
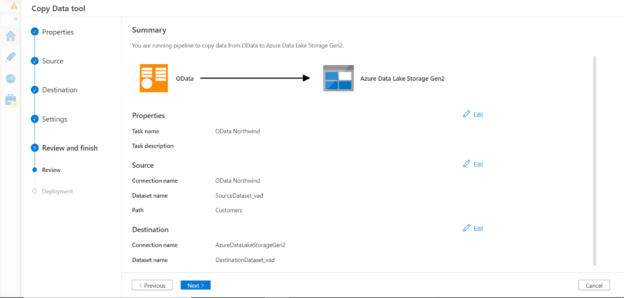
In this article, we will learn how to use Azure Data Factory to import data from OData APIs on Azure storage repositories.
Introduction
Data practice has the following major part – Data Collection, Data Preparation and Curation, Data Management, and Data Consumption. Typically, data consumption is viewed as a practice of accessing data from data repositories by connecting to it using database drivers. NoSQL databases employ APIs to facilitate read-write operations on the data repositories. Another popular and modern approach to consume data is by using Application Programming Interfaces a.k.a. APIs. One of the most well-known forms of APIs is REST APIs, which is one of the architecture standards for APIs. OData is extended sets of guidelines on the top of REST APIs that are often used to define the data model in the APIs for facilitating data ingestion as well as consumption using these data APIs. OData has been a popular standard for interfacing with data and with the cloud becoming the preferred platform for hosting data, there comes a need to consume import data from data repositories that enable data access using their published OData APIs. On the Azure cloud platform, various data repositories can host a variety of data. Using Azure Data Factory, we can import data from OData APIs and populate different types of data repositories and facilitate data exchange using the OData APIs. Let’s move forward and learn how to use Azure Data Factory in importing data from OData APIs on Azure storage repositories.
What is OData?
Before we proceed with the actual implementation of importing data from the OData feeds, let’s understand few important basics of OData in a little more detail for conceptual clarity. Representational State Transfer (REST) is a resource-based architectural style or pattern. OData is an application-level protocol. Microsoft introduced OData in 2007 and over the years it became an industry-standard protocol. While REST is a generic set of guidelines to build REST APIs, OData can be considered a technology that can be used to enable data access using interoperable REST APIs. Data exposed via OData APIs typically have AtomPub or JSON as the output format. If an OData connector is used to access data from OData APIs, the connector generally takes care of converting these data formats into a standard tabular format which can be readily loaded into the destination data repository.
Importing OData Feed
Now that we understand OData at a high level, we are ready to proceed with the actual implementation. We intend to use the OData API as the source and one of the supported Azure data repositories as the destination. We would be using Azure Data Factory as the ETL or importing tool that would fetch data from source to destination. For this, firstly we need an OData API that publishes some data which we can consume. One of the most popular and freely available OData API is the Northwind OData APIs which exposes several tables with sample data and is based on the popular Northwind sample database distributed by Microsoft in the early versions of SQL Server. This service can be accessed from this URL. If one can reach this API via a standard internet connection, an Azure Storage account with a container in it already exists, and an Azure Data Factory instance is already created, we are ready to start the actual implementation.
Navigate to the Azure Data Factory instance and open the dashboard page. Click the Author and monitor link to open the Azure Data Factory portal, and you should be able to see the home page as shown below.
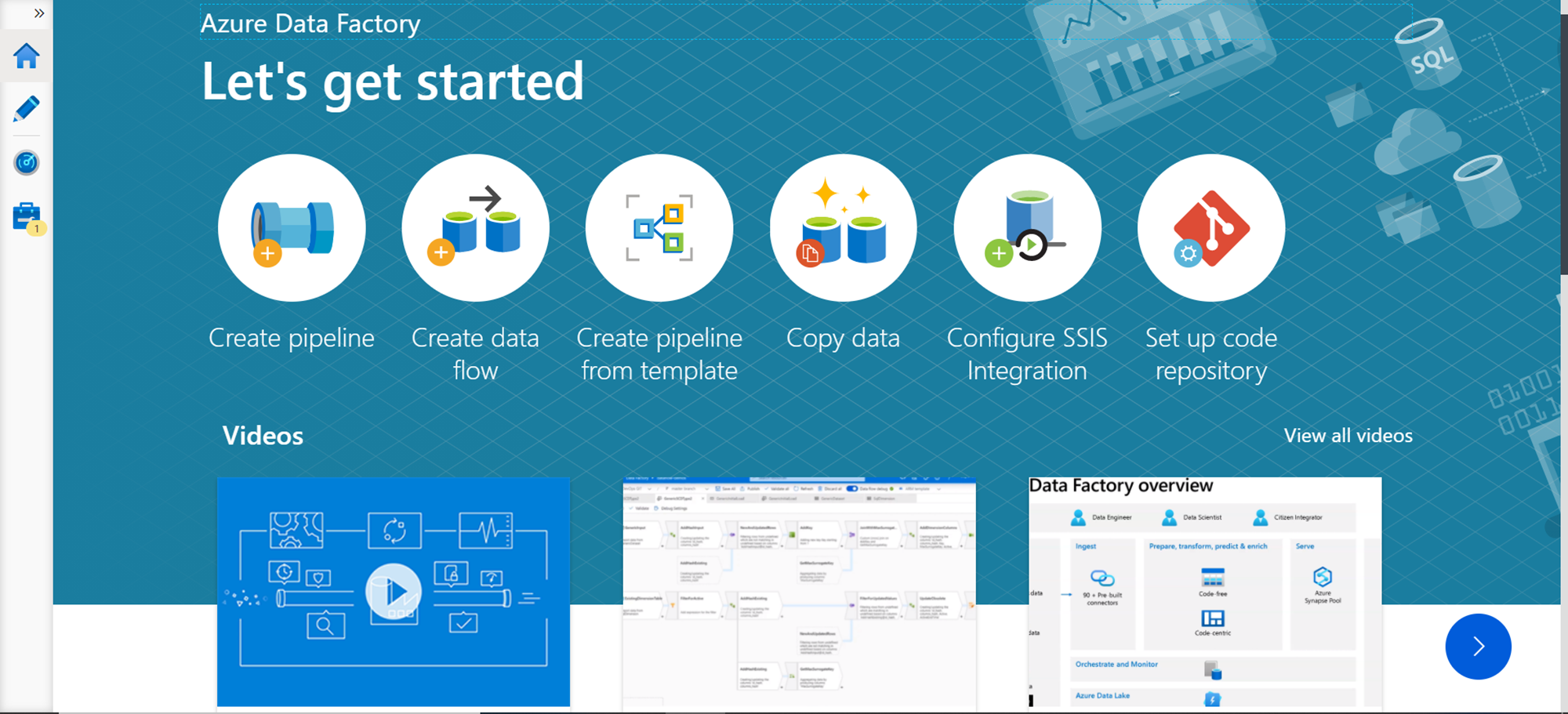
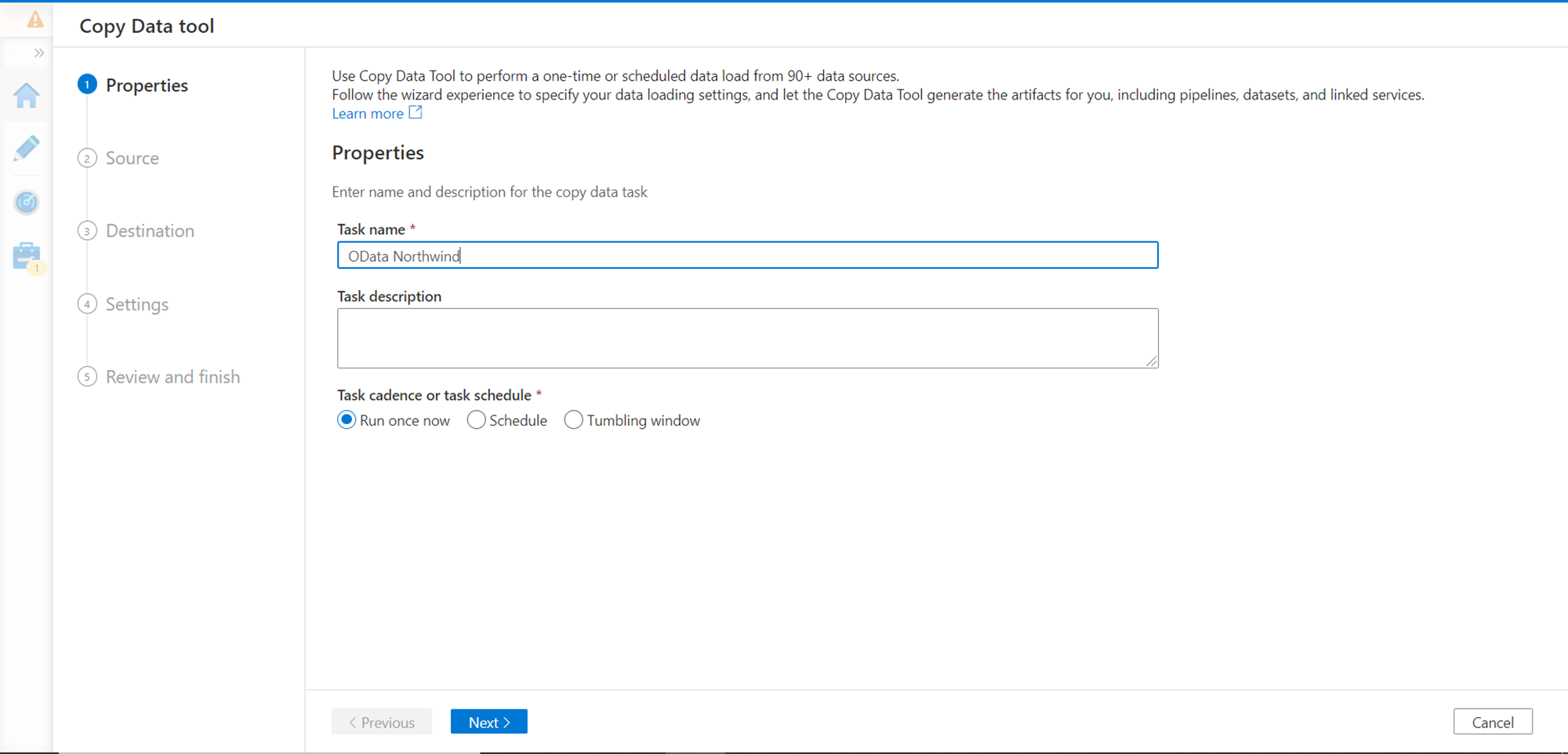
We intend to import data from the OData APIs, so we can directly use the copy tool. Click on the Copy data icon and it would initiate the copy wizard as shown below. Provide an appropriate name for this task. For now, we intend to execute this task only once, so we can continue with the default option of Run Once now as the execution frequency.
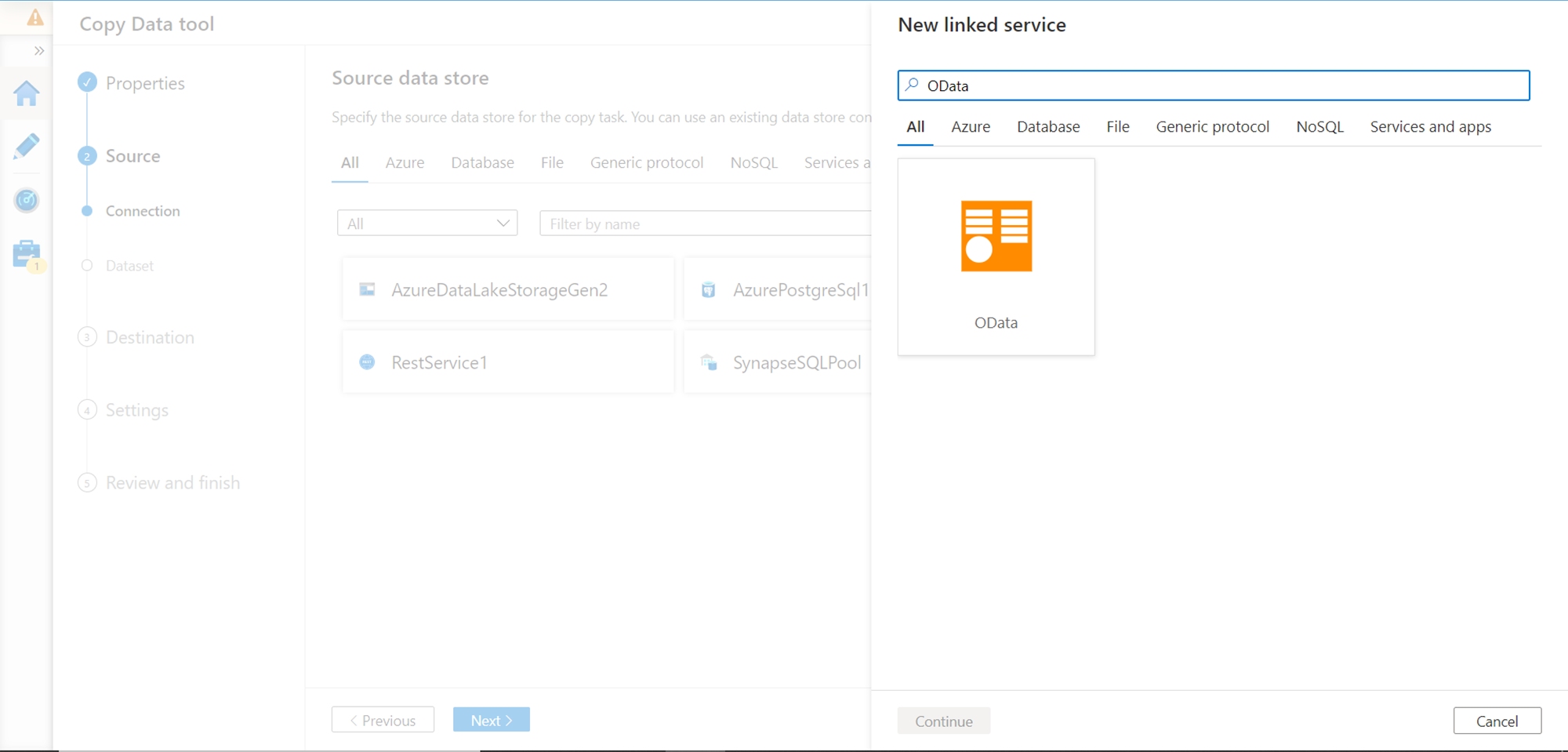
In the next step, we need to select the source data repository. Search for OData and you would find it as shown below. We need to create a new linked service of OData type. Click on the OData icon and then click on the Continue button to move to the next step.
In this step, we need to configure the details to connect to the OData API. Provide an appropriate name for this connection. We can use the existing Auto Resolve Integration Runtime which is selected by default. Key in the service URL of the OData API in the Service URL field. This connection supports multiple types of authentication mechanisms, but in our case, it’s a publicly accessible API, so we would use the Anonymous style of authentication as shown below.
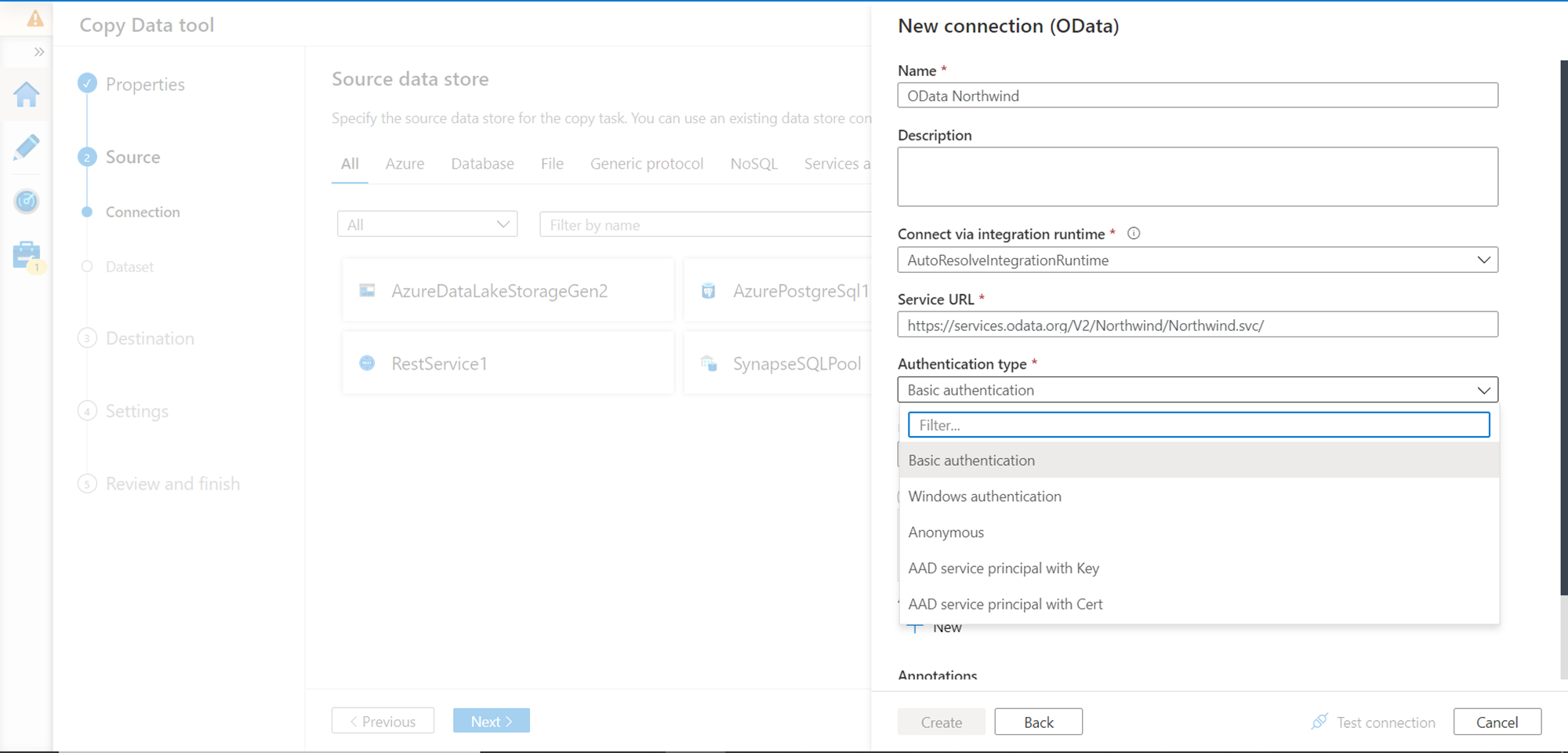
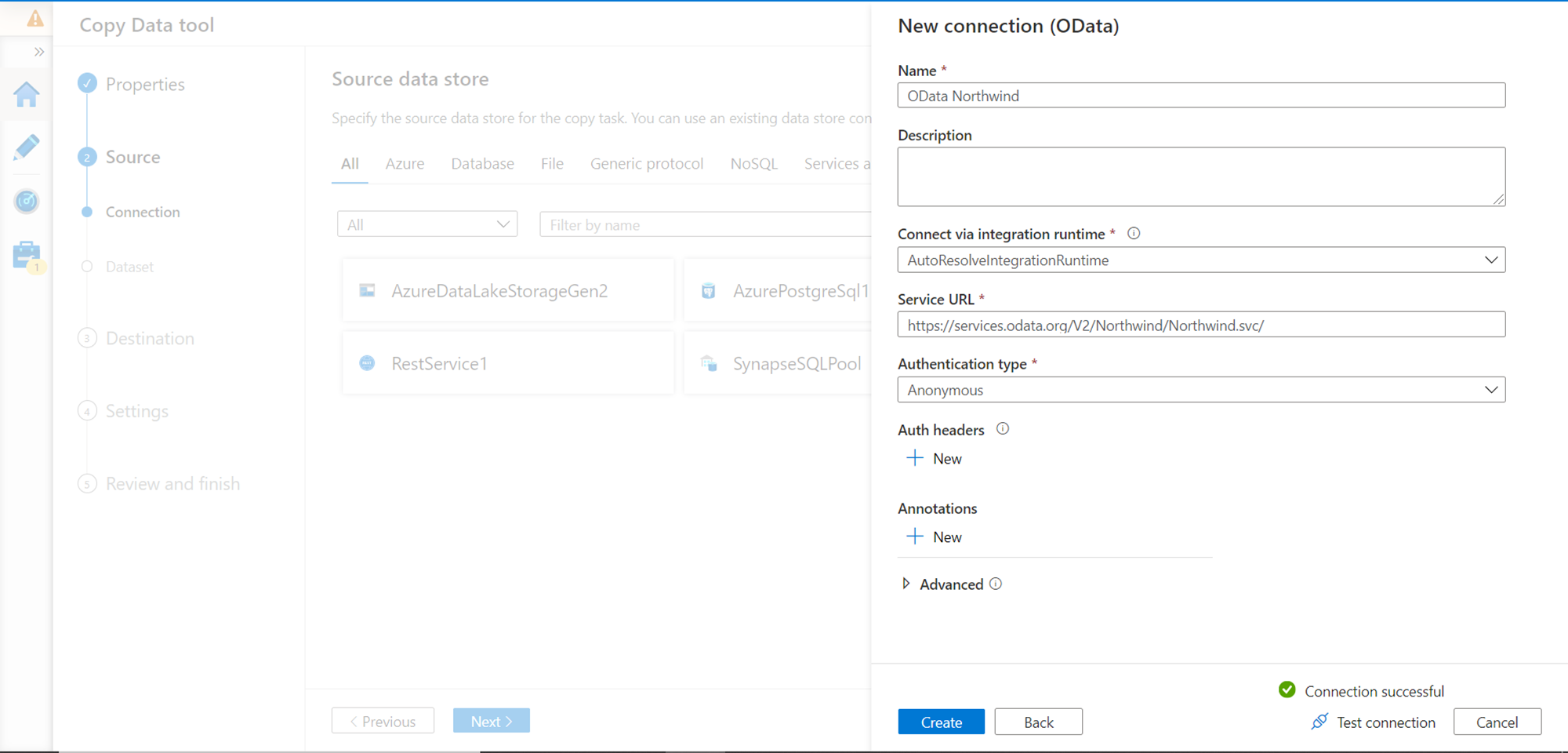
Once the configuration is done, click on the Test Connection button, and if everything is configured correctly, the connection should be successful as shown below. Click on the Create button and proceed to the next step.
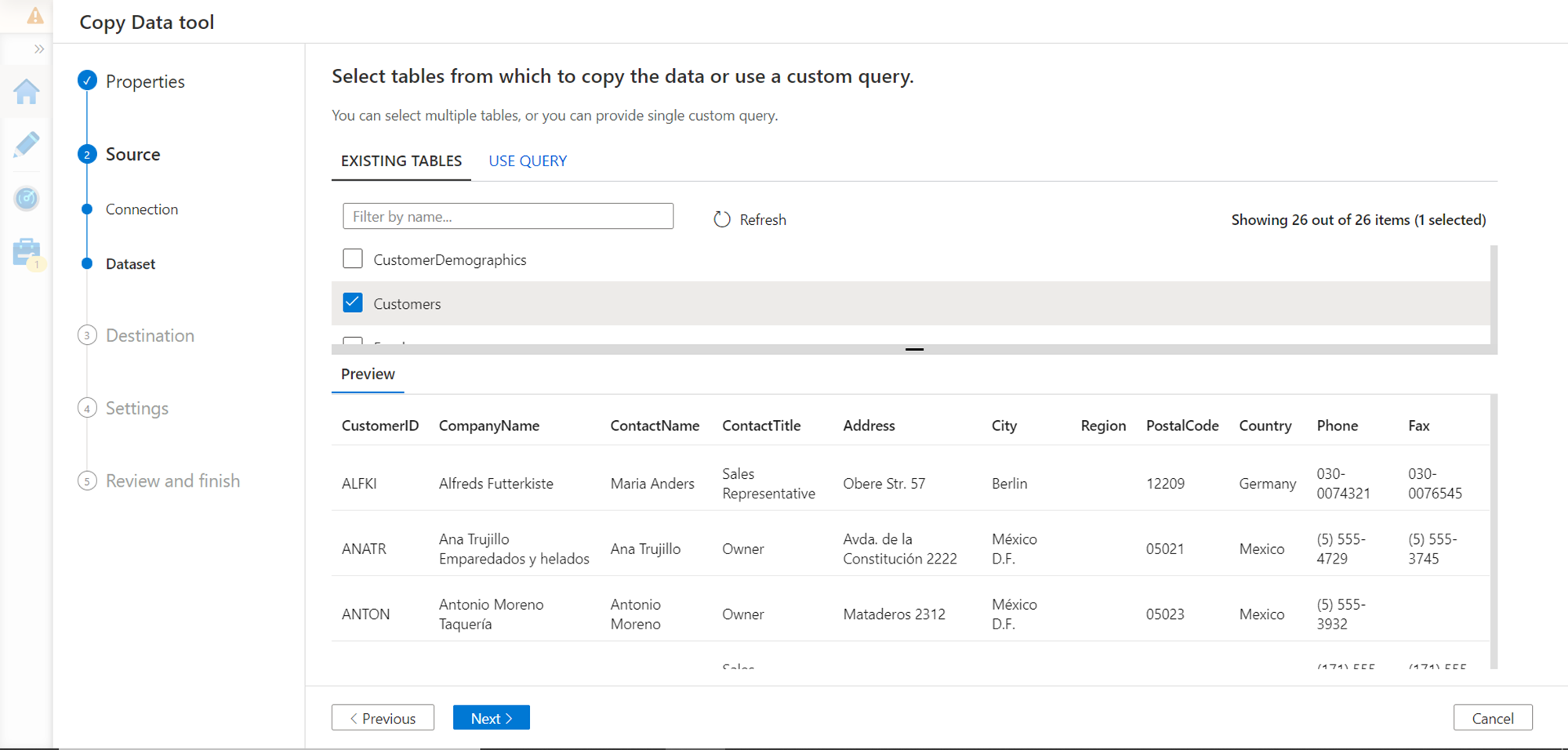
In this step, we need to configure the datasets that we intend to import. Based on the definition of the API, we would be presented with a list of tables to select from. One of the tables in the list is the Customers table, select the same and you would be able to preview the data as well as shown below. Proceed to the Next step.
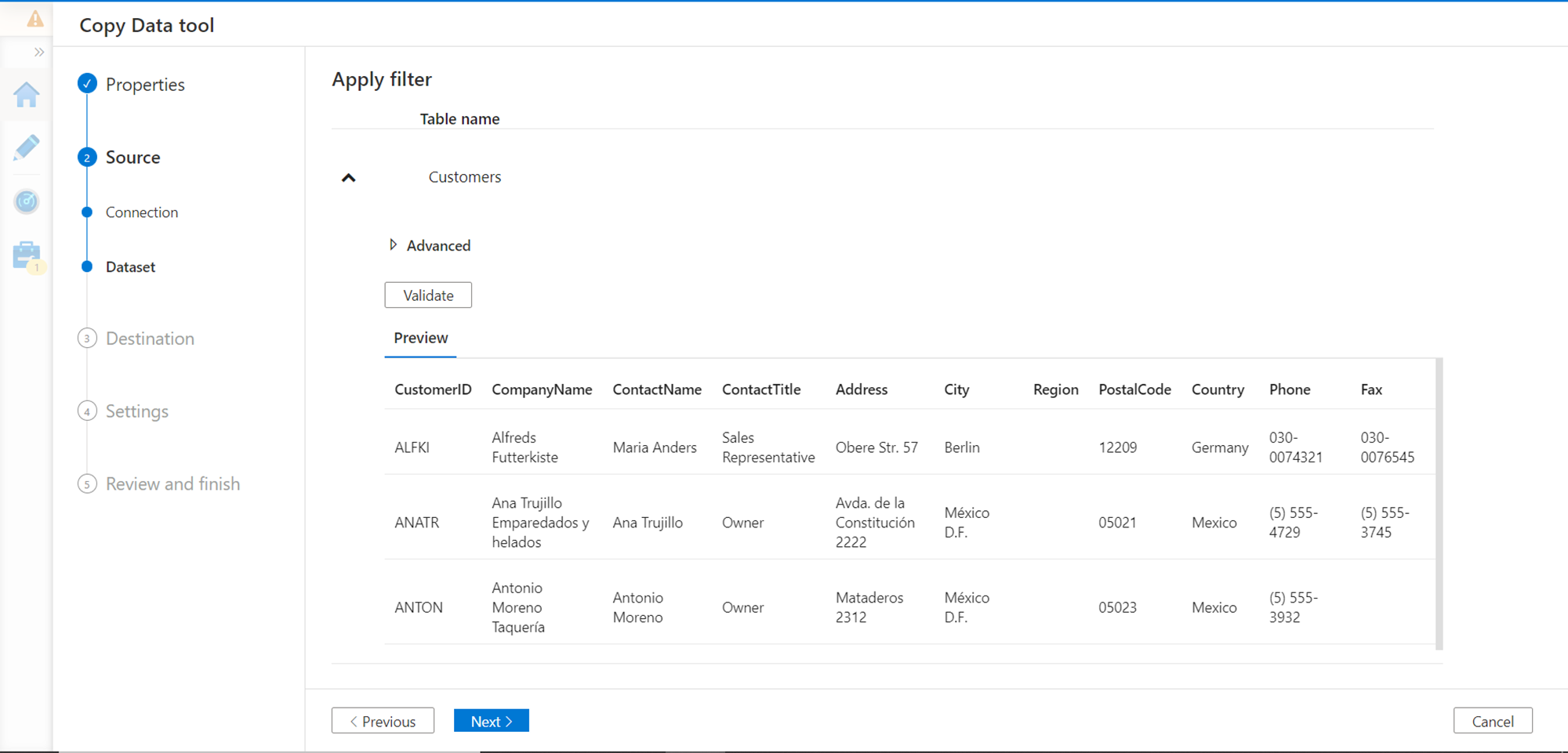
In this step, one can validate whether the data types and other details of the table are compatible for Azure Data Factory to import this type of data. Click on the Validate button to validate the table for import. Once the validation is successful, proceed to the Next step.
Now we need to select the destination linked service. Follow the same step mentioned above for OData API, and instead, this time select the Azure Storage Account which we would be using as the destination. Once the linked service is registered, it would look as shown below. Select the same and proceed to the next step to configure the location where we would import the data. One can also select any other data repository as the destination.
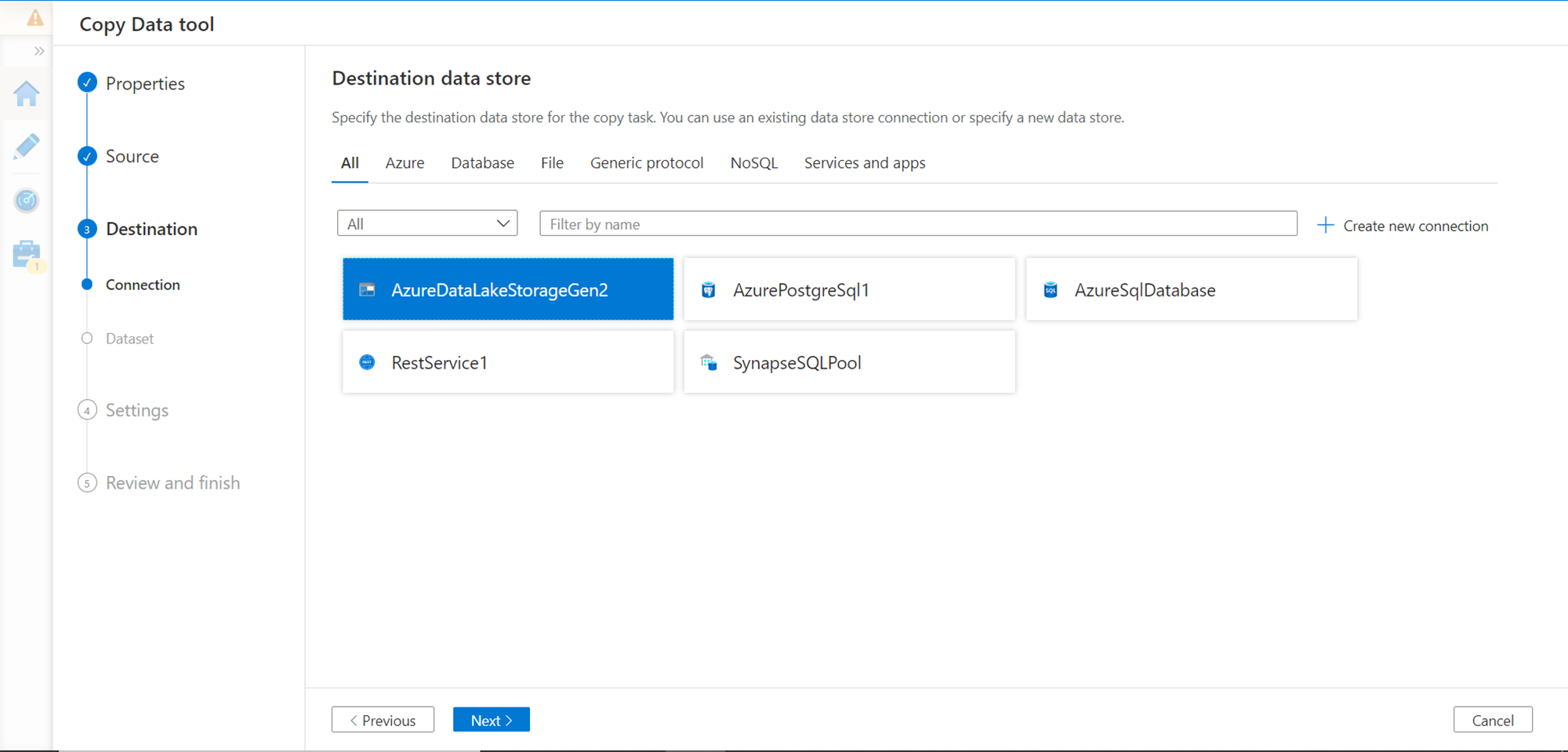
In this step, we need to configure an existing folder in the Azure Data Lake Storage account where we would be storing the imported data. Provide a relevant location and a file name and proceed to the next step.
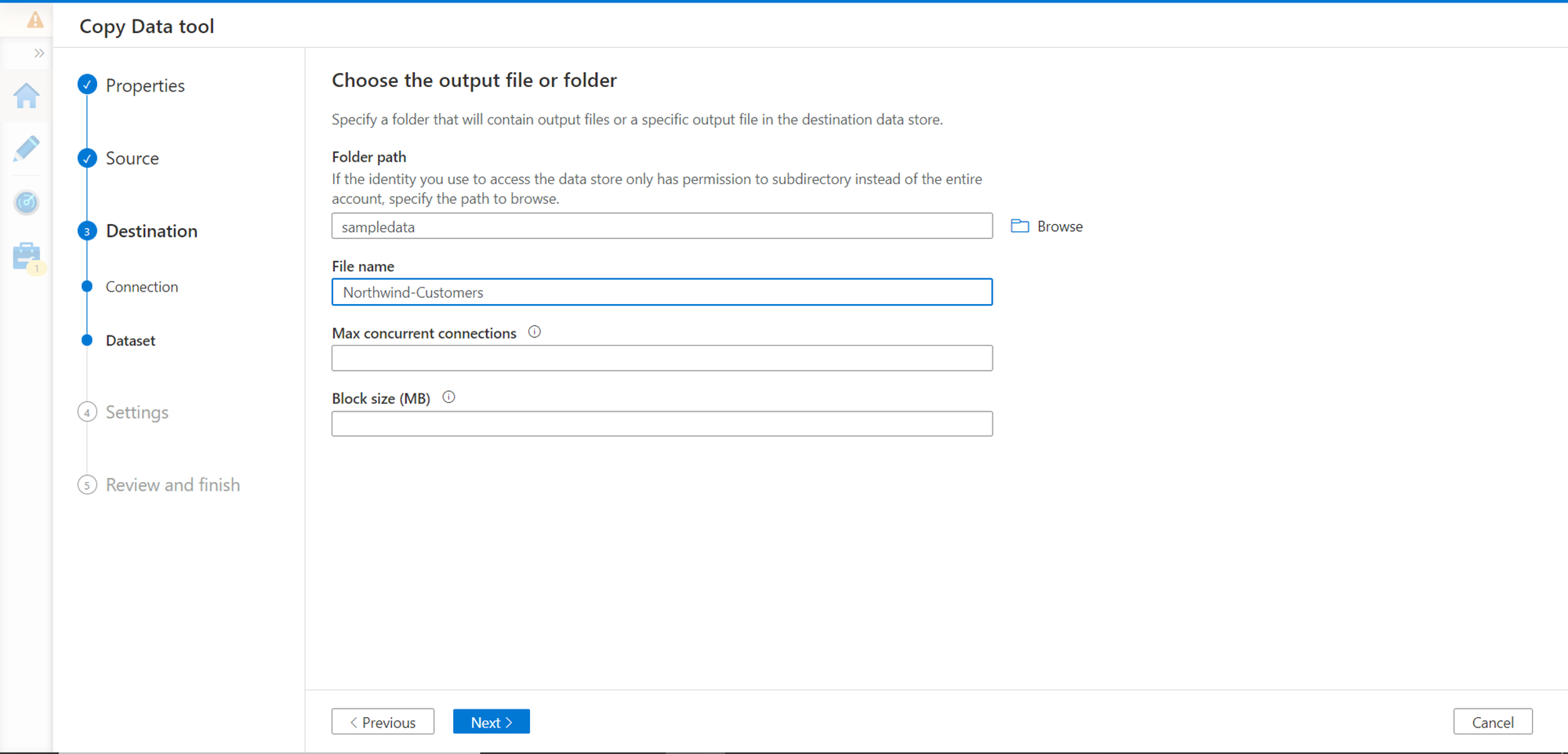
In this step, we need to configure the file format and other file-related settings. Let’s say that we intend to store this data in the form of a CSV file. So, select the settings as shown below. One other important setting is to add column headers in the file. As we are importing data from an external API into a file, it’s important to add headers else it would be confusing to identify the columns. So, ensure to check this option as shown below.
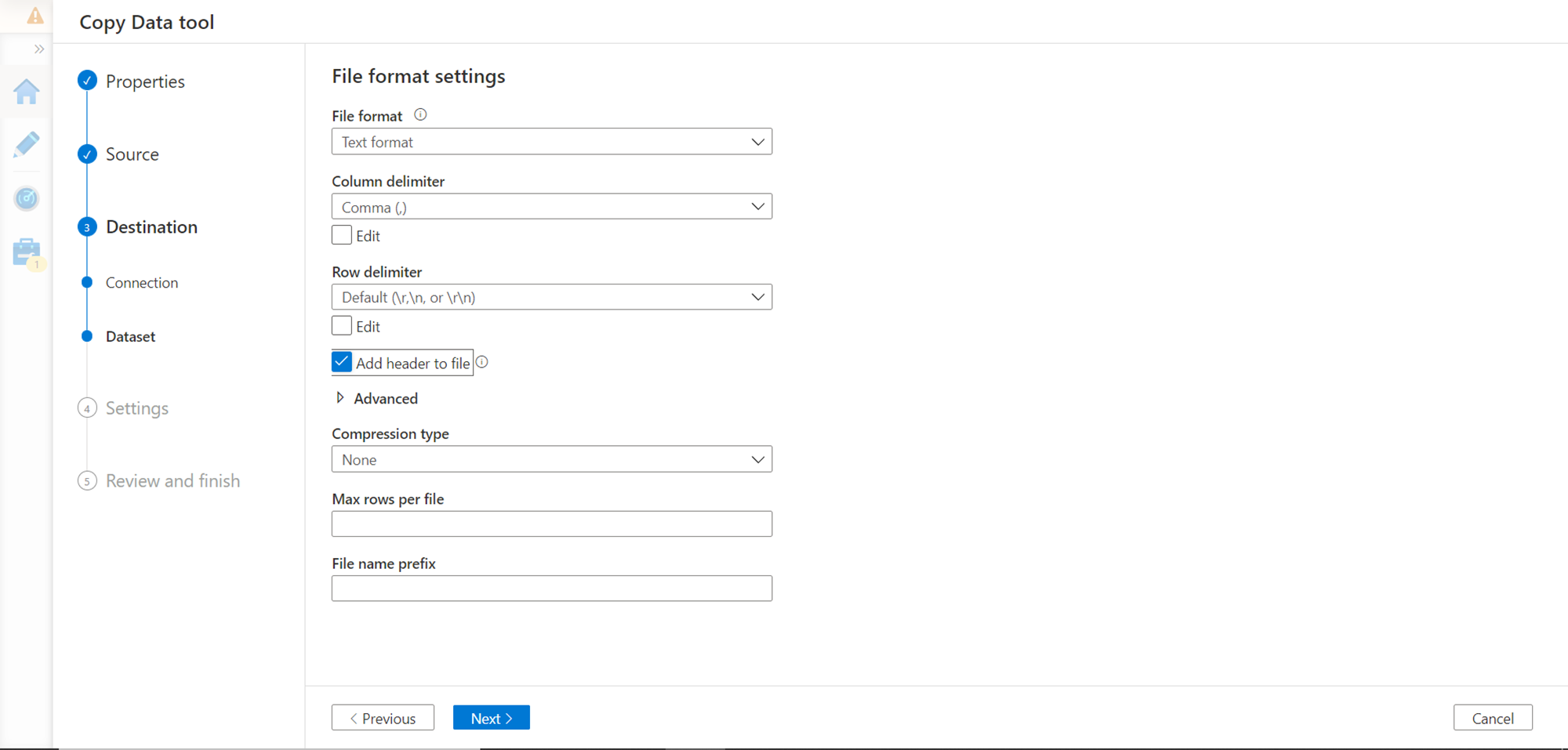
In this step, we can optionally configure the data consistency and performance-related setting. For now, in this exercise, we can continue with the default settings. While moving this to production, these settings are very important to configure.
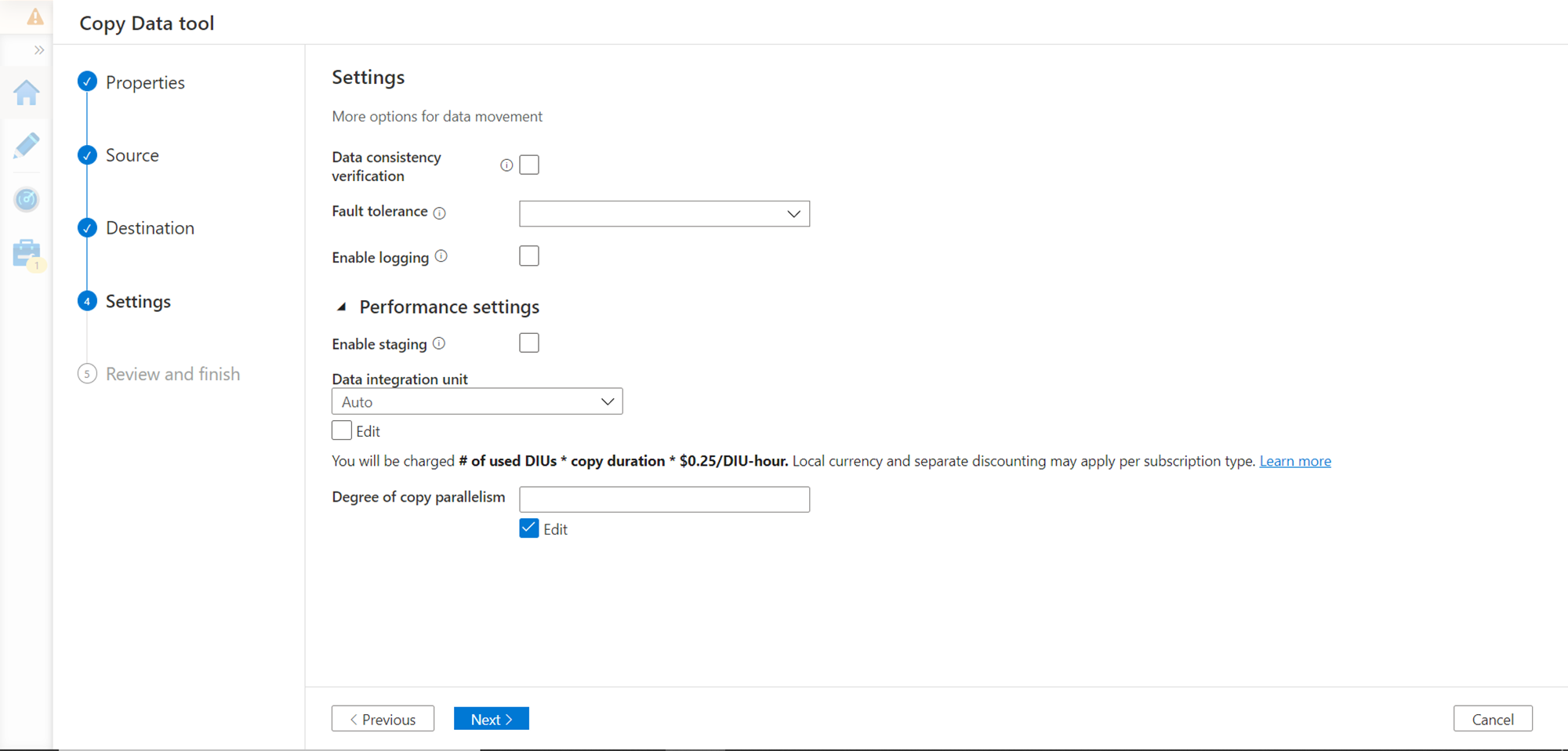
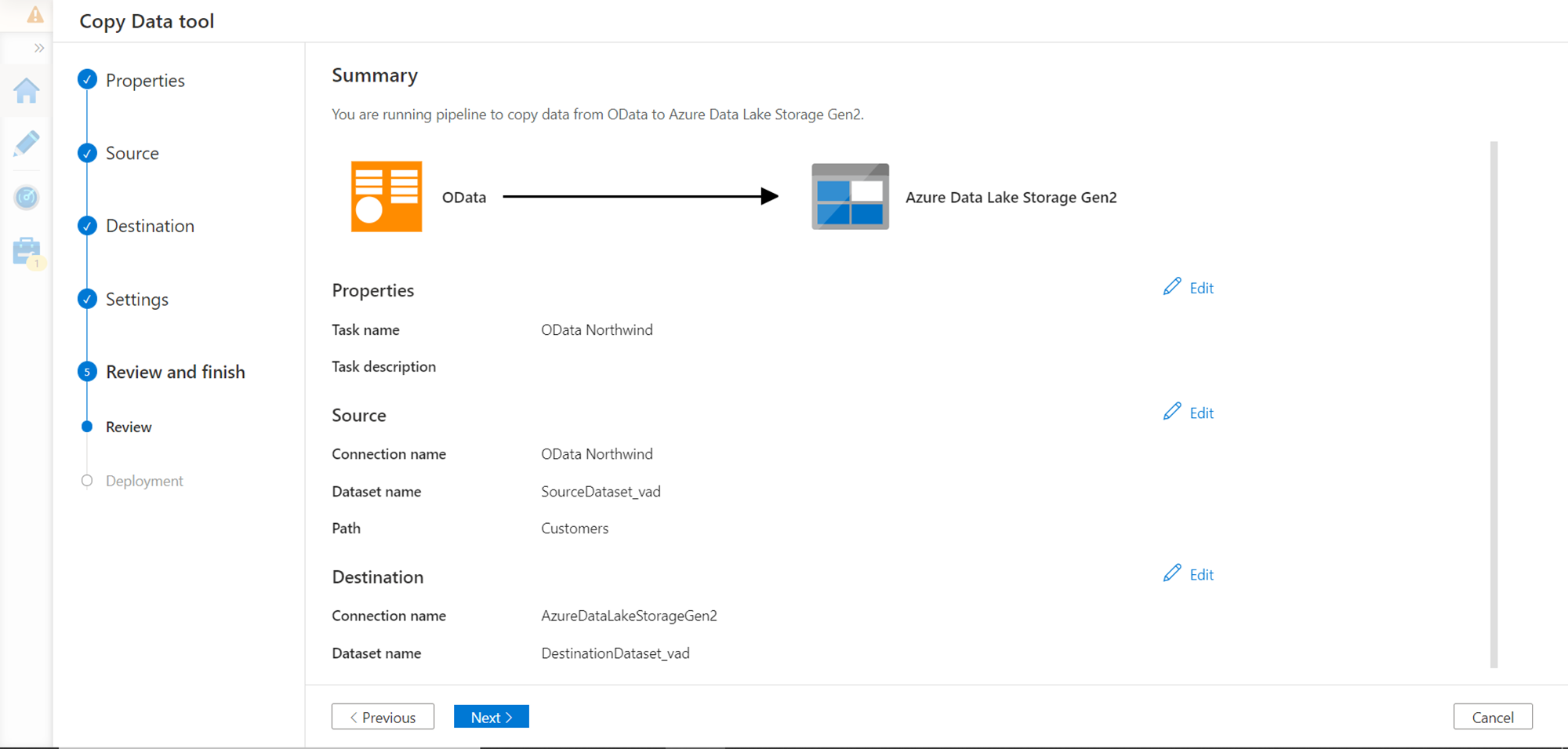
Validate the configured settings before execution as shown below. Once verified, proceed to the next step where it would start the execution.
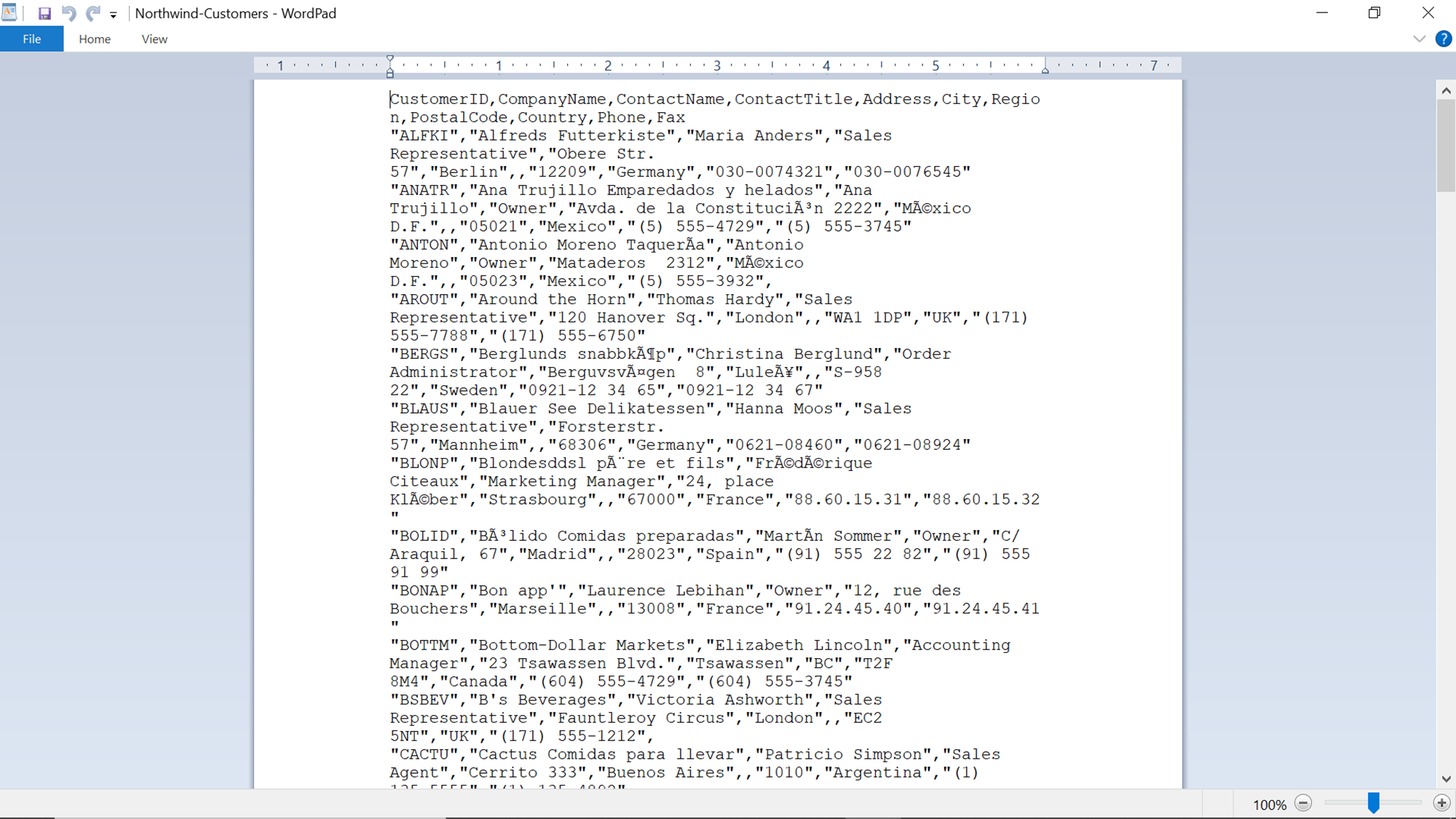
Once the execution is complete, navigate to the location where we configured the file to be created and open the file. We should be able to find that the data was imported successfully in a CSV format with column headers in it.
In this way, we can import data from OData APIs using Azure Data Factory.
Conclusion
In this article, we understood what OData is and how it plays a role in the data consumption and data publishing process. We learned how to use Azure Data Factory with OData to import the data in Azure support data repositories.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023