
Introduction
Database availability is critical to every enterprise and conversely, unavailability directly can create a severe negative impact to the business in today’s world. As database administrators, it is important that we ensure we take all possible steps to minimize data loss. While it is naïve to think that our databases are invincible because of all such precautions, we can always aim to bring the databases back into operation as quickly as possible by meeting the RPO and RTO. This way, the business is unaffected, and we also meet our SLAs.
Apart from good knowledge of the system, it is important we have a well-defined data and tested backup-and-restore strategy. Testing the backup-and-restore procedure to ensure quick recovery with minimal administrative overhead is one means towards that end. While advanced techniques such as AlwaysOn and Mirroring help ensure higher availability, disaster recovery is all about well-defined and tested backup and restoration methods.
When planning for disaster recovery techniques, here are some points about volatility that we need to keep in mind:
- How frequently is the table updated?
- Are your databases transactions highly frequent? If so, one must perform more frequent log backup than a full backup.
- How often does the database structure change?
- How often does the database configuration change?
- What are the data loading patterns and what is the nature of the data?
We must plan our backup-and-restore strategy keeping these aspects in mind. And to ensure the strategy is close to airtight, we need to try out all possible combinations of backup and restoration, observe the nuances in the results, and tune the strategy accordingly. So, we must:
- Consider the size of the database, the usage patterns, nature of the content, and so on.
- Keep in mind any of the configuration constraints, such as hardware or backup media.
In this article, we touch base on the aforementioned points, and decide on the requirements as well, based on attributes such as the database sizes, their internal details, and the frequency of changes. Let us now go ahead and look at the considerations that are important to build a backup strategy.
By the end of the article, we would be equipped with a couple of scripts that would give us all vital information in a nice tabular format, that would help us with planning and decision-making when it comes to backups and their restoration.
Background
Take a look at the business requirements, as each database may have different requirements based on the application it serves. The requirements may be based on:
- How frequently does the application access the database? Is there a specific off-peak period when the backups can be scheduled?
- How frequently does the data get changed? If the changes are too frequent, you may want to schedule incremental backups in between full backups. Differential backups also reduce the restoration time.
- If only a small part of a large database changes frequently, partial and/or file backups can be used.
- Estimate the size of a full backup. Usually, the backup is smaller than the database itself, because it does not record the unused space in a database.
This post demonstrates one of the ways to gather an inventory of database backup information. The output of the script includes various columns that show the internals of a database, backup size, and gives the latest completion statuses and the corresponding backup sizes. Though the output is derived from the msdb database, having the data consolidated at one place gives us better control and provides us with greater visibility into the database process. A clear understanding of these parameters is a good way to forecast storage requirements. We can schedule a job to pull the data to a central repository and then develop a report on capacity planning and forecasting on a broader spectrum of database backup. That way, we’d have an insight into the sizing of every backup type, such as Full, Differential and Log. With such information, we can easily decide on the type of backup required at a very granular level, i.e., at the database level.
Going this way, we can optimize our investments in storage and backup. It helps us decide on alternatives if needed. The base for every decision is accurate data. The accuracy of information gives us a baseline to decide the viable options to back up the SQL databases. The idea behind this implementation is to get the useful data using a technique native to SQL, and have brainstorming sessions based on that, to identify the best design and solution for the backup problem.Getting started
There are many ways to gather data in a central server repository such as using T-SQL and PowerShell. In this section, I’m going to discuss the data gathering tasks using PowerShell cmdlets.
The pre-requisites are
- Require SSMS version 16.4.1
- SQL Server PowerShell module
New cmdlets have been introduced with the SQL Server module, which is going to replace SQLPS, by retaining the old functionality of SQLPS with added set of rich libraries. It is safe to remove the SQLPS and load the SQL Server module.
You can remove the SQLPS using below command:
Remove-Module SQLPS
Load the SQL Server Module using the below command:
Import-Module SqlServer
The new cmdlets, Read-SQLTableData and Write-SqlTableData are introduced to load the data as SQLTABLE

With these cmdlets, a query can be executed and the results can be stored in a very simple way. It’s like storing everything as a table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Invoke-Sqlcmd -Query " SELECT name AS object_name ,SCHEMA_NAME(schema_id) AS schema_name ,type_desc ,create_date ,modify_date FROM sys.objects WHERE modify_date > GETDATE() - 10 ORDER BY modify_date;" -OutputAs DataTables | Write-SqlTableData -ServerInstance hqdbst11 -DatabaseName SQLShackDemo - SchemaName dbo -TableName SQLSchemaChangeCapture -Force |
- In this case we are writing T-SQL data into the table using the Write-SqlTableData cmdlet
-
I will be discussing these two parameters of Write-SqlTableData
- Passthru – It just inserts the records into the destination table
- Force – Creates an object if the object is missing in the destination
-
The below T-SQL provides 3 different levels of output:
-
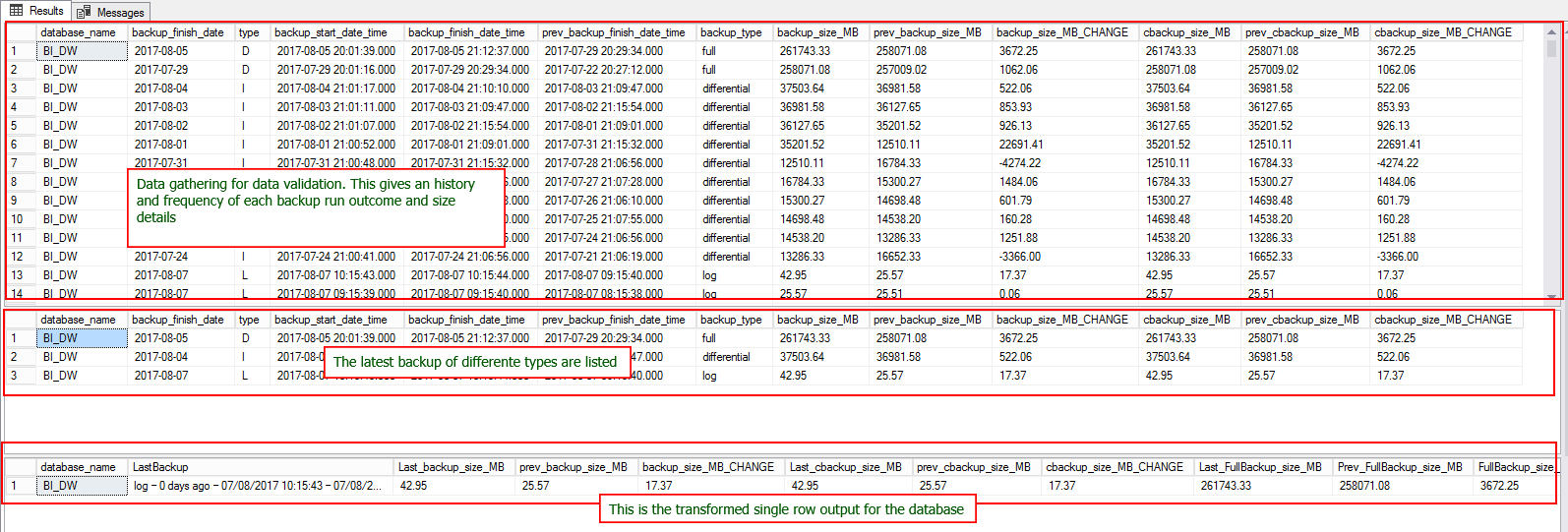
Base details – 1 row per backup.
- Shows backup size, previous backup size, and the change between the two
- Previous backup size based on the type and database
-
Latest backups per database per type
- with size changes from previous backup
- row per database per backup type
-
Base details – 1 row per backup.
-
Latest backups ONLY
- One row per database, containing details about the latest backup
- Each row includes individual columns for the last time each backup type was completed
- Each row includes backup sizes, types, previous sizes, and the difference between the two
- The output shows the nature of the backup and its corresponding sizes. This gives a clear indication of size estimates required for future growth which is in line with the retention period objective.
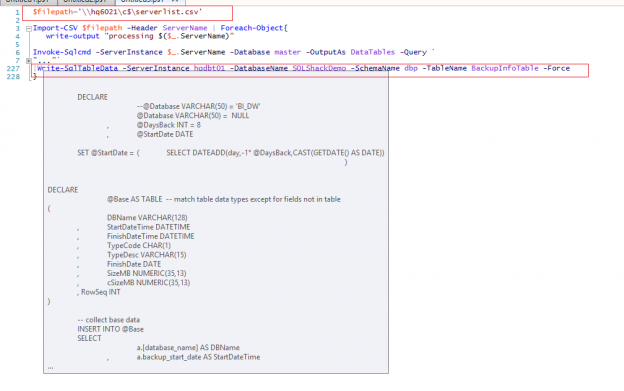
Let’s run the T-SQL to see the output yielding the desired data; the T-SQL is available at Appendix A. The output of the T-SQL is given below.
Let us now try to get the org-level information that would help us with planning. We’re going to use another T-SQL script, coupled with PowerShell. The PowerShell script is available at Appendix B.
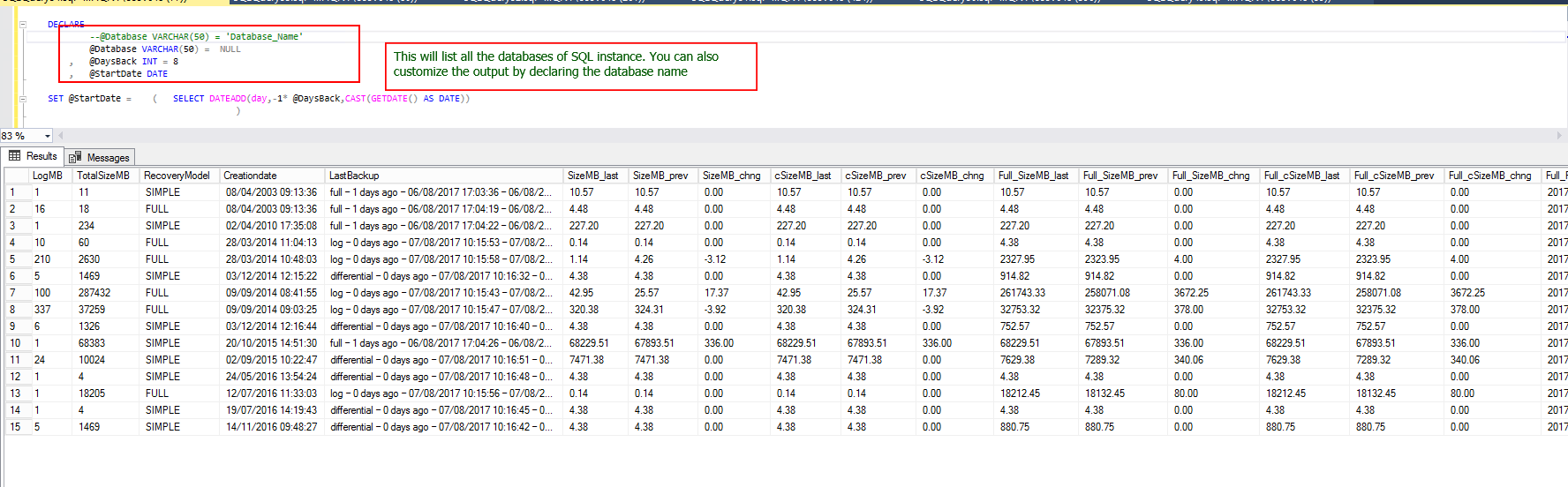
The PowerShell output window shows the data in a simple manner. With very few lines of code, the data is pulled and stored in a central repository (SqlShackDemo, in the BackupInfo table).
The T-SQL code is shown in gray. It’s just those few lines that do all the magic.
Summary
As administrators, we should understand the business impact that any amount of downtime causes. Business impact is measured based on the cost of the downtime and the loss of data, against the cost of reducing the downtime and minimizing data loss.
One of the ways of cost optimization is proper backup and restoration. To optimize costs, decision-making is required, and for that, data is required. We fetch the necessary data, and store it in a centralized repository, which is a great place to understand how the system is functioning. This data also helps us generate projections, pertaining to capacity planning and forecasting in terms of database backup.
Having a good understanding of the data and various test procedures for backup will help an administrator prevent various forms of failure by helping him maintain a low MTTR (Mean-Time-To-Recover) and MTBF (Mean-Time-Between-Failures).
Also, the use of the SQL Server PowerShell module along with the new cmdlets has made our life a lot easier, in that the PowerShell script output can be stored as Stables, with minimal efforts. The SQL Server module replaces the SQLPS—the old functionality still exists, but has been merged with a bunch of new functionalities.
The implementation discussed in this post gives us an ample amount of data that helps decide a good backup strategy and planning methodology, that meets our business needs.
References
- Nearly everything has changed for SQL Server PowerShell
- backupset (Transact-SQL)
- Introduction to Backup and Restore Strategies in SQL Server
Appendix (A)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 |
DECLARE @Database VARCHAR(50) = 'BI_DW' --@Database VARCHAR(50) = NULL -- collect base data SELECT a.[database_name] , a.backup_set_id , a.backup_start_date AS backup_start_date_time , a.backup_finish_date AS backup_finish_date_time , a.[type] , CASE a.[type] WHEN 'D' THEN 'full' WHEN 'L' THEN 'log' WHEN 'I' THEN 'differential' ELSE 'other' END AS backup_type , CASE a.[type] WHEN 'D' THEN 'Weekly' WHEN 'L' THEN 'Hourly' WHEN 'I' THEN 'Daily' ELSE 'other' END AS backup_freq_def , CAST(a.backup_finish_date AS DATE) AS backup_finish_date , a.backup_size/1024/1024.00 AS backup_size_MB , a.compressed_backup_size/1024/1024.00 AS cbackup_size_MB --, ROW_NUMBER()OVER(PARTITION BY a.[database_name], a.[type] ORDER BY a.backup_finish_date) AS Row_Seq , ROW_NUMBER()OVER(ORDER BY a.[database_name], a.[type], a.backup_finish_date DESC) AS Row_Seq -- this makes the last queries easier than the previous method INTO #Base FROM msdb.dbo.backupset a WHERE ( a.[database_name] = @Database OR @Database IS NULL ) AND a.backup_finish_date >= DATEADD(day,-21,CAST(GETDATE() AS DATE)) -- get 21 days so get at least 2 weeks of FULL backups to compare. filter to 14 for the rest in next query. -- create details from base SELECT a.[database_name] , a.backup_finish_date , a.[type] , a.backup_start_date_time , a.backup_finish_date_time , b.backup_finish_date_time AS prev_backup_finish_date_time , a.backup_type , CAST(a.backup_size_MB AS DECIMAL(10,2)) AS backup_size_MB , CAST(b.backup_size_MB AS DECIMAL(10,2)) AS prev_backup_size_MB , x.backup_size_MB_CHANGE , CAST(a.cbackup_size_MB AS DECIMAL(10,2)) AS cbackup_size_MB , CAST(b.cbackup_size_MB AS DECIMAL(10,2)) AS prev_cbackup_size_MB , x.cbackup_size_MB_CHANGE , a.Row_Seq INTO #Details FROM #Base a INNER JOIN #Base b -- do INNER, don't show the row with no previous records, nothing to compare to anyway except NULL ON b.[database_name] = a.[database_name] AND b.[type] = a.[type] AND b.Row_Seq = a.Row_Seq + 1 -- get the previous row (to compare difference in size changes CROSS APPLY ( SELECT CAST(a.backup_size_MB - b.backup_size_MB AS DECIMAL(20,2)) AS backup_size_MB_CHANGE , CAST(a.cbackup_size_MB - b.cbackup_size_MB AS DECIMAL(10,2)) AS cbackup_size_MB_CHANGE ) x WHERE a.backup_finish_date >= DATEADD(day,-14,CAST(GETDATE() AS DATE)) -- limit result set to last 14 days of backups -- Show details SELECT a.[database_name] , a.backup_finish_date , a.[type] , a.backup_start_date_time , a.backup_finish_date_time , a.prev_backup_finish_date_time , a.backup_type , a.backup_size_MB , a.prev_backup_size_MB , a.backup_size_MB_CHANGE , a.cbackup_size_MB , a.prev_cbackup_size_MB , a.cbackup_size_MB_CHANGE FROM #Details a ORDER BY a.Row_Seq -- can order by this since all rows are sequenced, not partitioned first. -- Show latest backups types per database with size changes from previous backup SELECT a.[database_name] , a.backup_finish_date , a.[type] , a.backup_start_date_time , a.backup_finish_date_time , a.prev_backup_finish_date_time , a.backup_type , a.backup_size_MB , a.prev_backup_size_MB , a.backup_size_MB_CHANGE , a.cbackup_size_MB , a.prev_cbackup_size_MB , a.cbackup_size_MB_CHANGE --, x.Row_Seq FROM #Details a CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database per type b.Row_Seq FROM #Details b WHERE b.[database_name] = a.[database_name] AND b.[type] = a.[type] ORDER BY b.backup_finish_date_time DESC ) x WHERE x.Row_Seq = a.Row_Seq -- only display the rows that match the latest backup per database per type ORDER BY a.Row_Seq -- get the latest backups ONLY per database, also show the other types in the same row -- Show latest backups types per database with size changes from previous backup SELECT a.[database_name] --, a.backup_finish_date AS latest_backup_finish_date --, a.backup_type AS latest_backup_type --, a.backup_finish_date_time --, a.prev_backup_finish_date_time , ISNULL( ( a.backup_type + ' – ' + LTRIM(ISNULL(STR(ABS(DATEDIFF(DAY, GETDATE(),a.backup_finish_date_time))) + ' days ago', 'NEVER')) + ' – ' + CONVERT(VARCHAR(20), a.backup_start_date_time, 103) + ' ' + CONVERT(VARCHAR(20), a.backup_start_date_time, 108) + ' – ' + CONVERT(VARCHAR(20), a.backup_finish_date_time, 103) + ' ' + CONVERT(VARCHAR(20), a.backup_finish_date_time, 108) + ' (' + CAST(DATEDIFF(second, a.backup_finish_date_time,a.backup_finish_date_time) AS VARCHAR(4)) + ' ' + 'seconds)' ), '-' ) AS LastBackup , a.backup_size_MB AS Last_backup_size_MB , a.prev_backup_size_MB , a.backup_size_MB_CHANGE , a.cbackup_size_MB AS Last_cbackup_size_MB , a.prev_cbackup_size_MB , a.cbackup_size_MB_CHANGE --, x.Row_Seq , f.* -- full backup sizes: lastest, previous, and change , d.* -- differential backup sizes: lastest, previous, and change , l.* -- log backup sizes: lastest, previous, and change FROM #Details a CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database b.Row_Seq FROM #Details b WHERE b.[database_name] = a.[database_name] ORDER BY b.backup_finish_date_time DESC ) x CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for full b.backup_size_MB AS Last_FullBackup_size_MB , b.prev_backup_size_MB AS Prev_FullBackup_size_MB , b.backup_size_MB_CHANGE AS FullBackup_size_MB_CHANGE , b.cbackup_size_MB AS Last_CFullBackup_size_MB , b.prev_cbackup_size_MB AS Prev_CFullBackup_size_MB , b.cbackup_size_MB_CHANGE AS CFullBackup_size_MB_CHANGE FROM #Details b WHERE b.[database_name] = a.[database_name] AND b.backup_type = 'full' ORDER BY b.backup_finish_date_time DESC ) f CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for differential b.backup_size_MB AS Last_DiffBackup_size_MB , b.prev_backup_size_MB AS Prev_DiffBackup_size_MB , b.backup_size_MB_CHANGE AS DiffBackup_size_MB_CHANGE , b.cbackup_size_MB AS Last_CDiffBackup_size_MB , b.prev_cbackup_size_MB AS Prev_CDiffBackup_size_MB , b.cbackup_size_MB_CHANGE AS CDiffBackup_size_MB_CHANGE FROM #Details b WHERE b.[database_name] = a.[database_name] AND b.backup_type = 'differential' ORDER BY b.backup_finish_date_time DESC ) d CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database for log b.backup_size_MB AS Last_LogBackup_size_MB , b.prev_backup_size_MB AS Prev_LogBackup_size_MB , b.backup_size_MB_CHANGE AS LogBackup_size_MB_CHANGE , b.cbackup_size_MB AS Last_CLogBackup_size_MB , b.prev_cbackup_size_MB AS Prev_CLogBackup_size_MB , b.cbackup_size_MB_CHANGE AS CLogBackup_size_MB_CHANGE FROM #Details b WHERE b.[database_name] = a.[database_name] AND b.backup_type = 'log' ORDER BY b.backup_finish_date_time DESC ) l WHERE x.Row_Seq = a.Row_Seq -- only display the rows that match the latest backup per database ORDER BY a.Row_Seq DROP TABLE #Base DROP TABLE #Details |
Appendix (B)
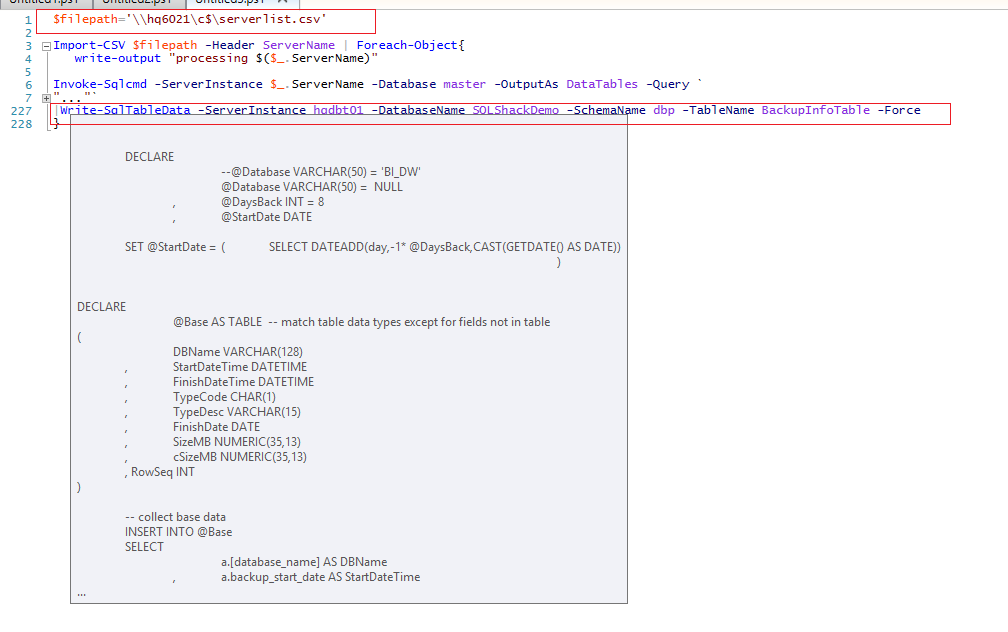
The T-SQL is executed across all the SQL instances listed in the input file
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 |
$filepath='\\hq6021\c$\serverlist.csv' Import-CSV $filepath -Header ServerName | Foreach-Object{ write-output "processing $($_.ServerName)" Invoke-Sqlcmd -ServerInstance $_.ServerName -Database master -OutputAs DataTables -Query ` " DECLARE --@Database VARCHAR(50) = 'BI_DW' @Database VARCHAR(50) = NULL , @DaysBack INT = 8 , @StartDate DATE SET @StartDate = ( SELECT DATEADD(day,-1* @DaysBack,CAST(GETDATE() AS DATE)) ) DECLARE @Base AS TABLE -- match table data types except for fields not in table ( DBName VARCHAR(128) , StartDateTime DATETIME , FinishDateTime DATETIME , TypeCode CHAR(1) , TypeDesc VARCHAR(15) , FinishDate DATE , SizeMB NUMERIC(35,13) , cSizeMB NUMERIC(35,13) , RowSeq INT ) -- collect base data INSERT INTO @Base SELECT a.[database_name] AS DBName , a.backup_start_date AS StartDateTime , a.backup_finish_date AS FinishDateTime , a.[Type] AS TypeCode , CASE a.[Type] WHEN 'D' THEN 'full' WHEN 'L' THEN 'log' WHEN 'I' THEN 'differential' ELSE 'other' END AS TypeDesc , CAST(a.backup_finish_date AS DATE) AS FinishDate , a.backup_size/1024/1024.00 AS SizeMB , a.compressed_backup_size/1024/1024.00 AS cSizeMB , ROW_NUMBER() OVER(ORDER BY a.[database_name], a.[Type], a.backup_finish_date DESC) AS RowSeq FROM msdb.dbo.backupset a WHERE ( a.[database_name] = @Database OR @Database IS NULL ) AND a.backup_finish_date >= DATEADD(week,-1,@StartDate) -- get extra week so 2 weeks of FULL backup come through -- create details from base ; WITH CTE_Details AS ( SELECT a.DBName , a.FinishDate , a.TypeCode , a.StartDateTime , a.FinishDateTime , b.FinishDateTime AS FinishDateTime_prev , a.TypeDesc , x.SizeMB , x.SizeMB_prev , x.SizeMB_chng , x.cSizeMB , x.cSizeMB_Prev , x.cSizeMB_chng , a.RowSeq FROM @Base a INNER JOIN @Base b -- do INNER, don't show the row with no previous records, nothing to compare to anyway except NULL ON b.DBName = a.DBName AND b.TypeCode = a.TypeCode AND b.RowSeq = a.RowSeq + 1 -- get the previous row to compare difference in size changes CROSS APPLY ( SELECT CAST(a.SizeMB - b.SizeMB AS DECIMAL(20,2)) AS SizeMB_chng , CAST(a.cSizeMB - b.cSizeMB AS DECIMAL(10,2)) AS cSizeMB_chng , CAST(a.SizeMB AS DECIMAL(10,2)) AS SizeMB , CAST(b.SizeMB AS DECIMAL(10,2)) AS SizeMB_prev , CAST(a.cSizeMB AS DECIMAL(10,2)) AS cSizeMB , CAST(b.cSizeMB AS DECIMAL(10,2)) AS cSizeMB_Prev ) x WHERE a.FinishDateTime >= @StartDate -- limit result set to last 14 days of backups ) -- get the latest backups ONLY per database, also show the other types in the same row -- Show latest backups types per database with size changes from previous backup -- include total log since last differential, and average differential since last full SELECT @@SERVERNAME Servername ,CONVERT(VARCHAR(25), a.DBName) AS dbName ,CONVERT(VARCHAR(10), DATABASEPROPERTYEX(a.DBName, 'status')) [Status] ,( SELECT COUNT(1) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid !=0 ) DataFiles ,( SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0 ) [DataMB] ,( SELECT COUNT(1) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0 ) LogFiles ,( SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0 ) [LogMB] ,( SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid!=0)+(SELECT SUM((size*8)/1024) FROM sys.sysaltfiles WHERE DB_NAME(dbid) = DB.name AND groupid=0 ) TotalSizeMB ,CONVERT(sysname,DatabasePropertyEx(name,'Recovery')) RecoveryModel , CONVERT(VARCHAR(20), crdate, 103) + ' ' + CONVERT(VARCHAR(20), crdate, 108) AS [Creationdate] -- , a.DBName , ISNULL(a.TypeDesc + ' – ' + LTRIM(ISNULL(STR(ABS(DATEDIFF(DAY, GETDATE(),a.FinishDateTime))) + ' days ago', 'NEVER')) + ' – ' + CONVERT(VARCHAR(20), a.StartDateTime, 103) + ' ' + CONVERT(VARCHAR(20), a.StartDateTime, 108) + ' – ' + CONVERT(VARCHAR(20), a.FinishDateTime, 103) + ' ' + CONVERT(VARCHAR(20), a.FinishDateTime, 108) + ' (' + CAST(DATEDIFF(second, a.FinishDateTime,a.FinishDateTime) AS VARCHAR(4)) + ' seconds)','-' ) AS LastBackup , a.SizeMB AS SizeMB_last , a.SizeMB_prev , a.SizeMB_chng , a.cSizeMB AS cSizeMB_last , a.cSizeMB_prev , a.cSizeMB_chng , f.* -- full backup sizes: lastest, previous, and change , d.* -- differential backup sizes: lastest, previous, and change , l.* -- log backup sizes: lastest, previous, and change , ( SELECT -- total log size since last differential sum(c.SizeMB) FROM CTE_Details c WHERE c.TypeDesc = 'log' AND c.DBName = a.DBName AND c.FinishDateTime >= d.diff_FinishDateTime_last -- since last differential GROUP BY c.DBName , c.TypeDesc ) AS Log_Total_SizeMB_SinceLastDiff , ( SELECT -- average differential size since last full sum(c.SizeMB) FROM CTE_Details c WHERE c.TypeDesc = 'differential' AND c.DBName = a.DBName AND c.FinishDateTime >= f.full_FinishDateTime_last -- since last differential GROUP BY c.DBName , c.TypeDesc ) AS Diff_Avg_SizeMB_SinceLastFull FROM CTE_Details a INNER JOIN ( SELECT -- do this rather than Cross apply, doesn't perform query for each row. MAX(b.FinishDateTime) AS FinishDateTime , b.DBName FROM CTE_Details b GROUP BY b.DBName ) x ON x.DBName = a.DBName AND x.FinishDateTime = a.FinishDateTime --CROSS APPLY ( SELECT TOP 1 -- get the latest backup record per database -- b.RowSeq -- FROM CTE_Details b -- WHERE b.DBName = a.DBName -- ORDER BY -- b.FinishDateTime DESC -- ) x OUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for full b.SizeMB AS Full_SizeMB_last , b.SizeMB_prev AS Full_SizeMB_prev , b.cSizeMB_chng AS Full_SizeMB_chng , b.cSizeMB AS Full_cSizeMB_last , b.cSizeMB_Prev AS Full_cSizeMB_prev , b.cSizeMB_chng AS Full_cSizeMB_chng , b.FinishDateTime AS Full_FinishDateTime_last FROM CTE_Details b WHERE b.DBName = a.DBName AND b.TypeDesc = 'full' ORDER BY b.FinishDateTime DESC ) f OUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for differential b.SizeMB AS Diff_SizeMB_last , b.SizeMB_prev AS Diff_SizeMB_prev , b.cSizeMB_chng AS Diff_SizeMB_chng , b.cSizeMB AS Diff_cSizeMB_last , b.cSizeMB_Prev AS Diff_cSizeMB_prev , b.cSizeMB_chng AS Diff_cSizeMB_chng , b.FinishDateTime AS Diff_FinishDateTime_last FROM CTE_Details b WHERE b.DBName = a.DBName AND b.TypeDesc = 'differential' ORDER BY b.FinishDateTime DESC ) d OUTER APPLY ( SELECT TOP 1 -- get the latest backup record per database for log b.SizeMB AS Log_SizeMB_last , b.SizeMB_prev AS Log_SizeMB_prev , b.cSizeMB_chng AS Log_SizeMB_chng , b.cSizeMB AS Log_cSizeMB_last , b.cSizeMB_Prev AS Log_cSizeMB_prev , b.cSizeMB_chng AS Log_cSizeMB_chng , b.FinishDateTime AS Log_FinishDateTime_last FROM CTE_Details b WHERE b.DBName = a.DBName AND b.TypeDesc = 'log' ORDER BY b.FinishDateTime DESC ) l inner join sys.sysdatabases DB on db.name=a.DBName --WHERE x.RowSeq = a.RowSeq -- only display the rows that match the latest backup per database "` |Write-SqlTableData -ServerInstance hqdbt01 -DatabaseName SQLShackDemo -SchemaName dbp -TableName BackupInfoTable -Force } |

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021