
In the article on Deadlock Analysis and Prevention, we saw how deadlock occurs. We saw that SQL Server selects one of the processes involved in the deadlock as deadlock victim. In this article, we will look at the criteria on which SQL server selects a deadlock victim. Why one process is selected as deadlock victim and not the other.
Deadlock Detection
SQL Server runs a lock monitor thread every five seconds to check if any deadlocks have occurred. If a deadlock is found, a victim is selected and the interval for the lock monitor thread is reduced, this can be to as low as 100 milliseconds in some cases. If the lock monitor thread stops finding deadlocks the interval for deadlock detection is then periodically increased up to the default five seconds interval.
When a deadlock is detected, SQL Server then needs to select a victim of the deadlock.
Once this has been done, the victim transaction is rolled back and all of the resources held by the victim are released. A 1205 error is sent to the application that was running the victim transaction.
Deadlock Priority
By default, SQL Server chooses as the deadlock victim the transaction that is least expensive to rollback. In simple terms, a transaction that makes the fewest changes to the database is considered the least expensive.
However, users can set custom priorities for a particular transaction using the SET DEADLOCK_PRIORITY statement. The process with the lowest deadlock priority will then be the one chosen as the deadlock victim.
Example: SET DEADLOCK_PRIORITY NORMAL
By default the priority for all the processes is normal. It can be set to LOW, NORMAL or HIGH. It can also be set to an integer value in the range of -10 to 10.
As noted earlier, the process or transaction with the lowest deadlock priority is chosen as the deadlock victim. If the priority of all the transactions involved in the deadlock is same, the transaction that is least expensive is chosen as deadlock victim. In the unlikely event that both the deadlock priority and the cost of the transactions involved in the deadlock are equal, then deadlock victim will be selected randomly.
This is most easily explained by working through an example.
Creating Dummy Data
Let’s create some dummy data. We will use this data in our deadlock example. Execute the following script on your SQL Server.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE DATABASE testdb; GO USE testdb; CREATE TABLE table1 ( id INT IDENTITY PRIMARY KEY, student_name NVARCHAR(50) ) INSERT INTO table1 values ('James') INSERT INTO table1 values ('Andy') INSERT INTO table1 values ('Sal') INSERT INTO table1 values ('Helen') INSERT INTO table1 values ('Jo') INSERT INTO table1 values ('Wik') CREATE TABLE table2 ( id INT IDENTITY PRIMARY KEY, student_name NVARCHAR(50) ) INSERT INTO table2 values ('Alan') INSERT INTO table2 values ('Rik') INSERT INTO table2 values ('Jack') INSERT INTO table2 values ('Mark') INSERT INTO table2 values ('Josh') INSERT INTO table2 values ('Fred') |
Deadlock Priority Example
First, let’s take a look at a practical example of how deadlock victims being selected based on their deadlock priority.
We will run two parallel instances of SSMS. Each instance will run one transaction that will be accessing a resource locked by the other transaction. A deadlock will occur and SQL server will then select as the victim the transaction that is the least expensive to roll back.
Script for the First Transaction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE testdb; -- Transaction1 BEGIN TRAN UPDATE table1 SET student_name = student_name + 'Transaction1' WHERE id IN (1,2,3,4,5) UPDATE table2 SET student_name = student_name + 'Transaction1' WHERE id = 1 COMMIT TRANSACTION |
Script for the Second Transaction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE testdb; -- Transaction2 BEGIN TRAN UPDATE table2 SET student_name = student_name + 'Transaction2' WHERE id = 1 UPDATE table1 SET student_name = student_name + 'Transaction2' WHERE id IN (1,2,3,4,5) COMMIT TRANSACTION |
The process of creating a deadlock is simple. First execute the first update statement from the first transaction and then execute the first update statement from the second transaction.
This will create locks on table1 and table2. Now execute the second update statement from transaction1. This statement tries to access table2 which is locked by transaction2.
Finally, execute the second update statement in transaction2. This statement tries to access table1 which is locked and at this stage a deadlock will occur.
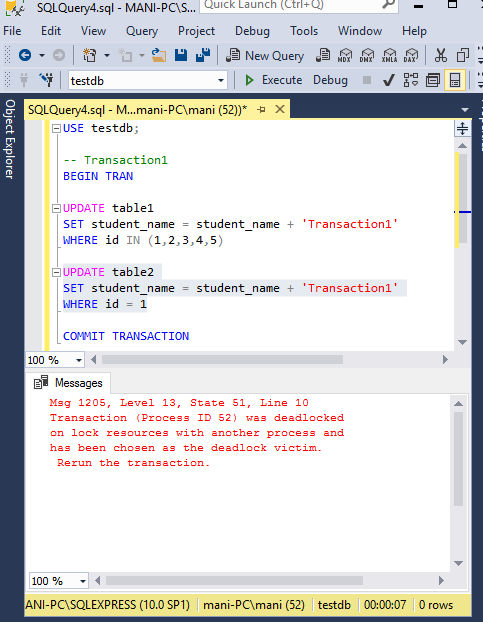
Now we know that by default, the deadlock priority for both of the transactions is NORMAL, therefore SQL server will select that transaction as deadlock victim which is least expensive to rollback.
The first UPDATE statement of transaction1, it is updating five rows of table1 whereas the first UPDATE statement of transaction2 is updating only one row in table2. This means that transaction2 is the least expensive to rollback.
After some time, you will see SQL Server select transaction2 as the deadlock victim and it will then roll it back as expected. The error message is shown in the following screenshot:
Now if you select the data from table1 you should see updated data as shown below:
| id | student_name |
| 1 | JamesTransaction1 |
| 2 | AndyTransaction1 |
| 3 | SalTransaction1 |
| 4 | HelenTransaction1 |
| 5 | JoTransaction1 |
| 6 | Wik |
Deadlock with Deadlock Priority set to High
In the next example, we will set the deadlock priority of transaction2 to HIGH and will again create a deadlock.
This time transaction1 will be selected as deadlock victim since it will have deadlock priority of NORMAL by default. Before we do that let’s clean our tables and re-insert the data into it.
Let’s truncate both the tables using following commands:
|
1 2 3 4 |
TRUNCATE TABLE table1; TRUNCATE TABLE table2; |
Now again add some data in table1 and table2 by executing the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE testdb; INSERT INTO table1 values ('Andy') INSERT INTO table1 values ('Sal') INSERT INTO table1 values ('Helen') INSERT INTO table1 values ('Jo') INSERT INTO table1 values ('Wik') INSERT INTO table2 values ('Rik') INSERT INTO table2 values ('Jack') INSERT INTO table2 values ('Mark') INSERT INTO table2 values ('Josh') INSERT INTO table2 values ('Fred') |
Again, lets run two instances of SSMS in parallel and execute two transactions in them.
The script for transaction1 is same as in the previous example. In transaction2, we need to set the deadlock priority to HIGH. The script for transaction2 is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE testdb; -- Transaction2 SET DEADLOCK_PRIORITY HIGH BEGIN TRAN UPDATE table2 SET student_name = student_name + 'Transaction2' WHERE id = 1 UPDATE table1 SET student_name = student_name + 'Transaction' WHERE id IN (1,2,3,4,5) COMMIT TRANSACTION |
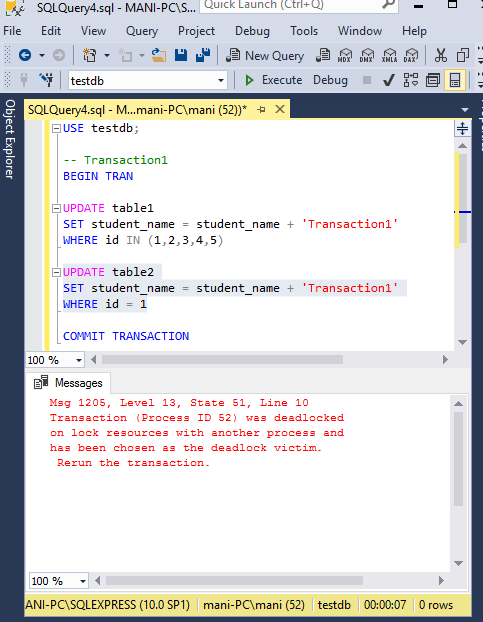
Now, repeat the same scenario as we did in the previous example and create a deadlock. This time you will see that transaction1 running in the first instance will be chosen as deadlock victim as shown in the following screenshot.
Conclusion
SQL Server selects deadlock victim following these rules:
- The process with the lowest deadlock priority is set as deadlock victim.
- If the deadlock priority of all the processes involved in deadlock is same, then the process that is least expensive to rollback is selected as deadlock victim.
- If both the deadlock priority and cost of processes involved in deadlock is same, then the process a process is selected randomly as deadlock victim.
Other great articles from Ben
| How To Use Window Functions |
| Understanding SQL Server query plan cache |
| How SQL Server selects a deadlock victim |

View all posts by Ben Richardson
- Working with the SQL MIN function in SQL Server - May 12, 2022
- SQL percentage calculation examples in SQL Server - January 19, 2022
- Working with Power BI report themes - February 25, 2021