
Every DBA knows that database grows over time and that the growth never stops. The more data is in the database, the more time (work) SQL Server is needed in order to deal with it. From SQL Server 2008 on, new tools are available in order to help DBAs to reduce the size of database.
This article will describe SQL Server data compression and the SSMS Data Compression Wizard will be explained.
The SQL Server data compression reduces the amount of physical disk space required to store data and the amount of disk I/O is saved by performing SQL Server data compression.
SQL Server data compression does not compress entire database at once, instead, it can be used on the following database objects:
- Table that is stored as a clustered index
- Table stored as a heap
- Partitioned tables and indexes
- Non-clustered index
- Indexed view
There are two types of SQL Server data compressions:
- Row level data compression
- Page level data compression
Row level data compression
Basically, row compression is the compression of data types, which means that this type of compression will take fixed character strings and store them as variable length data types and strip the blank characters.
For example, if the Char (150) data type for column is used and, for storing, the “This is test” date, only twelve characters are needed, the Row level data compression will strip the blank characters and only 12 characters are stored.
Row level data compression does not store NULL or 0 values, it reduces the quantity of metadata used to store a row.
More about Row level data compression can be found on the Row Compression Implementation page.
Page level data compression
This type of compression offers a higher level of SQL Server data compression then the Row level data compression but CPU usage is greater.
Page level data compression starts with Row level data compression and then uses additional two compressions: prefix and dictionary compressions.
Prefix compression removes repeating patterns from the beginning of the values in the column and replaces it with an appropriate reference. That information is saved in the compression information (CI) structure that immediately follows the page header.
Dictionary compression finds the repeated values on the whole age and places them in CI area.
The main difference between prefix compression and dictionary compression is that the prefix compression searches for repeated data on a column while the dictionary compression searches on repeated value on the whole a data page.
More about Page level data compression can be found on the Page Compression Implementation page.
Data Compression Wizard
The SQL Server data compression can be used via SQL Server Management Studio (SSMS) Data Compression Wizard or using T-SQL.
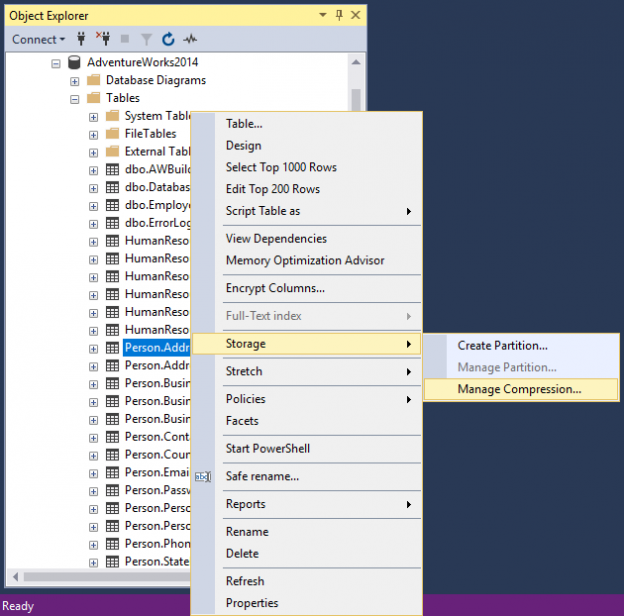
To compress the data using Data Compression Wizard, go to Object Explorer, find (select) a table which want to compress, right click and, from the Storage sub-menu, choose the Manage Compression command:
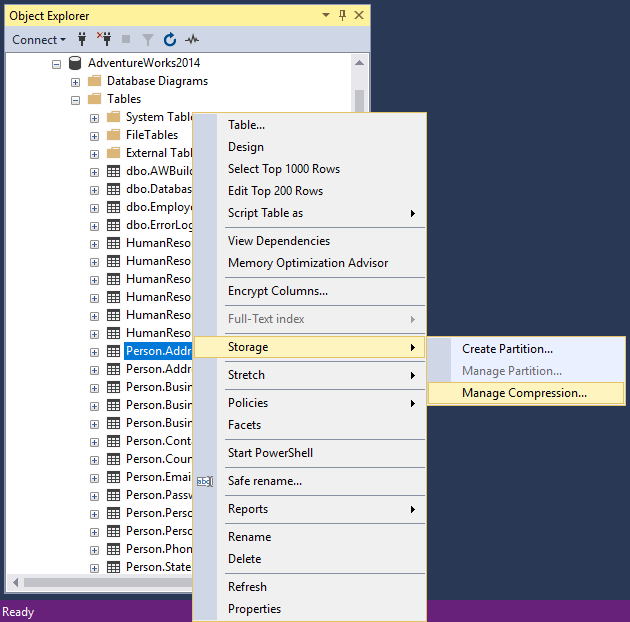
After clicking on the Manage Compression command, the Welcome page of the Data Compression Wizard will appear:
Showing this page on the start of the compression process is optional. To skip this page, next time, when launch the Data Compression Wizard, check the “Do not show this starting page again” check box.
To proceed, press the Next button. The next page that appears in the compression process is the Select Compression Type page:
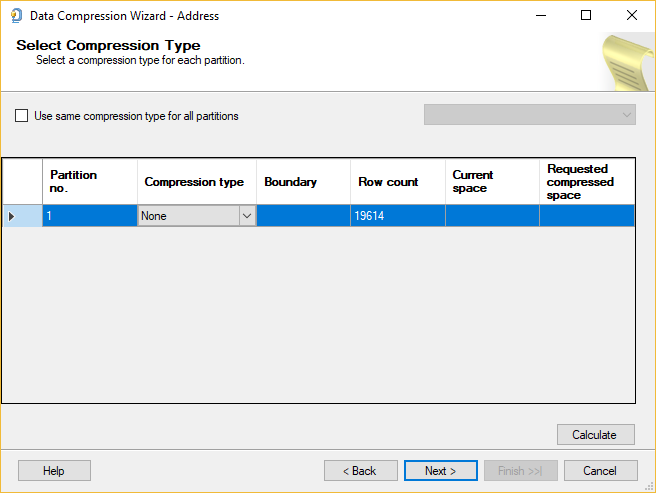
On this page, the compression type needs to be chosen. There are three types: Row, Page, None.
If the None type is selected, then no compression will be performed.
If an object (table, index) is partitioned, then, to enable the compression type on all partitions, the “Use the same compression type for all partitions”check box needs to be checked. This will enable drop down box and disable the Compression type box:
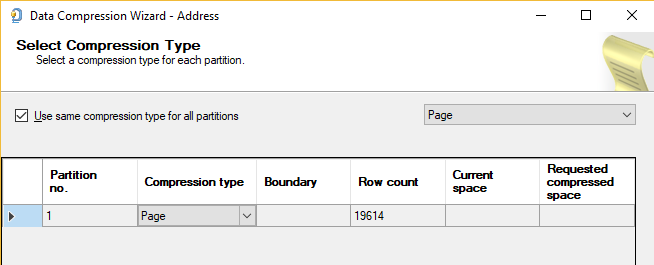
The Partition no. box will list all partitions that exist in a table/index. This field cannot be modified.
The Compression type column is for choosing a compression type for all partitions. If the “Use the same compression type for all partitions” check box is active, then the Compression type column is disabled.
The Boundary column shows the partition boundary. The Boundary column is the read-only column; which mean that cannot be modified.
The Row count column shows the total number of rows in partition. The Row count column cannot be modified (read-only).
The Current space column shows the size in megabytes (MB) which partition occupies. The data in this column cannot be modified (read-only).
The Requested compressed space column calculates the estimation size of the partition which will take after compression by using the type in the Compression type column. This value is visible after pressing the Calculate button and cannot be modified:
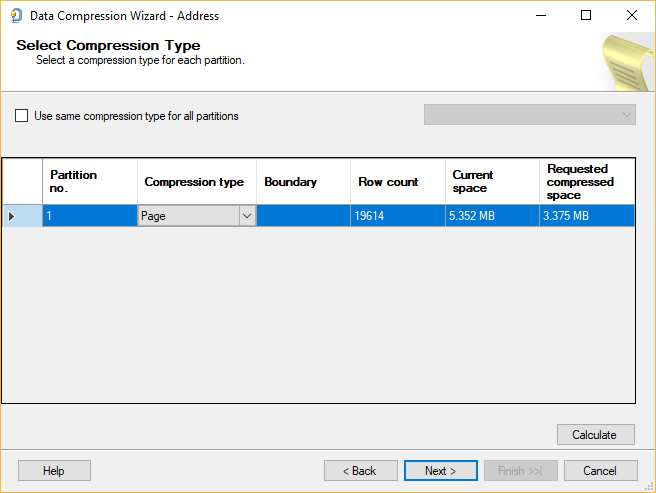
When click on the Calculate button, it calculates (estimates) the size of partitions. Depending on the value set in the Compression type column, the calculated (estimated) size will be displayed in the Requested compressed space column.
After the size estimation on the Select Compression Type is finished, press the Next button to continue. The next page is the Select an Output Option page:
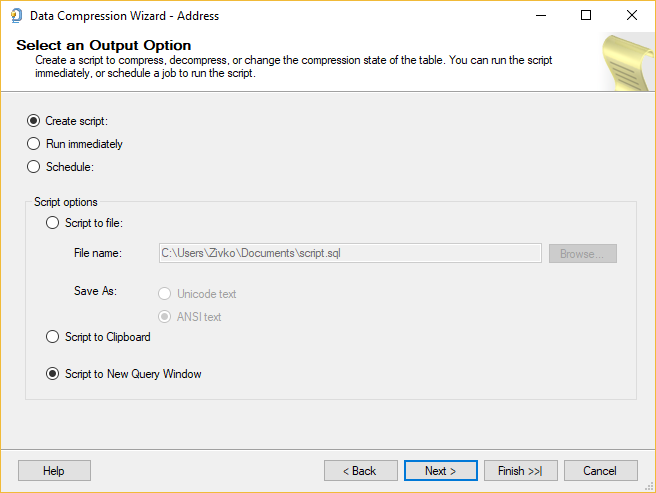
On this page, it can be set how the SQL Server data compression changes will be performed by:
- Creating script
- Run immediate
- Schedule
After choosing how the SQL Server data compression will be performed, in this example, the Run immediate action type is selected, click the Next button to proceed.
The next page that appears in the Data Compression Wizard is Summary page:
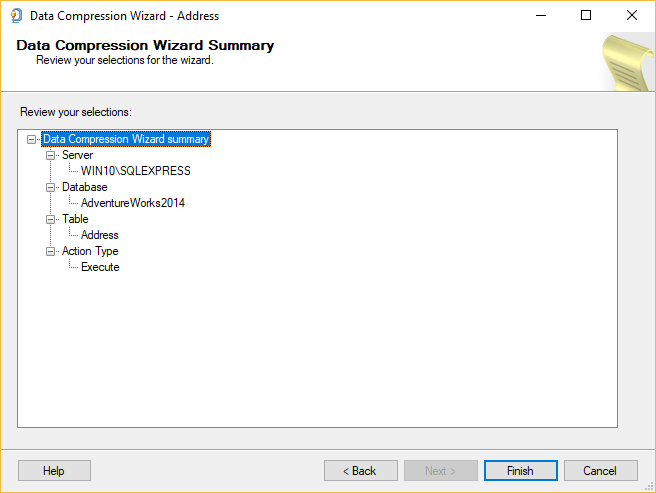
This page shows all action the Data Compression Wizard will take after pressing the Finish button.
The last page is the Compression Wizard Progress page which shows the progress information about the actions that are performed:
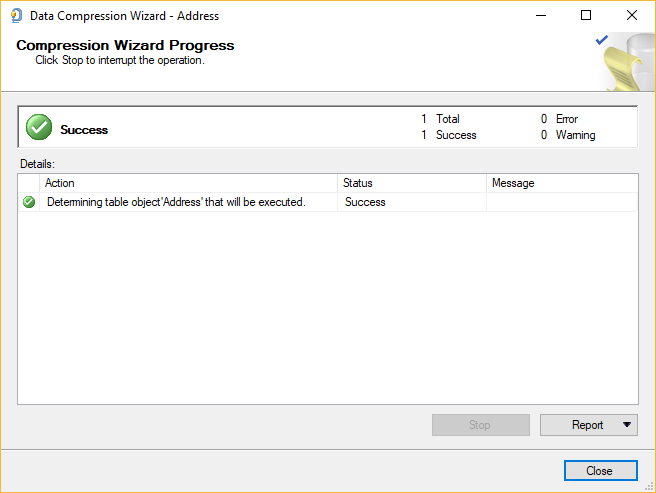
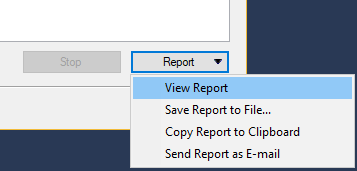
Under the Report button, a couple of options exist for creating a report that contains the results of the Data Compression Wizard:

He is a prolific author of authoritative content related to SQL Server including a number of “platinum” articles (top 1% in terms of popularity and engagement). His writing covers a range of topics on MySQL and SQL Server including remote/linked servers, import/export, LocalDB, SSMS, and more.
In his part-time, Zivko likes basketball, foosball (table-soccer), and rock music.
See more about Marko at LinkedIn
View all posts by Marko Zivkovic
- How to connect to a remote MySQL server using SSL on Ubuntu - April 28, 2020
- How to install MySQL on Ubuntu - March 10, 2020
- Using SSH keys to connect to a remote MySQL Server - November 28, 2019