
SQL Server 2016 came with many new features and enhancements for existing ones, that concentrate on the aspect of SQL Server security. One of the new security features introduced in SQL Server 2016 is Row-Level Security. This feature allows us to control access deeply into the rows level in the database table, based on the user executing the query. This is done within the database layer, in complete transparency to the application process, without the need to manage it with complex coding at the application layer.
Row-Level Security (RLS) provides us with a way to restrict users to allow them to work only with the data they have access to. For example, each courier in a shipping company can access only the data related to the shipments he is requested to deliver, without being able to access other courier’s data. Each time data access is performed from any tier, data access will be restricted by the SQL Server Engine, reducing the security system surface area.
There are two types of security predicates that are supported in Row-Level Security; the Filter predicate that filters row silently for read operations. The Silent filter predicate means that the application will not be made aware that the data is filtered, null values will be returned if all rows are filtered, without raising an error message. The Block predicate prevents any write operation that violates any defined predicate with an error message returned as a result of the block. This policy can be turned ON and OFF with four main blocking types; AFTER INSERT and AFTER UPDATE blocking will prevent the users from updating the rows to values that will violate the predicate. BEFORE UPDATE will prevent the users from updating the rows that are violating the predicate currently. BEFORE DELETE will prevent the users from deleting the rows. Trying to add a predicate on a table that already has a predicate defined will result with error.
Data access restriction using Row-Level Security is accomplished by defining a Security predicate as an inline-table-valued function that will restrict the rows based on filtering logic, which is invoked and enforced by a Security Policy created using the CREATE SECURITY POLICY T-SQL statement and working as predicates container. SQL Server allows you to define multiple active security policies but without overlapping predicates. Altering a table with a schema bound security policy defined on it will fail with error.
As in any new feature, SQL Server Row-Level Security has a number of limitations, such as the fact that Filestream and Polybase features are not compatible with the feature. Although you are able to create a view over a table with Row-Level Security configured on it, you are not able to create an indexed view on that view. It is not recommended to configure Change Data Capture, Change tracking and/or Temporal Tables on a table with Row-Level Security due to fact that critical data may be available in the tables containing the data changes or the history tables and will be accessible by all users that deal with these tables to get the latest changes. The blocked predicate is not compatible with partitioned views, but it can be used with the filter predicate. Another thing is that RLS is implemented using a function, which may lead to that situation when the optimized, any queries that use the Columnstore indexes may be re-written, resulting in the batch mode not being used.
Let’s start our demo to understand how the Row-Level Security feature works in a practical sense. We will start by creating a demo table that will hosts the couriers’ shipments information, on which we will configure Row-Level Security:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
USE [SQLShackDemo] GO CREATE TABLE [dbo].[Courier_Shipments]( [ID] [int] IDENTITY(1,1) NOT NULL, [Courier_Name] [varchar](10) NULL, [NumOfShipmentsInPackage] [int] NULL, [Package_Date] [datetime] NULL, [Package_Cost] [int] NULL, [Package_City] [varchar](10) NULL, CONSTRAINT [PK_Courier_Shipments] PRIMARY KEY CLUSTERED ( [ID] ASC )) ON [PRIMARY] GO |
Once the table is created successfully, let’s insert few rows on that table, for example, we will insert two records for each courier as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [SQLShackDemo] GO INSERT INTO [dbo].[Courier_Shipments] ([Courier_Name] ,[NumOfShipmentsInPackage] ,[Package_Date] ,[Package_Cost] ,[Package_City]) VALUES ('John',5,'2016-09-22 01:35:00:000',580,'LON'), ('Ghezil',3,'2016-09-22 03:45:00:000',470,'LAX'), ('Mark',2,'2016-09-22 04:32:00:000',118,'JFK'), ('Ghezil',5,'2016-09-22 02:38:00:000',358,'LAX'), ('Mark',4,'2016-09-22 06:12:00:000',774,'JFK'), ('John',7,'2016-09-22 08:07:00:000',941,'LON') GO |
Also we will create a three users, one for each courier who will retrieve his shipments data:
|
1 2 3 4 5 |
CREATE USER John WITHOUT LOGIN; CREATE USER Ghezil WITHOUT LOGIN; CREATE USER Mark WITHOUT LOGIN; |
And grant SELECT access on the Courier_Shipments table for the newly created three users:
|
1 2 3 4 5 |
GRANT SELECT ON [Courier_Shipments] TO John; GRANT SELECT ON [Courier_Shipments] TO Ghezil; GRANT SELECT ON [Courier_Shipments] TO Mark; |
It is highly recommended to create a separate schema for the Row-Level Security database objects:
|
1 2 3 4 |
CREATE SCHEMA RLS; GO |
Till this step, the table and the new schema is ready to start configuring the Row-Level Security feature. First we will create the Filter Predicate function that depends on the logged in user name to filter the users and check their access on the data as follows:
|
1 2 3 4 5 6 7 8 |
CREATE FUNCTION RLS.fn_SecureCourierData(@CourierName AS sysname) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AS 'SecureCourierShipments' WHERE @CourierName = USER_NAME(); |
And create the Security Policy on the Courier_Shipments table using the previously created predicate function, then turn it on:
|
1 2 3 4 5 6 |
CREATE SECURITY POLICY CourierShipments ADD FILTER PREDICATE RLS.fn_SecureCourierData(Courier_Name) ON dbo.Courier_Shipments WITH (STATE = ON); |
Now, Row-Level Security is fully configured and ready to start filtering any new data access on the Courier_Shipments table. Expanding the Security node of the SQLShackDemo database, the newly created Security Policy can be found as in the following image using the SQL Server Management Studio:
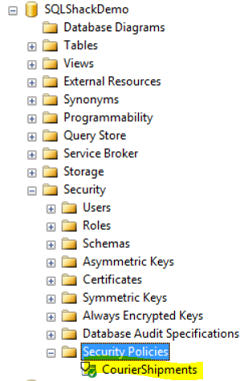
If we try to run the below query using John user:
|
1 2 3 4 5 |
EXECUTE AS USER = 'John'; SELECT * FROM Courier_Shipments; REVERT; |
The following result will show us that the query executed by John will return only the two records related to John’s shipments:

The same thing will occur with Ghezil, if he tries to run the below SELECT statement with his user:
|
1 2 3 4 5 |
EXECUTE AS USER = 'Ghezil'; SELECT * FROM Courier_Shipments; REVERT; |
The two records related to him will be retrieved only:

The third courier also, Mark, who will retrieve only the rows related to his shipments when he run the below query:
|
1 2 3 4 5 |
EXECUTE AS USER = 'Mark'; SELECT * FROM Courier_Shipments; REVERT; |
The results the Mark will see:

It is clear from the previous results that the Row-Level Security feature can be used to filter the data that each user can see depending on the filtering criteria defined in the predicate function.
If you manage to stop using the Row-Level Security feature that we configured, you need to disable the Security Policy using the ALTER SECURITY POLICY statement below:
|
1 2 3 |
Alter Security Policy CourierShipments with (State = off) |
Then drop that Security Policy and the Filter Predicate function as follows:
|
1 2 3 4 |
Drop Security Policy CourierShipments Drop Function RLS.fn_SecureCourierData |
Now the Row-Level Security is removed completely from the Courier_Shipments table.
As we mentioned previously, there is another type of predicates that can be used in the Row-level Security feature which is the Block Predicate. Let’s have a second demo to know how the block predicate can be configured and work.
Again, we will create a predicate function that will filter the data access depends on the users connecting to that table as follows:
|
1 2 3 4 5 6 7 8 9 |
CREATE FUNCTION RLS.fn_SecureCourierData (@Courier_Name sysname) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AS fn_SecureCourierData_result WHERE @Courier_Name= user_name() GO |
Also we will create the security policy, but this time it will contain an AFTER INSERT block predicate condition in addition to the filter predicate:
|
1 2 3 4 5 6 |
CREATE SECURITY POLICY dbo.fn_Courier_Shipments ADD FILTER PREDICATE RLS.fn_SecureCourierData(Courier_Name) ON dbo.Courier_Shipments, ADD BLOCK PREDICATE RLS.fn_SecureCourierData(Courier_Name) ON dbo.Courier_Shipments AFTER INSERT GO |
And enable the Security policy as follows:
|
1 2 3 |
Alter Security Policy fn_Courier_Shipments with (State = ON) |
As the blocking will be on the INSERT operation, we will grant Mark user access to do so:
|
1 2 3 |
GRANT SELECT, INSERT, UPDATE, DELETE ON Courier_Shipments TO Mark; |
If Mark tries to apply the below SELECT statement with his user:
|
1 2 3 4 5 |
EXECUTE AS USER = 'Mark'; SELECT * FROM Courier_Shipments; REVERT; |
We will see the same previous result, where he will be able to see the records related to his shipments only:

But if he tries to insert a new record with his user, but with the courier name different from his name, let’s say John:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
EXECUTE AS USER = 'Mark'; INSERT INTO [dbo].[Courier_Shipments] ([Courier_Name] ,[NumOfShipmentsInPackage] ,[Package_Date] ,[Package_Cost] ,[Package_City]) VALUES ('John',5,'2016-09-22 01:35:00:000',580,'LON') REVERT; |
He will receive an error message indicates that the INSERT process is blocked on the Courier_Shipments table using the block predicate, as he is trying to insert a new record not related to his name as follows:

Again, if the previous insert statement is modified by replacing John name with Mark name and execute it with Mark’s user:
|
1 2 3 4 5 6 7 8 9 10 11 |
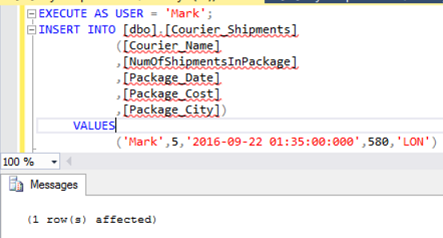
EXECUTE AS USER = 'Mark'; INSERT INTO [dbo].[Courier_Shipments] ([Courier_Name] ,[NumOfShipmentsInPackage] ,[Package_Date] ,[Package_Cost] ,[Package_City]) VALUES ('Mark',5,'2016-09-22 01:35:00:000',580,'LON') |
The new row will be inserted successfully:
Which is clear from running the SELECT statement with his user, showing the below result:

As you can conclude from the previous result, the Row-level Security feature can be also used to block the user from applying specific operations on the rows that he has no access on it.
New system objects have also been introduced in SQL Server 2016 to query the Row-Level Security feature’s information. The sys.security_policies can be used to retrieve all information about the defined security policy on your database as below:
|
1 2 3 |
SELECT name,type_desc ,create_date ,modify_date,is_enabled,is_schema_bound FROM sys.security_policies |
The result in our case will be like:

The sys.security_predicates system object also can be used to retrieve all predicates; filter and block predicates defined within the security policy as follows:
|
1 2 3 |
SELECT * FROM sys.security_predicates |
The security policy predicates in our demo will be like:

A common question that you may ask or may be asked, is if there any performance impact or side effect when using the Row-Level Security feature? The suitable answer here is that it depends. Yes, it depends on the complexity of the predicate logic you define, as it will be checked for each data access in your table. If you define a simple direct predicate filter, you will not notice any overhead or performance degradation in your database.
Conclusion
SQL Server 2016 comes with many useful features that make our life easier. One of these features is the Row-Level Security feature that is used to secure the access on the database at the row level, by filtering the data that the user has no access to and allow him/her to work only on the rows he/she has access to. Row-Level Security also enables users to block specific operations by preventing the user from inserting, updating or deleting the data he/she doesn’t have to. You can easily add the predicates and filtering criteria that fit your situation, but complex predicates will degrade the database performance as this predicate will be checked each time a data access is performed. The most important advice here is to test this feature and your custom configurations on a test environment first before applying it to the production environment in order to be in the safe side.
See more
To audit all SQL database and security activities, consider ApexSQL Audit, an enterprise level SQL Server auditing tool.
Useful links


He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021