
In the previous articles of this series, we showed how to create Azure Data Factory pipelines that consist of multiple activities to perform different actions, where the activities will be executed sequentially. This means that the next activity will not be executed until the previous activity is executed successfully without any issue.
In this article, we will show how to control the dependencies between the activities and the pipeline runs in the Azure Data Factory.
Dependency between Activities
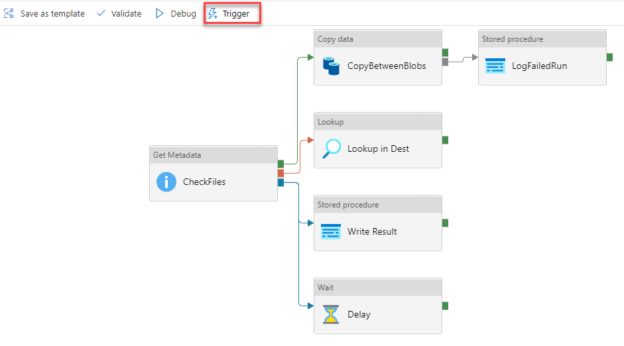
As mentioned previously, the default behavior of the pipeline activities is that it will not be executed unless the previous activity is executed successfully. This default dependency type in the Azure Data Factory activities is the Success type, with the green box icon and green arrow, as shown below:
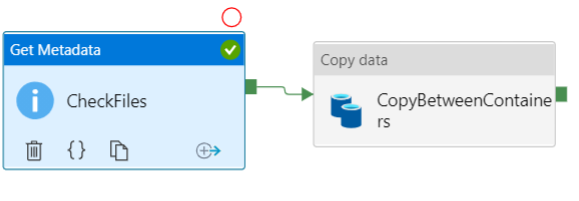
If you click on any activity, you will see a number of icons that can be used to drop the activity, view the source code, and clone that activity. At the most right of these icons you will the  alone icon, which is used to control the dependency between the current activity and the next activities, where you can add and configure it to run the next activity if the current activity succeeded, failed, completed regardless of the result and finally skipped and not executed, as shown below:
alone icon, which is used to control the dependency between the current activity and the next activities, where you can add and configure it to run the next activity if the current activity succeeded, failed, completed regardless of the result and finally skipped and not executed, as shown below:
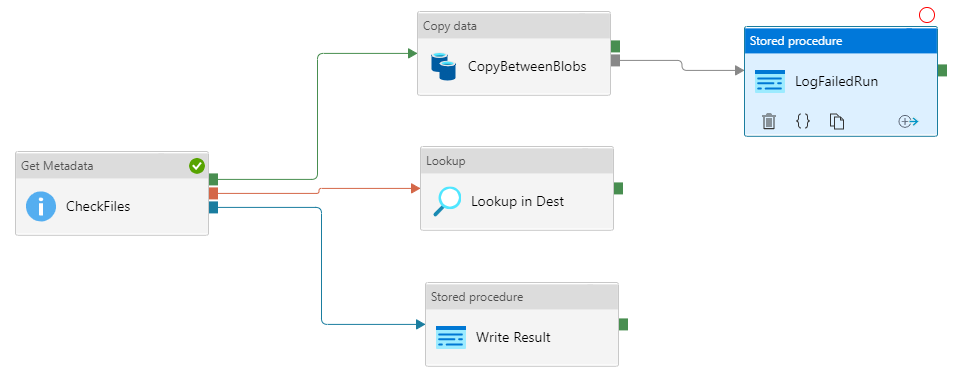
To understand each activity execution dependency option from the previous list, let us create a more complex Azure Data Factory pipeline, in which we have a Get Metadata activity that checks the existence of a specific file in the source Azure Storage Account, if the file is in the storage account then the Get Metadata activity will be executed successfully, and the copy activity that is connected with the green box and the green arrow, that indicates a succeeded execution of the previous activity, will be executed too, and the file will be copied from the source Azure Storage Account to the destination account.
On the other hand, if the Get Metadata activity failed due to the absence of the file in the Azure Storage Account, the Lookup activity that is connected to the red box and the red arrow will be executed, to search for that file in the destination Azure Storage Account, and you can add any activity to perform the proper action if the file is found in the destination Azure Storage Account, based on your own logic.
You can see also a blue box and a blue arrow that is connected to a Stored Procedure execution activity, that contains the action that will be performed when the Get Metadata activity completed, regardless of the completion status, succeeded or failed, where we will use this activity to write a log to an Azure SQL Database table when the activity execution completed.
The last dependency option is the grey box and the grey arrow that is connected to the Stored Procedure execution activity that will be executed when the previous activity, which is the copy activity, is skipped and not executed, as shown below:
Now, let us test the Azure Data Factory pipeline execution scenarios and see what will be executed in each scenario!
Having the requested file in the source Azure Storage Account, we expect the Get Metadata activity to be executed successfully, which leads to executing the Copy activity that moves the file from the source storage account to the destination storage account.
Notice that the Lookup activity will be skipped as the Get Metadata succeeded and the Stored Procedure execution activity that is connected to the Copy activity also skipped as the Copy activity executed in this Azure Data Factory pipeline and not skipped.
The Stored Procedure execution activity that is connected directly to the Get Metadata activity will be executed also, as the Get Metadata activity completed, as shown from the green circles and output tab below:
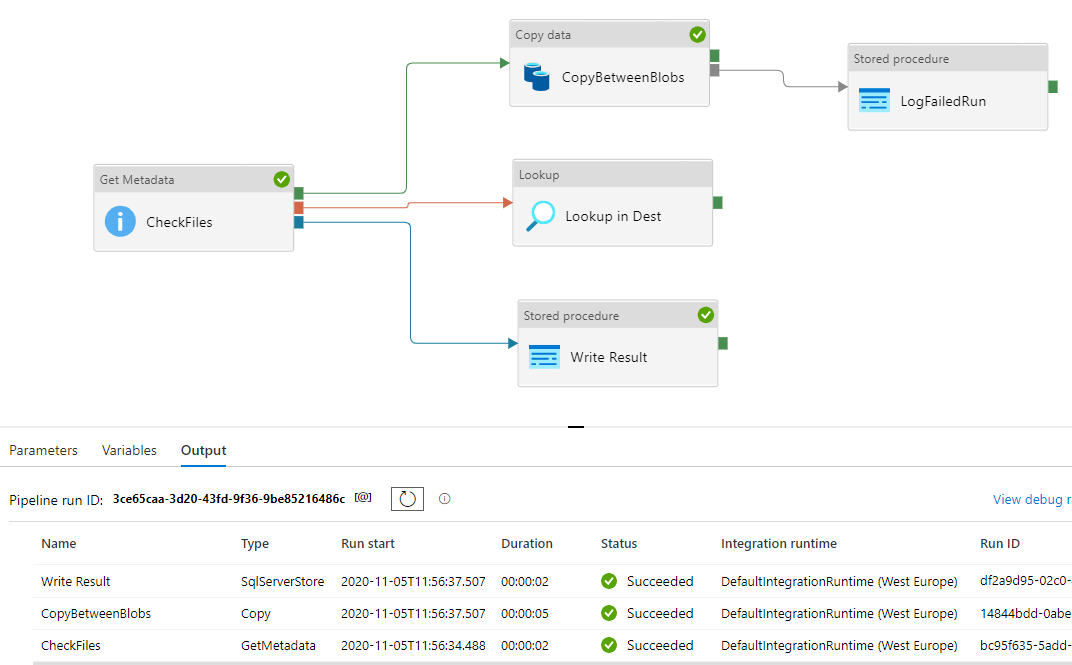
Now, assume that the requested file is not available in the source Azure Storage Account, then the Get Metadata activity will fail when executing the Azure Data Factory pipeline.
With the failure of the Get Metadata activity, the Lookup activity that searches for the file in the destination Azure Storage Account, and the Stored Procedure execution activity that is connected to the Copy activity will be executed also and log the Get Metadata activity failure in an Azure SQL Database table, as the Copy activity, that runs only when the Get Metadata activity completed successfully, is skipped due to the Get Metadata activity failure.
Again, the Stored Procedure execution activity that is connected directly to the Get Metadata activity will be executed also, as the Get Metadata activity completed, regardless of succeeded or failed, as shown from the green circles and output tab below:
Tumbling Window Trigger Dependency
In Azure Data Factory, Tumbling Window trigger consists of a series of fixed-size, non-overlapping, and contiguous time intervals that are fired at a periodic time interval from a specified start time, while retaining state. For more information, check How to Schedule Azure Data Factory Pipeline Execution Using Triggers.
With Tumbling Window dependency, you can guarantee that the preceding window should be completed successfully in order to proceed with the next window, where the dependency in these windows can be with the preceding windows in the same trigger, called self-dependency, or dependency on another Tumbling Window trigger, based on the fact that, the Tumbling Window trigger in Azure Data Factory retains the execution status.
Let us first create a new Tumbling Window Trigger from the pipeline Author window, by clicking on the Trigger button and choose the New/Edit option, as shown below:
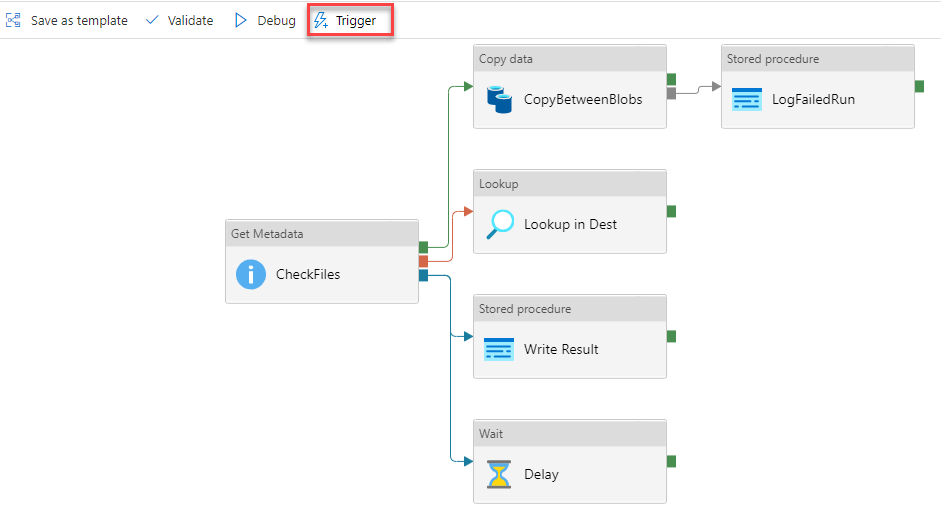
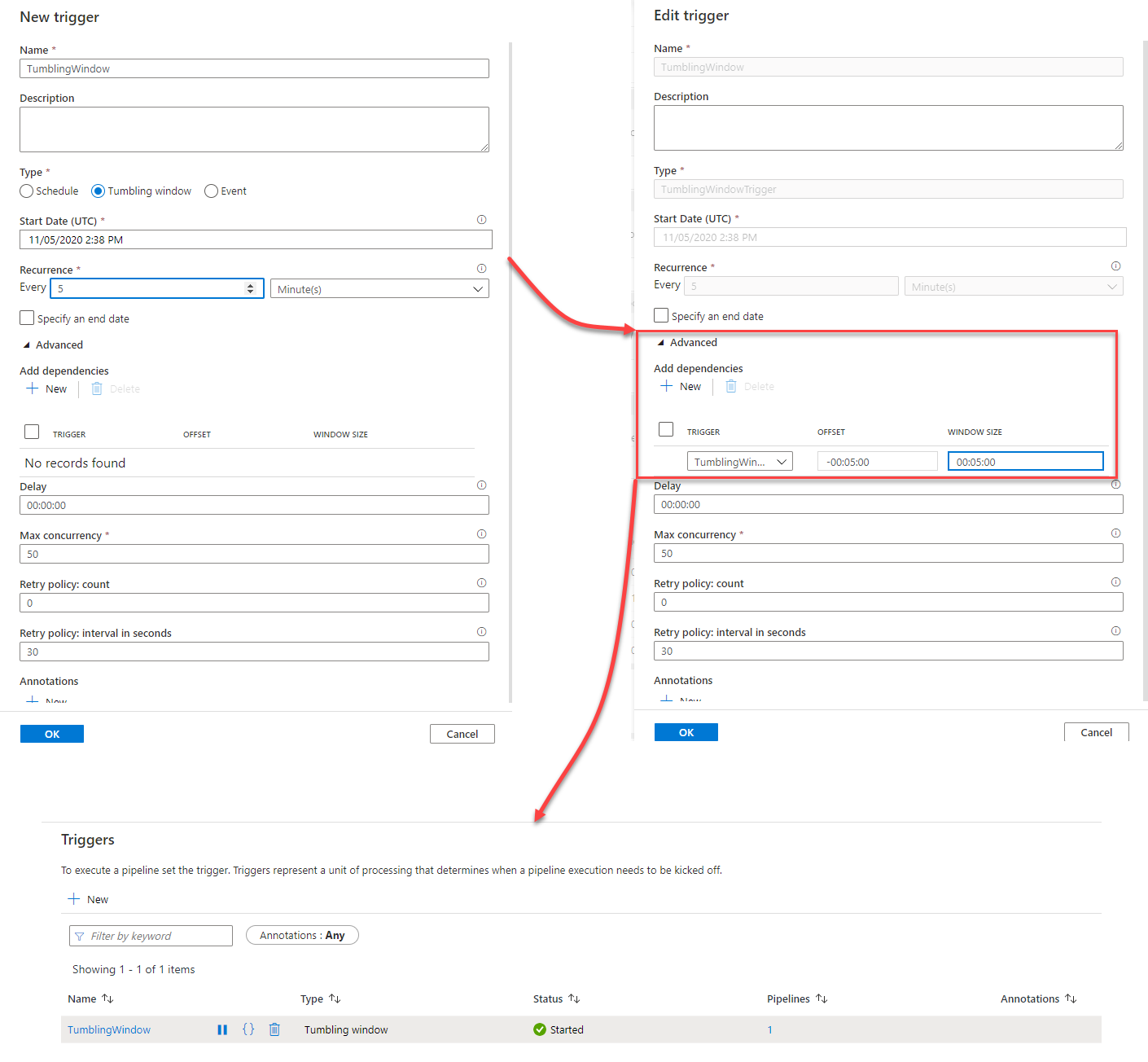
In the New Trigger window, provide a meaningful name for the trigger, choose Tumbling Window as the trigger type, set value for the pipeline start date, execution recurrence and optionally the end date, then click Create to proceed.
Once created, edit the trigger again, go to Advanced -> Add Dependencies then click on the +New option to add a new dependency. Here we will create a self-dependency to the same trigger so we will choose the same trigger in the trigger name. The Offset value is a positive or negative timespan value, which is mandatory for the self-dependency scenario that is used as an offset for the dependency trigger, where the Size is a positive timespan value that indicates the size of the dependency tumbling window. Both values should be provided in the hh:mm:ss format. After configuring the tumbling window trigger dependency, open the Manage page and browse for the Triggers list, where you can enable and edit the created trigger and check the Azure Data Factory pipelines that are connected to that trigger, as shown below:
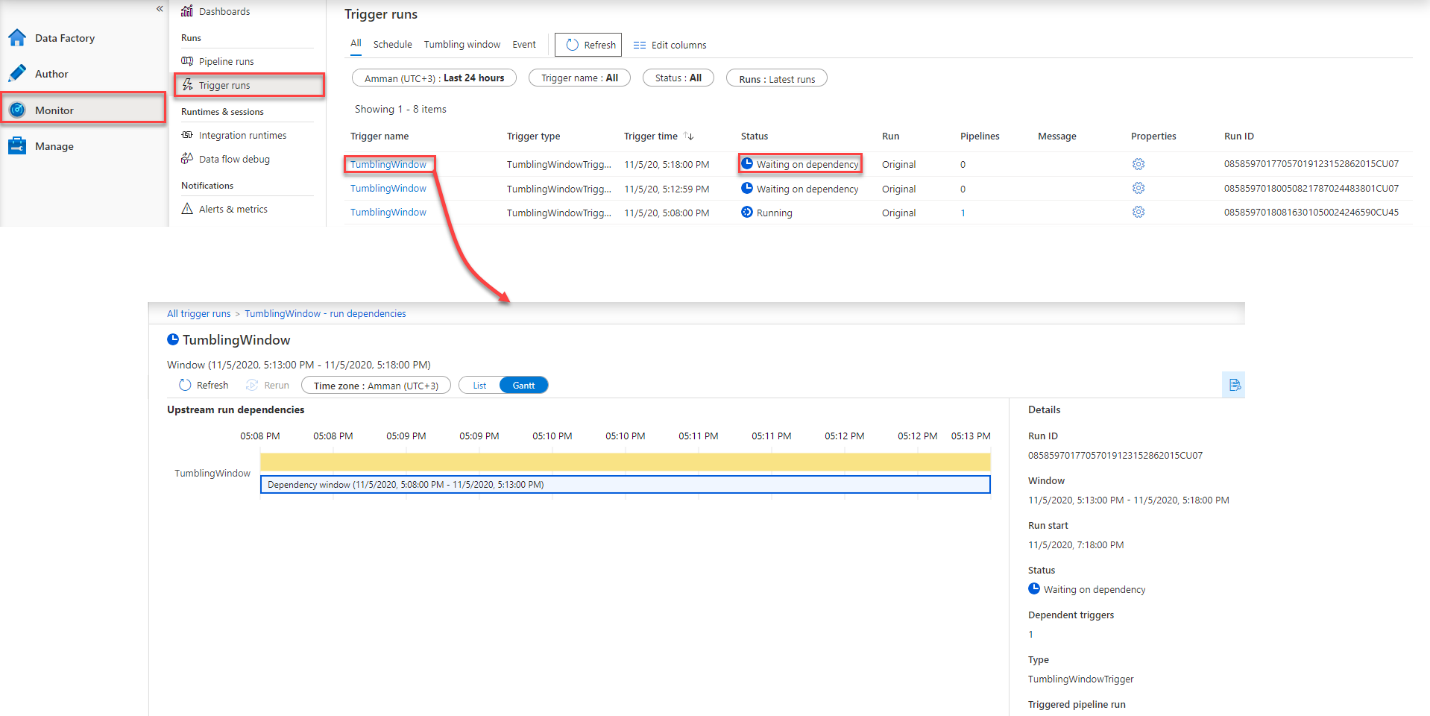
To monitor the tumbling window execution, go to the Monitor page and check the status of the different pipeline executions in different tumbling windows, where you will see the first execution is in Running state and the rest of executions are in Waiting state on dependency, till the first time slot execution is completed successfully. You can see also that the name of the Tumbling Window trigger that is configured with dependencies is provided as a hyperlink that directs to the dependency monitoring window, that shows useful information about the trigger execution such as the Run ID, Window time, the execution status of the dependencies, taking into consideration that the tumbling window trigger will wait for 7 days before failing with timeout error, as shown below:
Conclusion
In this article, we discussed how to configure the dependency between the activities within the Azure Data Factory pipeline based on the execution status of the previous activity. Also, we showed how to configure the self-dependency between the tumbling windows within the tumbling window trigger. Stay tuned for the next article in this series!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021