
In the previous article, Copy data between Azure data stores using Azure Data Factory, we discussed how to copy the data stored in an Azure Blob Storage container to an Azure SQL Database table using Azure Data Factory and review the created pipeline components and result.
In this article, we will show how to copy data from an on-premises SQL Server database to an Azure SQL Database using Azure Data Factory.
Prepare On-premises SQL Server
In order to copy data from an on-premises SQL Server database to an Azure SQL Database using Azure Data Factory, make sure that the SQL Server version is 2005 and above, and that you have a SQL or Windows authentication user to connect to the on-premises SQL Server instance.
As the SQL Server instance is located inside an on-premises network, you need to set up a self-hosted integration runtime to connect to it. A self-hosted integration runtime provides a secure infrastructure to run the copy activities between a cloud data store and a data store in a private network. It is recommended for the self-hosted integration runtime to be on the same machine as the data source or in any machine close to the data source in order to reduce the time for the self-hosted integration runtime to connect to the data source.
In order to set up the self-hosted integration runtime, open the Azure Data Factory from the Azure Portal, click on the Manage icon at the left side of the window, select the Integration Runtime tab and click on the New option, as shown below:
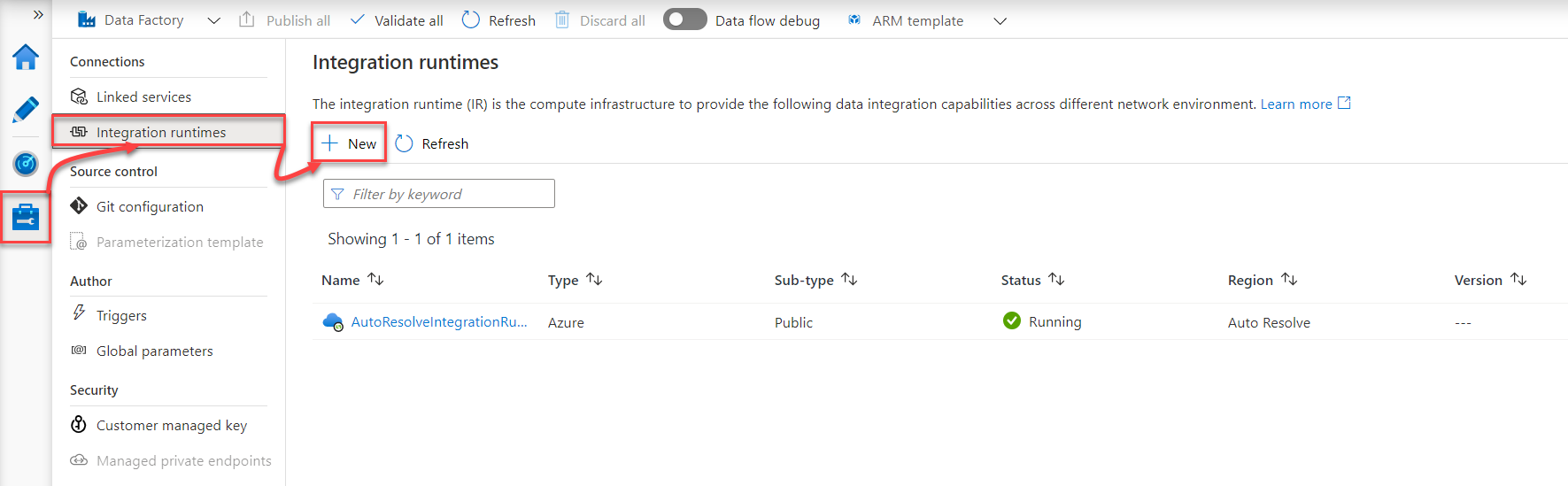
From the displayed Integration Runtime Setup window, choose the type of the integration runtime that you plan to create, which is Self-Hosted Integration Runtime in our scenario, then click Continue, as below:
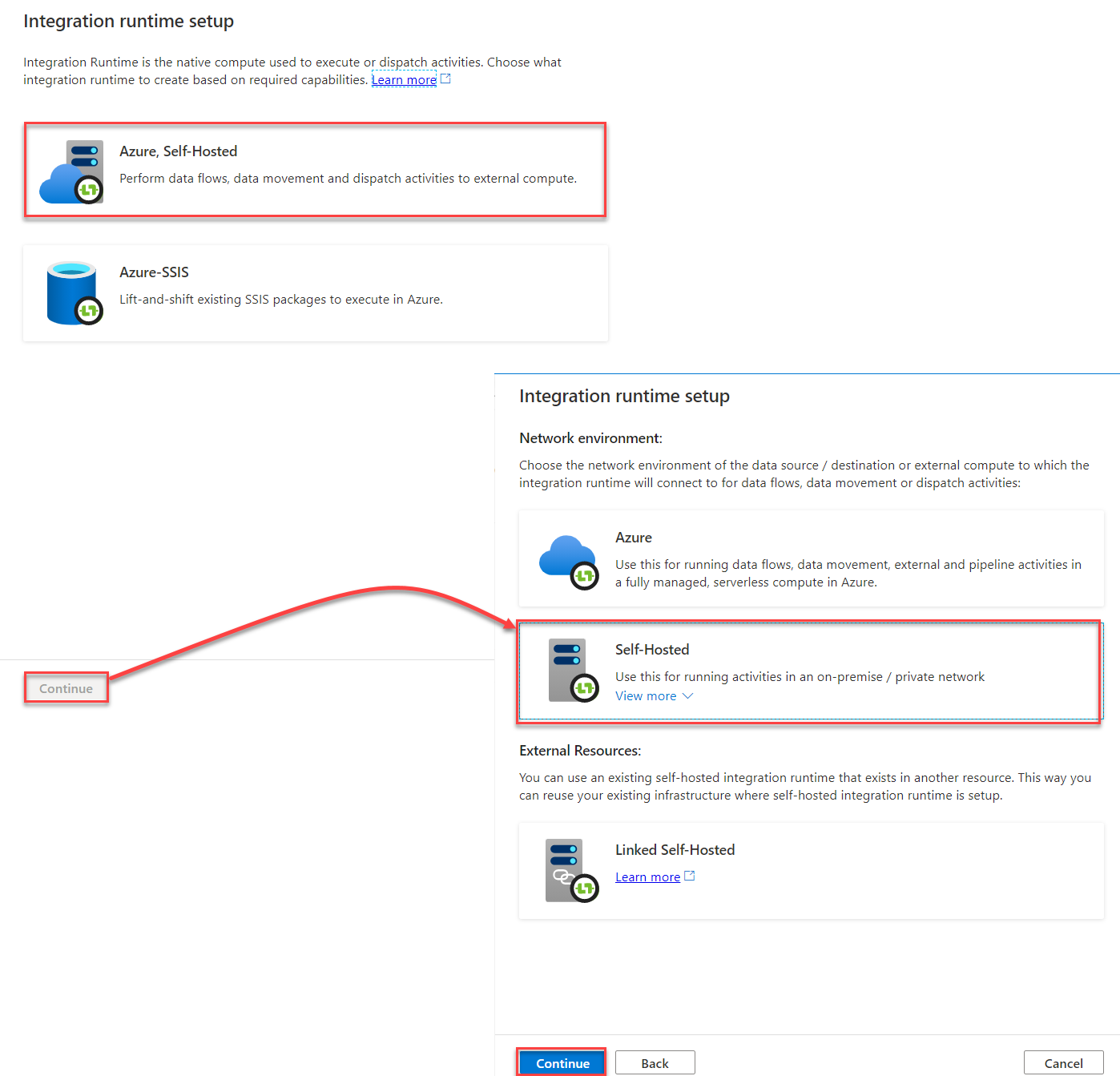
After that, provide a unique meaningful name for your SH-IR and click Create to proceed. A new window will be displayed, providing you with the link that will be used to download the latest version of the Self-Hosted IR and the authentication key that will be used to register the SH-IR. Click on the download link, copy the installation media to the machine that hosts the on-premises SQL Server instance and copy the authentication key to register it once installed, as below:
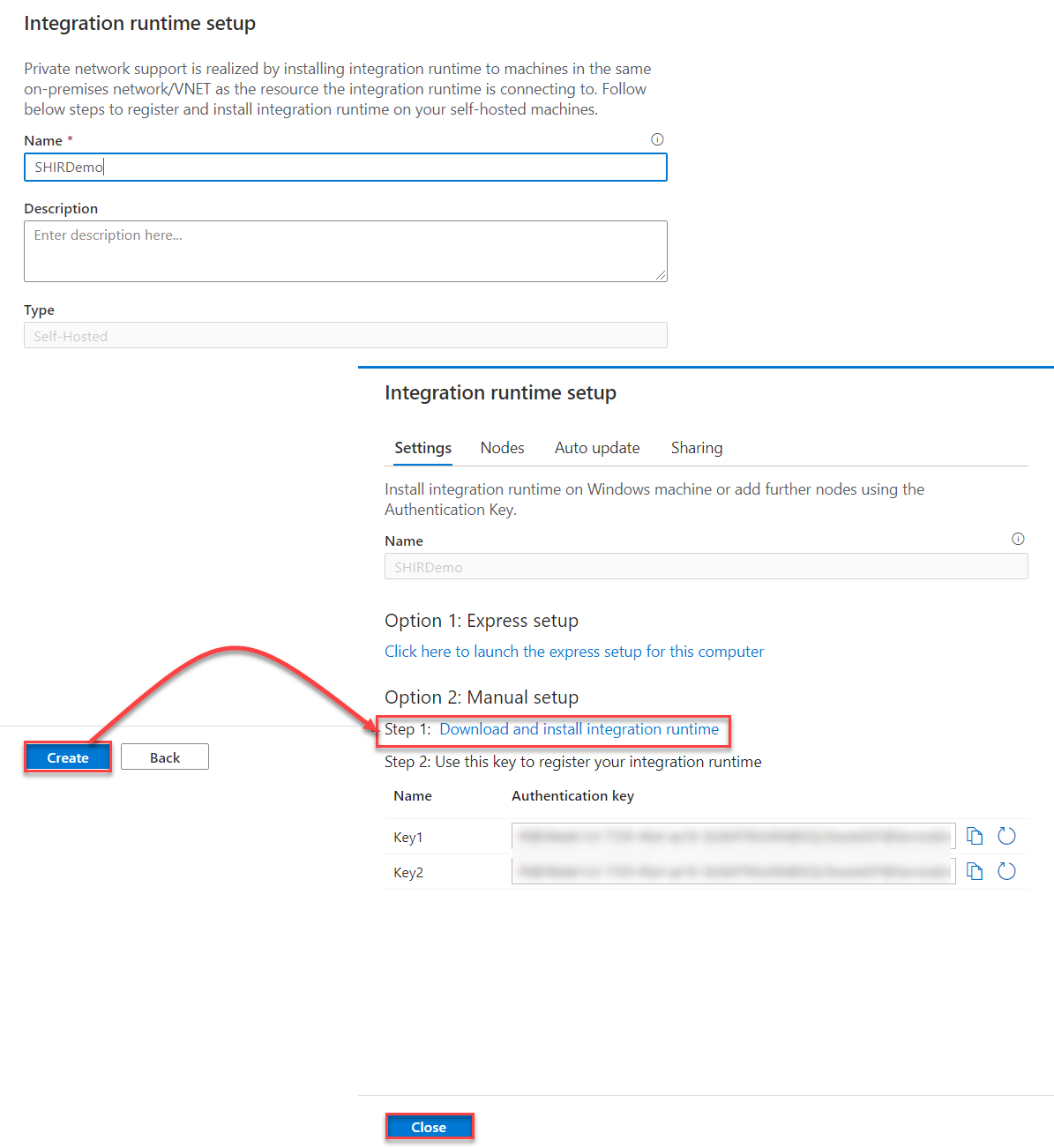
Now run the installation wizard of the Self-Hosted IR on the on-premises machine where the SQL Server instance is hosted, in which you will be asked to accept the terms of the license agreement, specify the installation path of the SH-IR then install it, as shown below:
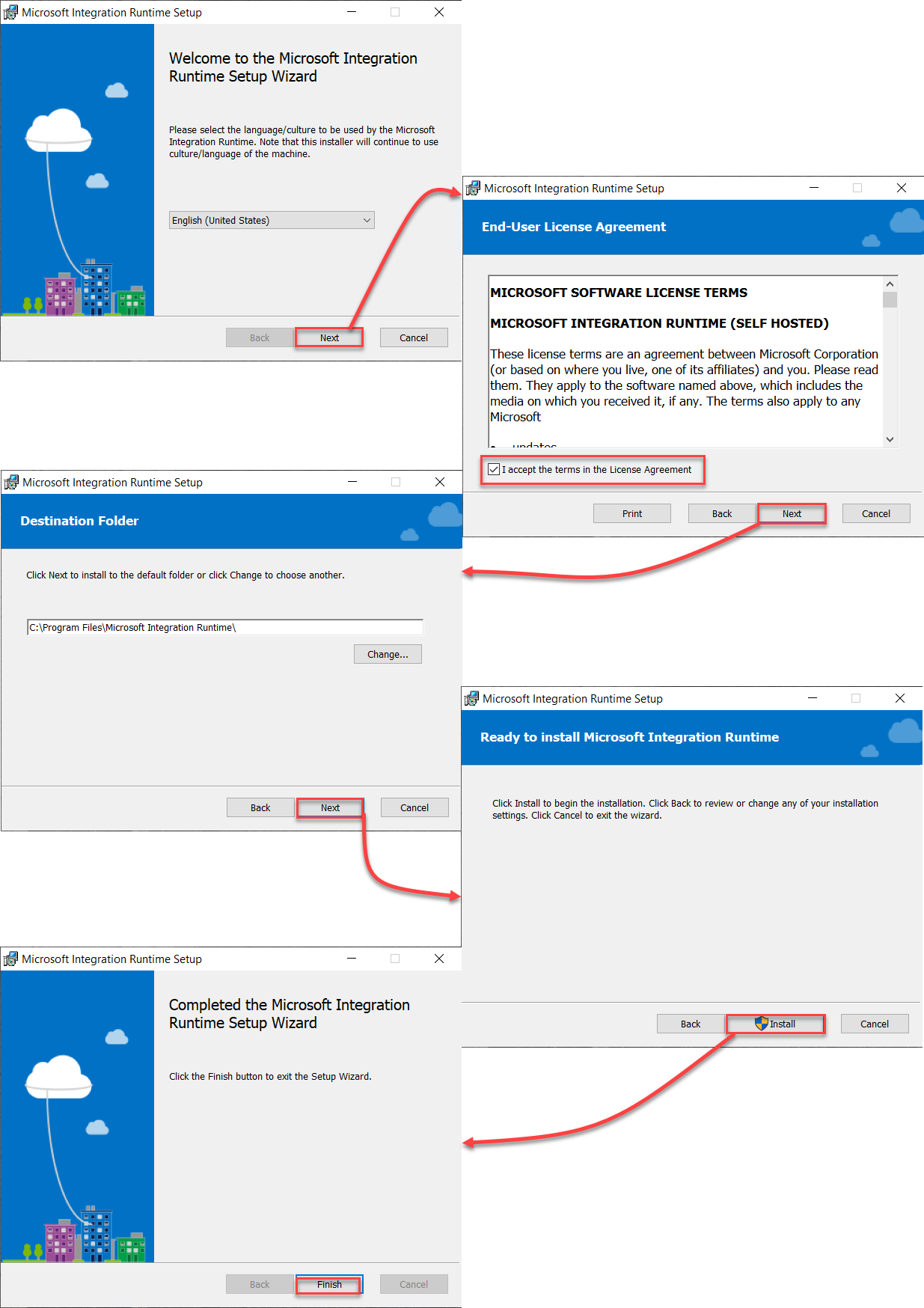
Once installed, a new window will be displayed to register the Self-Hosted IR to the Azure Data Factory using the authentication key copied previously, as shown below:
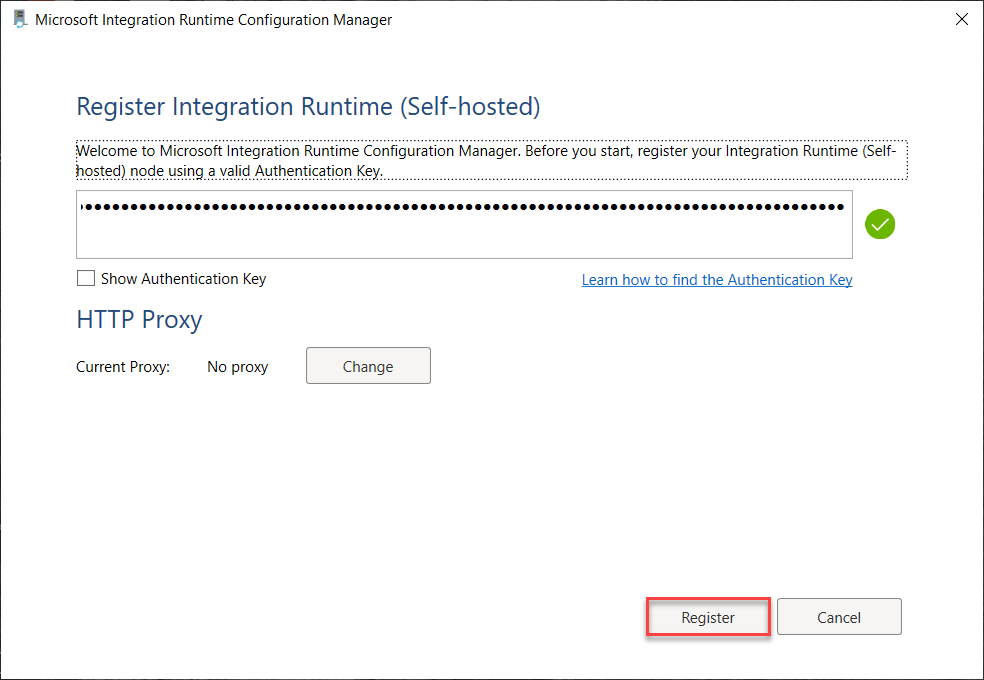
Then it will show the nodes that are assigned for the SH-IR, with the ability to configure the security of the SH-IR connection using certificates, as below:
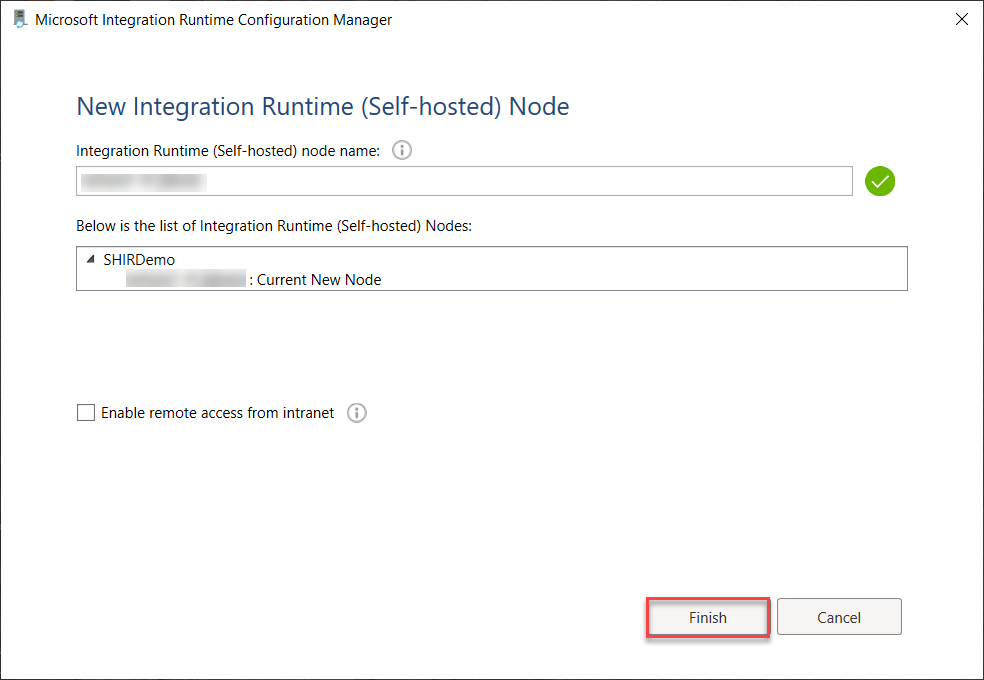
Finally, the Self-Hosted Integration Runtime is installed to the on-premises machine, registered and connected to the Azure Data Factory, as shown below:
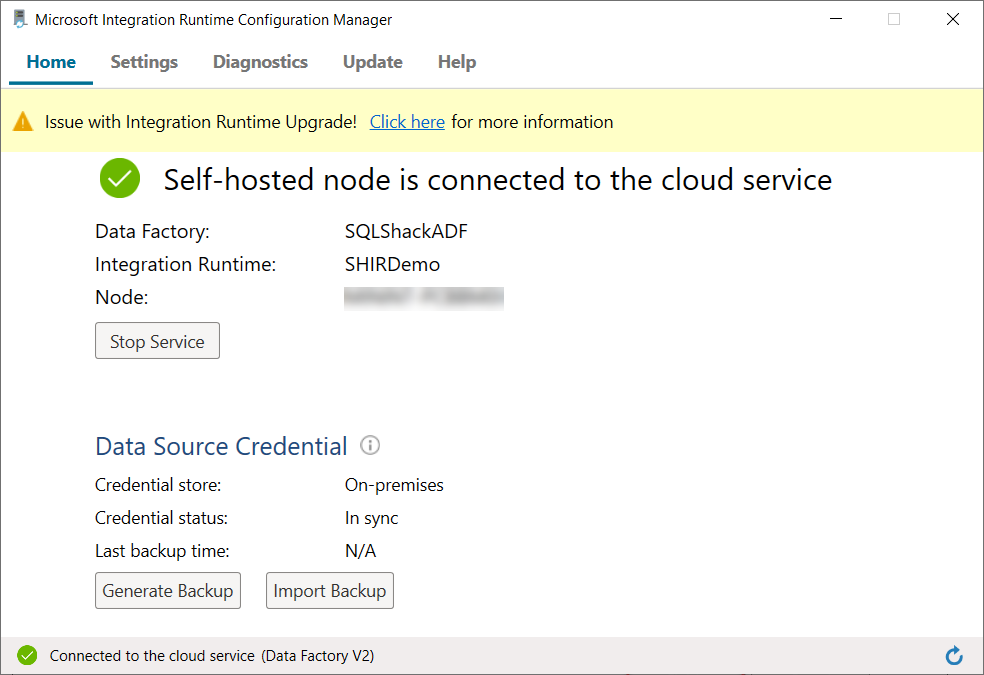
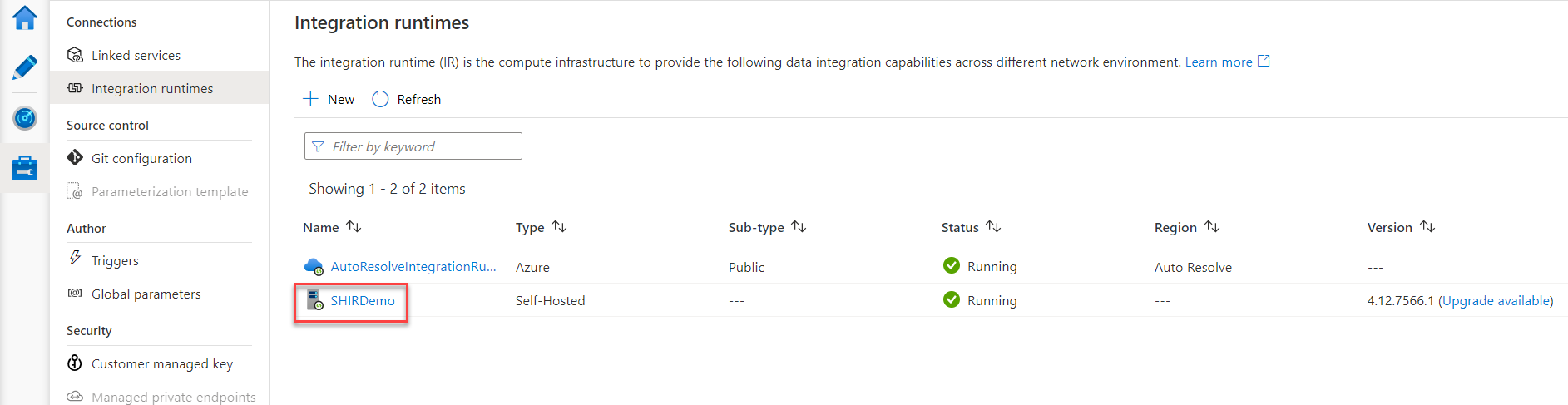
You can verify the SH-IR registration and connection from the Azure Data Factory, from the integration runtime tab under the Manage tab, where the SH-IR is listed under the IR list and the status of the IR is Running, with the ability to upgrade the SH-IR to the latest version from that page, as shown below:
Copy from On-premises to Azure SQL Database
With the Self-Hosted Integration Runtime installed and registered on the On-premises SQL Server machine, the source data store is ready. From the Azure SQL Database side, we need to make sure that the Allow Azure Services and resources to access this server firewall option is enabled, in order to allow the Azure Data Factory to access that database server.
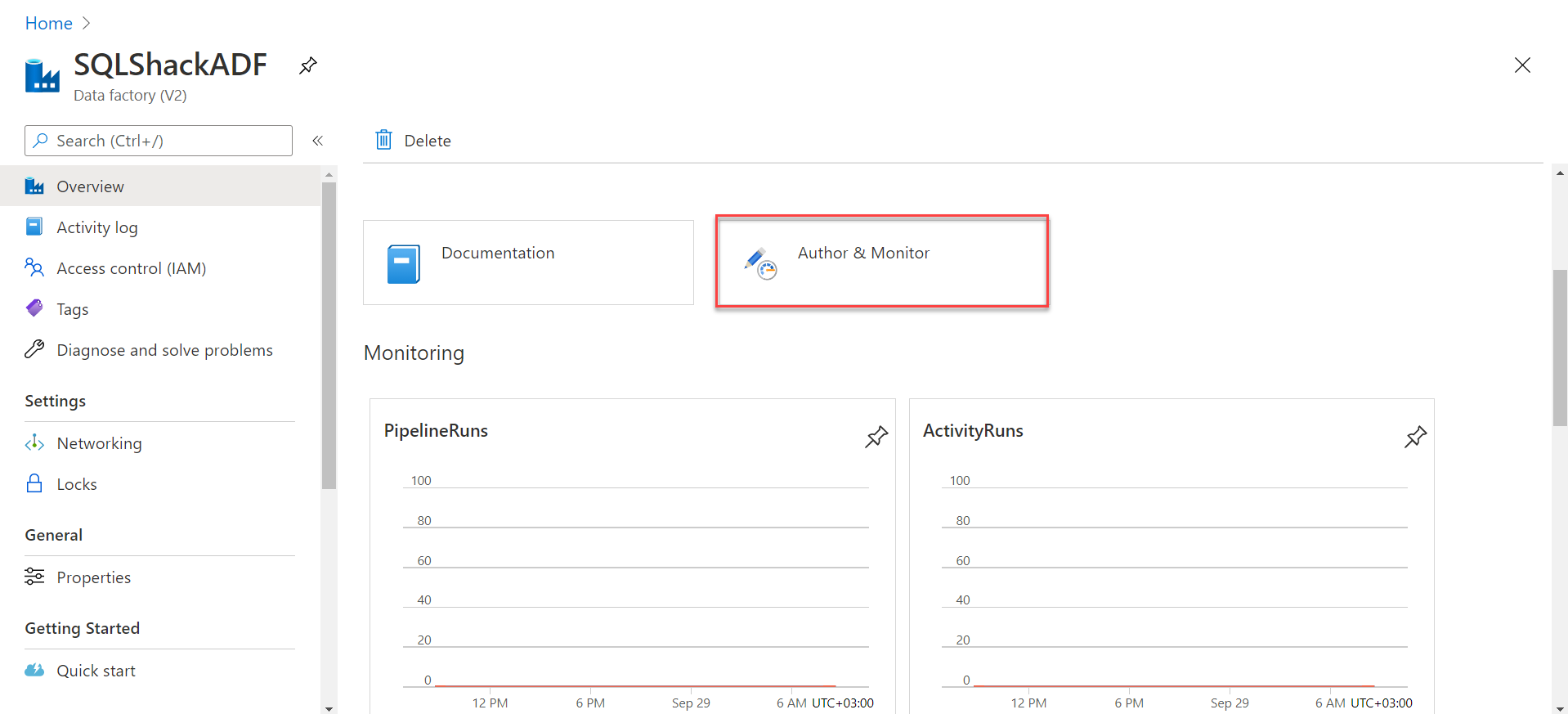
To create a pipeline that will be used to copy data from the on-premises SQL Server to the Azure SQL Database, open the Azure Data Factory from the Azure Portal and click on the Author & Monitor option under the Overview tab, as shown below:
From the opened Data Factory, you can create and configure the copy pipeline using two methods: creating the pipeline components one by one manually, using the Create Pipeline option or to create the pipeline using the Copy data tool, as shown below:

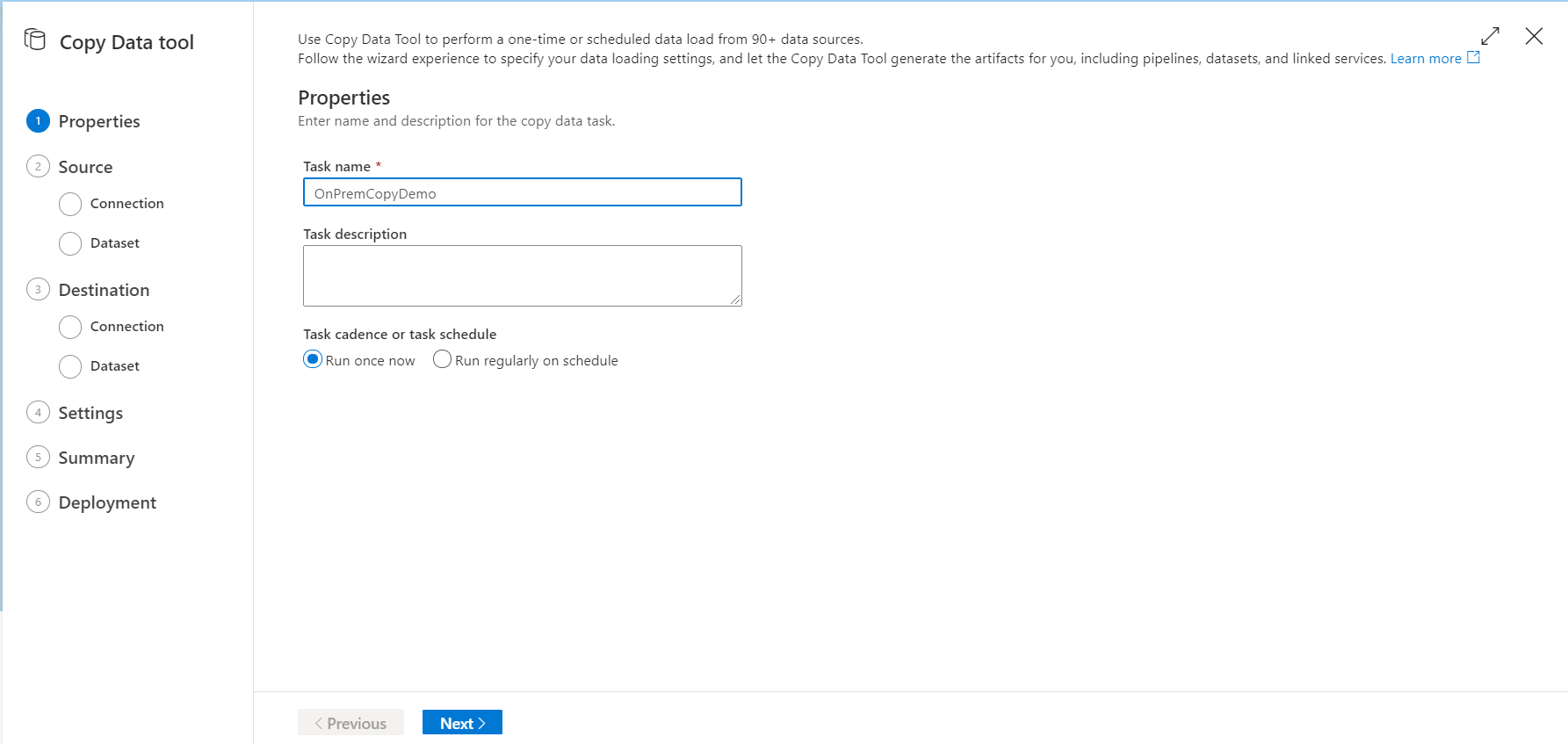
First, you need to provide a unique name for the copy activity that indicates the main purpose of that pipeline then specify whether to schedule this copy process or run it once, as shown below:
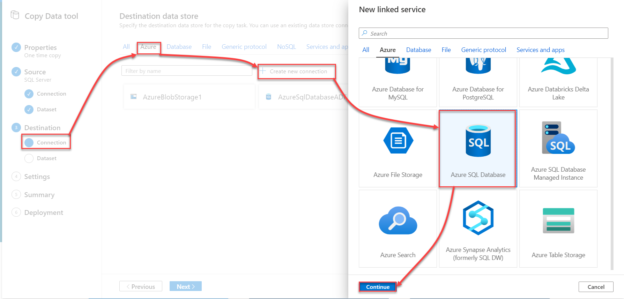
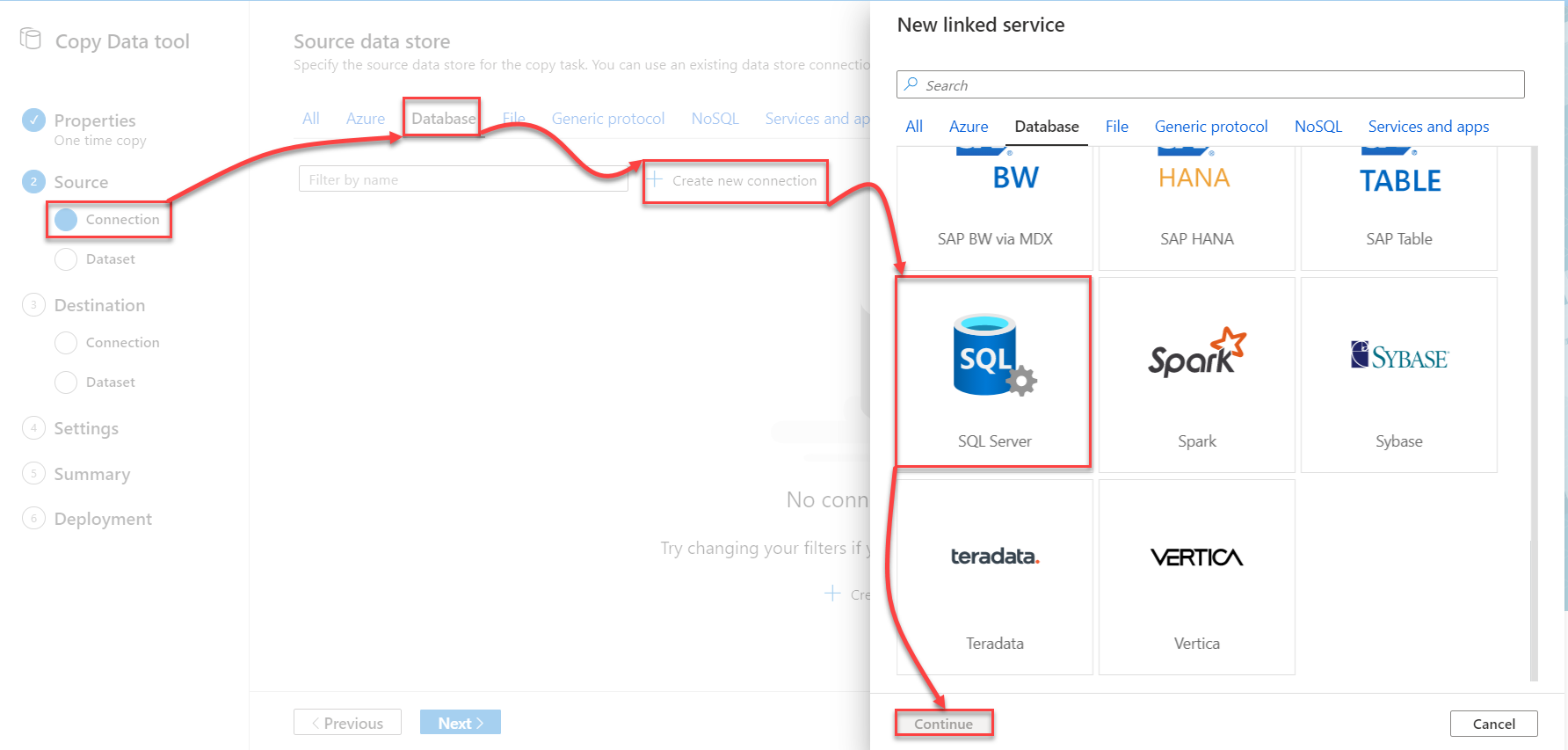
After that, you need to create the Linked Service that connects to the source data store, which is the on-premises SQL Server instance, as in our demo. To select the source data store type, click on the Database category, click on Create new connection then choose SQL Server data store, as shown below:
The New linked Service wizard will ask you to provide a unique name for the source Linked Service, the integration runtime that will be used to connect to the source data store, which is the Self-Hosted IR, the name of the on-premises SQL Server, the source database name and the credentials that will be used to connect to that database server. To verify the provided connection properties, click on the Test Connection option then Create to proceed with the Linked Service creation, as shown below:
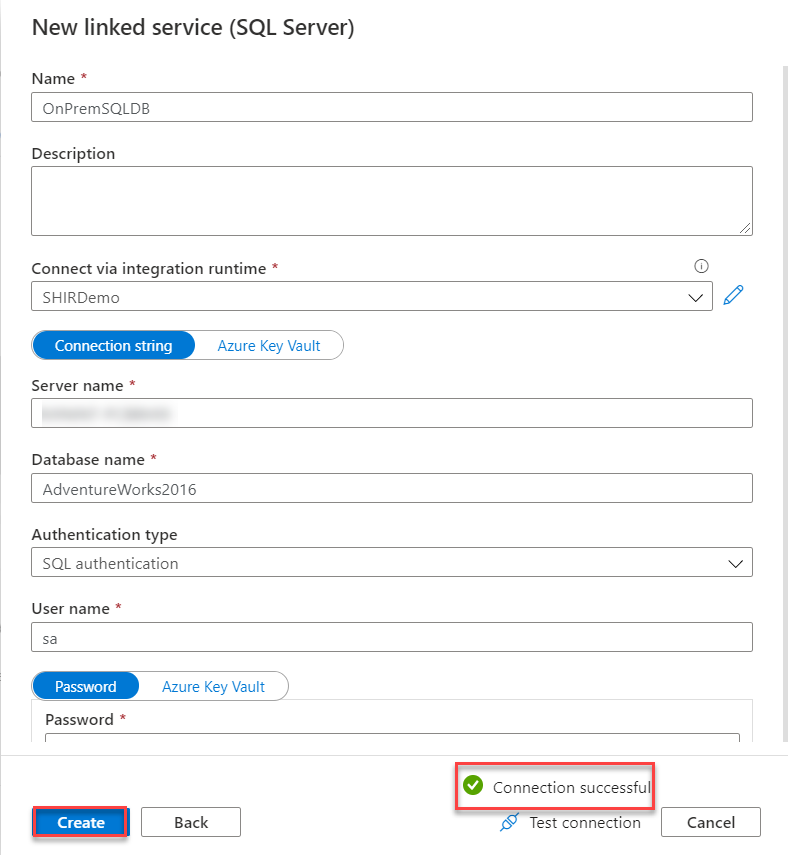
And the created source Linked Service will be displayed under the Source Data stores, as shown below:
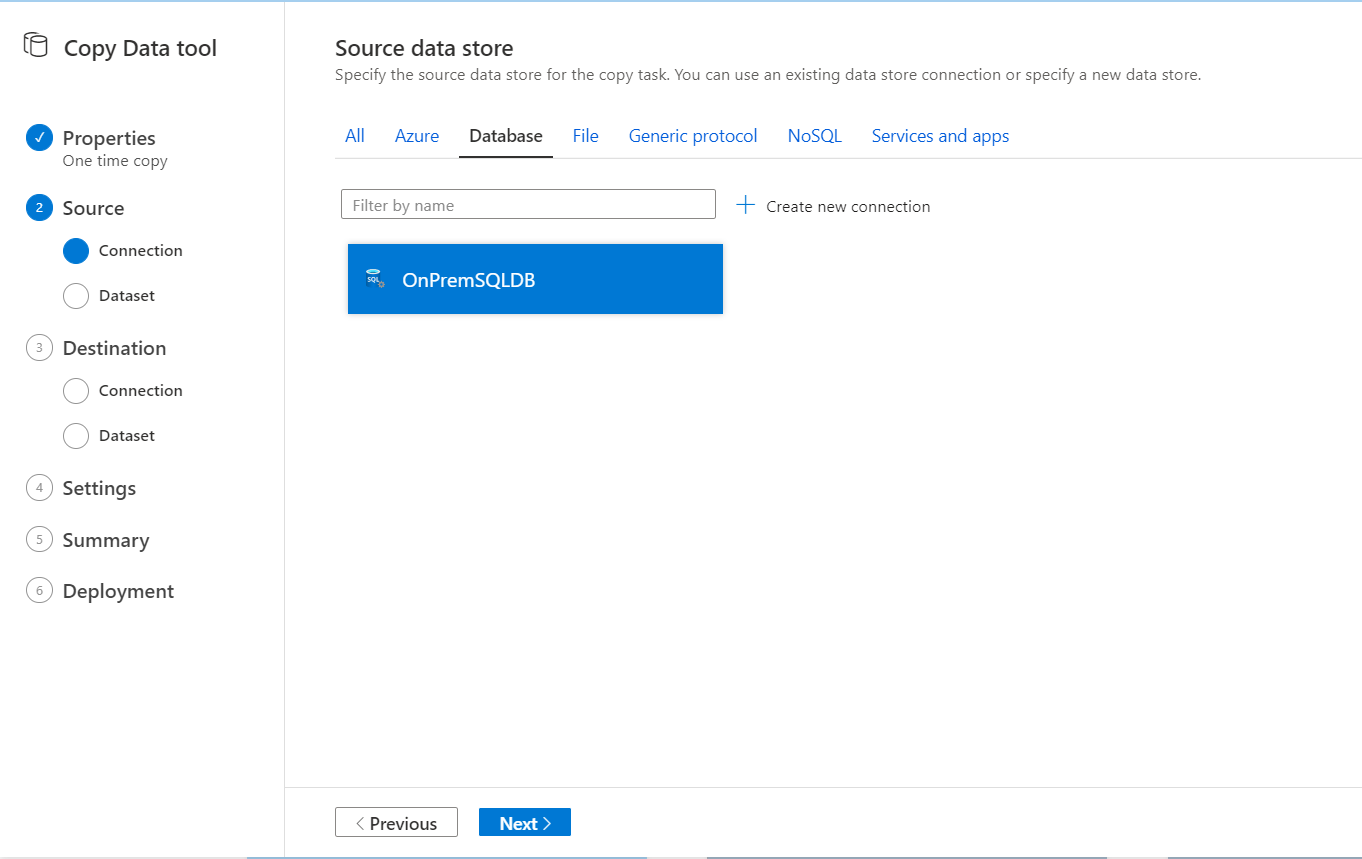
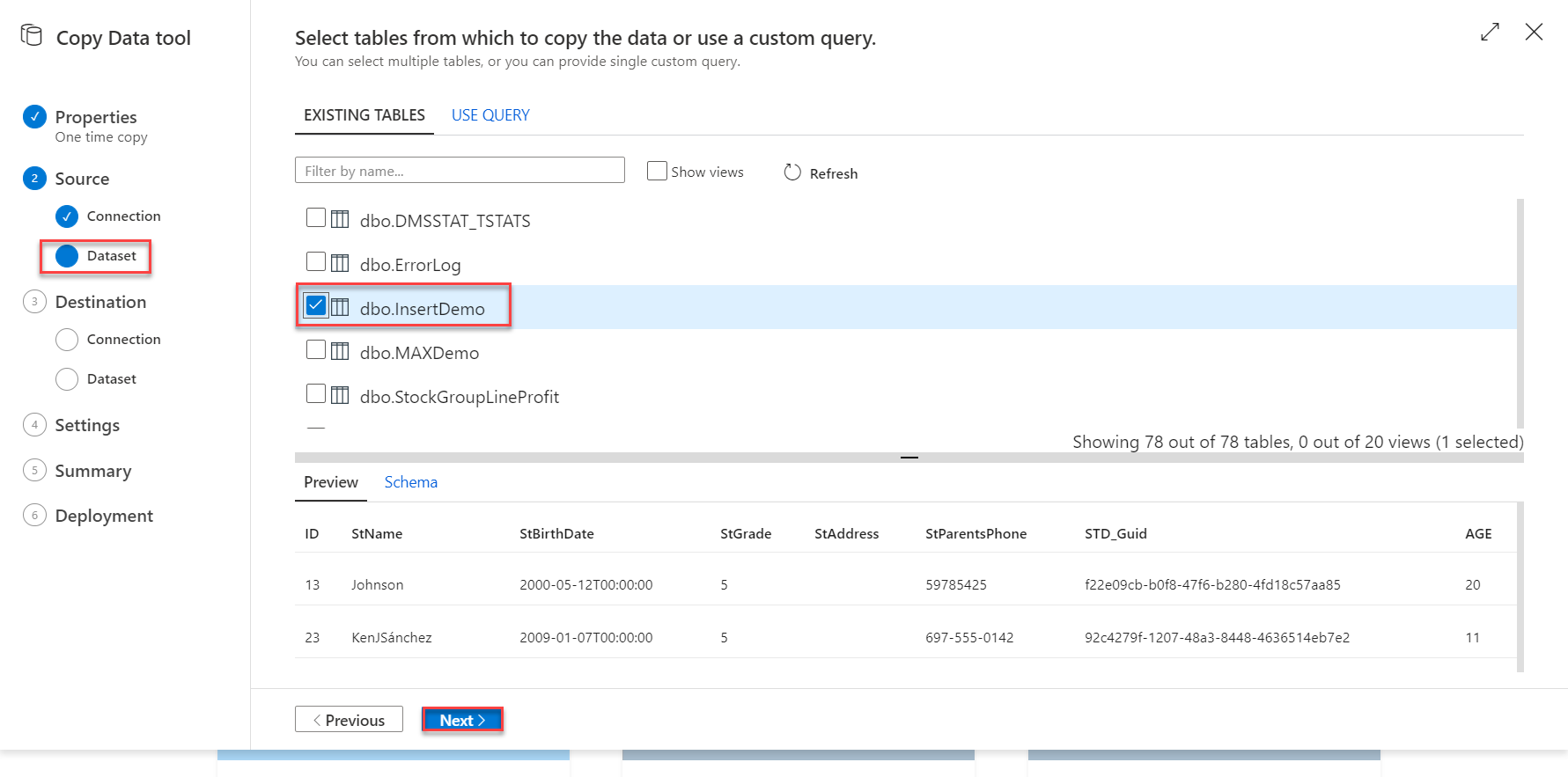
With the source Linked Service created successfully, you need to create the Dataset that is a reference to the source table(s) you will read from. Where you will be requested to select the tables to be copied to the sink data store, or to write a query that filters the data you are interested in, as shown below:
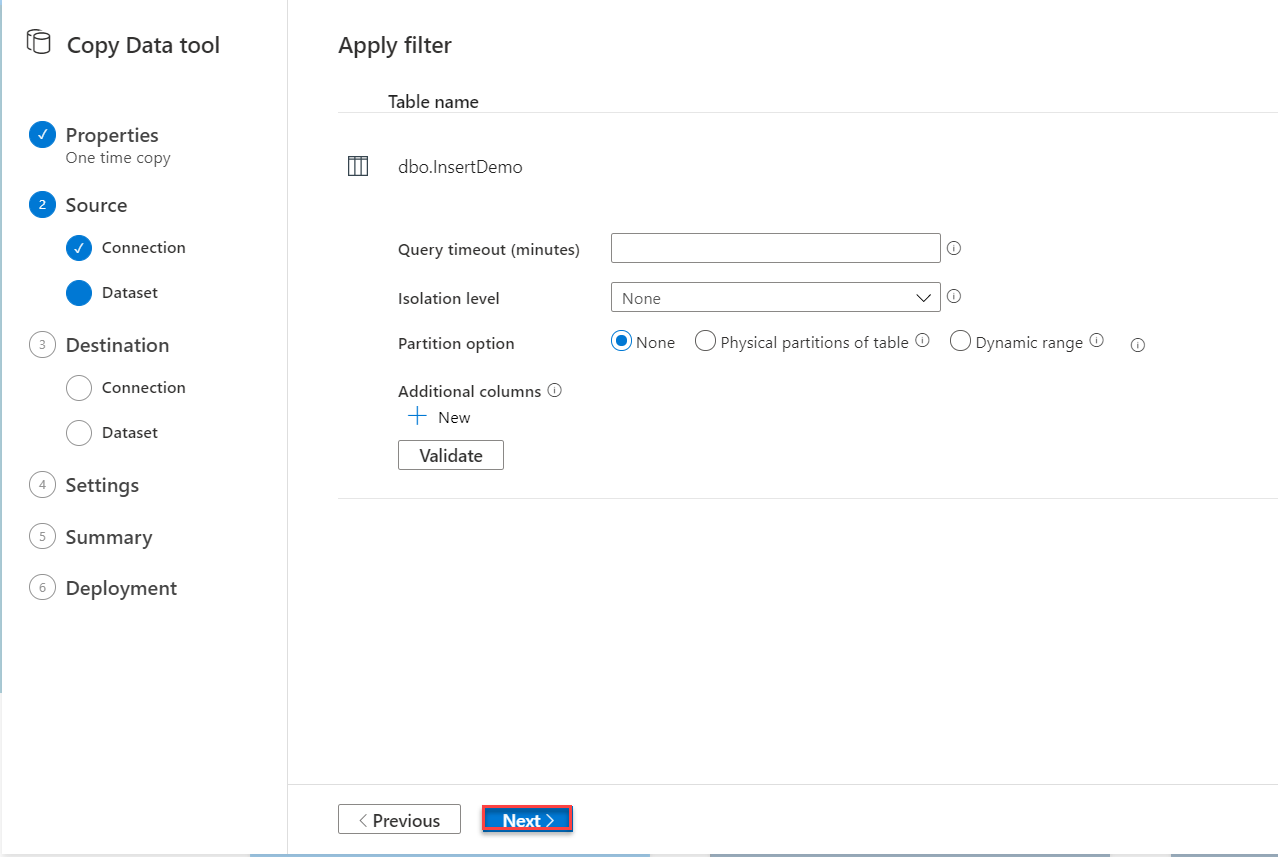
With the ability to apply additional filters to the source data, as below:
The next step is to configure the destination Linked Service, which is the Azure SQL Database that can be found under the Azure category, as shown below:
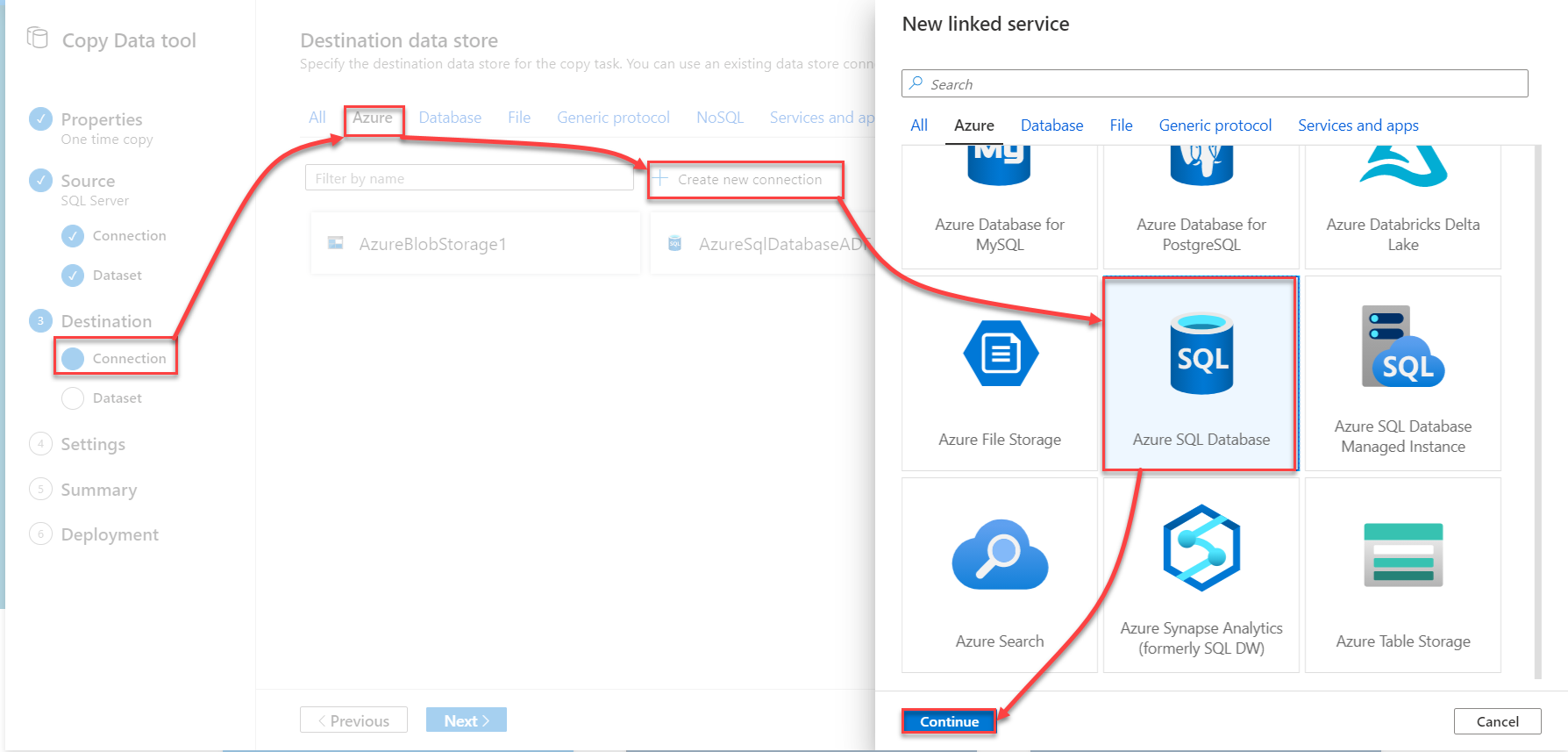
In the destination New Linked Service window, you need to provide a unique name for the destination Linked Service, the subscription name, the Azure SQL server and database names and finally the credentials that will be used by the Azure Data Factory to access the Azure SQL Database. After providing all required connection properties, click on the Test Connection option to verify the connection between the Data Factory and the Azure SQL Database then click Create to create the Linked Service, as shown below:
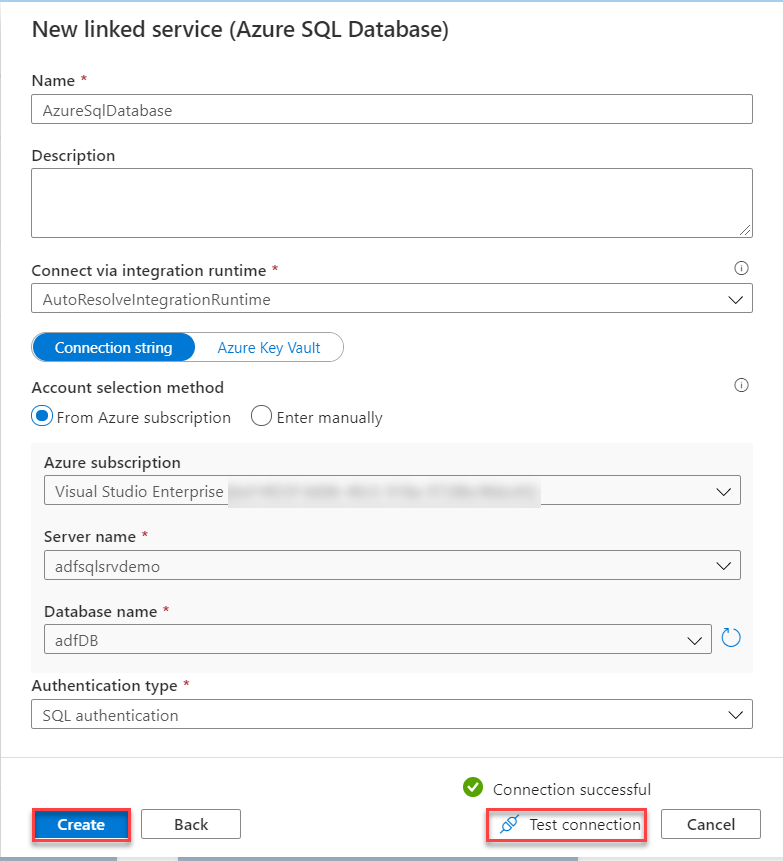
And the destination Linked Service will be displayed under the Linked Services list, as below:
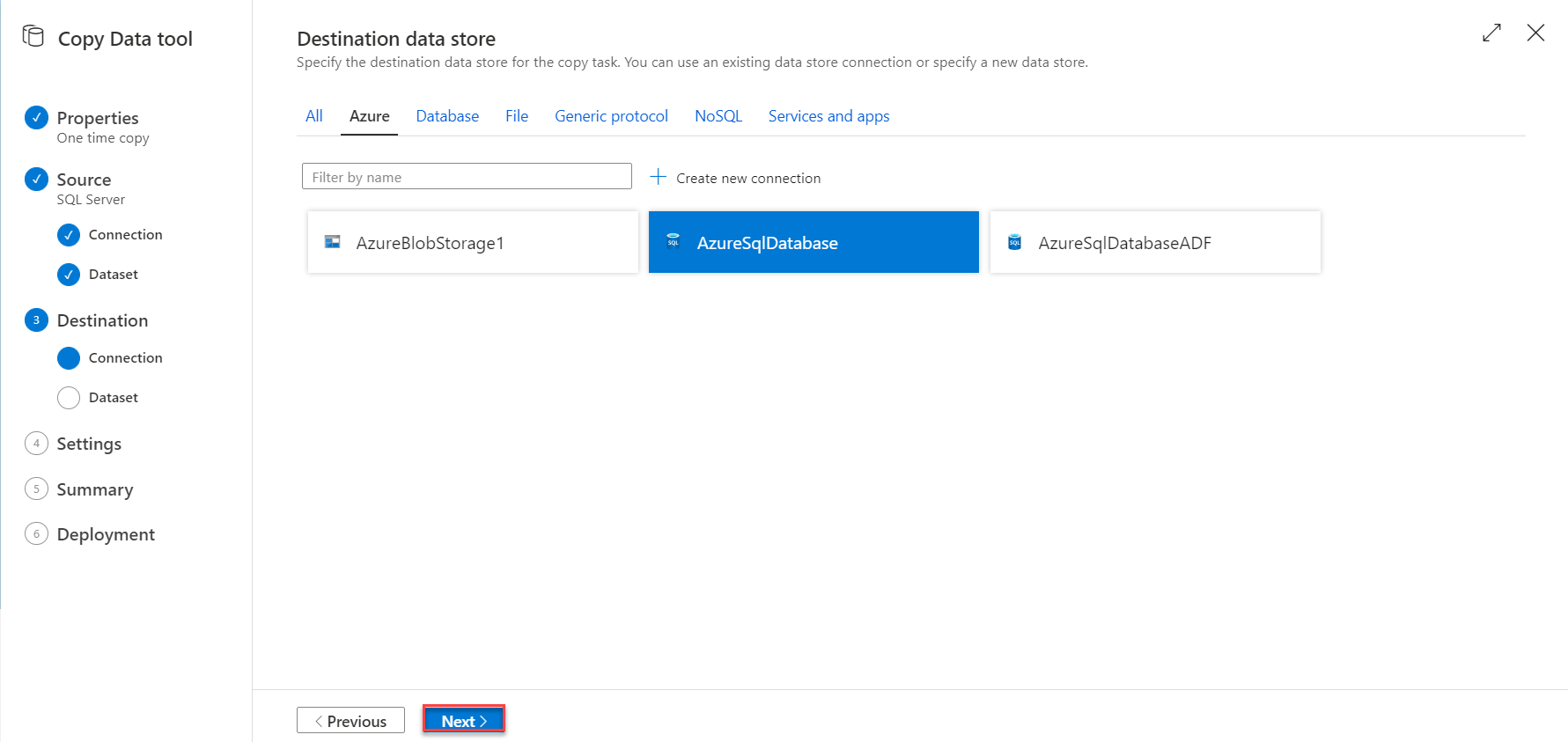
With the destination Linked Service created, you need to create the destination dataset, by selecting the destination table in the Azure SQL Database, where a new table will be created automatically if it does not exist or appending the copied data to an existing table, based on the source schema as shown below:
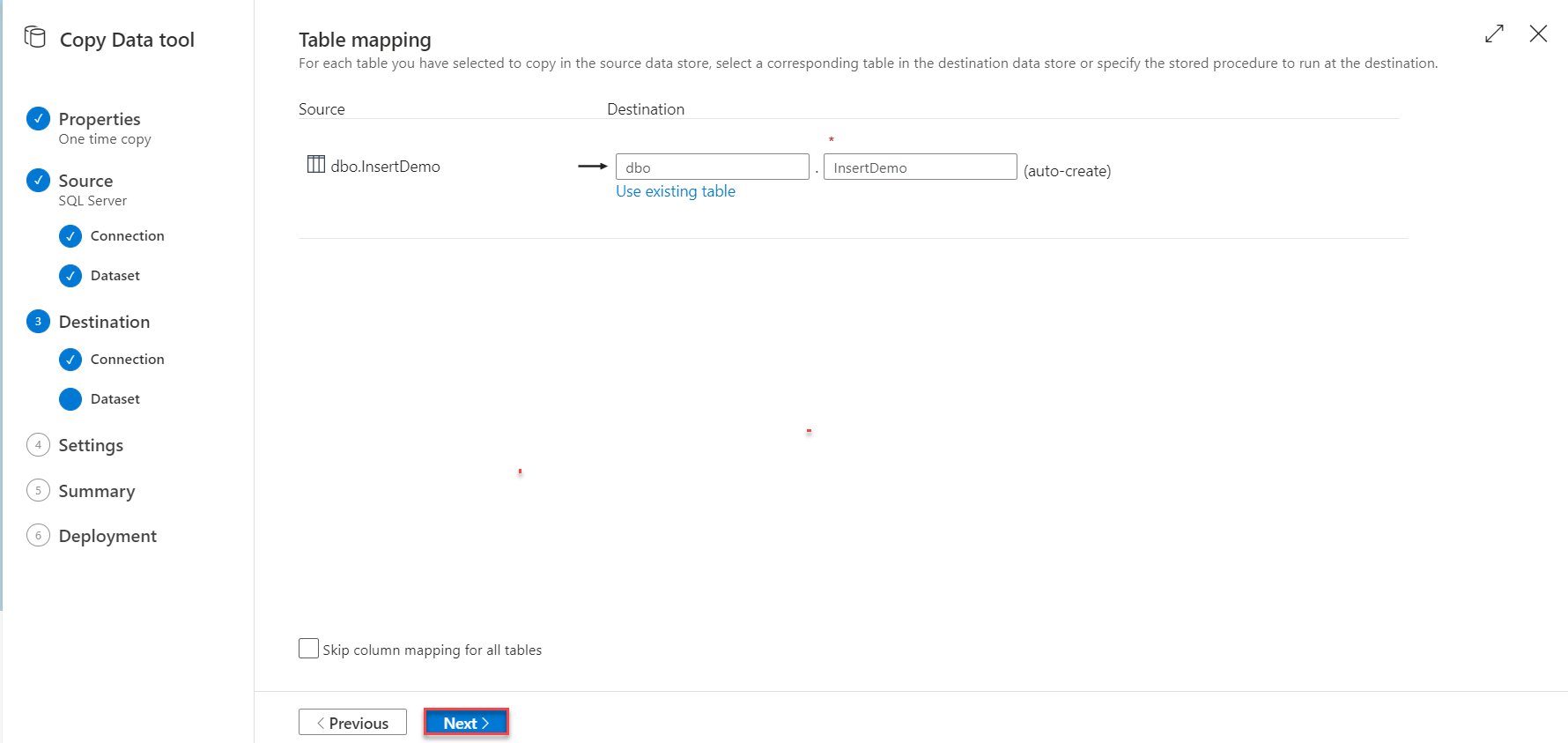
In addition, you need to review the schema mapping between the source and destination tables, with the ability to provide any script that should be executed before copying the data, as below:
And finally, you are asked to configure the copy activity settings, such as the performance and fault tolerance settings, as below:
When you finish configuring all required settings, review all your choices before starting the pipeline deployment process, with the ability to edit it from the Summary window, then click Next to proceed:
At that step, the Linked services and the pipeline will be created then executed as shown below:
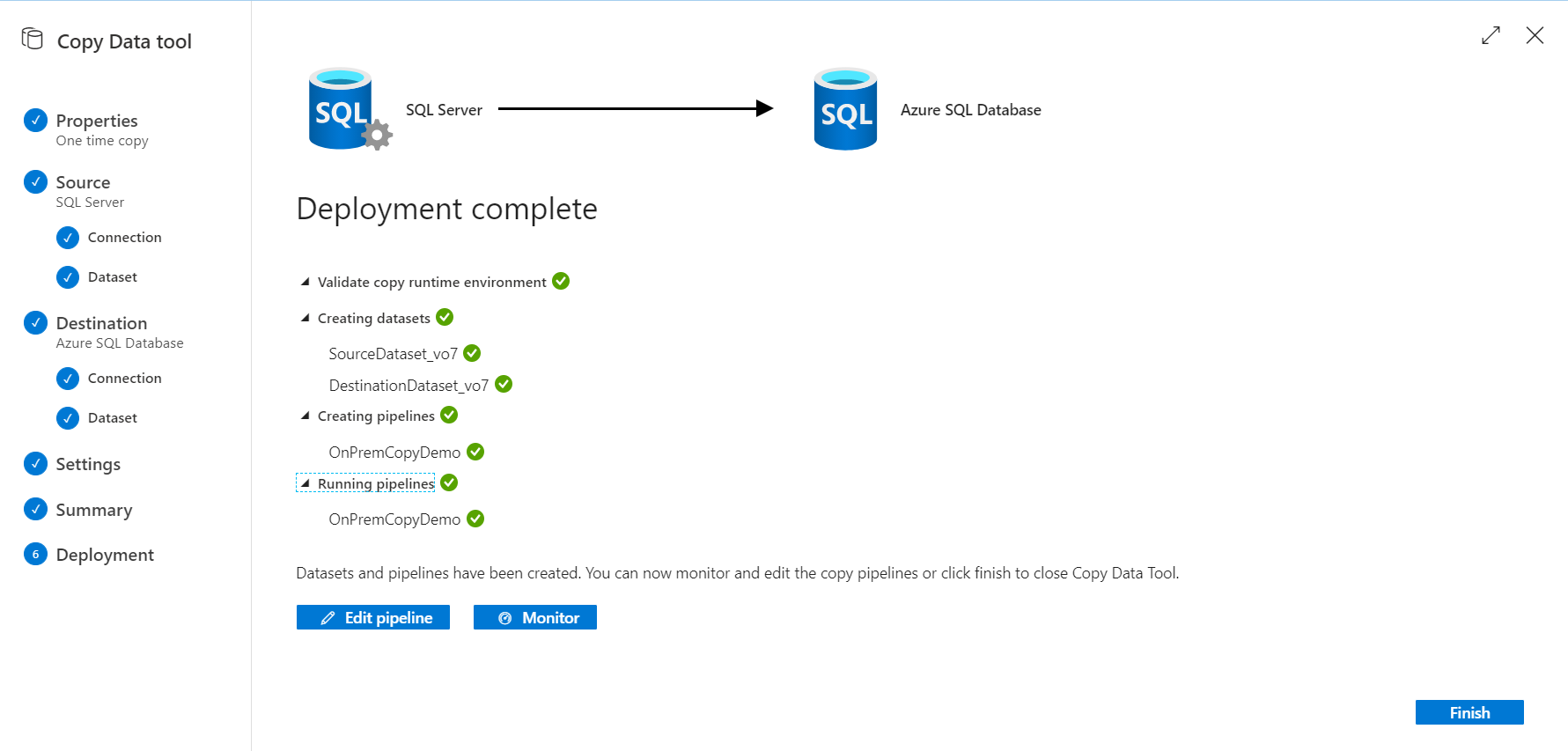
To edit the created pipeline components, click on the Edit pipeline button in the previous window, or click directly on the Author tab, where you will be able to perform changes to the pipeline copy activity properties and the created datasets, as shown below:
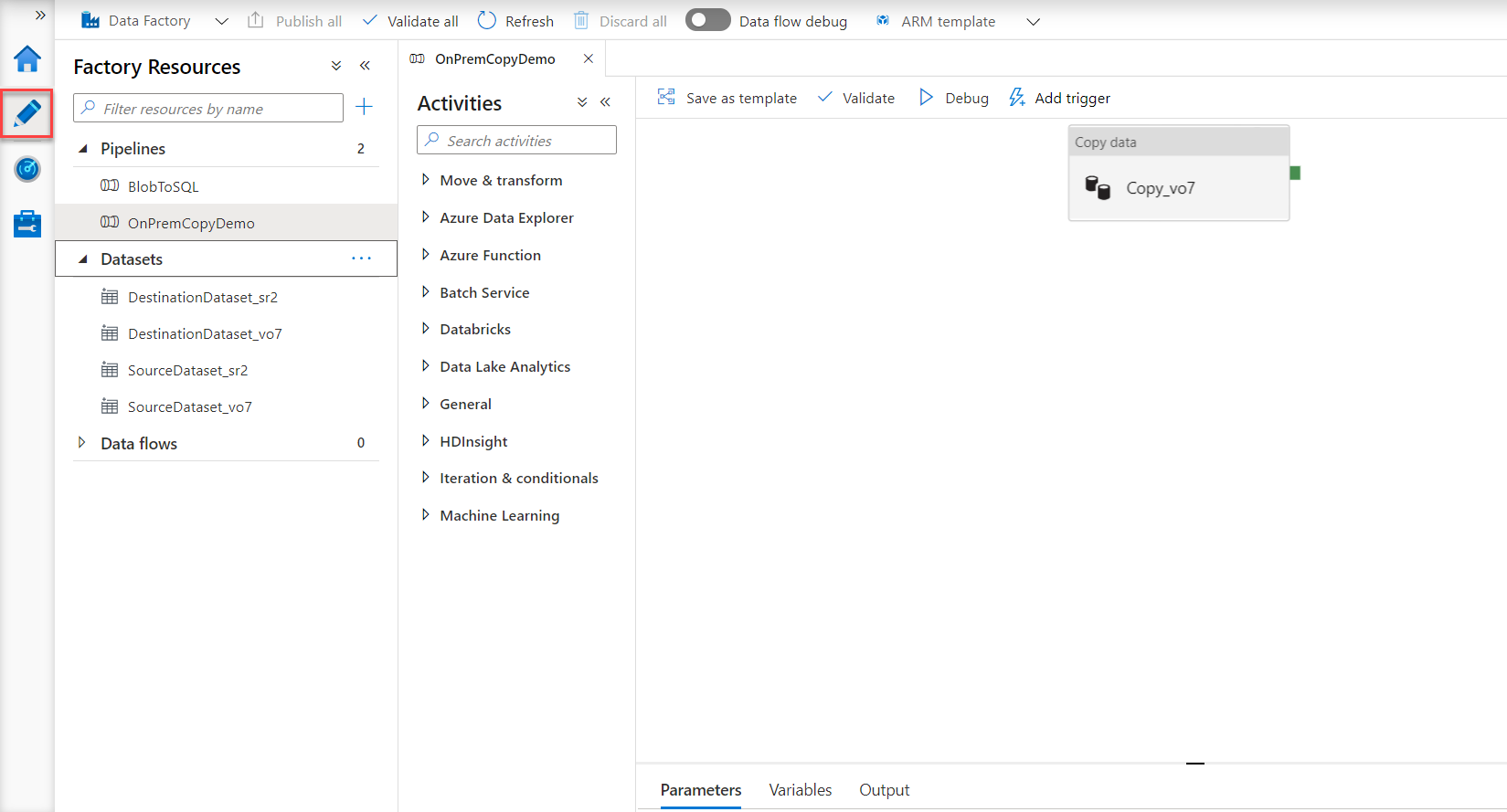
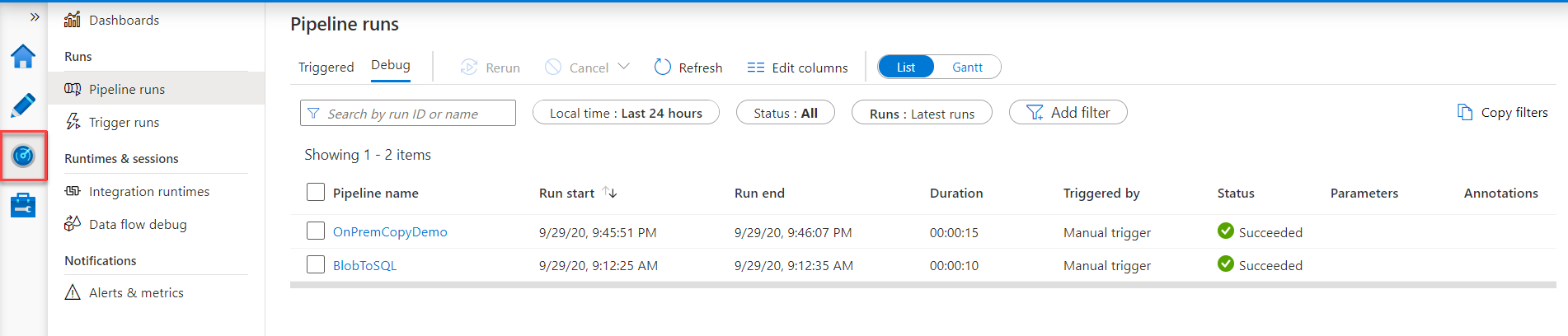
Clicking on the Monitor button will move you to the Pipeline runs window that shows the execution logs for all pipelines, including the execution time, duration and result, as shown below:
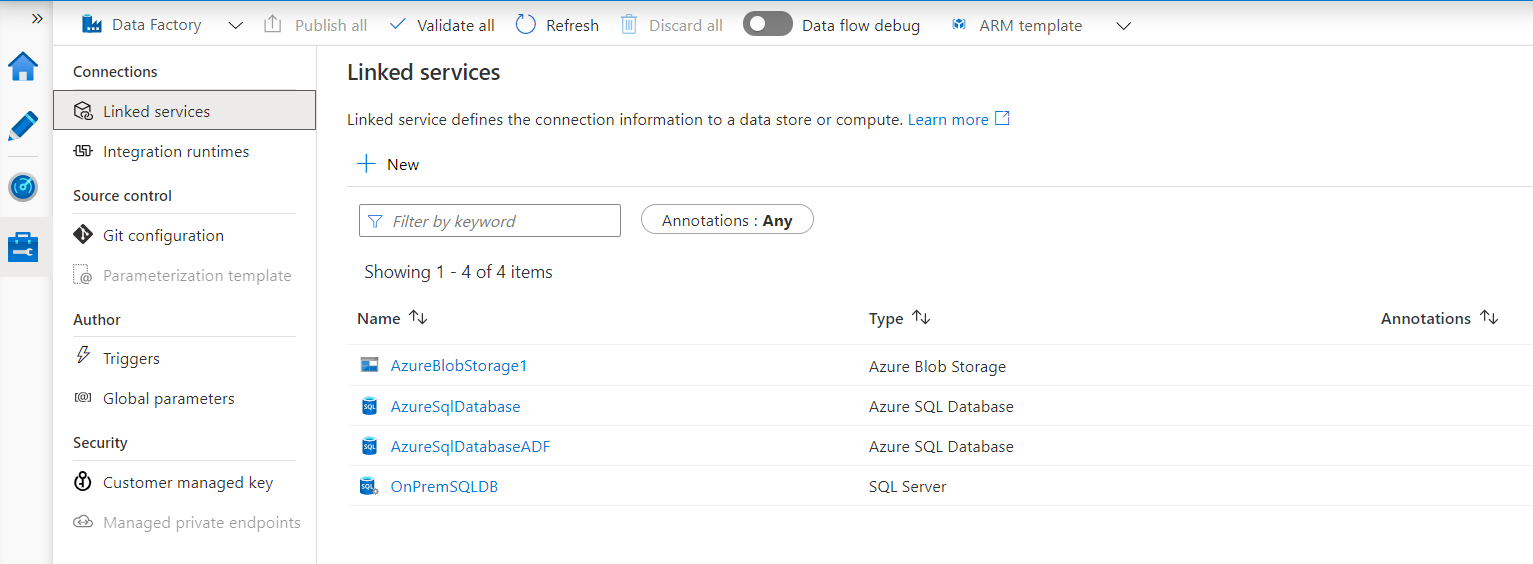
The Azure Data Factory linked Services can be checked and edited from the copy activity properties or directly from the Manage option, as shown below:
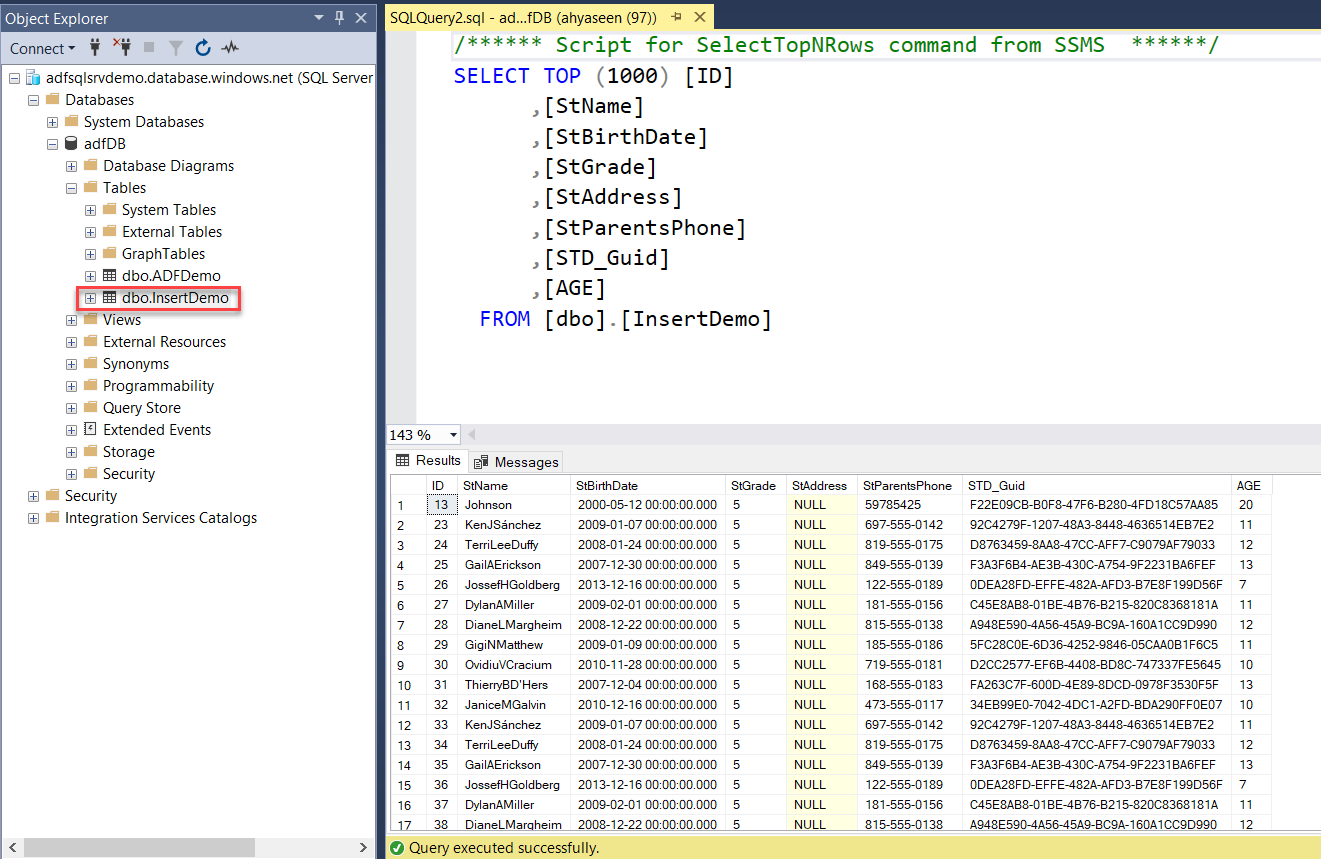
Finally, to verify that the data is copied from the on-premises SQL Server database to the Azure SQL Database, connect to the Azure SQL Database using SSMS and run the SELECT statement below to check the copied data:
Conclusion
In this article, we showed how to copy data from an on-premises data store to an Azure data store. In the next article, we will show how to perform a transformation process for the data using the Azure Data Factory. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021