
Introduction
From time to time, we may encounter the following scenarios when dealing with data processing:
- We have two CSV files that I want to merge them based on one common column value
- We want to split a file vertically, for example, an employee csv file, the Salary and DOB fields need to be removed into another file, dedicated only for authorized persons.
- We want to split a CSV file horizontally, for example, in a sales CSV file, we want to split the file based on Store name, etc.
All this work can be done at database side. The common approach is to load the whole CSV file(s) into one or two staging tables and then do
- After loading two CSV files into two staging tables, use INNER/LEFT/RRIGHT JOIN on the common column to get two tables together. If only common records are needed, we use INNER JOIN, otherwise, use LEFT or RIGHT JOIN.
- After loading the CSV file into one staging table, select the needed column list as per requirement to split the table vertically.
- After loading the CSV file into one staging table, select the table with a where clause to split the table horizontally.
However, with SQL Server 2016 R integration, we can easily handle this type of work in T-SQL directly without relying on the intermediate staging table(s). This will reduces workload in creating and manipulating staging tables.
Preparing Test Data
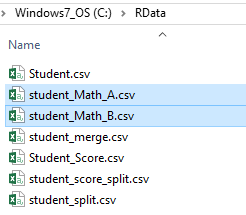
We will prepare two short CSV files as shown below, the first is [Student.csv] file, which has 10 students.

The 2nd file is [Student_Score.csv] file, which has 8 records (missing student id 7 and 10 on purpose)
The two files are located in my local C:\Rdata\ folder
Merge Implementation
Now our requirement is to merge the two files based on [StudnetID] column, and using [Student.csv] as the primary file, meaning if a student does not have a corresponding record at [Student_Score.csv] side, we still needs this student record to appear in the merged file. We will save the new file as [Student_Merge.csv].
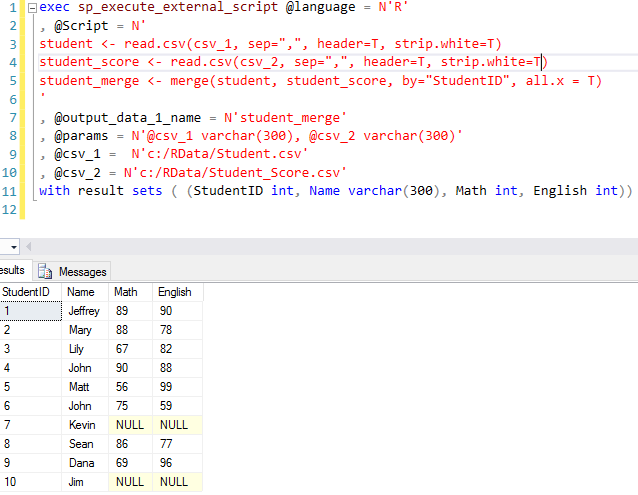
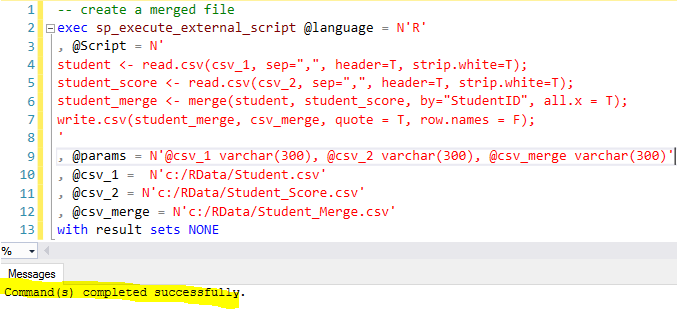
Here is the code to do the work (the source code can be found at the [Summary] section)
Quick Explanation:
- Two csv files are read into each of its corresponding variables via line 3 and 4, the file names are provided by input parameters (line 8, 9, 10) @csv_1 and @csv_2. Notice that the file path is using forward-slash (/) instead of the backward slash (\), this is because backward slash is used as escape character, so if you really want to use backward slash, you need to use double slash i.e. \\.
- The two variables [student] and [student_score] are merged via [merge] function by [StudentID] common field, and all [student] records will be kept there via all.X = T, here T is the short abbreviation of TRUE. (line 5)
- The merged result is put into variable [student_merge] (line 5) and all the records in this variable will be returned (line 7)
- After running the script, we can see StudentID 7 and 10 do have NULL values in [Math] and [English], this is because the original [Student_Score.csv] does not contain these two students.
-
One thing worth mentioning is that the StudentID field in each CSV file does NOT need to be sorted. For example, if [Student.csv] has the following records

After running the T-SQL script, we will still get the same result.
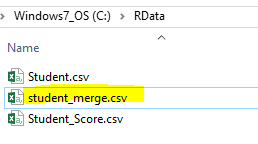
Now we see how to merge the two csv files, next step is we can either import the merged result to a database table using INSERT … SELECT … or we can create a new CSV file as shown below.
And we can see a new file created under C:\RData\

Quick Explanation:
- The code is exactly the same as previous one but we add a write.csv function on line 7
- This write.csv function get its file name from a variable [csv_merge], which is populated by an input parameter on line 12.
Vertical Split Implementation
Now assume, I want to split this [student_merge.csv] to [Student_split.csv] and [Student_Score_Split.csv] files with the same field names as in corresponding [Student.csv] and [Student_Score.csv].
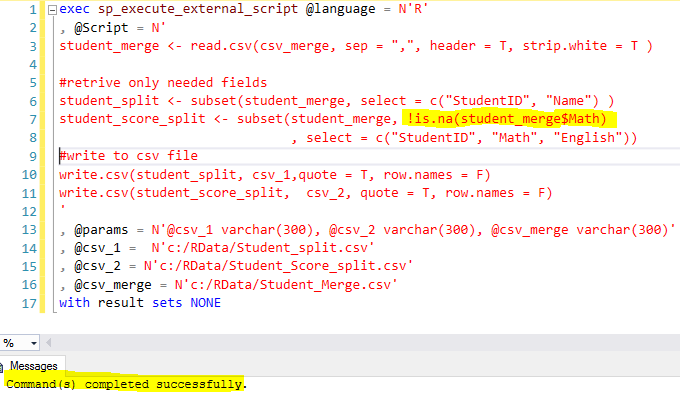
Here is the code to do the work:
Quick Explanation:
- Read the [Student_Merge.csv] into variable [student_merge] (line 3)
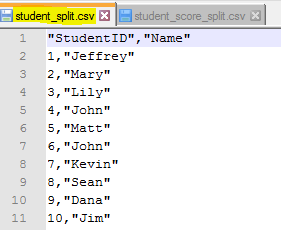
- Then through subset() function, we retrieve the columns we need, column list is defined in [select] parameter, such as select = c(“StudentID”, “Name”) (line 6,7,8)
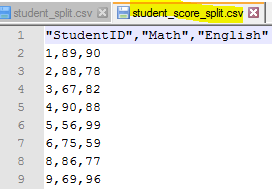
- For [student_score_split] variable, we do not want to contain students (like student id 7 and 10) who do not have scores, as such, we use a filter !is.na(student_merge$Math), meaning the records in variable [student_merge] whose [Math] column is not NULL (i.e. NA) (line 7)
- Write the two variables [student_split] and [student_score_split] to two csv files.
- All the csv file names are provided through store procedure’s input parameters (line 13, 14,15,16)
After executing the script, we will have two newly created files under folder C:\RData\ as shown below
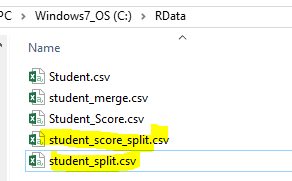
We can open the two files in an editor and see the following result
Horizontal Split Implementation
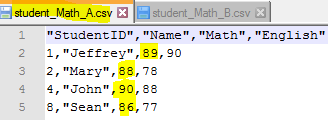
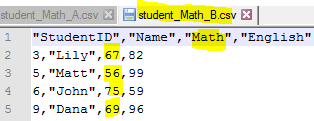
Just assume we need to split [student_merge.csv] into two csv files, those with Math score >= 80 and those Math score < 80.
Here is the code
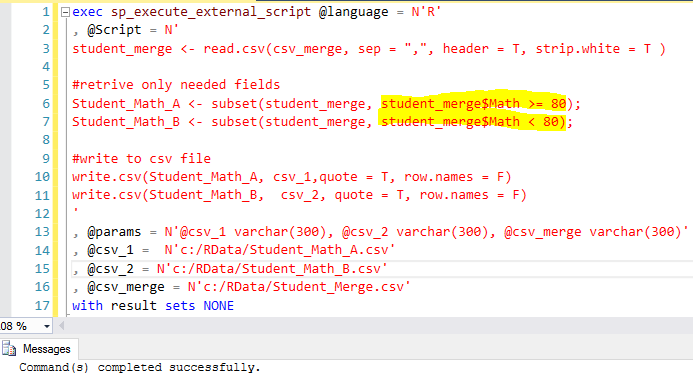
Quick Explanation:
- Read the [Student_Merge.csv] into variable [student_merge] (line 3)
- Use subset() function to filter out the records as per business requirement, i.e. student_merge$Math >= 80 and student_merge$Math < 80 and assign to each variable Student_Math_A and Student_Math_B. (line 6, 7)
- Export the two variables [Student_Math_A] and [Student_Math_B] to two csv files.
- All the csv file names are provided through store procedure’s input parameters (line 13, 14,15,16)
Now there are two new files created in C:\RData\
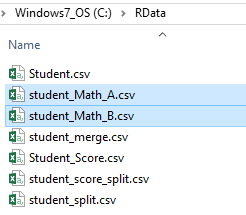
When we open the two files in an editor, we will see this
Summary
In this article, we see how we can manipulate a CSV file with R inside T-SQL. This can be very convenient in various file pre-processing scenarios, and no doubt greatly extend the functions of T-SQL.
The following is the complete script I used in this article.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
-- Merged two csv files exec sp_execute_external_script @language = N'R' , @Script = N' student <- read.csv(csv_1, sep=",", header=T, strip.white=T); student_score <- read.csv(csv_2, sep=",", header=T, strip.white=T); student_merge <- merge(student, student_score, by="StudentID", all.x = T); write.csv(student_merge, csv_merge, quote = T, row.names = F); ' , @params = N'@csv_1 varchar(300), @csv_2 varchar(300), @csv_merge varchar(300)' , @csv_1 = N'c:/RData/Student.csv' , @csv_2 = N'c:/RData/Student_Score.csv' , @csv_merge = N'c:/RData/Student_Merge.csv' with result sets NONE go -- Vertical split exec sp_execute_external_script @language = N'R' , @Script = N' student_merge <- read.csv(csv_merge, sep = ",", header = T, strip.white = T ) #retrive only needed fields student_split <- subset(student_merge, select = c("StudentID", "Name") ) student_score_split <- subset(student_merge, !is.na(student_merge$Math) , select = c("StudentID", "Math", "English")) #write to csv file write.csv(student_split, csv_1,quote = T, row.names = F) write.csv(student_score_split, csv_2, quote = T, row.names = F) ' , @params = N'@csv_1 varchar(300), @csv_2 varchar(300), @csv_merge varchar(300)' , @csv_1 = N'c:/RData/Student_split.csv' , @csv_2 = N'c:/RData/Student_Score_split.csv' , @csv_merge = N'c:/RData/Student_Merge.csv' with result sets NONE; go -- Horizontal Split exec sp_execute_external_script @language = N'R' , @Script = N' student_merge <- read.csv(csv_merge, sep = ",", header = T, strip.white = T ) #retrive only needed fields Student_Math_A <- subset(student_merge, student_merge$Math >= 80); Student_Math_B <- subset(student_merge, student_merge$Math < 80); #write to csv file write.csv(Student_Math_A, csv_1,quote = T, row.names = F) write.csv(Student_Math_B, csv_2, quote = T, row.names = F) ' , @params = N'@csv_1 varchar(300), @csv_2 varchar(300), @csv_merge varchar(300)' , @csv_1 = N'c:/RData/Student_Math_A.csv' , @csv_2 = N'c:/RData/Student_Math_B.csv' , @csv_merge = N'c:/RData/Student_Merge.csv' with result sets NONE; go |
When embedding R script inside the T-SQL, I find the safest way is to use the R core packages and their libraries, such as library(utils) and library(base). If you use some other 3rd party packages, there can be some unknown errors when embedding the R script into the T-SQL, though the R script runs OK outside of T-SQL.
There are many other file processing scenarios I have not discussed but worth some serious trials, such as file merge based on multiple columns, file splitting on complex conditions, adding a calculated column based on other columns, removing some specified records as per business requirements, updating some records or appending some records etc.
In short, with R, we can process CSV files directly which usually cannot be done with T-SQL, thus results in concise and easy-to-maintain codes.
References
The following list contains four R functions used in this article.

- using data warehousing technology to manage big number of SQL Server instances for capacity planning, performance forecasting, and evidence mining
- doing data visualization and analysis with R
- doing T-SQL puzzles
He enjoys writing and sharing his knowledge
View all posts by Jeffrey Yao
- How to Merge and Split CSV Files Using R in SQL Server 2016 - February 21, 2017
- How to Import / Export CSV Files with R in SQL Server 2016 - February 9, 2017