
Background
From time to time, I’ve run into replication issues in inherited environments that I did not architect and some of these environments experienced errors in replication because of how it was constructed from the beginning. In this tip, we look at some of the basics in replication architecture and then at solving some of these problems. Some of the replication issues I’ve seen are caused by misunderstanding what is impossible and possible with replication.
Discussion
In an ideal replication set up, we have a publication server, distribution server, and a subscriber server (see the below image).
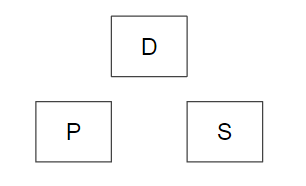
The reason for this design is scale from the beginning, especially if we’re replicating large data sets for analysis, as we can scale out publishers if we horizontally distribution publications and we can reduce the load on an individual distribution database. Companies looking to reduce or cut costs might want to consider using Microsoft Azure SQL for subscriptions to publications. Another helpful way to reduce costs is considering what version of SQL Server you’re using for the distributor, publisher and subscriber – for an example, if your heaviest analysis is on your subscriber, you might want to think about making sure it’s build to handle that load.
What would happen if I replicated one table to the same subscription twice in two different publications? In the below image, we see the exact same table with the same data set being replicated from two different publications to the exact same destination table – let’s assume that in this case it comes from the same database and same server.
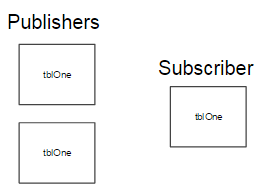
We will see primary key errors in the replication error log because the primary key is identical and we’re attempting to duplicate the data. I’ve seen this issue before where DBAs simply added replication on a target that already existed, and the errors flooding the log caused a tie up in the distribution database. This may also occur when a destination table receives data from two identical source tables that are on different servers; we will see in the subscriber folder the sources and can track which publications may be sending duplicate data.
Similar to the above issue, another error I’ve seen with replication that also involved poor architecture was replicating the same publisher table twice using different columns in each case to two different destinations on the same database, yet using the same underlying stored procedures. If we’re going to use stored procedures to replicate data, then we have to think about either naming them in a way that the stored procedure name is unique (including destination database, schema and table name in their name), or we may want to consider an alternate way to replicate the data – like direct inserts, updates or deletes. If we don’t, consider that the same named stored procedure will try to copy two different column data sets over to two different tables, and yet this is wrong. Typically, in these cases we’ll see data failures and skipped records and finally a publication going inactive. When we look at the stored procedure, we may realize that the definition doesn’t match one of the tables.
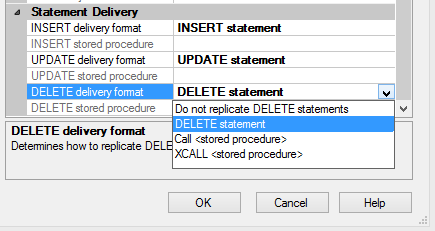
I do not like the idea of replicating the same table with a different column set of the table to the same subscriber (though there are exceptions in cases where the two together are significantly less than the full table as a whole), so I’ll generally push back on this and replicate the full table along with two views that will pull part of the table, or use Entity Framework for a select.
Other issue involves using DELETEs over drop-and-recreate or TRUNCATEs. I do not have any problems with using DELETEs, as there are situations where it is the only way to eliminate data, as inconvenient and slow as it is. DBAs who use these over the other methods must first understand what overhead will be added by using them and must optimize for them, otherwise they will experience issues.
Some useful tips and questions
First, always verify that what you’re planning to replicate doesn’t already exist. This is a very basic step in replication and it helps avoid flooding the error log with a meaningless error that reflects a misunderstanding of replication. In addition, adding replication to the exact same destination from the exact same source is wasteful. This would be like trying to create a database that already exists and getting upset when it fails – if it already exists, use it. The below basic query will tell you if you have a duplicate article being replicated to the same database schema and table on the same server – you would need to expand this on all publisher servers if you want to track across multiple servers:
|
1 2 3 4 5 6 7 8 |
SELECT a.publisher_db + '.' + a.source_owner + '.' + a.source_object AS SourceObject , s.subscriber_db + '.' + CASE WHEN a.destination_owner IS NULL THEN a.source_owner END + '.' + a.destination_object AS DestinationObject FROM MSarticles a INNER JOIN MSsubscriptions s ON a.publication_id = s.publication_id ORDER BY (s.subscriber_db + '.' + CASE WHEN a.destination_owner IS NULL THEN a.source_owner END + '.' + a.destination_object) DESC |
Second, DBAs should question whether replication needs to be added in the first place, as there are situations where other tools exist and are superior. For an example, timed-loads might be better with ETL. In the case of replicating the different column set of the same source table to the same destination database, how much do the two sets add in comparison to the full set of data, and why is that the choice over replicating the full table with two views, or allowing Entity Framework to select a different column set for the report or application? These architecture questions can save a lot of time when troubleshooting later. If something sounds wrong or redundant, always push back, as most redundancy is misunderstanding the problem.
Third, when using DELETEs over other methods, DBAs should do the following:
Optimize the logs for DELETEs, otherwise you will have to stay on top of log growth (log micromanagement). Additionally, DELETEs have an effect on the system’s resources as well; they do have their place, provided that a person stays on top of the effects. In my experience, log micromanagement increases the risk for integrity check failures; I highly advise against it. The best practice is to give your log drive at least double the maximum required space for replication if using DELETEs.
Do not promise clients or end users quick turn-arounds. DELETEs are incredibly slow whereas TRUNCATEs or drop-and-recreates are not. Microsoft even advises that if all data in the table must be removed, use TRUNCATE (see below references). If we choose a slow method, we can’t promise a quick turn-around.
Final thoughts
Many replication problems occur because of poor architecture and the same is just as true with custom made ETL design. If an environment commits to using replication, I’d suggest thinking about the design, being strict about the objects that are replicated and building validation steps both before and after replication processes. Without all of this in place, replication won’t be a solution, but a problem.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020