
Summary
While alerting on failed SQL Server Agent jobs is straightforward, being notified when a job is missed is not a simple or built-in feature.
If the SQL Server Agent is stopped due to an issue with the service, server, or a planned maintenance, any jobs that would have executed will be skipped without a warning or alert. This could lead to important tasks never occurring.
In this article, we will build a solution that compares expected executions with actual job runs and reports on any differences found. When automated, this can ensure that important jobs are never missed.
Prerequisites
This project requires a handful of pieces in order to function:
- A calendar table. This is a table with a date primary key and a variety of metrics based on that date, such as day of the week, week in the quarter, or day of the year. Details on building one (if you do not already have one) can be found here: Designing a Calendar Table
- A process that can generate SQL Server Agent schedules for any given range of dates and times. The following article contains a proc that will handle this task for us: Generating Schedules with SQL Server Agent
- A process that will capture SQL Server Agent job run history and compare it to the results of the expected executions. That is the piece of the puzzle that we will focus on in this article
To simplify getting all of this working, all of the above scripts will be attached to this article so that you can download them and get started quickly.
Building a Solution
To find instances of missed SQL Server Agent jobs, we need to read the job history in MSDB and compare the results to the expected job run list. Before starting, we should define boundaries for our research. Typically, we will only ever analyze a relatively limited time span of job history, and the bounds of that date/time range should be given by parameters. For our discussion, we will define the following 2 parameters for this purpose:
- @start_time_local: The start time for the range we will analyze. This time is provided in local time to match up with the data stored in MSDB, which is all based on local server time. If the server is maintained in UTC, then these times will match UTC times as well
- @end_time_local: The end time for the range we will analyze
Boundaries are needed to ensure we do not process too much history and exceed the retained history data within MSDB. We also would not benefit from monitoring missed jobs from a week ago. Ideally, we would want to know about this problem sooner rather than later, and more frequently rather than less often. To keep things simple, we’ll examine a half hour of data at a time whenever we run our process. If the job runs at 11:00am, we will check all jobs that ran and should have run between 10:30am and 11:00am.
Our first task is to collect the job run history for a given server. All of the data needed for this task can be found in MSDB tables:
- Msdb.dbo.sysjobs: Contains a row per job as defined in SQL Server Agent, along with details
- Msdb.dbo.sysjobhistory: Contains a row per job and job step as they are executed. Since this table contains both overall job success and step details, the step_id is used to distinguish between each. A step_id of 0 indicates the overall job completion info, whereas other steps indicate the completion details of each step. Errors, as well as completion times are included here
- Msdb.dbo.syscategories: Job categories are defined here, both system categories and customized ones that we create
- Msdb.dbo.sysjobactivity: Contains rows for the next queued future job run for each job. This can be used to check if a job is currently in the processes of executing and the progress it has made
Using some of these tables, we can compile a list of all executed jobs present in MSDB’s history:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM msdb.dbo.sysjobhistory INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobhistory.job_id INNER JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id WHERE sysjobs.enabled = 1 |
The results provide a row per job execution, as well as a row per step:

If step details are unneeded and all you care about is overall job completion details, then you may filter out all but step_id = 0. Note that the detailed error/warning messages associated with a job will be stored within the row associated with the step that generated an error. For example, if a job fails on step 3 with a foreign key violation, then the specifics of that error will be present in the history row for step_id = 3 only, and not in the overall job data for step_id = 0.
We can adjust the above query to bound our data based on a date range:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT sysjobs.job_id, sysjobs.name AS job_name, sysjobhistory.step_id, * FROM msdb.dbo.sysjobhistory INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobhistory.job_id INNER JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id WHERE sysjobs.enabled = 1 AND msdb.dbo.agent_datetime(run_date, run_time) >= @start_time_local AND msdb.dbo.agent_datetime(run_date, run_time) <= @end_time_local |
By setting bounds based on a start and end time, we can ensure we only consider recent data that is relevant to our work. A job that ran a week ago is no longer needed for researching recent missed jobs, nor do we want to scan the same data more than once. The function msdb.dbo.agent_datetime allows us to quickly convert between the integer representations of dates within MSDB and the DATETIME data type that we will want to use for any work we do.
In addition to job history, we also want to verify if any jobs are currently running. If so, we don’t want to inadvertently report them as missed as they should run, but have yet to complete. The following query will return data on any currently running jobs that started during the period of time we are examining:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM msdb.dbo.sysjobactivity INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobactivity.job_id WHERE sysjobactivity.start_execution_date IS NOT NULL AND sysjobactivity.stop_execution_date IS NULL AND sysjobactivity.start_execution_date BETWEEN @start_time_local AND @end_time_local; |
Note that we can determine if a job is running based on the existence of an execution start date, but without a stop date. The results will look like this:

With these 2 queries, we can capture a list of all jobs that are running or that have recently executed and completed.
The last component needed to begin analyzing missed jobs is a list of expected runtimes based on job schedules. This is a bit of an involved project, so much so that I dedicated an entire article to creating a solution to this problem. If you already have a solution that returns this data, feel free to insert it into the process in place of mine. Code in this article will utilize the parameter structure of the script introduced above, though, so some slight adjustments will be needed if another stored procedure is to be used with it.
We’ll briefly introduce the syntax for this stored procedure before moving on to detecting missed jobs:
|
1 2 3 4 5 6 7 |
EXEC dbo.generate_job_schedule_data @start_time_utc = NULL, @end_time_utc = NULL, @start_time_local = '1/21/2019 00:00:00', @end_time_local = '1/21/2019 02:00:00', @return_summarized_data = 1, @include_startup_and_idle_jobs_in_summary_data = 0; |
6 parameters are defined for the stored procedure dbo.generate_jbo_schedule_data:
- @start_time_utc: The beginning of the time frame to monitor, in UTC
- @end_time_utc: The end of the time frame to monitor, in UTC
- @start_time_local: The beginning of the time frame to monitor, in the local server time zone
- @end_time_local: The end of the time frame to monitor, in the local server time zone
- @return_summarized_data: When set to 1, will return a row per job with a grouped summary of jobs, run counts, etc…When set to 0, it will return a row per job execution. While the detail data can be useful, it will also become very large on a server with lots of jobs or jobs with very frequent execution. Our solution will summarize results to keep things fast and efficient
- @include_startup_and_idle_jobs_in_summary_data: When set to 1, will include a row for jobs configured to run on SQL Server Agent startup or when the server is idle. We do not need this here, so it will be set to 0
The datetime ranges can be provided in local time or UTC time and the proc will manage conversions as needed via the SQL server’s UTC offset. This provides some level of convenience, depending on who or what is going to run this process.
With these 3 pieces, we can create a stored procedure that will compare job history to expected job executions and determine if anything is missing and alert on it.
Detecting Missed Jobs
Our task is to create two lists of job runs and compare them. If the expected job run count for any given job is higher than the actual job run count (including in-process executions), then we have a problem that is potentially worth alerting on. For the purposes of this demo, we will analyze a half-hour time period from 5 minutes ago through 35 minutes ago. Not including the immediately preceding 5 minutes reduces the noise from jobs that are executing at the moment that this analysis is performed.
To enumerate the time period that we will process, we’ll begin our process with two parameters:
|
1 2 |
@start_time_local DATETIME, @end_time_local DATETIME |
These are self-explanatory and bound our data analysis to the specific period of time that we defined above.\
To store data for this time period, we’ll create two temporary tables to store these metrics so that we can easily compare the two:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE #job_schedule_metrics ( job_id UNIQUEIDENTIFIER, job_name VARCHAR(128) NOT NULL, first_job_run_time_utc DATETIME NOT NULL, last_job_run_time_utc DATETIME NOT NULL, first_job_run_time_local DATETIME NOT NULL, last_job_run_time_local DATETIME NOT NULL, count_of_events_during_time_period INT NOT NULL, job_schedule_description VARCHAR(250) NOT NULL ); |
This table will contain the output of the stored procedure dbo.generate_job_schedule_data and will be summarized so that we only get a row per job, rather than a full list of all possible executions. This will be the full list of SQL Server Agent job executions that were supposed to occur during a given time period.
|
1 2 3 4 |
CREATE TABLE #job_run_history_metrics ( job_id UNIQUEIDENTIFIER, job_name VARCHAR(128) NOT NULL, run_count INT NOT NULL); |
This temporary table will also contain a row per job for each execution that actually occurred and was logged in MSDB for a given time period.
Let’s start out by collecting metrics on job history:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
WITH CTE_STEP_COUNTS AS ( SELECT sysjobs.job_id, sysjobs.name AS job_name, sysjobhistory.step_id, COUNT(*) AS job_step_count FROM msdb.dbo.sysjobhistory INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobhistory.job_id INNER JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id WHERE sysjobs.enabled = 1 AND msdb.dbo.agent_datetime(run_date, run_time) >= @start_time_local AND msdb.dbo.agent_datetime(run_date, run_time) <= @end_time_local GROUP BY sysjobs.name, sysjobs.job_id, sysjobhistory.step_id) INSERT INTO #job_run_history_metrics (job_id, job_name, run_count) SELECT CTE_STEP_COUNTS.job_id, CTE_STEP_COUNTS.job_name, MAX(CTE_STEP_COUNTS.job_step_count) AS run_count FROM CTE_STEP_COUNTS GROUP BY CTE_STEP_COUNTS.job_name, CTE_STEP_COUNTS.job_id; |
This query provides a bit of additional detail to ensure that jobs in progress are not included (yet). By counting the occurrence of each completed step in each job, we can determine which is most frequent, which ultimately represents the number of times a job was executed, even if some subsequent steps are still awaiting execution.
We still want to include running jobs as an addition to this data. This provides an optimistic interpretation of job data, assuming by default that a job in progress will complete. This is acceptable as our goal is to report missed jobs and not failed/cancelled jobs. We also automatically include manual job runs in this count as an assumption that if an operator executes a job outside of the bounds of a typical schedule that it should count towards the history for a given time period.
The following query will check exclusively for SQL Server Agent jobs that are currently executing and if so increment the job count by 1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
MERGE INTO #job_run_history_metrics AS TARGET USING ( SELECT sysjobactivity.job_id, sysjobs.name AS job_name FROM msdb.dbo.sysjobactivity INNER JOIN msdb.dbo.sysjobs ON sysjobs.job_id = sysjobactivity.job_id WHERE sysjobactivity.start_execution_date IS NOT NULL AND sysjobactivity.stop_execution_date IS NULL AND sysjobactivity.start_execution_date BETWEEN @start_time_local AND @end_time_local GROUP BY sysjobactivity.job_id, sysjobs.name) AS SOURCE ON (SOURCE.job_id = TARGET.job_id) WHEN MATCHED THEN UPDATE SET run_count = run_count + 1 WHEN NOT MATCHED BY TARGET THEN INSERT (job_id, job_name, run_count) VALUES ( SOURCE.job_id, SOURCE.job_name, 1); |
Since any given job may only be executing at any given point in time, incrementing by one is sufficient for our needs.
Populating expected scheduled job metrics is a simple task as we have already tackled a stored procedure to provide this data:
|
1 2 3 4 5 |
INSERT INTO #job_schedule_metrics (job_id, job_name, first_job_run_time_utc, last_job_run_time_utc, first_job_run_time_local, last_job_run_time_local, count_of_events_during_time_period, job_schedule_description) EXEC dbo.generate_job_schedule_data @start_time_local = @start_time_local, @end_time_local = @end_time_local, @return_summarized_data = 1, @include_startup_and_idle_jobs_in_summary_data = 0; |
This populates the temp table with a row per job that indicates how many times the job should run during the time period specified. Being able to encapsulate the logic of this process into a single stored procedure and reuse it as-needed here is a big convenience and is worth implementing in this fashion, regardless of how you crunch this data.
At this point, we have everything we need and can compare our two data sets to determine if any jobs are missed:
|
1 2 3 4 5 6 7 8 |
SELECT job_schedule_metrics.*, ISNULL(job_run_history_metrics.run_count, 0) AS run_count FROM #job_schedule_metrics job_schedule_metrics LEFT JOIN #job_run_history_metrics job_run_history_metrics ON job_run_history_metrics.job_id = job_schedule_metrics.job_id WHERE job_run_history_metrics.job_id IS NULL OR (job_run_history_metrics.job_id IS NOT NULL AND job_run_history_metrics.run_count < job_schedule_metrics.count_of_events_during_time_period); |
We left join our job history to ensure that we account for both jobs that have missed some runs and those that missed all runs (and therefore have no history data to join).
If no jobs are missed, then this query will return no data and an IF EXISTS check against it will return 0. If jobs are missed, then we will get a set of data that indicates when the job should have run, how many times it should have run, and the actual number of executions. Here is a sample of missed job execution data:

We can see that on my test server there are 2 jobs that should have executed, but did not. We include the schedule details as well, which assists in diagnosing what should have happened (but did not). Lastly, if we want, we can dump the missed job data into a temporary table and construct an HTML email based on that data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
DECLARE @profile_name VARCHAR(MAX) = 'Default Public Profile'; DECLARE @email_to_address VARCHAR(MAX) = 'ed@myemail.com'; DECLARE @email_subject VARCHAR(MAX); DECLARE @email_body VARCHAR(MAX); SELECT @email_subject = 'Missed Job Alert: ' + ISNULL(@@SERVERNAME, CAST(SERVERPROPERTY('ServerName') AS VARCHAR(MAX))); SELECT @email_body = 'At least one job run was missed on ' + ISNULL(@@SERVERNAME, CAST(SERVERPROPERTY('ServerName') AS VARCHAR(MAX))) + ' during the period ' + CAST(@start_time_local AS VARCHAR(MAX)) + ' to ' + CAST(@end_time_local AS VARCHAR(MAX)) + ': <html><body><table border=1> <tr> <th bgcolor="#F29C89">Job Name</th> <th bgcolor="#F29C89">Job Schedule Description</th> <th bgcolor="#F29C89">Expected job run count</th> <th bgcolor="#F29C89">Actual job run count</th> </tr>'; SELECT @email_body = @email_body + CAST((SELECT missed_jobs.job_name AS 'td', '', missed_jobs.job_schedule_description AS 'td', '', CAST(missed_jobs.count_of_events_during_time_period AS VARCHAR(MAX)) AS 'td', '', CAST(ISNULL(missed_jobs.run_count, 0) AS VARCHAR(MAX)) AS 'td' FROM #missed_jobs missed_jobs ORDER BY missed_jobs.job_name ASC, missed_jobs.job_schedule_description FOR XML PATH('tr'), ELEMENTS) AS VARCHAR(MAX)); SELECT @email_body = @email_body + '</table></body></html>'; SELECT @email_body = REPLACE(@email_body, '<td>', '<td valign="top">'); EXEC msdb.dbo.sp_send_dbmail @profile_name = @profile_name, @recipients = @email_to_address, @subject = @email_subject, @body_format = 'html', @body = @email_body; |
This will provide a nicely formatted email that includes all of the columns returned above. If email is your alerting method of choice, then this is a good start on turning missed job metrics into an email. Here is an example of what that email will look like:

Of course, email is not the only way to alert on missed jobs. Some alternate ideas include:
- This data could be sent to a reporting server for regular processing
- A monitoring service can consume this data and return missed job runs when found
- A central server can execute the checks against MSDB on a set of target servers, thus removing the need for decentralized alerts
- Powershell can manage this process
Depending on your database environment, there may be other possibilities as well. Tailor your own processes to fit the data and make best use of your existing tools.
What are Target Jobs for This Process?
Not all jobs are created equal and we do not need to monitor every single job for completeness. Only critical jobs for which a missed run is problematic should be considered.
For example, missing a transaction log backup can typically be tolerated as the next run of this job will catch up where the previous one left off and continue normally from that point on. Missing a full backup, though, can result in adverse side-effects, such as bloated differential backups and unnecessarily long backup chains.
The following is a short list of jobs that benefit most from a process such as this:
- Full backup jobs. Possibly differential backups, if infrequent
- Reports that generate and are expected at specific times
- ETL processes that move/transform data at specific points in time
- Data warehousing or analytics tasks
These tasks are all run relatively infrequently and are time-sensitive. A data collection process that needs to take a point-in-time snapshot at a certain time of day will become stale as time passes after its expected runtime. Missed backups or critical maintenance processes can have unintended consequences for performance, business SLAs, RPO (recovery point objective), or RTO (recovery time objective).
While all jobs can be monitored, some will benefit more than others. Worse, the noise of low-priority jobs being missed and alerted on can be a distraction when an unexpected outage occurs. Consider categorizing or filtering SQL Server Agent jobs so that only important ones are monitored for missed runs.
Categories can be added easily via TSQL:
|
1 2 3 4 |
EXEC msdb.dbo.sp_add_category @class = 'JOB', @type = 'LOCAL', @name = 'Unmonitored'; |
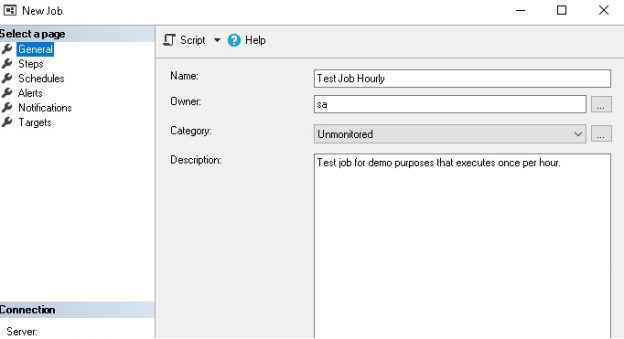
The result will be a new category that may be chosen when creating or modifying a job:
Categories are stored in msdb.dbo.syscategories and we can view jobs that are associated with that query by joining msdb.dbo.sysjobs to that table:
|
1 2 3 4 5 6 |
SELECT * FROM msdb.dbo.sysjobs INNER JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id WHERE syscategories.name = 'Unmonitored'; |
The results show the job that I created above:

Alternatives to this would include:
- Having specific parts of a job’s name indicate how monitoring tools treat them
- Maintain a metadata table for jobs that should or should receive additional monitoring
- Apply monitoring to all jobs indiscriminately
The correct choice depends on your environment and the style of jobs and loads that are processed. A report server with many infrequent (but important) jobs may benefit from a high level of failure/missed job reporting. A server that runs highly-resilient jobs constantly may not need to monitor for missed runs as they would catch up a soon as the server is returned to its typical operating state.
Gotchas
As with any monitoring process, we should consider the target set of jobs that we care about most with respect to catching missed jobs. There is no sense in monitoring anything unless there is a valid reason to do so. Here are some considerations for implementing this process (or one like it):
SQL Server Agent Unavailable for Extended Period of Time
If a server is unavailable for a long time and is not due to planned maintenance, then we would want to rely on other alerting mechanisms to find out, such as the SQL Server Agent service being unavailable or unreachable.
We should never rely on an alert for a purpose it is not intended for. A missed job alert should not be used as a method of alerting to a server or service being down.
SQL Server Agent History Retention
Job execution history is only as valuable as the amount of data that is retained. You may configure the retention policy via TSQL or by clicking on the properties for SQL Server Agent:
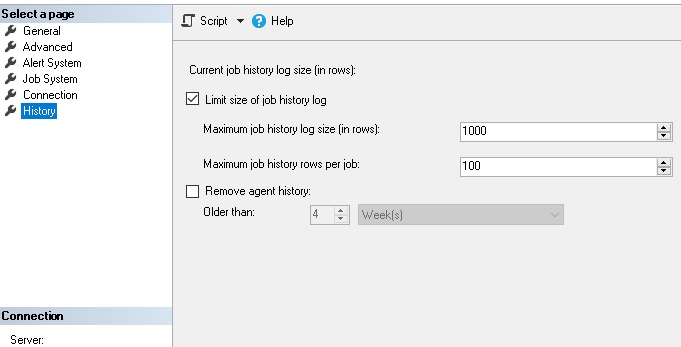
From here, we can adjust job history retention per job and also for the server as a whole. If job history falls off of the end of our retention period before the missed job alert reads it, then we will see false alerts.
In general, it is a good idea to maintain more than enough history to ensure that any history data needed for monitoring processes, operators, or for troubleshooting is available.
Long-Running Inconsistent Jobs
Some jobs are designed to run very often, but may essentially perform no-ops most of the time. The few times that work is needed, the job could run for minutes or hours. This will result in the job either being seen as completed successfully or in-progress. Using a semaphore to initiate a SQL Server Agent job process puts more power into metadata or code, but makes monitoring it difficult.
Any job that runs exceedingly often may be a good candidate to not be monitored for missed jobs. Instead, building them to be resilient may be more valuable. If it fails, we care and will respond, but otherwise can know that it runs often enough to tolerate server outages or maintenance.
Failed/Cancelled Jobs
We have covered missed jobs in detail, but could extend monitoring to provide additional metrics on failed jobs. SQL Server Agent allows jobs to be configured with failure actions, so this is a relatively straightforward scenario to alert on. That being said, a server with many jobs may spit out a ton of noise and for a busy server a more centralized approach may be beneficial. If this sounds interesting or useful, take a look at an article I wrote that covers a process to monitor and report on failed jobs: Reporting and alerting on job failure in SQL Server
An email for all job failures in a given time period may be cleaner and easier to manage than an email per failed job. This also provides us the ability to store the details of failures in a table as a permanent resource, in case email or network communications are unavailable at any given point in time.
Storage of Missed Jobs
If desired, a table may be created to store the details of missed jobs. This provides some additional logging in the event that email, a network, or other resources are unavailable to let us know of missed jobs when they are detected.
Conclusion
Missed jobs can be a serious problem when important reports, data loads, or backups fail to execute. By default, SQL Server does not monitor or alert on a job that was missed due to an outage, planned maintenance, or a server problem.
This can be problematic in any database environment, whether in an on-premises version of SQL Server or in Azure. Notifying an operator about a failed job condition is critically important. Equally important is to consider what to do when jobs are missed.
As an additional thought experiment, we can consider making jobs more resilient so that they can easily pick up where they left off without missing out on any critical processing. For example, if a full backup does not run as expected, a backup process could detect that and run it at the next available/acceptable time.
By monitoring and alerting on missed jobs, we can plug a gaping hole that is present in many SQL Server environments by default and allow us to manage maintenance, outages, or unusual events with less concern about what might have been missed during those scenarios.
Review questions
Q: How can I exclude specific jobs or groups of jobs?
A: Job categories can be used to classify jobs as special with regards to monitoring. Once classified, processes that read or act on job data can automatically filter them out. Other filters can be applied up front, such as those based on schedules, business hours, or priority.
Q: A job is indicated as missed, but isn’t! Why?
A: This is usually the result of jobs with unusually long runtimes. If a job runs long enough to miss its next execution time, then it will appear as missed, even if it isn’t. Similarly, jobs that run indefinitely will miss schedules naturally as well.
Assuming these types of jobs are resilient enough to tolerate these irregularities, then there is no need to monitor them for missed executions and they should be excluded from our process.
Q: Frequently executing jobs are showing as missed when they are not. What can I do about this?
A: SQL Server Agent maintains a history of job executions per job and overall as configured in the SQL Server Agent properties. If a job runs very often, it is possible that its history is being cleaned up before our process has a chance to read and process it.
There are multiple valid solutions to this, such as:
- Adjust job history retention in the SQL Server Agent properties to maintain more job runs
- Adjust our process to run more often
- If the job in question is resilient towards missed runs, then you may simply want to exclude it from monitoring missed runs
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019
Code
Download T-SQL code associated with this article here
Table of contents
| Generating Schedules with SQL Server Agent |
| Detecting and Alerting on SQL Server Agent Missed Jobs |

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack