
With the introduction of Microsoft’s new In-Memory OLTP engine* (code name Hekaton) a new type of nonclustered index was introduced to help you search the in-memory tables based on a range of values. Although the name is similar it does differ from the one we have in the traditional disk tables.
The target of the Hekaton project was to achieve 100 (hundred) times faster OLTP processing. The standard nonclustered indexes based on the B-tree were not the optimal solution, in-memory OLTP tables work with nonclustered indexes based on a Bw-Tree, a lock and latch free structure.
In 2011 the Bw-Tree was introduced by Microsoft Research, later the index based on it was referred as ‘range index’ but the ‘nonclustered indexes’ terminology is the official name now.
The nonclustered index is an ideal solution to optimize queries scanning the index for a range of values using inequality and range predicates (>, <, <=, >=, BETWEEN) and equality (=) when not using the full key value**.
|
1 2 3 4 5 6 |
SELECT OrderId, OrderDate FROM ShopOrders WHERE OrderDate > @Date SELECT LastName FROM EmpInformation WHERE LastName = ‘Be%’ |
We will discuss the nonclustered indexes, their internal structure (1), and how they work with the standard data modification statements (2).
Simply explained, in the In-Memory OLTP Engine, nonclustered indexes are a tree structure where a page location is referenced from a mapping table and when a page needs to be modified it is not edited in place but a new page is created instead.
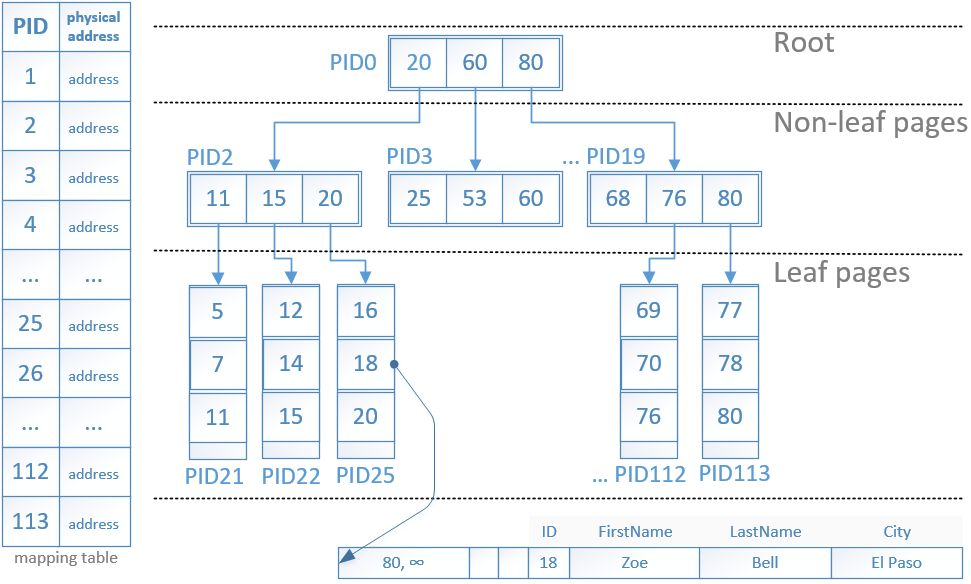
You can see from Figure 1 that the structure of the Bw-tree is similar to the B-tree, the main difference is that a mapping table is used to reference pages. Also the index pages are unchangeable once they are build.
The mapping table store the logical page ID (PID) and each PID maps to a physical memory address of a page. Index pages are never updated, instead when an edit is required they are replaced with a new page and the mapping table is updated with the memory address of the new page retaining the same PID.
The index pages as seen can be root, non-leaf and leaf pages.
The pages reference each other not by using a physical page number, but the logical PID relying on the mapping table. This is the key enabler for the performance of the nonclustered indexes as it helps to isolate the effects of non-leaf node split and updates to a specific node instead to the whole index structure.
The root and the non-leaf pages also referred to as internal index pages contain information about the Max key values, but not for the Minimum key values of a node, the effects of it we will review in another article.
The leaf note pages do not refer to the mapping table but have information for the real physical location of the data.
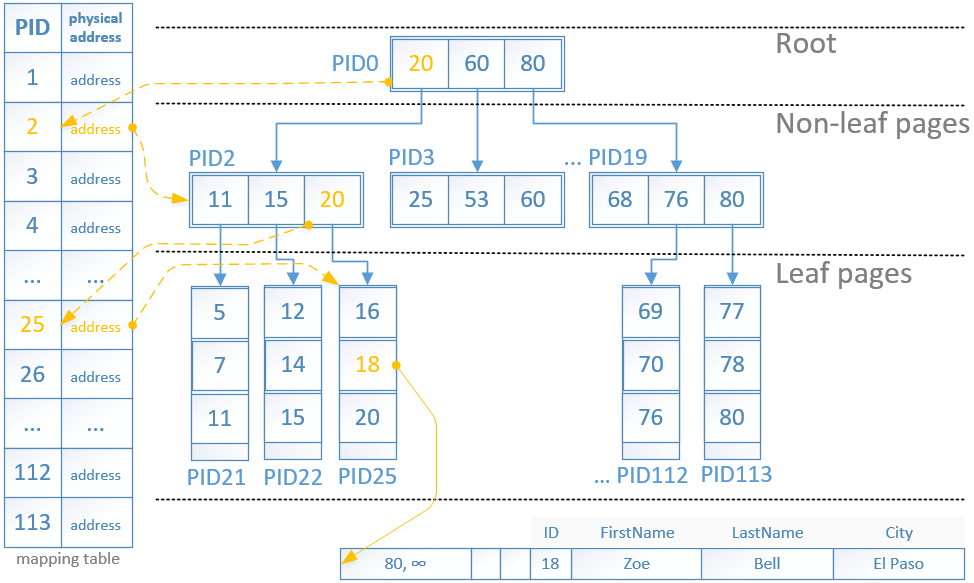
In order for the index to complete a seek request looking for rows with ID between ‘18’ and ‘19’ the following steps will be performed as seen on Figure 2.
We are starting with page PID0, it contains information for the maximum ranges of the next 3 pages. The range we are looking is between 18 and 19. The information about this range is in page PID2.
The PID2 is referenced thru the mapping table which provides us with the memory address.
The page PID2 contains information about the maximum ranges of its child pages. The information for range 15 to 20 is contained in page PID25.
The PID25 is referenced thru the mapping table which provides us with the memory address.
The page PID25 as a leaf page does not contain PID references but rather the physical location of the data pages. Upon reading the page PID25 we are able to locate all rows that satisfy our ‘WHERE’ clause.
If there are rows with duplicate data, for example multiple rows with ID of ‘18’ they will be linked together similar as in the hash indexes***. The leaf index pages will not contain information about duplicates.
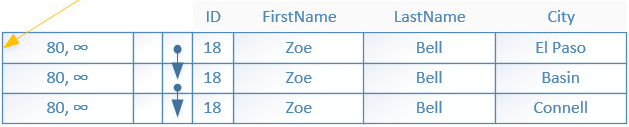
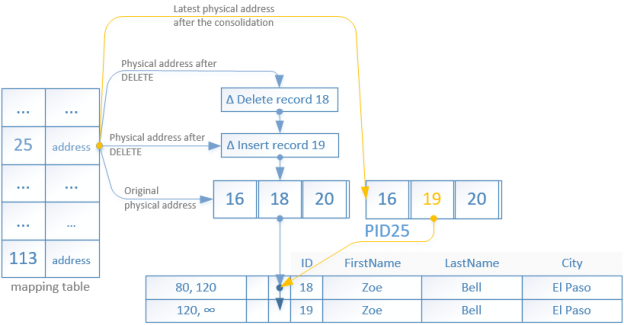
The same is true if a row is updated, again similar as in the hash indexes.
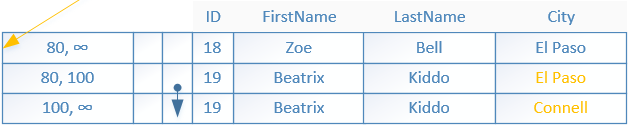
As already mentioned the index pages are not modified, instead data changes are represented using set of delta values. Each edit of an index page, no matter what, creates a new smaller page containing a delta record indicating the change that was made. DELETE and INSERT operations create a single delta record. UPDATE operations create two delta records, one for each task required. When a delta record is added, the mapping table is updated with the new physical address of the delta record page.
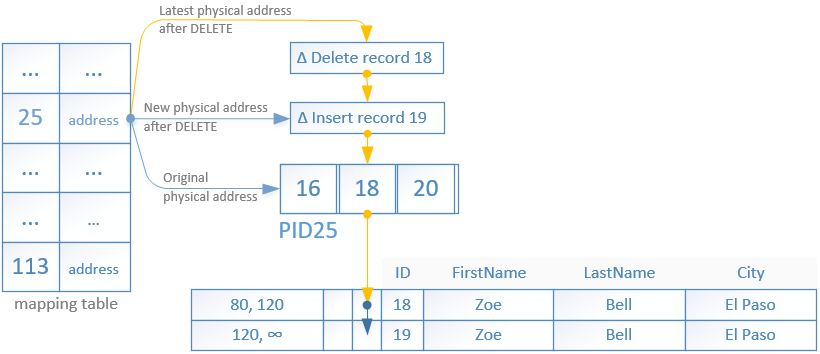
Figure 3 shows the operations required to modify a single row to have its ID updated from ‘18’ to ‘19’.
As we have already discussed, rows are not modified in place but rather a new row is inserted with updated BeginTs and EndTs referenced from the old record. The old record is then marked for deletion by having its EndTs updated.
In order to perform this operation a delta record is created for the INSERT operation of the new row.
The physical address for the PID25 in the mapping table is updated with the new one pointing to the delta record. The delta record references the original leaf page.
A new delta record is created for the deletion of the old row containing the ID ‘18’. Again the physical address for PID25 in the mapping table is updated with the latest one pointing to the last delta record.
You may have already guessed that a long chain of delta records can degrade the performance of a nonclustered index. Upon reaching a certain limit of elements in the chain the delta records and the referenced index page will be consolidated. The limit of elements in a chain is 16.
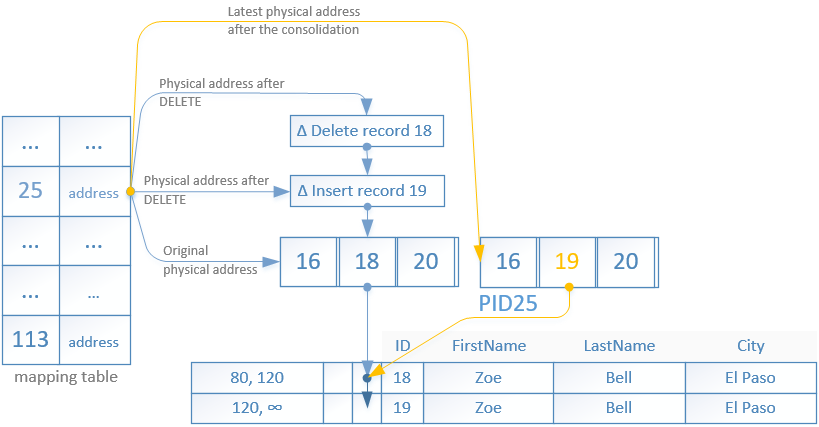
The consolidation takes the original page and its delta records and rebuilds the page appending the all delta records together with the latest operation which detected that the chain limit of 16 was reached.
Once the new page is ready the physical address in the mapping table will be replaced pointing to it and the old page will be marked for garbage collection.

View all posts by Kaloyan Kosev
- Performance tuning for Azure SQL Databases - July 21, 2017
- Deep dive into SQL Server Extended events – The Event Pairing target - May 30, 2017
- Deep dive into the Extended Events – Histogram target - May 24, 2017