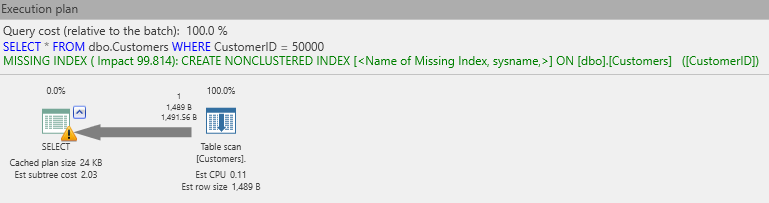
El texto en verde, arriba, es solo un mensaje de este tipo. En este acápite básicamente, SQL Server dice que, si hubiera un índice en la columna Cu stomerID, ¡el costo de la consulta general podría reducirse en un 99.8%! Eso reduciría el costo a casi nada. En lugar de una exploración de tabla, podría usar una operación de búsqueda de índice.
La pregunta entonces es ¿siempre se debe implementar un índice faltante? Como suele ser el caso, “depende” es la única respuesta verdadera. ¿Es esta una consulta anual que se ejecuta en 10 minutos sin el índice? Quizás pueda dejar solo ese índice faltante. ¿Es una consulta que se ejecuta miles de veces por segundo desde un servidor de comercio electrónico ocupado? ¡Probablemente deberías implementar la recomendación! ¡No asumas que mamá sabe más! Debe pensarlo detenidamente y comprender los patrones de uso y el costo de un índice antes de hacer nada. Ahora que lo pienso…
Pregunta 10: ¿Puedo tener demasiados índices?
Actualmente en la realidad, hay consejos en el campo que indican que solo debe indexar cada columna de su tabla para que ningún plan de ejecución tenga un índice faltante. ¿Es este un buen consejo? Una vez más, la respuesta pertinente es: depende.
Las bases de datos de un Data Warehouse a menudo tienen una tabla calendario. Esa tabla tendrá una fila para cada fecha y columnas para cada uso concebible: MonthNumber, QuarterNumber, HalfYearNumber, MonthText, FullDateText, Is_Holiday, Is_BusinessDay y muchos, muchos más. Tal tabla es estática. A menudo, la clave principal (y el índice agrupado) es una columna entera o de fecha con la fecha que coincide con las otras columnas de la fila. Esta tabla nunca (o rara vez) cambia. Además, la misma tabla no es demasiado grande. (¿Cuántas filas necesitarías para un siglo?) En una tabla así, indexar cada columna puede tener sentido. Puede tener índices filtrados para los distintos indicadores, índices ascendentes y descendentes, por lo que la mayoría de los cuales no estarán agrupados.
Ahora considere nuestra tabla de clientes. Si indexamos cada columna, ¿qué sucede cuando insertamos un nuevo cliente?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
INSERT INTO [dbo].[Customers] ([FirstName] ,[LastName] ,[Street] ,[StreetNumber] ,[Unit] ,[City] ,[StateProvince] ,[ISO3_Country] ,[EmailAddress] ,[HomePhone] ,[MobilePhone]) VALUES ('Ford', 'Prefect', 'The Resraurant', '42', 'N/a', 'End of the Universe', 'Improbable', 'FPP', 'Ford@HeartOfGold.com', 2125551212, 3141592653 ) GO |
El plan de ejecución real para esto es:
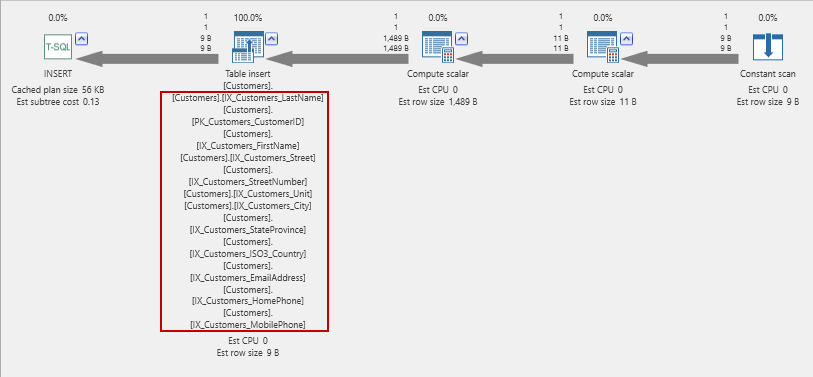
¡Resultado es que: ¡Todos esos índices deben mantenerse! Este trabajo puede ejecutarse rápidamente, por lo que, a menos que tenga una tabla estática (como una tabla de calendario), ¡indexar cada columna generalmente es una mala idea!
Resumen
La indexación adecuada de una tabla de SQL Server es clave para lograr obtener un rendimiento consistente y óptimo. Recuerde que hay muchas cosas adicionales para considerar al diseñar una estructura de índice. Por consiguiente, casi ninguna de esas consideraciones se puede diseñar o efectuar sin consultar a los usuarios comerciales que entienden los datos y cómo se utilizarán los mismos, aunque puede resultar que, después de que la nueva tabla haya estado en uso durante algún tiempo, se presenten en ellas otras opciones de indexación en sí mismas.
Este artículo ha intentado responder algunas de las preguntas más importantes sobre la indexación en general y específicamente cómo se hace en SQL Server. Sin embargo, en realidad solo hemos explorado y arañado solamente la superficie. ¡Cada pregunta respondida aquí podría ser considerada como su propio artículo completo y posiblemente una serie de artículos! Además, no hemos abordado otros tipos de índices (por ejemplo, índices XML) ni hemos examinado los objetos en memoria y cómo cambian la figura para las nuevas ediciones de SQL Server.
Estén atentos para obtener artículos más detallados sobre la indexación de SQL Server.

Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook "Getting Started With Python" and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight