
Ever been as frustrated as I have when importing flat files to a SQL Server and the format suddenly changes in production?
Commonly used integration tools (like SSIS) are very dependent on the correct, consistent and same metadata when working with flat files.
So I’ve come up with an alternative solution that I would like to share with you.
When implemented, the process of importing flat files with changing metadata is handled in a structured, and most important, resiliant way. Even if the columns change order or existing columns are missing.
Background
When importing flat files to SQL server almost every standard integration tool (including TSQL bulkload) requires fixed metadata from the files in order to work with them.
This is quite understandable, as the process of data transportation from the source to the destination needs to know where to map every column from the source to the defined destination.
Let me make an example:
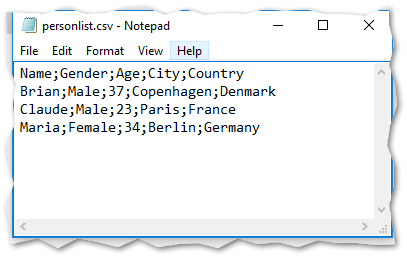
A source flat file table like below needs to be imported to a SQL server database.
This file could be imported to a SQL Server database (in this example named FlatFileImport) with below script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
create table dbo.personlist ( [name] varchar(20), [gender] varchar(10), [age] int, [city] varchar(20), [country] varchar(20) ); BULK INSERT dbo.personlist FROM 'c:\source\personlist.csv' WITH ( FIRSTROW = 2, FIELDTERMINATOR = ';', --CSV field delimiter ROWTERMINATOR = '\n', --Use to shift the control to next row TABLOCK, CODEPAGE = 'ACP' ); select * from dbo.personlist; |
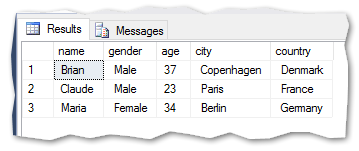
The result:
If the column ‘Country’ would be removed from the file after the import has been setup, the process of importing the file would either break or be wrong (depending on the tool used to import the file) The metadata of the file has changed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- import data from file with missing column (Country) truncate table dbo.personlist; BULK INSERT dbo.personlist FROM 'c:\source\personlistmissingcolumn.csv' WITH ( FIRSTROW = 2, FIELDTERMINATOR = ';', --CSV field delimiter ROWTERMINATOR = '\n', --Use to shift the control to next row TABLOCK, CODEPAGE = 'ACP' ); select * from dbo.personlist; |
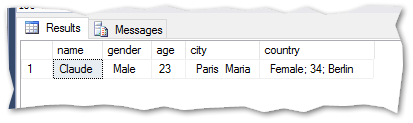
With this example, the import seems to go well, but upon browsing the data, you’ll see that only one row is imported and the data is wrong.
The same would happen if the columns ‘Gender’ and ‘Age’ where to switch places. Maybe the import would not break, but the mapping of the columns to the destination would be wrong, as the ‘Age’ column would go to the ‘Gender’ column in the destination and vice versa. This due to the order and datatype of the columns. If the columns had the same datatype and data could fit in the columns, the import would go fine – but the data would still be wrong.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- import data from file with switched columns (Age and Gender) truncate table dbo.personlist; BULK INSERT dbo.personlist FROM 'c:\source\personlistswitchedcolumns.csv' WITH ( FIRSTROW = 2, FIELDTERMINATOR = ';', --CSV field delimiter ROWTERMINATOR = '\n', --Use to shift the control to next row TABLOCK, CODEPAGE = 'ACP' ); |

When importing the same file, but this time with an extra column (Married) – the result would also be wrong:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- import data from file with new extra column (Married) truncate table dbo.personlist; BULK INSERT dbo.personlist FROM 'c:\source\personlistextracolumn.csv' WITH ( FIRSTROW = 2, FIELDTERMINATOR = ';', --CSV field delimiter ROWTERMINATOR = '\n', --Use to shift the control to next row TABLOCK, CODEPAGE = 'ACP' ); select * from dbo.personlist; |
The result:
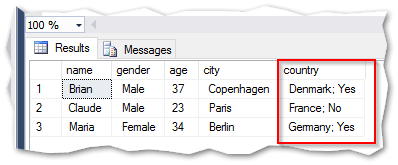
The above examples are made with pure TSQL code. If it was to be made with an integration tool like SQL Server Integration Services, the errors would be different and the SSIS package would throw more errors and not be able to execute the data transfer.
The cure
When using the above BULK INSERT functionality from TSQL the import process often goes well, but the data is wrong with the source file is changed.
There is another way to import flat files. This is using the OPENROWSET functionality from TSQL.
In section E of the example scripts from MSDN, it is described how to use a format file. A format file is a simple XML file that contains information of the source files structure – including columns, datatypes, row terminator and collation.
Generation of the initial format file for a curtain source is rather easy when setting up the import.
But what if the generation of the format file could be done automatically and the import process would be more streamlined and manageable – even if the structure of the source file changes?
From my GitHub project you can download a home brewed .NET console application that solves just that.
If you are unsure of the .EXE files content and origin, you can download the code and build your own version of the GenerateFormatFile.exe application.
Another note is that I’m not hard core .Net developer, so someone might have another way of doing this. You are very welcome to contribute to the GitHub project in that case.
The application demands inputs as below:
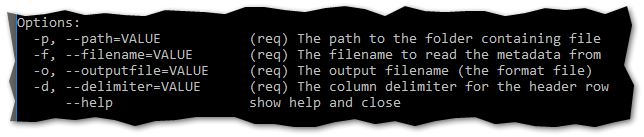
Example usage:
generateformatfile.exe -p c:\source\ -f personlist.csv -o personlistformatfile.xml -d ;
The above script generates a format file in the directory c:\source\ and names it personlistFormatFile.xml.
The content of the format file is as follows:

The console application can also be called from TSQL like this:
|
1 2 3 4 5 6 |
-- generate format file declare @cmdshell varchar(8000); set @cmdshell = 'c:\source\generateformatfile.exe -p c:\source\ -f personlist.csv -o personlistformatfile.xml -d ;' exec xp_cmdshell @cmdshell; |
If by any chance the xp_cmdshell feature is not enabled on your local machine – then please refer to this post from Microsoft: Enable xp_cmdshell
Using the format file
After generation of the format file, it can be used in TSQL script with OPENROWSET.
Example script for importing the ‘personlist.csv’
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- import file using format file select * into dbo.personlist_bulk from openrowset( bulk 'c:\source\personlist.csv', formatfile='c:\source\personlistformatfile.xml', firstrow=2 ) as t; select * from dbo.personlist_bulk; |
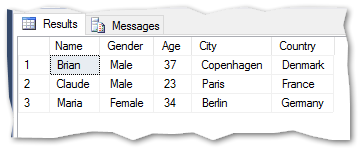
This loads the data from the source file to a new table called ‘personlist_bulk’.
From here the load from ‘personlist_bulk’ to ‘personlist’ is straight forward:
|
1 2 3 4 5 6 7 8 9 10 11 |
-- load data from personlist_bulk to personlist truncate table dbo.personlist; insert into dbo.personlist (name, gender, age, city, country) select * from dbo.personlist_bulk; select * from dbo.personlist; drop table dbo.personlist_bulk; |
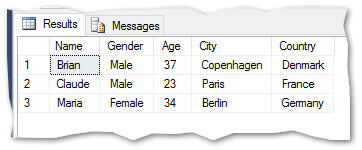
Load data even if source changes
The above approach works if the source is the same every time it loads. But with a dynamic approach to the load from the bulk table to the destination table it can be assured that it works even if the source table is changed in both width (number of columns) and column order.
For some the script might seem cryptic – but it is only a matter of generating a list of column names from the source table that corresponds with the column names in the destination table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
-- import file with different structure -- generate format file if exists(select OBJECT_ID('personlist_bulk')) drop table dbo.personlist_bulk declare @cmdshell varchar(8000); set @cmdshell = 'c:\source\generateformatfile.exe -p c:\source\ -f personlistmissingcolumn.csv -o personlistmissingcolumnformatfile.xml -d ;' exec xp_cmdshell @cmdshell; -- import file using format file select * into dbo.personlist_bulk from openrowset( bulk 'c:\source\personlistmissingcolumn.csv', formatfile='c:\source\personlistmissingcolumnformatfile.xml', firstrow=2 ) as t; -- dynamic load data from bulk to destination declare @fieldlist varchar(8000); declare @sql nvarchar(4000); select @fieldlist = stuff((select ',' + QUOTENAME(r.column_name) from ( select column_name from INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'personlist' ) r join ( select column_name from INFORMATION_SCHEMA.COLUMNS where TABLE_NAME = 'personlist_bulk' ) b on b.COLUMN_NAME = r.COLUMN_NAME for xml path('')),1,1,''); print (@fieldlist); set @sql = 'truncate table dbo.personlist;' + CHAR(10); set @sql = @sql + 'insert into dbo.personlist (' + @fieldlist + ')' + CHAR(10); set @sql = @sql + 'select ' + @fieldlist + ' from dbo.personlist_bulk;'; print (@sql) exec sp_executesql @sql |
The result is a TSQL statement what looks like this:
|
1 2 3 4 5 |
truncate table dbo.personlist; insert into dbo.personlist ([age],[city],[gender],[name]) select [age],[city],[gender],[name] from dbo.personlist_bulk; |
The exact same thing would be able to be used with the other source files in this demo. The result is that the destination table is correct and loaded with the right data every time – and only with the data that corresponds with the source. No errors will be thrown.
From here there are some remarks to be taken into account:
- As no errors are thrown, the source files could be empty and the data updated could be blank in the destination table. This is to be handled by processed outside this demo.
Further work
As this demo and post shows it is possible to handle dynamic changing flat source files. Changing columns, column order and other changes, can be handled in an easy way with a few lines of code.
Going from here, a suggestion could be to set up processes that compared the two tables (bulk and destination) and throws an error if X amount of the columns are not present in the bulk table or X amount of columns are new.
It is also possible to auto generate missing columns in the destination table based on columns from the bulk table.
The only boundaries are set by limits to your imagination
Summary
With this blogpost I hope to have given you inspiration to build your own import structure of flat files in those cases where the structure might change.
As seen above the approach needs some .NET programming skills – but when it is done and the console application has been built, it is simply a matter of reusing the same application around the different integration solutions in your environment.
Happy coding 🙂
See more
Consider these free tools for SQL Server that improve database developer productivity.
External links:


His work spans from the small tasks to the biggest projects. Engaging all the roles from manual developer to architect in his 11 years experience with the Microsoft Business Intelligence stack. With his two certifications MSCE Business Intelligence and MCSE Data Platform, he can play with many cards in the advisory and development of Business Intelligence solutions. The BIML technology has become a bigger part of Brians approach to deliver fast-track BI projects with a higher focus on the business needs.
View all posts by Brian Bønk Rueløkke
- How to import flat files with a varying number of columns in SQL Server - February 22, 2017
- Ready, SET, go – How does SQL Server handle recursive CTE’s - August 19, 2016
- Use of hierarchyid in SQL Server - July 29, 2016