
In SQL Server, when talking about table partitions, basically, SQL Server doesn’t directly support hash partitions. It has an own logically built function using persisted computed columns for distributing data across horizontal partitions called a Hash partition.
For managing data in tables in terms storage, performance or maintenance, there is a need to keep data allocation units in large chunks. For the purpose of speeding up loading and archiving of data, tables may need to be divided into multiple units that can reside in multiple filegroups. When referring to partitions, there are two types; Vertical and Horizontal partitions.
Note: This concept was explained nicely by Milica Medic in the article Database table partitioning in SQL Server.
First, I will describe partitions at a high level.
Vertical partitions
Generally, Vertical partitioning means a semi data normalization process based on data use vs meaning within the database design. It involves removing redundant columns from the table and organizing a second table connected via a relationship. Suppose, we have a “heavy” table in terms of size; large columns may exist in the tables for an example, nvarchar, xml etc. Data might be rarely accessed in those large columns. When performing an operation in heavy tables, issue may arise with related IO cost, locking, latch contention etc. Vertical portioning is meant to address this by offloading lesser used columns and their resulting data to another table.
Vertical partitioning should be considered carefully, though, because it might affect performance if the partition is very large because there may be an increased number of joins in queries used for getting the records, when all of the columns (vs just a sub-set) are required.
Horizontal partitions
In this approach, the tables are divided into multiple tables, but with each table having the same columns. The partitioning, in this case, is that the rows are divided, amongst these tables, as per applied rules.
Hash partitions in SQL Server
In simple terms, a Hash partition is a Horizontal partition. It’s needed to logically build a hashing function and with it, ensure data is randomly distributed across the partition. This means that the partition key functions as an identifier and any new row are allocated to a particular partition based on the result of passing the partition key into a hashing algorithm. Due to this, data will be inserted randomly across the partition. Compared with a Horizontal Partition the only difference is that, here there is a need to add persisted computed columns into the index keys to deal with the partitioning scheme.
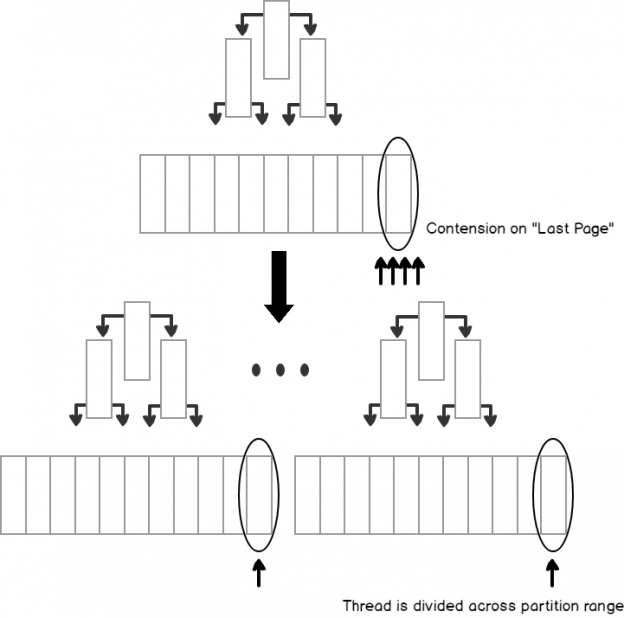
Why we need Hash partitions in SQL Server
In my previous article, I have discussed about Hot latches. You can refer this for more clarification about “The last page insert contention issue”.
When concurrency insertion happens then query queues are generated on the last page. This means, in attempting to perform this insertion request latch contention issue is generated. For the solution of this latch contention, there are multiple options available. Out of those, a Hash Partition is one of the best technique for reducing latch contention.
Building Hash partition with the help of computed column
As a part of the horizontal partition, let’s discuss in steps, how to organize and distribute data using a hashing function. Currently, for the demonstration purposes, I am going to create a new database with steps.
Step1: Create a new DB
|
1 2 3 4 |
USE MASTER GO CREATE DATABASE Hashpartition GO |
We need an additional filegroup and file for holding partitions and to ensure that the filegroup resides in an optimal drive location in term of IO cost. We can add filegroup at the time of database creation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ALTER DATABASE Hashpartition ADD FILEGROUP DistData; GO ALTER DATABASE Hashpartition ADD FILE ( NAME = DistDatafile, FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL14.SQL2017\MSSQL\DATA\DistDatafile.ndf', SIZE = 5 MB, MAXSIZE = UNLIMITED, FILEGROWTH = 5MB ) TO FILEGROUP DistData; GO |
Now we have the filegroup DistData with the new file DistDatafile added into the database Hashpartition.
Step2: Creating a new partition function
Partition function need to create in the current database. it maps the rows of a table or index into partitions based on the values of a specified column.
Syntax
|
1 2 3 |
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type ) AS RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [ ,..n ] ] ) |
A boundary value needs to be assigned. it specifies the boundary value of each partition of a partition table or index that uses partition_function_name. If the boundary_value is empty the partition function maps the whole table or index using partition_function_name into a single partition. There is only one partitioning column used which is specified in a CREATE_TABLE OR CREATE_INDEX statement. It needs to specify which side of each boundary value interval, left or right, the boundary_value [ ,..n ] belongs, when interval values are sorted by the Database Engine in ascending order from left to right. If not specified then LEFT is the default.
For an example, Here I will create table “customer_invoice”. Using this function, I will distribute the value in 8 boundaries.
For introducing the function, execute as follows.
|
1 |
CREATE PARTITION FUNCTION [Hashing] (TINYINT) AS RANGE LEFT FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7) |
Step3: introduce a new partition scheme and integrate to object in steps.
A Partition Scheme need to be created in the current database. It maps the partitions of a partitioned table or index to filegroups. The number and domain of the partitions of a partitioned table or index are determined in a partition function. It means, first need to create partition function Before creating a partition scheme.
Syntax
|
1 |
CREATE PARTITION SCHEME partition_scheme_name AS PARTITION partition_function_name [ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,..n ] ) |
We have already created partition function “Hashing”. As per mentioned above syntax, I will go for creating a new partition scheme with using partition function “Hashing”. Partitions will be created by the partition function are mapped to the filegroups specified in the partition scheme. A single partition cannot contain both FILESTREAM and non-FILESTREAM filegroups.
For introducing the partition scheme, execute as follows.
|
1 |
CREATE PARTITION SCHEME [ps_Hashing] AS PARTITION [Hashing] ALL TO ([DistData]) |
Scheme “ps_hashing” is introduced. Currently, its bounded with function Hashing and storage is residing with this filegroup “DistData”. Now I am going to integrate table object “customer_invoice” which is available for me in my environment, but here for demonstration purpose, I will mention object script here, execute as follows.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE customer_invoice ( id INT, invoiceMonth INT, invoiceDetail VARCHAR (100), custcode int, dtDate DATETIME DEFAULT GETUTCDATE () ) |
Still, all steps are performed with aligning horizontal partition steps. As a part of scatter, the step is distributing data with generating dynamic key value; “Hash value”. For the purpose of dynamic distribution, Here I am going to add persisted computed column into this table “customer_invoice”. Execute as follows.
|
1 2 3 |
ALTER TABLE [dbo].[customer_invoice] ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([invoiceDetail])%(12)),(0))) PERSISTED NOT NULL |
After adding this step, a Computed column is added. We need to add index part latter on. As for its functionally, it’s getting the checksum value of the column invoiceDetail and finalize the value with modulo operation. We need to make sure for calculating the hash value as per of data flow. Here For demonstration purposes, I introduced an example for distributing key part of the data.
In addition, I need to add a unique index with the leading column key hashvalue in this table; “customer_invoice”. I will go to add with the combination of the unique value column id with aligning partition scheme “ps_Hashing”. Execute as follows.
|
1 2 3 4 |
CREATE UNIQUE CLUSTERED INDEX [IX_Distribution] ON [dbo].[customer_invoice] ([ID] ASC, [HashValue]) ON ps_Hashing(HashValue) |
After adding this index, now Data distribution is organized randomly on this table. Now the data insert is going to the end of the logical range, but the hash value module’s operation is divided this across the B-tree structure though we can solve out last page insertion contention/Hot latch issue.
Step4: Demonstration of distributing the data flow.
Now, I have a database ready for execution, I will add sample chunk records with the help of the script, execute as follows.
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO customer_invoice(invoiceMonth, invoiceDetail, custcode) VALUES (1,'Test invoice 1',101), (2,'Test invoice 2 for second try',102), (3,'Test invoice 3 for second try',103), (4,'Test invoice 4 for second try',104), (5,'Test invoice 5 for second try',105), (6,'Test invoice 6 for second try',106), (7,'Test invoice 7 for second try',107), (8,'Test invoice 8 for second try',108) |
Data is inserted across the B-Tree structure randomly, as a part of viewing range wise distribution, I have prepared script. Execute as follows.
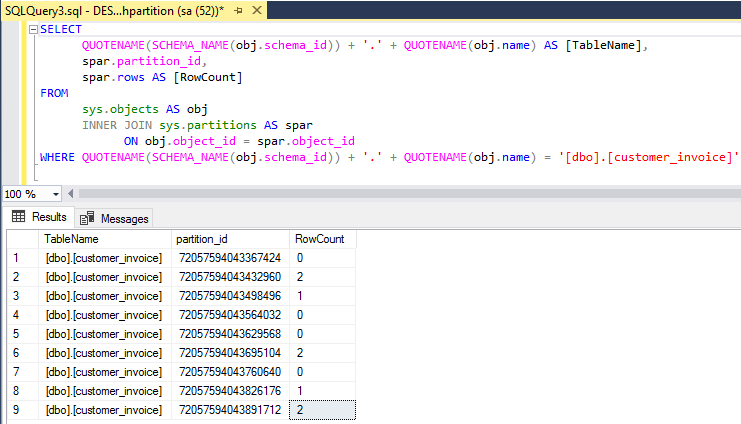
Kindly review above mentioned result, data is distributed randomly as we insert before. Here we have created own filegroup for demonstration purpose, we can organize data in multiple file group wise as per business use case. Kindly insuring the index should be the light weight in terms of key-length because of, due to heavy concurrency, it might be the case Page-split found. I suggest, need to study about hash value and observe your business use-case, then initiate appropriate action into it.
Trade-offs when using hash partitioning
- Due to random insertions, within a concurrent environment, it might be the case that heavy page splitting occurs.
- SELECT query performance might be affected due to hash partition bad query plan estimation.
- It is more difficult to maintain referential integrity while increasing key combinations of unique CLUSTERED index.
- Due to large size of the index, it is difficult to maintain maintenance as well.
Benefits of partitioning
- You can transfer or get subsets of data in a quick and efficient manner, while maintaining the integrity of data collection. For OLTP workloads you can get the data in quickly if data is available in a partitioned manner.
- The Data buffer is made smaller while data is screened with an appropriate partition, due to the fact that will often reduce the IO operational and data sorting cost.
- You may improve query performance, based on the types of queries for an example, the query optimizer can process equi-join queries between two or more partitioned tables faster when the partitioning columns in the tables are the same, because the partitions themselves can be joined.
- In addition, you can improve performance by enabling lock escalation at the partition level in lieu of a whole table. This can reduce lock contention at the table level.
- We can solve the concurrency insertion Hot-latches (PAGELATCH-EX) issue with Hash Partitions.
References
- Latch objects
- Create partitioned tables and indexes
- $partition
- All about Latches in SQL Server
- Partitioning & Archiving tables in SQL Server (Part 1: The basics)
- Archiving SQL Server data using Partitions

During his career, he strongly workes on his DBA development and has been working with SQL Server 2000, 2005, 2008, 2012, 2014 and 2016.
Currently, his main role is query tuning with respect to optimization and server performance. He is interested in constant learning and likes to face challenges. In his spare time, he spends time with his family.
- Hash partitions in SQL Server - June 28, 2018
- The Halloween Problem in SQL Server and suggested solutions - May 4, 2018
- How to identify and resolve Hot latches in SQL Server - November 7, 2017