
In this article, we will explore how to split native backup and restore for AWS RDS SQL Server from the AWS S3 bucket.
Introduction
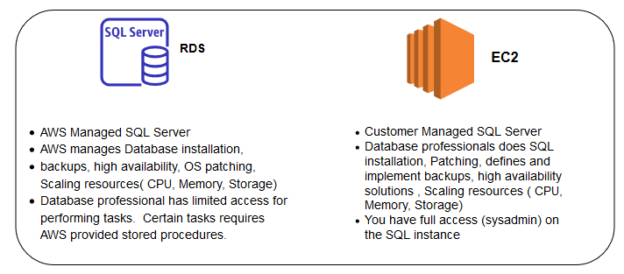
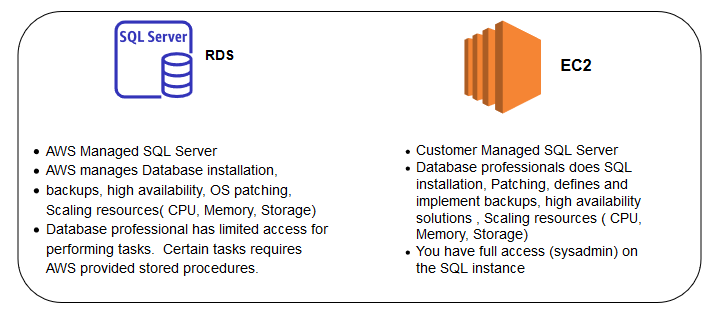
We can deploy SQL Server in Amazon Web Services (AWS) cloud infrastructure using the following ways.
- AWS Managed RDS SQL Server
- Customer Managed SQL Server
In the below table, we can see a high-level comparison between EC2 and RDS SQL.
In the traditional SQL Server, either on-premises or EC2 instance, we define the database backup policies. When we take full backup for a vast database, we should split it into multiple files. You can take advantage of multiple IOPS while writing the backups to the media. Also, if you do not have sufficient space in the drive, you can split the backups into multiple copies and place them on separate drives.
Apart from this, if you store your backup files on the cloud, it becomes easy for you to download the smaller files. The large backup file might take longer depending upon your network bandwidth. Suppose you upload or download a single backup file on the cloud. If any network interruption occurs, you might need to start the download or upload process again.
We will explore whether it is possible to take split native database backups for AWS RDS SQL Server.
Split backups for AWS RDS SQL Server databases
RDS automatically takes full and incremental snapshots for your SQL instances. You can perform recovery for your database instance in case of any issues. AWS automatically manages these snapshot backups for point-in-time recovery.
Refer to the article, Split SQL database backups into multiple backup files using SSMS for more details.
The default snapshot retention policy is as below:
|
Configured source |
Default backup retention |
|
AWS web console |
7 days |
|
AWS command-line tools (CLI) |
1 day |
|
AWS API |
1 day |
You can refer to the article, Explore Manual Snapshots in AWS RDS SQL Server for more details on AWS snapshots.
Environment details
- RDS instance: For this article, I assume that you have a running instance of AWS RDS SQL
Server. You can go through the article, Getting Started with AWS RDS SQL Server, for detailed instructions. For this article, I have [SQLShackDemo] DB instance
- SQL Server Version: SQL Server 2017 Express edition
- Region: ap-south-1b
- size: db.t3.medium
- Publicly accessible: Yes

AWS S3 Bucket: You should have an AWS S3 bucket in the same region where your RDS instance exists
- Bucket region: Asia Pacific (Mumbai)


Native backups for AWS RDS SQL Server
In the article, AWS RDS SQL Server migration using native backups, we learned that you could take native backups in RDS and store them into the S3 bucket.
To enable the native backup, you should do the following as specified in the URL.
- Define the IAM policy and provide permissions for the AWS S3 bucket
- Create a Role for AWS RDS SQL Server that uses the IAM policy we created in the above step
- Create an option group for SQL Server 2019 Express edition and add the SQLSERVER_BACKUP_RESTORE feature
- Modify RDS instance properties to use the new option group instead of the default group
By default, the RDS SQL instance does not have a user database. To work with a SQL database for split backups, we use the [AdventureWorks2017] database in the RDS instance. You need to follow the below steps.
- Download the [AdventureWorks2017] database full backup file from Microsoft docs
- Open the S3 bucket and upload the backup file
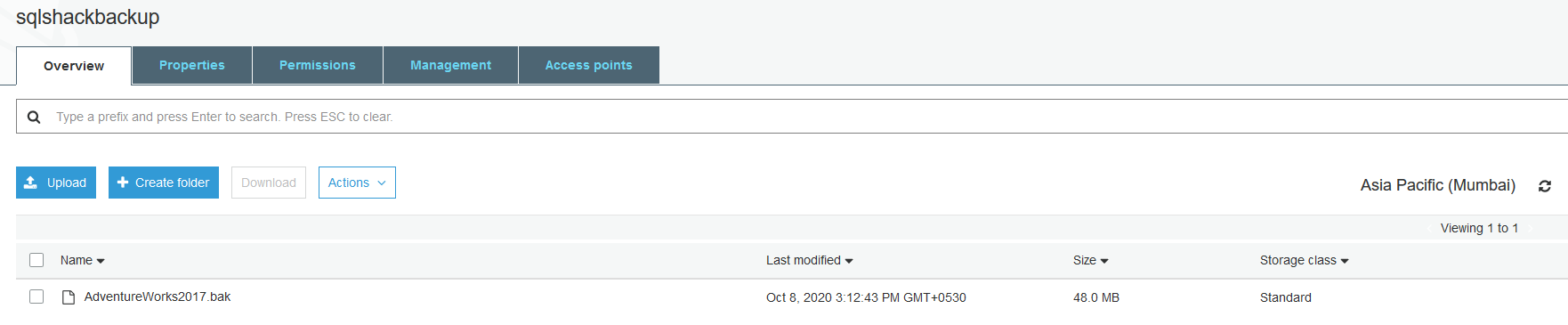
- Connect to the SQL Server and restore the native backup for [AdventureWorks2017] database in the RDS instance. In the RDS instance, we use the stored procedure msdb.dbo.rds_restore_database for restoration purposes
This stored procedure requires two-parameter:
- @restore_db_name: It is the database name for backup restoration
- @s3_arn_to_restore_from: It is the amazon resource name for the AWS S3 bucket object. You can specify S3 bucket ARN following by the backup file name as shown below
|
1 2 3 |
exec msdb.dbo.rds_restore_database @restore_db_name='AdventureWorks2017', @s3_arn_to_restore_from='arn:aws:s3:::sqlshackbackup/AdventureWorks2017.bak'; |
In the output, you get a task id and its details such as s3_object_arn, created_date.

You can use another stored procedure msdb.dbo.rds_task_status to track the restore status.

Take a split database backup for AWS RDS SQL Server
By default, AWS native backup creates a single file irrespective of the database size. For the native backup, we run the stored procedure msdb.dbo.rds_backup_database.
In the below query, we take a full database backup in the S3 bucket. The backup file name is AdventureWorks2017_Native1.bak
|
1 2 3 4 |
exec msdb.dbo.rds_backup_database @source_db_name='AdventureWorks2017', @s3_arn_to_backup_to='arn:aws:s3:::sqlshackbackup/AdventureWorks2017_Native1.bak', @overwrite_S3_backup_file=1; |
It takes the backup and stores in the S3 bucket. You can go back to the S3 bucket and refresh the contents. Here, we can see the native backup for the [AdventureWorks2017] backup.
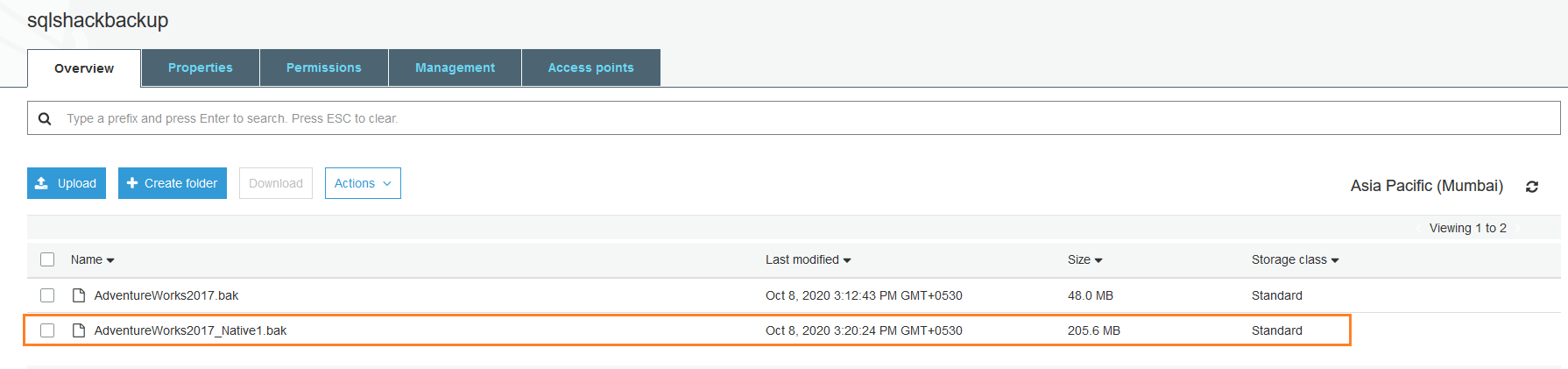
In the above image, notice a difference between the backup sizes.
- AdventureWorks2017.bak is the source backup file that we restored in the RDS instance. It is a compressed backup
- AdventureWorks2017_Native1.bak is the native database backup that we took from the RDS instance. It is an uncompressed backup file
If you want to take a compressed backup in the RDS instance, you can enable the compression using the following command. The point is that you cannot take compressed backup in the RDS express edition.

Suppose we have an extensive database and we want to utilize the split or multi-file backup functionality. TO do so, we add a new parameter @number_of_files in the t-SQL. The default value of this parameter is 1. Therefore, we do not need @number_of_files argument in the single backup file restore. You can split a backup file 10 times in the RDS database. Therefore, you can use the value in between 1 to 10 for a split backup.
For example, suppose we want to split the native backup for [AdventureWorks2017] into five backup files. In the below query, we make the following changes.
- Specify the backup file name as AdventureWorks2017_Split*.bak
- Specify the argument @number_of_files value as 5
|
1 2 3 4 5 |
exec msdb.dbo.rds_backup_database @source_db_name='AdventureWorks2017', @s3_arn_to_backup_to='arn:aws:s3:::sqlshackbackup/AdventureWorks2017_Split*.bak', @number_of_files=5, @overwrite_S3_backup_file=1; |

Track the backup task status using the following query:
|
1 |
exec msdb.dbo.rds_task_status @task_id=4 |

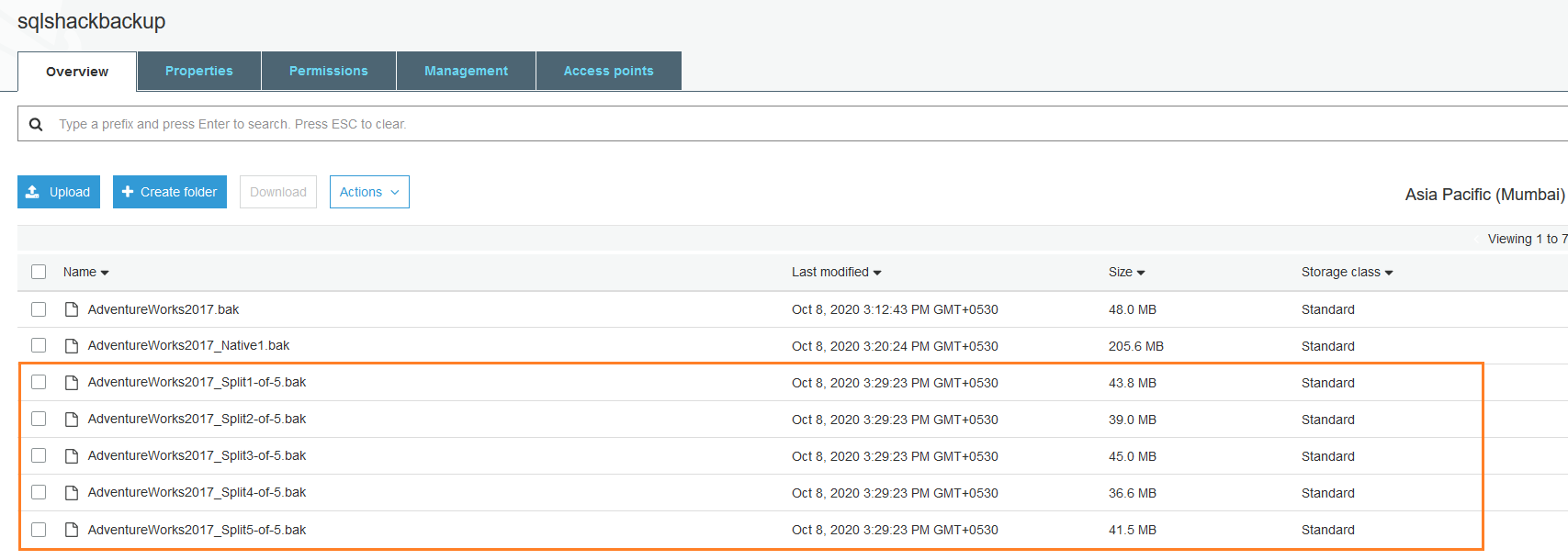
Once the lifecycle status changes to SUCCESS, refresh your S3 bucket. You have five (spitted) copy of your native backup. The size of each backup file may vary a little due to the extent of your database.
For the backup file, it automatically adds the suffix because we specified * for the file name in the query. The file names of the split backups are as below:
- AdventureWorks_Split1-of-5.bak
- AdventureWorks_Split2-of-5.bak
- AdventureWorks_Split3-of-5.bak
- AdventureWorks_Split4-of-5.bak
- AdventureWorks_Split5-of-5.bak
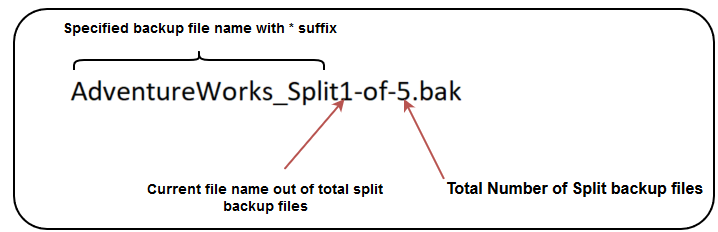
You can quickly understand the split backup file names using the below image. By looking at each file, you can identify how many backup files are there in the particular backup set.
Restore split native backups in AWS RDS SQL Server from AWS S3 buckets
We can restore the split backups stored in the AWS S3 bucket in the RDS instance. We do not require any specific argument for such backups restoration.
In the below query, look at the value for the @s3_arn_to_restore_from parameter. As we have multiple split backup files, we cannot specify a particular backup file for database restore. SQL Server requires all the split backup files for restoration purposes. Therefore, we specify the names of the backup files as AdventureWorks2017_Split*.
It checks for all files in the S3 bucket and finds the backup files whose name starts with AdventureWorks2017_Split.
|
1 2 3 |
exec msdb.dbo.rds_restore_database @restore_db_name='AdventureWorks2017_New', @s3_arn_to_restore_from='arn:aws:s3:::sqlshackbackup/AdventureWorks2017_Split*'; |
Once we execute the restoration, it processes all split files, builds a restoration plan and restores the database as per your specified name.

In the below status command, it shows database restoration is successful using the split backup files. On the left-hand side, object explorer shows the restored database [AdventureWorks2017].

- Note: While doing the restoration for split backups, we cannot specify the file name in the format as AdventureWorks2017_Split*.bak
|
1 2 3 |
exec msdb.dbo.rds_restore_database @restore_db_name='AdventureWorks2017_New', @s3_arn_to_restore_from='arn:aws:s3:::sqlshackbackup/AdventureWorks2017_Split*.bak'; |
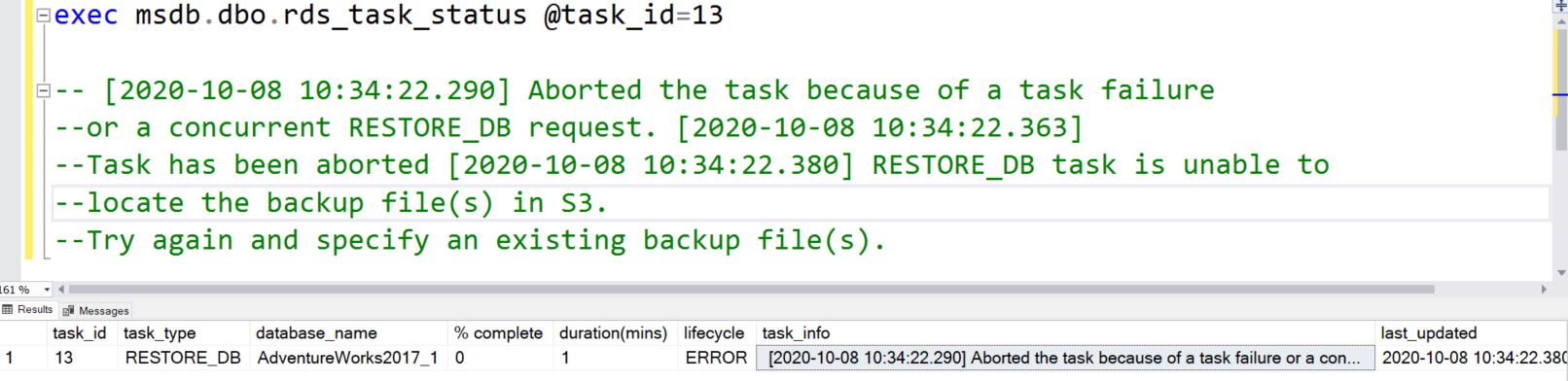
It starts the database restoration, but if you check the status, it gives you a failure message.

I have copied the error message from the task_info column (in green text). It fails because SQL Server is not able to locate the split backup files in the S3 bucket.
Conclusion
In this article, we learned the process to take split database backups and store in the AWS S3 bucket. Further, we restored the split native backups for the AWS RDS SQL Server.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023