
Introduction
Among many different things that can affect SQL Server performance, some are more significant than others. In addition, some changes can be relatively easy to implement, but others are quite painfully:
- Schema design has the single biggest impact on performance, but it’s also almost impossible to change afterwards
- Proper indexes also can switch a database to “turbo mode”, and they can be relatively easy added to production systems
- Query optimization should be the third task in performance tuning — the impact can be significant, but more often than not it requires changes on the client side
- Concurrency control, like switching from locking to versioning, can help in some specific cases
- Hardware tuning should be the last option.
Through this series we are going to evaluate end to end indexing strategy that helps you improve SQL Server overall performance without affecting others aspects of production systems, like data consistency, client applications behavior or maintenance routines.
Four different table structures
Before SQL Server 2014 we had only two options:a table could be a heap or a b-tree. Now data can also be stored inside in-memory tables or in form of columnstore indexes. Due to the fact that these structures are completely different, the very first step of index strategy is to choose the correct table structure. To help you take informed decision, I’m going to compare available options.
Test environmentLet’s start with a sample database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
USE [master]; GO IF DATABASEPROPERTYEX (N'Indices', N'Version') > 0 BEGIN ALTER DATABASE Indices SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DROP DATABASE Indices; END GO CREATE DATABASE Indices CONTAINMENT = NONE ON PRIMARY ( NAME = N'Indices', FILENAME = N'e:\SQL\Indices.mdf' , SIZE = 500MB , FILEGROWTH = 50MB ) LOG ON ( NAME = N'Indices_log', FILENAME = N'e:\SQL\Indices_log.ldf' , SIZE = 250MB , FILEGROWTH = 25MB ) GO ALTER DATABASE Indices SET RECOVERY SIMPLE; GO USE Indices GO |
In addition to this, we will need a tool that allows us to simulate and measure user activity(all we need is the ability to execute queries simultaneously and monitor execution times as well as number of read/write pages). You will find a lot of tools such as those in the Internet – I chose SQLQueryStress, a free tool made by Adam Mechanic.
Heaps
A table without clustered index is a heap — just a set of unordered pages. This is the simplest data structure available, but as you will see definitely not the best one:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE dbo.Heap( id INT IDENTITY(1,1), fixedColumns CHAR(200) CONSTRAINT Col2Default DEFAULT 'This column mimics all fixed-legth columns', varColumns VARCHAR(200) CONSTRAINT Col3Default DEFAULT 'This column mimics all length-legth columns', ); GO |
Let’s check how long it takes to load 100000 rows into this table using 50 concurrent sessions — for this purpose I’m going to execute simple INSERT INTO dbo.Heap DEFAULT VALUES; statement with number of iteration set to 2000 and number of threads to 50.
On my test machine (SQL Server 2014, Intel Pentium i7 with SSD drive), it took 18 seconds, in average. As a result we got these 3300 pages of table:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT index_type_desc,avg_page_space_used_in_percent ,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats (db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed'); GO; ------------------------------------------------------------------------------------- HEAP 97,2869038794168 300,090909090909 3301 100000 0 258 |
Of course, because there is no ordering whatsoever, the only way to get a row from this table is through a scan:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SET STATISTICS IO ON; SELECT * FROM dbo.Heap WHERE id=2345; GO ---------------------------------------------------------------------------------------------------------- (1 row(s) affected) Table 'Heap'. Scan count 1, logical reads 3301, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
Not only SELECT performance is bad, UPDATEs against heaps are also really slow. In order to see it we need two queries: the first one will return some numbers and will be used for parameter substation, the second one will be executed in 5 concurrent sessions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT 9 AS nr UNION SELECT 13 UNION SELECT 17 UNION SELECT 25 UNION SELECT 29; UPDATE dbo.Heap SET varColumns = REPLICATE('a',200) WHERE id % @var = 0; |
The results are shown in the picture below (4 noticed exceptions were due to deadlocks):
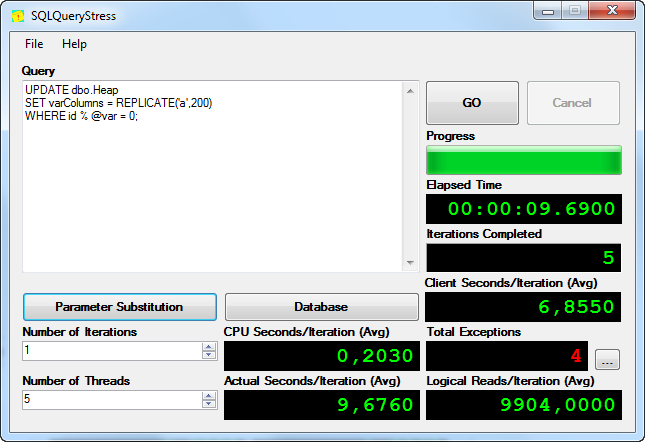
Altogether 7 700 rows were modified, it means that we achieved about 800 modifications per second.
Not only UPDATEs are slow, but they can have a side effect that will affect the performance of queries and will last till the heap is rebuilt. Now I’m talking about forwarded records (if there is not enough space on a page to store new version of a record, the part of it will be saved on a different page, and only forwarding pointer to this page will be stored with the remaining part of this record). In this case more than 3000 forwarded records were created:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT index_type_desc,avg_page_space_used_in_percent ,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats (db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed'); ---------------------------------------------------------------------------------------- HEAP 96,9105263157895 316,090909090909 3477 103160 3160 262,446 |
The remaining operations, DELETEs, also have unwanted side effects — space taken by deleted records will not be reclaim automatically:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DELETE dbo.Heap WHERE id % 31 = 0; SELECT index_type_desc,avg_page_space_used_in_percent ,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats (db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed'); GO ---------------------------------------------------------------------------------------- HEAP 93,8075858660736 316,090909090909 3477 99827 3052 262,461 |
At this point the only way of reclaiming this space and getting rid of forwarded records is to rebuild a table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ALTER TABLE dbo.Heap REBUILD; SELECT index_type_desc,avg_page_space_used_in_percent ,avg_fragment_size_in_pages,page_count,record_count,forwarded_record_count, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats (db_id(), OBJECT_ID('dbo.Heap'), NULL, NULL, 'detailed'); ---------------------------------------------------------------------------------------- HEAP 97,7820607857672 195,647058823529 3326 96775 0 270,076 |
Recommendations
Because of suboptimal SELECT performance, and side effects of UPDATE and DELETE statements, heaps are sometimes used for logging and stage tables — in first case, rows are almost always only inserted into a table, in the second one we try maximize data load by inserting rows into a heap and after moving them to a destination, indexed table. But even for those scenarios heaps are not necessary the best (more on this topic in upcoming articles). So, the first step our indexing strategy is to find heaps. Quite often these tables will be unused, so they will have no or minimal impact on performance. This is why you should concentrate on active heaps — one of the standard ways of finding them in current database is to execute this query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT t.name, ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates, ius.last_user_scan FROM sys.indexes i INNER JOIN sys.objects o ON i.object_id = o.object_id INNER JOIN sys.tables t ON o.object_id = t.object_id INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id LEFT OUTER JOIN sys.dm_db_index_usage_stats ius ON i.object_id = ius.object_id AND i.index_id = ius.index_id WHERE i.type_desc = 'HEAP' AND COALESCE(ius.user_seeks, ius.user_scans, ius.user_lookups, ius.user_updates) IS NOT NULL AND o.is_ms_shipped = 0 AND o.type <> 'S'; ---------------------------------------------------------------- Heap 0 1 0 0 2014-09-24 15:42:38.923 |
With this list in hand you should start asking serious question why these tables are heaps. And if no excuses were given, covert them into different structures.
What is coming next?
In the next article two new table structures (in-memory tables and columnstore indexes) will be described and compared with heaps.

A consultant, lecturer, authorized Microsoft trainer with 15 years’ experience, and a database systems architect. He prepared Microsoft partners for the upgrade to SQL Server 2008 and 2012 versions within the Train to Trainers program.
A speaker at numerous conferences, including Microsoft Technology Summit, SQL Saturday, Microsoft Security Summit, Heroes Happen {Here}, as well as at user groups meetings. The author of many books and articles devoted to SQL Server.
View all posts by Marcin Szeliga
- Index Strategies – Part 2 – Memory Optimized Tables and Columnstore Indexes - October 30, 2014
- Index Strategies – Part 1 – Choosing the right table structure - October 6, 2014