
Introduction
Azure SQL Data Warehouse is a new addition to the Azure Data Platform. When I first heard about it I wasn’t quite sure about what exactly it would be. As it turns out it is relational database for large amounts of database and really big queries as a service. This is essentially the equivalent of the APS (Analytics Platform System) in the cloud.
In this article, I will explore the Azure SQL DW and look at some of its key features to determine what the best use cases would be.

The Basics
Provisioning an Azure SQL Data warehouse is simple enough. Once logged into Azure, go to New ->
Databases -> SQL Data Warehouse.

In the SQL Data Warehouse blade enter the following fields:
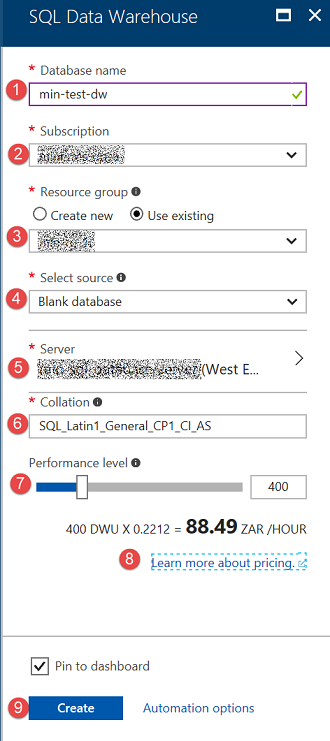
| No | Item | Description |
| 1 | Database Name | Select a name for your DW. This name must be unique for the selected server. |
| 2 | Subscription | Choose which of your Azure subscriptions you’d like to use if you have more than one. |
| 3 | Resource Group | Select an existing resource group or create a new one. If you are doing experiments, it always good to put all the resources in the same resource group. That way when you are done, you can simply delete the resource group, and it will delete everything. |
| 4 | Select Source |
One of 3 available options.
|
| 5 | Server | If you do not have an existing server, you will be able to create one here. This can be the same server you may have used previously for a SQL DB |
| 6 | Collation | Just like SQL Server, you must pick the collation. Choose carefully as it cannot be changed after you created the database. |
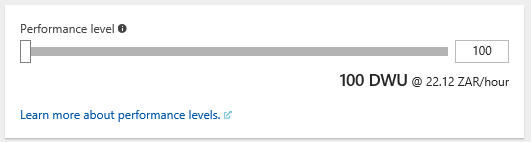
| 7 | Performance Level | This slider is used to scale up or down the number of Data Warehouse Units you’d like to use. A DWU is a measurement used to calculate the compute power of a data warehouse. |
| 8 | Pricing | When you have selected your DWU’s it will show an estimated cost of running your data warehouse per hour. |
| 9 | Create | Click on create to provision your data warehouse. This takes a couple of minutes. |
Once the DW has been provisioned you can connect to it using SSMS, remember that you have to configure the server firewall to allow access from your client.
In SSMS you will see that the icon for your DW looks different to that of a regular SQL DB.
The icon looks like a bunch of databases together, which is quite apt if we look at the architecture…
Architecture
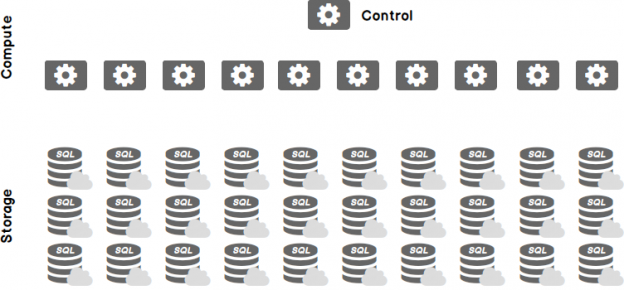
Azure SQL Data Warehouse uses distributed data and a massively parallel processing (MPP) design. The storage is de-coupled from the compute and control nodes, and as such, it can be scaled independently.
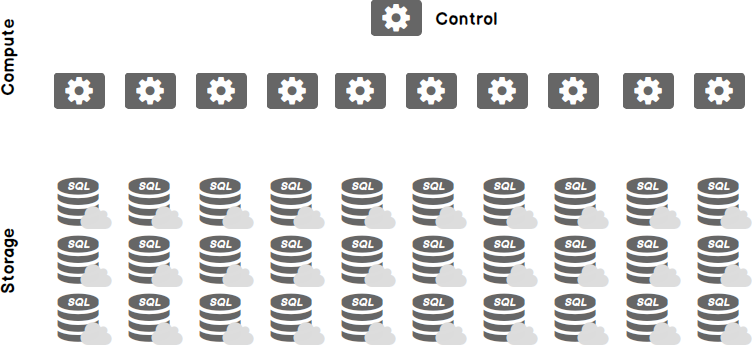
SQL DW data is distributed into 60 distributions, but it can have 1 or more compute node, depending on the number of DWUs that you select.
In my SQL DW created above I selected 400 DTU. Let’s have a look at what that gives me.
|
1 2 3 4 5 6 |
SELECT distinct pdw_node_id, MIN(distribution_id) [min_distributions_id], MAX(distribution_id) [max_distributions_id] FROM SYS.pdw_distributions GROUP BY pdw_node_id ORDER BY 2 |
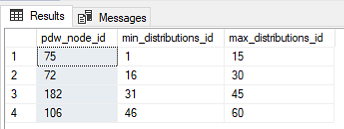
I can see here that I have 4 compute nodes, and that each node has 15 distributions. You can play around with this, but essentially as the number of compute nodes change the number of distributions will only be re-arranged to be equally distributed between the compute nodes. The distributions will always add up to 60. If you chose DWU 6000 you will essentially get a 1 to 1 ratio of compute to storage.
Azure SQL DW has two different types of distributions that can be used. The type of distribution is specified when a table is created.
-
Round Robin distribution
With this distribution, data is randomly assigned to each distribution. It assigns the data pretty evenly across all 60 distributions. Round-robin is the default distribution. In some cases, this can result in poorer performance than the hash distribution, because when assigning the rows it does not take the row content into account.
-
Hash distribution
This distribution allows you to pick a column to use as a hashing key. Selecting the wrong column to be used for the hashing function can result in unevenly distributed data (data skew). So be sure to select a column which has a lot of distinct values ideally 60 or more, since the data will be distributed amongst 60 distributions.
Use Cases
Azure SQL DW is best used for analytical workloads that makes use of large volumes of data and needs to consolidate disparate data into a single location.
Azure SQL DW has been specifically designed to deal with very large volumes of data. In fact, if there is too little data it may perform poorly because the data is distributed. You can imagine that if you had only 10 rows per distribution, the cost of consolidating the data will be way more than the benefit gained by distributing it.
SQL DW is a good place to consolidate disparate data, transform, shape and aggregate it, and then perform analysis on it. It is ideal for running burst workloads, such as month end financial reporting etc.
Azure SQL DW should not be used when small row by row updates are expected as in OLTP workloads. It should only be used for large scale batch operations.
Loading data
One of the key features of Azure Data Warehouse is the ability to load data from practically anywhere using a variety of tools.
Since PolyBase is built in, it can be used to load data parallelly from Azure blob storage. You can also use Azure Data Factory to facilitate the load from Azure blob storage with PolyBase.
Additionally, SQL Server Integration Services (SSIS), AZCopy, BCP, Import/ Export can be used.
Scaling Compute
Because storage and compute is decoupled in Azure Data Warehouse, it can be scaled independently.
Compute is measured in DWUs (Data warehouse units), your DWUs determines how many compute nodes you will have and the ratio of distributions to compute nodes. To scale compute you need to change the DWU setting. Scaling happens within minutes, so you can play around with it to find the optimal configuration.
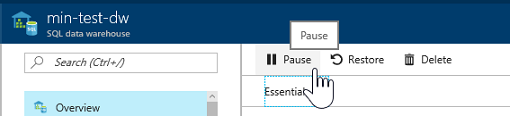
Another great thing about Azure SQL DW compute is that it can be paused. While it is paused, you won’t incur any costs for DWUs. This is really handy if you only need your DW some of the like, like for month end reporting etc.
Conclusion
Azure SQL Data Warehouse, is the ideal solution for when you need massively parallel processing. Unlike the on-premises equivalent (APS), Azure SQL DW is easily accessible to anyone with a workload using the familiar T-SQL language.
References

Minette currently works as a Data Platform Solution Architect at Microsoft South Africa.
View all posts by Minette Steynberg
- The end is nigh! (For SQL Server 2008 and SQL Server 2008 R2) - April 4, 2018
- 8 things to know about Azure Cosmos DB (formerly DocumentDB) - September 4, 2017
- Introduction to Azure SQL Data Warehouse - August 29, 2017